2017-2018-1 20155229 《信息安全系统设计基础》第十四周学习总结
对“第三章 程序机器级表示”的深入学习
- 我选择这章的理由是第一次学的时候还是不太理解,老师也有说这章建议在认真学习,所以本周的学习任务是认真再次学习这一章
c语言、汇编代码以及机器代码
这三者的关系大概顺序是:
- [1]C预处理器扩展源代码,展开所以的#include命名的指定文件;
- [2]编译器产生汇编代码(.s);
- [3]汇编器将汇编代码转化成二进制目标文件(.o).
- 汇编起着高级语言和底层二进制代码的桥梁作用.
1.机器语言
机器语言是用二进制代码表示的计算机能直接识别和执行的一种机器指令的集合。它是计算机的设计者通过计算机的硬件结构赋予计算机的操作功能。机器语言具有灵活、直接执行和速度快等特点。
2.汇编语言
汇编语言是用符号代替了机器指令代码,而且助记符与指令代码一一对应,基本保留了机器语言的灵活性。使用汇编语言能面向机器并较好地发挥机器的特性,得到质量较高的程序。汇编语言用来编制系统软件和过程控制软件,其目标程序占用内存空间少,运行速度快,有着高级语言不可替代的用途。
3.C语言
C语言是一门通用计算机编程语言,应用广泛。C语言的设计目标是提供一种能以简易的方式编译、处理低级存储器、产生少量的机器码以及不需要任何运行环境支持便能运行的编程语言
汇编代码起到了承上启下的作用,理解汇编代码以及与它的源C代码之间的联系,是理解程序如何执行的关键一步,因为编译器隐藏了太多的细节如:程序计数器、寄存器(整数、条件码、浮点)等。
调用函数
调用一个函数,实现将数据和控制代码从一个部分到另一个部分的跳转。
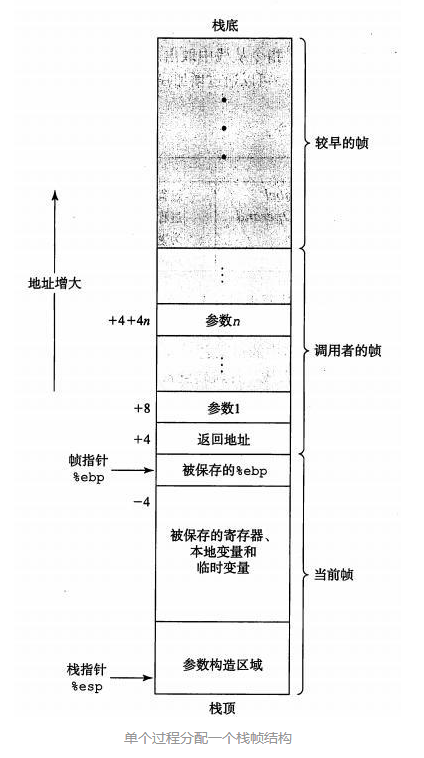
帧指针与栈指针的不公之处: ebp放与参数与返回地址的最下方,方便计算参数的偏移位置;而esp一直在栈顶,可以通过push将数据压入,通过pop取出,增加指针来释放空间。
①转移控制
call指令,同跳转一样,可以是直接的,也可以是间接的。
call指令的效果:1、将返回地址入栈2、跳转到被调用过程的起始处。
当调用过程返回时,执行会从此处继续。ret指令从栈中弹出地址,并跳转到这个位置(表示程序计数器被赋值为这个返回地址,并跳转到这个地址,执行这个地址对应的指令)。
其中call先将返回地址入栈,然后跳转到函数开始的地方执行。(返回地址是开始调用者执行call的后面那条指令的地址)当遇到ret指令的时候,弹出返回地址,并跳转到该处继续执行调用者剩余部分。
leave
等价于:
movl %ebp, %esp
popl %ebp
