当前的 CNN 中的 attention 机制主要包括:channel attention 和 spatial attention,当前一些方法(GCNet 、CBAM 等)通常将二者集成,容易产生 converging difficulty 和 heavy computation burden 的问题。尽管 ECANet 和 SGE 提出了一些优化方案,但没有充分利用 channel 和 spatial 之间的关系。因此,作者提出一个问题 “ Can one fuse different attention modules in a lighter but more efficient way? ”
为解决这个问题,作者提出了 shuffle attention,整体框架如下图所示。可以看出首先将输入的特征分为(g)组,然后每一组的特征进行split,分成两个分支,分别计算 channel attention 和 spatial attention,两种 attention 都使用全连接 + sigmoid 的方法计算。接着,两个分支的结果拼接到一起,然后合并,得到和输入尺寸一致的 feature map。 最后,用一个 shuffle 层进行处理。
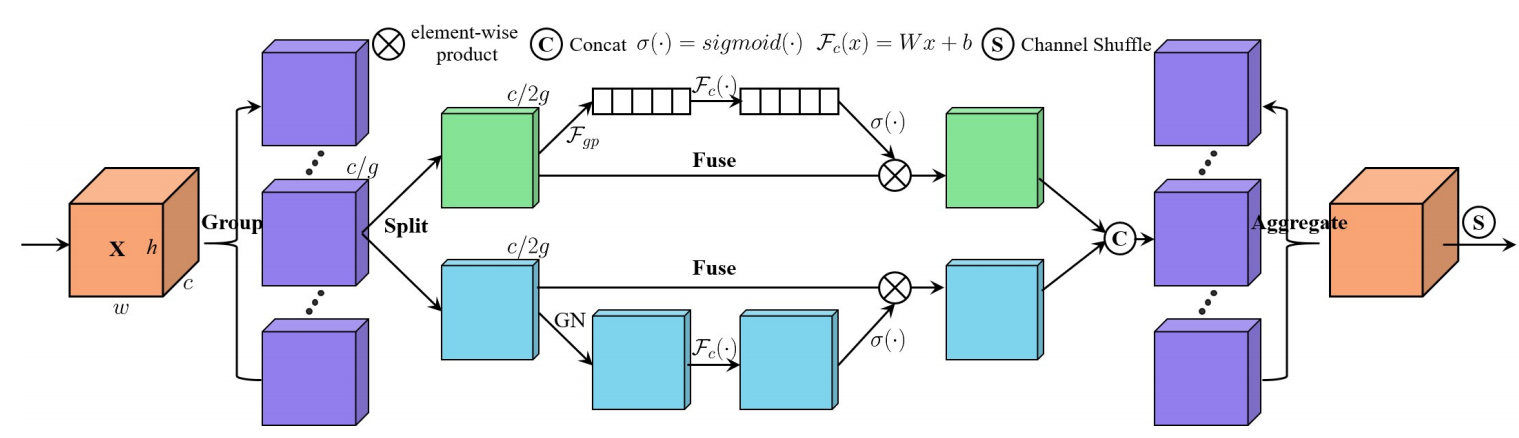
代码如下。 可以看出,在最后的 shuffle 部分,是直接分为两个组,然后置换进行组间交互。
class sa_layer(nn.Module):
def __init__(self, channel, groups=64):
super(sa_layer, self).__init__()
self.groups = groups
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.cweight = Parameter(torch.zeros(1, channel // (2 * groups), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * groups), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * groups), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * groups), 1, 1))
self.sigmoid = nn.Sigmoid()
self.gn = nn.GroupNorm(channel // (2 * groups), channel // (2 * groups))
def forward(self, x):
b, c, h, w = x.shape
# 将各个组与 n 合并在一维
x = x.reshape(b * self.groups, -1, h, w)
# 每组特征拆成 2 组,方便 2 分支处理
x_0, x_1 = x.chunk(2, dim=1)
# channel attention
xn = self.avg_pool(x_0)
xn = self.cweight * xn + self.cbias
xn = x_0 * self.sigmoid(xn)
# spatial attention
xs = self.gn(x_1)
xs = self.sweight * xs + self.sbias
xs = x_1 * self.sigmoid(xs)
# 沿 channel 方向合并
out = torch.cat([xn, xs], dim=1)
# 恢复与输入一致的 feature map 尺寸
out = out.reshape(b, -1, h, w)
# 分为两个组进行 channel shuffle,后面有代码解析
out = self.channel_shuffle(out, 2)
return out
Channel shuffle 的代码如下:
def channel_shuffle(x, groups):
b, c, h, w = x.shape
# 因为要分组,先 reshape 成5个维度
x = x.reshape(b, groups, -1, h, w)
# 把 groups 和 channel 维度替换
x = x.permute(0, 2, 1, 3, 4)
# 恢复成输入的形状,实现 channel shuffle
x = x.reshape(b, -1, h, w)
return x
实验部分可以参照原作者的论文,这里不多介绍。