一、Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中
Scrapy最初是为页面抓取而设计的,也可以应用在获取API所返回的数据,或者通用的网络爬虫
二、使用Scrapy抓取一个网站一共需要4个步骤:
1、创建一个Scrapy项目
2、定义Item容器
3、编写爬虫
4、存储内容
三、Scrapy框架
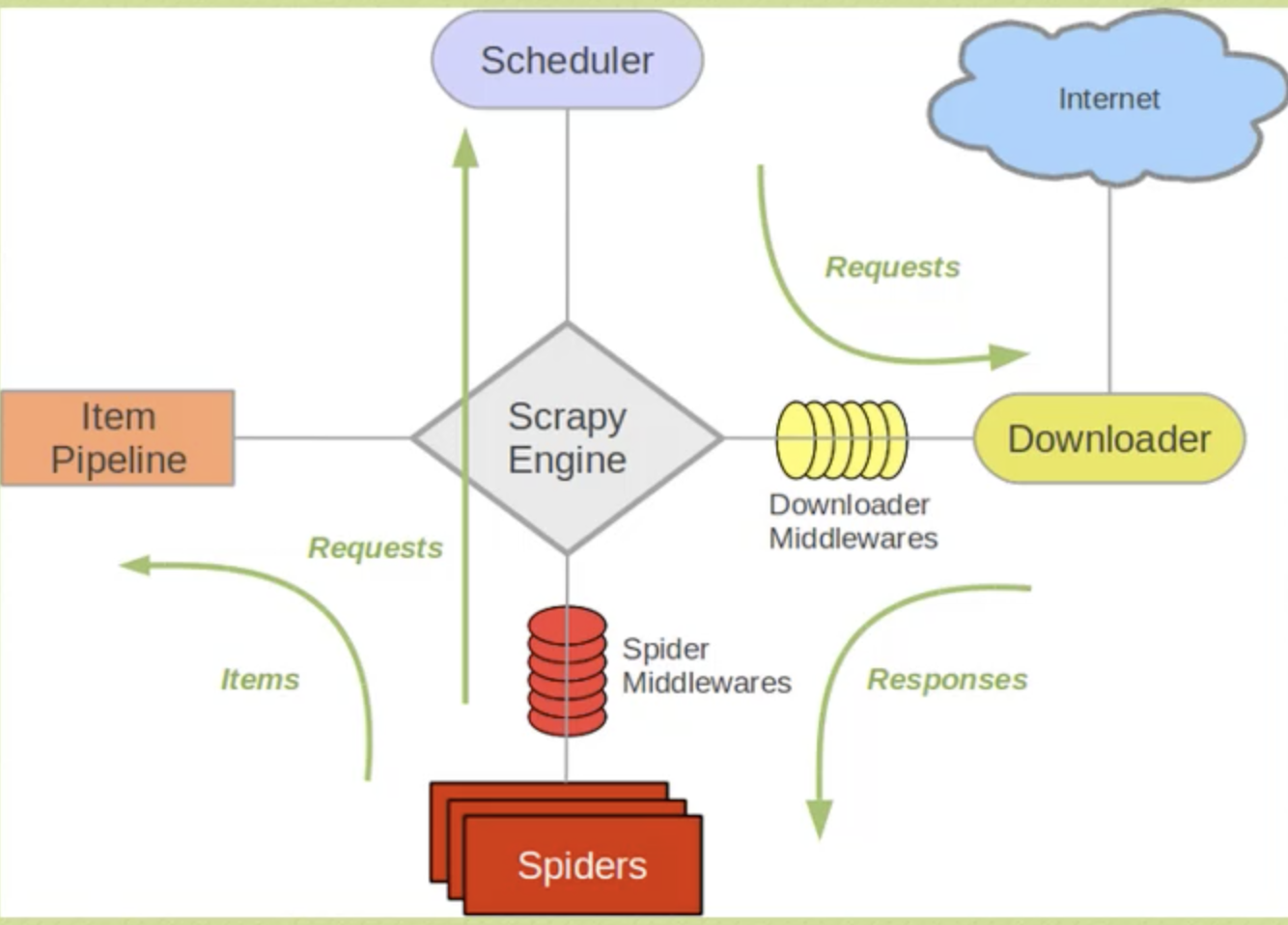
四、安装scrapy并创建scrapy框架
参考文档:https://blog.csdn.net/qijingpei/article/details/70194251
步骤1:安装Anaconda,在cmd窗口输入:conda install scrapy ,输入y回车表示允许安装依赖库
步骤2:测试scrapy是否安装成功,在dos窗口输入scrapy回车
步骤3:在Pycharm-->file-->settings-->搜索project interpreter(项目解释器)-->选择Anaconda3的python.exe --〉点击“OK”,千万不要点apply,可能会让你更新一大堆东西
步骤4:在pycharm中输入import scrapy ,如果不报错,应该就是可以用了
步骤5:在pycharm的终端输入:scrapy startproject module”,其中module为模块名
步骤6:创建后,在终端可以看到创建的module路径:如:/用户/wufq/module
步骤7:用pycharm打开此路径下的文件夹:module,这样在pycharm里面就可以看到scrapy的框架
步骤8:框架如下:
1)scrapy.cfg 框架的基本设置
2)settings.py 用户的相关设置
3)spiders 用户自己实现的spider文件夹
4)items.py 数据条目(保存爬取到的数据的容器,其使用方法和python字典类似,并且提供了额外的保护机制来避免拼写错误导致的未定义字段错误)
5)pipelines 管道
五、爬虫代码编写
1、首先对希望获取的数据进行建模:网站的名字,网站的超链接,网站的描述。即在items.py里面进行编写
#items.py里面编写 # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ModuleItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() #建模(爬取)的网站标题 link= scrapy.Field() #连接地址 desc = scrapy.Field() #网站描述
2、编写爬虫,在spider里面写(Spider是用户编写用于从网站上爬取数据的类。其包含了一个用于下载的初始URL,然后是如何跟进网页中的连接以及如何分析页面中的内容,还有提取item的方法)