程序寄存器组被所有过程共享。寄存器 %eax 、 %edx 、 %ecx 为调用者保存寄存器,由P保存,Q可以覆盖这些寄存器而不破坏P的数据。寄存器 %ebx 、 %esi 、 %edi 为被调用者保存寄存器,Q需要在覆盖它们之前将值保存到栈中,并在返回前恢复它们。
int swap(int *x, int *y)
{
int t = *x;
*x = *y;
*y = t;
return *x + *y;
}
int func()
{
int a = 1234;
int b = 4321;
int s = swap(&a, &b);
return s;
}
.p2align 4,,15
.globl swap
.type swap, @function
swap:
pushl %ebp 压入帧指针
movl %esp, %ebp 将帧指针设为栈指针指向位置
movl 8(%ebp), %edx 读取x
movl 12(%ebp), %ecx 读取y
pushl %ebx 压入%ebx(被调用者保存寄存器)
movl (%edx), %eax 读取*x
movl (%ecx), %ebx 读取*y
movl %ebx, (%edx) 将*y写入x指向存储器位置
movl %eax, (%ecx) 将*x写入y指向存储器位置
addl (%edx), %eax *x+*y
popl %ebx 恢复%ebx
popl %ebp 弹出帧指针(%esp等于原值)
ret 返回
.size swap, .-swap
.p2align 4,,15
.globl func
.type func, @function
func:
pushl %ebp 压入帧指针
movl $5555, %eax 保存计算结果(编译器-O2优化)
movl %esp, %ebp 将帧指针设为栈指针指向位置
popl %ebp 弹出帧指针(%esp未变)
ret 返回
.size func, .-func
②数据传送
当调用一个过程的时候,除了要把控制传递给调用过程,调用还需要把数据作为参数传递过去,调用过程可能返回一个值。
如果一个函数有大于6个整型参数,超出6个的部分就通过保存在调用者的栈帧来传递。
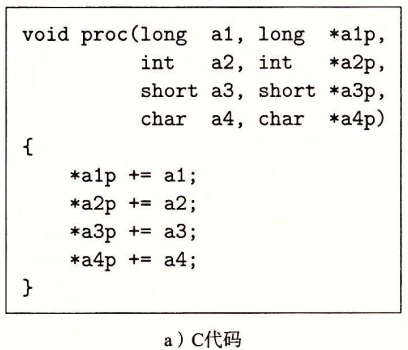
上面的程序代码,前六个参数可以通过寄存器传递,后面的两个通过栈传递。
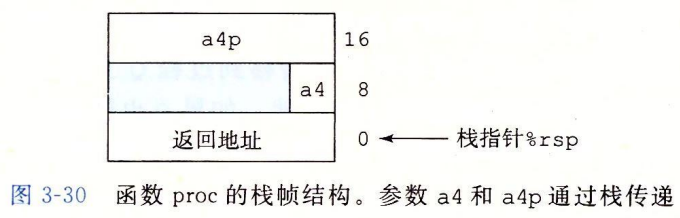
③栈上的局部存储
目前为止我们看到的大多数程序示例都不需要超过寄存器大小的本地存储。不过以下情况局部数据必须要放入内存中。
1.寄存器不足以存放所有的本地数据。
2.对一个局部变量使用运算符“&”。
3.某些局部变量是数组或者是结构体,必须能够通过数据的引用访问到。
eg.
