机器学习算法有很多种方法,用于纯数据驱动的预测方法。既然你已经完成了机器学习课程,
我们不会深入研究这些技术。但在这个视频中,我想向您展示一个具有代表性的例子,这些算法擅长什么 - 轨迹聚类。
与所有数据驱动的预测技术一样,会有两个阶段。算法从数据中学习模型的离线训练阶段和在线预测阶段,
它使用该模型来生成预测。我们先来讨论一下离线人脸。
第一步是获取大量的数据,可能会通过在相交处放置静态相机来实现。然后,我们必须清理数据,因为我们有些汽车
在处理步骤中观察可能被遮挡或出现其他问题。所以我们需要丢弃不好的数据。
一旦数据收集和清理完毕,我们会留下一堆看起来像这样的轨迹。

接下来,我们需要定义一些数学测度轨迹相似性,有很多方法可以做到这一点,但直观上我们想要的
说这样一个红色的轨迹更多,类似粉红色的这一个,而不是蓝色的这个,尽管它们是红色和蓝色的轨迹重叠
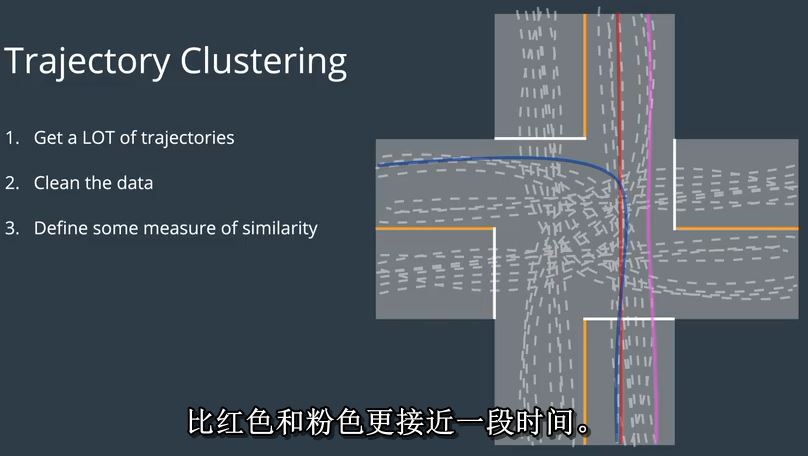
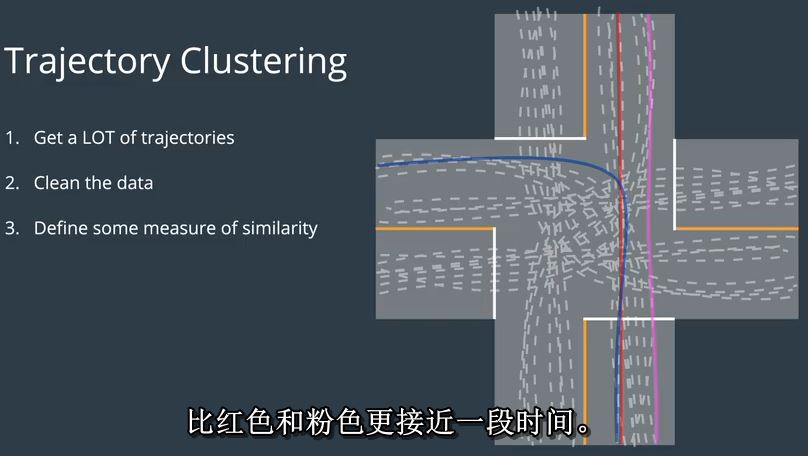
比红色和粉色更接近一段时间。如果您有兴趣了解更多信息,我将包括一篇论文的链接,详细讨论相似度度量,
但是一旦我们有了相似性度量,我们就可以使用机器学习算法如凝聚聚类或谱聚类聚类这些轨迹。
在四路站点交叉路口的情况下,我们预计会看到12个集群,因为每个集群都是这样四个停车标志车可以做三件事之一:右转,
直行或向左转。所以如果我们只看四个停车标志中的一个,我们期望看到左转弯的一组轨迹,直行,然后右转。
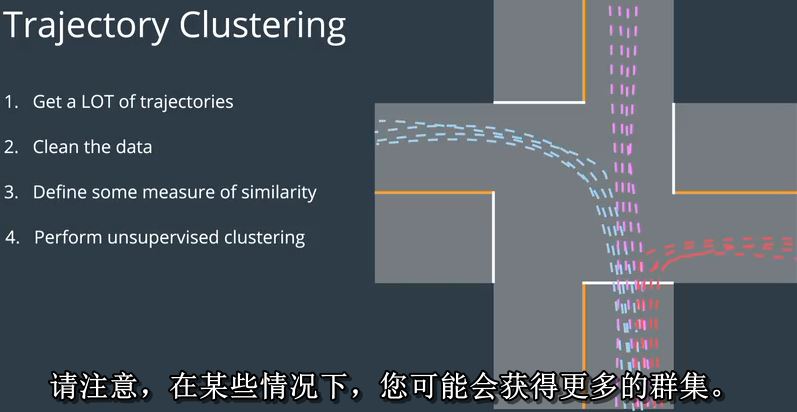
请注意,在某些情况下,您可能会获得更多的群集。例如,如果该车道由交通灯控制而不是停车,
您的群集算法可能会创建两倍的群集。其中三人没有穿过路口停下来,其中三人首先停在红绿灯处。
一旦轨迹被分组为簇,定义每个集群的原型轨迹是非常有用的。
对于左转集群,也许这三个轨迹是一个很好的模型。

它们提供了一个紧凑的表示左转通常看起来像在这个交叉点。在这一点上,我们有一个典型的汽车行为在这个交叉点的训练模型。
下一步是在道路上使用此模型来实际生成预测。