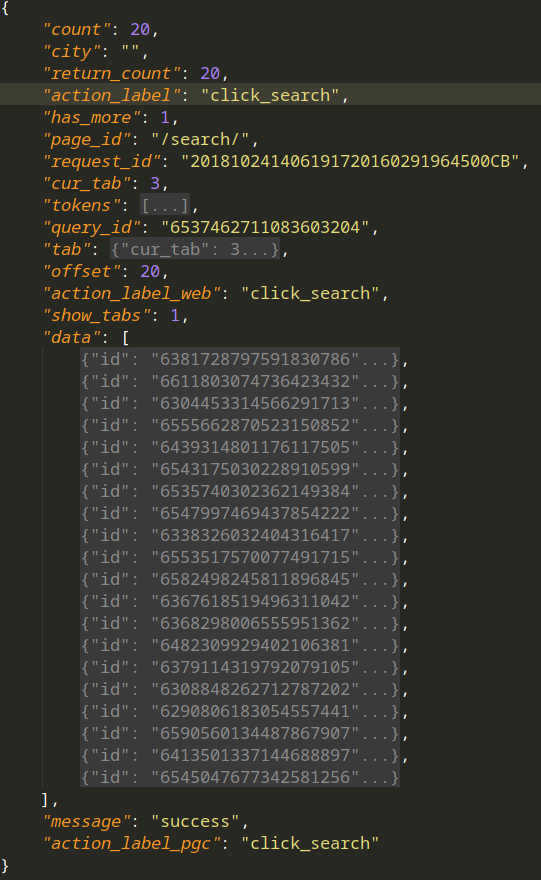
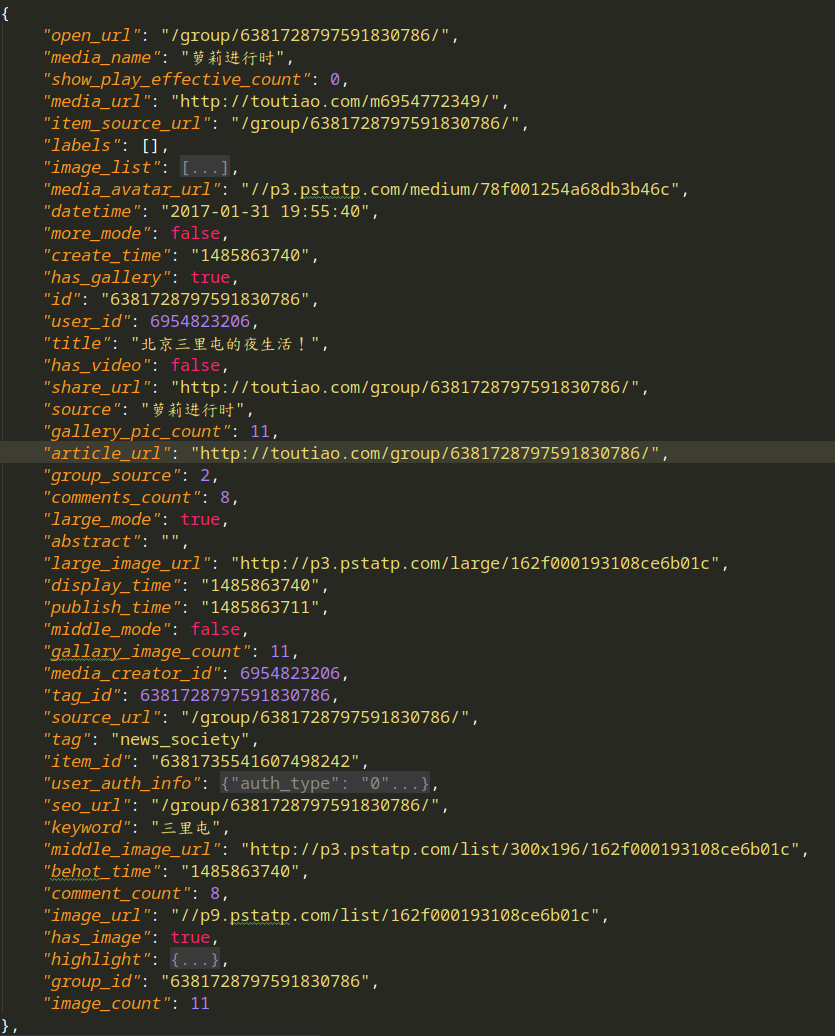
1.访问搜索图集结果,获得json如下(右图为data的一条的详细内容).页面以Ajax呈现,每次请求20个图集,其中
title --- 图集名字
artical_url --- 图集的地址
count --- 图集图片数量
2. 访问其中的图集
访问artical_url,获得图集图片详细信息,其中图片url为下载地址

展现出爬虫关键部分,整体项目地址在https://github.com/GeoffreyHub/toutiao_spider
1 #!/usr/bin/env python 2 # encoding: utf-8 3 4 """ 5 @version: python37 6 @author: Geoffrey 7 @file: spider.py 8 @time: 18-10-24 上午11:15 9 """ 10 import json 11 import re 12 from multiprocessing import Pool 13 import urllib3 14 urllib3.disable_warnings() 15 from requests import RequestException 16 17 from common.request_help import make_session 18 from db.mysql_handle import MysqlHandler 19 from img_spider.settings import * 20 21 22 23 class SpiderTouTiao: 24 25 26 def __init__(self, keyword): 27 self.session = make_session(debug=True) 28 self.url_index = 'https://www.toutiao.com/search_content/' 29 self.keyword = keyword 30 self.mysql_handler = MysqlHandler(MYSQL_CONFIG) 31 32 def search_index(self, offset): 33 url = self.url_index 34 data = { 35 'offset': f'{offset}', 36 'format': 'json', 37 'keyword': self.keyword, 38 'autoload': 'true', 39 'count': '20', 40 'cur_tab': '3', 41 'from': 'gallery' 42 } 43 44 try: 45 response = self.session.get(url, params=data) 46 if response.status_code is 200: 47 json_data = response.json() 48 with open(f'../json_data/搜索结果-{offset}.json', 'w', encoding='utf-8') as f: 49 json.dump(json_data, f, indent=4, ensure_ascii=False) 50 return self.get_gallery_url(json_data) 51 except : 52 pass 53 print('请求失败') 54 55 @staticmethod 56 def get_gallery_url(json_data): 57 dict_data = json.dumps(json_data) 58 for info in json_data["data"]: 59 title = info["title"] 60 gallery_pic_count = info["gallery_pic_count"] 61 article_url = info["article_url"] 62 yield title, gallery_pic_count, article_url 63 64 def gallery_list(self, search_data): 65 gallery_urls = {} 66 for title, gallery_pic_count, article_url in search_data: 67 print(title, gallery_pic_count, article_url) 68 response = self.session.get(article_url) 69 html = response.text 70 images_pattern = re.compile('gallery: JSON.parse("(.