#include<stdio.h>
int swap(int* a,int* b) {
int temp = *a;
*a = *b;
*b = temp;
return *a+*b;
}
int main()
{
int a=5,b=3;
int tot = swap(&a,&b);
printf("%d",tot);
return 0;
}
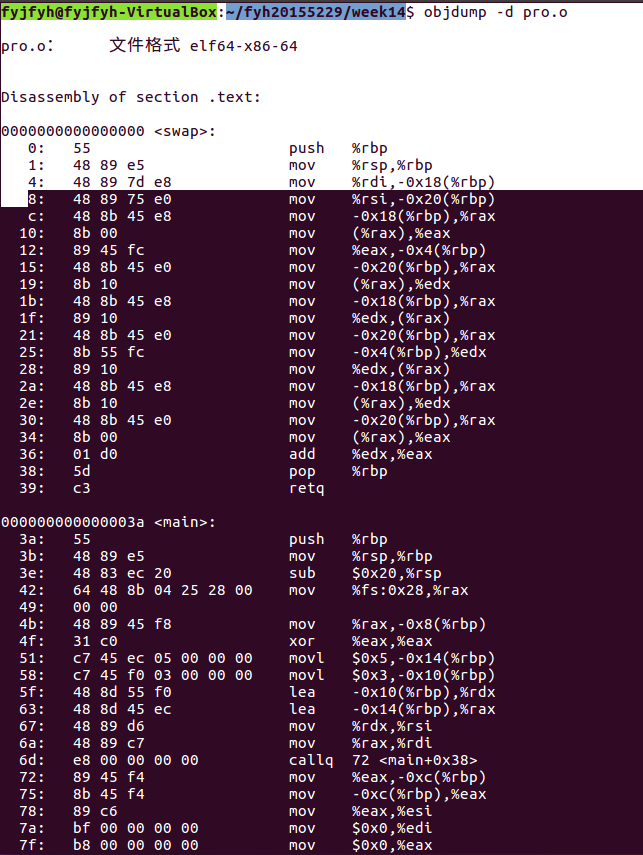
上面的汇编代码是一个交换两个int数据,并得到两个数之和的程序。
④递归的过程
因为寄存器和栈帧的存在是的x86-64过程能够递归的调用自身,每个过程调用在栈中都有自己的私有空间,因此多个未完成的调用的局部空间不会相互影响,栈的原则也提供了适当的策略,当过程被调用时分配局部存储,返回时释放局部存储。
x86-64:将IA32扩展到64位
-
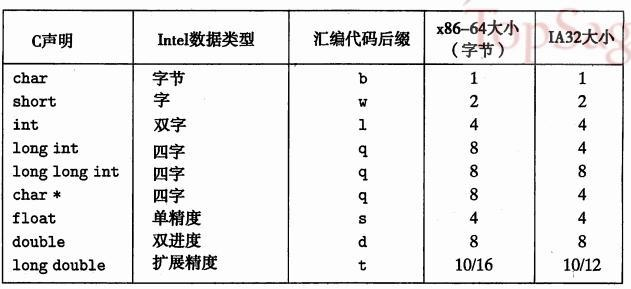
数据类型的比较:
-
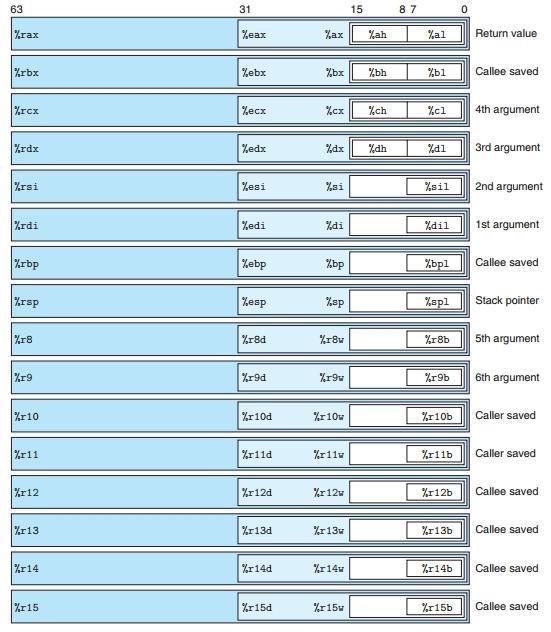
访问信息:
-
算术指令:当大小不同的操作数混在一起的时候,必须进行正确的扩展
-
过程
由于寄存器翻了一倍,64位中不需要栈帧来存储参数,而是直接使用寄存器
EAX、EBX、ECX、EDX、ESI、EDI、ESP、EBP 寄存器详解
4个数据寄存器(EAX、EBX、ECX和EDX)
2个变址和指针寄存器(ESI和EDI)
2个指针寄存器(ESP和EBP)
eax, ebx, ecx, edx, esi, edi, ebp, esp等都是X86 汇编语言中CPU上的通用寄存器的名称,是32位的寄存器。如果用C语言来解释,可以把这些寄存器当作变量看待。
4个数据寄存器(EAX、EBX、ECX和EDX):
-
32位CPU有4个32位的通用寄存器EAX、EBX、ECX和EDX。对低16位数据的存取,不会影响高16位的数据。这些低16位寄存器分别命名为:AX、BX、CX和DX,它和先前的CPU中的寄存器相一致。
-
4个16位寄存器又可分割成8个独立的8位寄存器(AX:AH-AL、BX:BH-BL、CX:CH-CL、DX:DH-DL),每个寄存器都有自己的名称,可独立存取。程序员可利用数据寄存器的这种“可分可合”的特性,灵活地处理字/字节的信息。
EAX 是"累加器"(accumulator), 它是很多加法乘法指令的缺省寄存器。
EBX 是"基地址"(base)寄存器, 在内存寻址时存放基地址。
ECX 是计数器(counter), 是重复(REP)前缀指令和LOOP指令的内定计数器。
EDX 则总是被用来放整数除法产生的余数。
ESI/EDI分别叫做"源/目标索引寄存器"(source/destination index),因为在很多字符串操作指令中, DS:ESI指向源串,而ES:EDI指向目标串.
EBP是"基址指针"(BASE POINTER), 它最经常被用作高级语言函数调用的"框架指针"(frame pointer).
eax,ax,al(ah)之间的关系
- eax是32位寄存器,ax是16位寄存器,al(ah)是八位寄存器。那么eax存储的数据就是ax的两倍,ax是al(ah)的两倍。
- eax可以存储的数字是DWORD(双字)ax存储的是WORD(字)AL(AH)存储的是BYTE(字节)
- 32位寄存器EAX、EBX、ECX和EDX不仅可传送数据、暂存数据保存算术逻辑运算结果,而且也可作为指针寄存器
缓冲区溢出
缓冲区溢出是指当计算机程序向缓冲区内填充的数据位数超过了缓冲区本身的容量。
eg.
#include <stdio.h>
#include <string.h>
#include <iostream>
using namespace std;
int main(int argc, char *argv[])
{
char buf[10];
strcpy(buf, argv[1]);
cout<<buf;
return 0;
}

连续输入一些字符就产生了溢出。
C语言常用的strcpy、sprintf、strcat 等函数都非常容易导致缓冲区溢出问题。
程序运行时,其内存里面一般都包含这些部分:
(1)程序参数和程序环境;
(2)程序堆栈(堆栈则比较特殊,主要是在调用函数时来保存现场,以便函数返回之后能继续运行),它通常在程序执行时增长,一般情况下,它向下朝堆增长。
(3)堆,它也在程序执行时增长,相反,它向上朝堆栈增长;
(4)BSS 段,它包含未初始化的全局可用的数据(例如,全局变量);
(5)数据段,它包含初始化的全局可用的数据(通常是全局变量);
(6)文本段,它包含只读程序代码。
BSS、数据和文本段组成静态内存:在程序运行之前这些段的大小已经固定。程序运行时虽然可以更改个别变量,但不能将数据分配到这些段中。
在栈中分配某个字节数组来保存一个字符串,但是字符串的长度超出了为数组分配的空间。C对于数组引用不进行任何边界检查,而且局部变量和状态信息,都存在栈中。这样,对越界的数组元素的写操作会破坏存储在栈中的状态信息。当程序使用这个被破坏的状态,试图重新加载寄存器或执行ret指令时,就会出现很严重的错误。
eg.