*?)"),', re.S) 71 result = re.search(images_pattern, html) 72 73 if result: 74 # result = result.replace('\', '') 75 # result = re.sub(r"\", '', result) 76 result = eval("'{}'".format(result.group(1))) 77 result = json.loads(result) 78 # picu_urls = zip(result["sub_abstracts"], result["sub_titles"], [url["url"] for url in result["sub_images"]]) 79 picu_urls = zip(result["sub_abstracts"], [url["url"] for url in result["sub_images"]]) 80 # print(list(picu_urls)) 81 gallery_urls[title] = picu_urls 82 else: 83 print('解析不到图片url') 84 85 with open(f'../json_data/{title}-搜索结果.json', 'w', encoding='utf-8') as f: 86 json.dump(result, f, indent=4, ensure_ascii=False) 87 88 break 89 90 # print(gallery_urls) 91 return gallery_urls 92 93 def get_imgs(self, gallery_urls): 94 params = [] 95 for title, infos in (gallery_urls.items()): 96 for index, info in enumerate(infos): 97 abstract, img_url = info 98 print(index, abstract) 99 response = self.session.get(img_url) 100 img_content = response.content 101 params.append([title, abstract, img_content]) 102 103 with open(f'/home/geoffrey/图片/今日头条/{title}-{index}.jpg', 'wb') as f: 104 f.write(img_content) 105 106 SQL = 'insert into img_gallery(title, abstract, imgs) values(%s, %s, %s)' 107 self.mysql_handler.insertOne(SQL, [title, abstract, img_content]) 108 self.mysql_handler.end() 109 110 print(f'保存图集完成' + '-'*50 ) 111 # SQL = 'insert into img_gallery(title, abstract, imgs) values(%s, %s, %s)' 112 # self.mysql_handler.insertMany(SQL, params) 113 # self.mysql_handler.end() 114 115 116 def main(offset): 117 spider = SpiderTouTiao(KEY_WORD) 118 search_data = spider.search_index(offset) 119 gallery_urls = spider.gallery_list(search_data) 120 spider.get_imgs(gallery_urls) 121 spider.mysql_handler.dispose() 122 123 124 if __name__ == '__main__': 125 groups = [x*20 for x in range(GROUP_START, GROPE_END)] 126 127 pool = Pool(10) 128 pool.map(main, groups) 129 130 # for i in groups: 131 # main(i)
项目结构如下:
.
├── common
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-37.pyc
│ │ └── request_help.cpython-37.pyc
│ ├── request_help.py
├── db
│ ├── __init__.py
│ ├── mysql_handle.py
│ └── __pycache__
│ ├── __init__.cpython-37.pyc
│ └── mysql_handle.cpython-37.pyc
├── img_spider
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-37.pyc
│ │ └── settings.cpython-37.pyc
│ ├── settings.py
│ └── spider.py
└── json_data
├── 沐浴三里屯的秋-搜索结果.json
├── 盘点三里屯那些高逼格的苍蝇馆子-搜索结果.json
├── 搜索结果-0.json
├── 搜索结果-20.json
├── 搜索结果-40.json