void echo()
{
char buf[8] ;
gets(buf) ;
puts(buf) ;
}
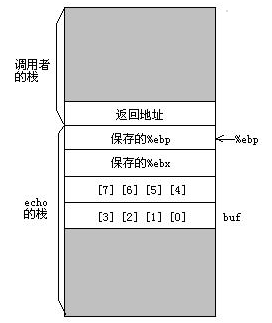
栈是向地地址增长的,数组缓冲区是向高地址增长的。故,长一些的字符串会导致gets覆盖栈上存储的某些信息。
随着字符串变长,下面的信息会被破坏:
输入的字符数量 被破坏的状态
0---7 无
8---11 保存的%ebx的值
12---15 保存的%ebp的值
16---19 返回地址
20+ caller中保存的状态
如果破坏了存储%ebp的值,那么基址寄存器就不能正确地恢复,因此调用者就不能正确地引用它的局部变量或参数。
如果破坏了存储的返回地址,那么ret指令会使程序跳转到完全意想不到的地方。
缓冲区溢出的一个更加致命的使用就是让程序执行它本来不愿意执行的函数。
输入给程序一个字符串,这个字符串包含一些可执行代码的字节编码,称为攻击代码,另外还有一些字节会用一个指向攻击代码的指针覆盖返回地址。这是一种最常见的通过计算机网络攻击系统安全的方法。执行ret指令的效果就是跳转到攻击代码。
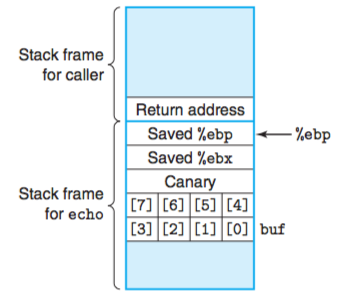
为buf分配的空间只有8个字节元素,上面地址保存的是%ebx, %ebp和返回地址的值,如果buf的长度超过分配的长度,就会把多出来的元素写入到保存这些寄存器地址的值,破坏%ebx,%ebp和返回地址的值,这样程序就不能正确的返回%ebx的值,不能正确的返回上以栈帧的地址,不能正确返回下一条要执行的命令地址。如果这些输入的元素包含一些可执行代码的字节编码,称为攻击代码(exploit code), 比如串改返回地址的值,使程序返回到恶意程序的代码地址进行执行,就会成为我们所说的蠕虫和病毒。
对抗缓冲区溢出攻击
1、栈随机化
为了在系统中插入攻击代码,攻击者不但要插入代码,还要插入指向这段代码的指针,这个指针也是攻击字符串的一部分。产生这个指针需要知道这个字符串放置的栈地址。在过去,程序的栈地址非常容易预测,在不同的机器之间,栈的位置是相当固定的。
栈随机化的思想使得栈的位置在程序每次运行时都有变化。因此,即使许多机器都运行相同的代码。它们的栈地址都是不同的。
实现的方式是:程序开始时,在栈上分配一段0--n字节之间的随机大小空间。程序不使用这段空间,但是它会导致程序每次执行时后续的栈位置发生了变化。
在Linux系统中,栈随机化已经变成了标准行为。(在linux上每次运行相同的程序,其同一局部变量的地址都不相同)
2、栈破坏检测
在C语言中,没有可靠的方法来防止对数组的越界写,但是,我们能够在发生了越界写的时候,在没有造成任何有害结果之前,尝试检测到它。
3、限制可执行代码区域
限制那些能够存放可执行代码的存储器区域。在典型的程序中,只有保存编译器产生的代码的那部分存储器才需要是可执行的,其他部分可以被限制为只允许读和写。
一般的系统允许三种访问的形式:读(从存储器读数据)、写(存储数据到存储器)和执行(将存储器的内容看作是机器级代码)
浮点数的机器级表示
为什么浮点数的表示是不精确的?(参考链接见最后)
- IEEE标准754规定了三种浮点数格式:单精度、双精度、扩展精度。
- 浮点数的表示格式:n是浮点数,s是符号位,m是尾数,e是阶数。
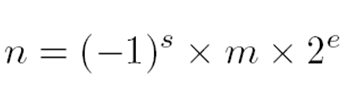
eg.单精度的20000.4
20000.4转换为单精度的2进制是多少?
此单精度浮点数是正数,那么尾数符号s=0,指数(阶数)e是8位,30到23位,尾数m(科学计数法的小数部分)23位长,22位到0位,共32位,如图

-
先看整数部分,20000先化为16进制(4e20)16,则二进制是(100 1110 0010 0000)2,一共15位。
-
再看小数部分,0.4化为二进制数,这里使用乘权值取整的计算方法,使用0.X循环乘2,每次取整数部分,但是我们发现,无论如何x2,都很难使得0.X为0.0,就相当于十进制的无限循环小数0.33333……一样,10进制数,无法精确的表达三分之一。也就是人们说的所谓的浮点数精度问题。因单精度浮点数的尾数规定长23位,那现在乘下去,凑够24位为止,即再续9位是(1.011001100)2
习题
3.59
假设
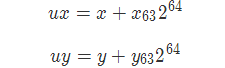
多个2 ^ 128溢出
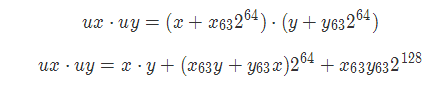
# void store_prod(int128_t* dest, int64_t x, int64_t y)
# dest in %rdi, x in %rsi, y in %rdx
store_prod:
movq %rdx, %rax # %rax = y
cqto # (int128_t)y, %rdx = (-1)y_63
movq %rsi, %rcx # %rcx = x
# x >> 63, if x == 1, %rcx = -1; if x_63 == 0, %rcx = 0
# %rcx = (-1)x_63
sarq $63, %rcx
# pay attention, imulq behaves differently according to param number(1/2)
imulq %rax, %rcx # %rcx = y * -x_63
imulq %rsi, %rdx # %rdx = x * -y_63
addq %rdx, %rcx # %rcx = x * -y_63 + y * -x_63
mulq %rsi # %rdx:%rax <= ux * uy
# lower 64 bits are same for x * y and ux * uy. ref (2.18) on book
# %rdx = ux * uy(high 64 bits) - (x_{63}y + y_{63}x)2^{64}
addq %rcx, %rdx
movq %rax, (%rdi) # set lower 64bits
movq %rdx, 8(%rdi) # set higher 64bits
ret
3.60
答:
A:
%rdi中保存着x
%esi中保存着n
%rax中保存着result
%rdx中保存着mask
B:result和mask的初始值是:
result = 0
mask = 1
C:mask的测试条件是:mask != 0
D:mask = mask << n
F:
long loop2(long x, int n) {
long result = 0;
long mask;
for (mask = 1; mask != 0; mask <<= n) {
result |= (x & mask);
}
return result;
}
代码托管
上周考试错题总结
14.( 多选题 | 1 分)
The following table gives the parameters for a number of different caches. For
each cache, determine the number of cache sets (S), tag bits (t), set index bits (s),
and block offset bits (b)

A .
第三行S为1
B .
第一行t为24
C .
第二行s为5
D .
第三行b的值为5
正确答案: A C D
18.( 多选题 | 1 分)
有关RAM的说法,正确的是()
A .
SRAM和DRAM掉电后均无法保存里面的内容。
B .
DRAM将一个bit存在一个双稳态的存储单元中
C .
一般来说,SRAM比DRAM快
D .
SRAM常用来作高速缓存
E .
DRAM将每一个bit存储为对一个电容充电
F .
SRAM需要不断刷新
G .
DRAM被组织为二维数组而不是线性数组
正确答案:A C D E G
解析:SRAM用来作为高速缓存存储器;DRAM用来作为主存以及图形系统的帧缓冲区。SRAM的存取比DRAM快。SRAM对诸如光和电噪声这样的干扰不敏感。代价是SRAM 单元比DRAM单元使用更多的晶体管。
结对及互评
点评模板:
- 博客中值得学习的或问题:
-
- 代码中值得学习的或问题:
-
本周结对学习情况
- [20155225]()
- 结对照片
- 结对学习内容
- 相互讲解学习的章节
其他(感悟、思考等,可选)
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 15篇 | 400小时 | |
| 第一周 | 20/20 | 1/ | 12/12 | |
| 第二周 | 42/62 | 1/2 | 8/20 | |
| 第三周 | 62/124 | 1/3 | 14/34 | |
| 第四周 | 61/185 | 1/4 | 10/44 | |
| 第五周 | / | 2/6 | 13/57 | |
| 第六周 | / | 2/8 | 17/74 | |
| 第七周 | / | 2/10 | 15/89 | |
| 第八周 | / | 2/12 | 12/101 | |
| 第九周 | / | 2/14 | 10/111 | |
| 第十一周 | / | 1/16 | 12/123 | |
| 第十三周 | / | 2/18 | 17/140 | 学习认为最重要的一章 |
| 第十四周 | / | 1/19 | 18/158 | 学习认为学的不好的一章 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:18小时
-
实际学习时间:18小时
-
改进情况:深入学习第三章
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)