关系型数据库
关系型数据库是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。简单说,关系型数据库是由多张能互相连接的表组成的数据库。
优点
- 都是使用表结构,格式一致,易于维护。
- 使用通用的 SQL 语言操作,使用方便,可用于复杂查询。
- 数据存储在磁盘中,安全。
缺点
- 读写性能比较差,不能满足海量数据的高效率读写。
- 不节省空间。因为建立在关系模型上,就要遵循某些规则,比如数据中某字段值即使为空仍要分配空间。
- 固定的表结构,灵活度较低。
常见的关系型数据库有 Oracle、DB2、PostgreSQL、Microsoft SQL Server、Microsoft Access 和 MySQL 等。
非关系型数据库
非关系型数据库又被称为 NoSQL(Not Only SQL ),意为不仅仅是 SQL(以前是叫做Not SQL,但后面妥协了)。通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定。
优点
- 非关系型数据库存储数据的格式可以是 key-value 形式、文档形式、图片形式等。使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
- 速度快,效率高。 NoSQL 可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘。
- 海量数据的维护和处理非常轻松。
- 非关系型数据库具有扩展简单、高并发、高稳定性、成本低廉的优势。
- 可以实现数据的分布式处理。
缺点
- 非关系型数据库暂时不提供 SQL 支持,学习和使用成本较高。
- 非关系数据库没有事务处理,没有保证数据的完整性和安全性。适合处理海量数据,但是不一定安全。
- 功能没有关系型数据库完善。
常见的非关系型数据库有 Neo4j、MongoDB、Redis、Memcached、MemcacheDB 和 HBase 等。
1 操作数据库
1.1 操作数据库(了解)
1、 创建数据库
CREATE DATABASE [IF NOT EXISTS] weston;
2、删除数据库
DROP DATABASE [IF EXISTS] weston;
3、使用数据库
USE weston;
4、查看数据库
SHOW DATABASES; --查看所有的数据库
1.2 数据库的列数据类型
数值
- tinyint 十分小的数据 1个字节
- smallint 较小的字节 2个字节
- mediumint 中等大小的数据 3个字节
- int 标准的整数 4个字节 常用,对应Java里的int类型
- bigint 较大的数据 8个字节 对应Java里的long类型
- float 浮点数 4个字节
- double 浮点数 8个字节(精度问题!)
- decimal 字符串类型的浮点数 金融计算的时候,一般是使用decimal
字符串
- char 字符串 0~255
- varchar 可变字符串 0~65535 常用的,对应Java里的String类型
- tinytext 微型文本 2^8 - 1 差不多可以写一篇博客
- text 文本串 2^16 - 1 保存大文本
时间日期,对应Java里的java.util.Date
- date YY-MM-DD 日期格式
- time HH:mm:ss 时间格式
- datetime YY-MM-DD HH:mm:ss 日期时间 最常用的时间格式
- timestamp 1970.1.1到现在的毫秒数 时间戳
- year 年份表示
null
- 没有值,未知
- 注意,不要使用NULL进行运算,结果为NULL
1.3 数据库的字段属性(重点)
- Unsigned
- 声明该字段为无符号的整数
- 声明了该列不能为负数
- zerofill
- 0填充的
- 不足的位数,使用0来填充。如
int(3)。5则为005
- 自增
- 通常理解为自增,自动在上一条记录的基础上 + 1(默认)
- 通常用来设计唯一的主键,必须是整数类型
- 可以自动以设置主键自增的起始值和步长
- 非空 NULL not NULL
- 假设设置为not null,如果不给该字段赋值,就会报错
- NULL,如果不填写值,默认就是null
- 默认
- 设置默认的值
拓展
/* 每一个表,都必须存在以下5个字段,未来做项目用的,表示一个记录存在意义
id 主键
version 乐观锁
is_delete 伪删除
gmt_create 创建时间
gmt_update 修改时间
*/
1.4 创建一个表
-- 格式
CREATE TABLE [IF NOT EXISTS] `表名`(
`字段名` 字段数据类型 [属性] [索引] [字段注释],
`字段名` 字段数据类型 [属性] [索引] [字段注释],
`字段名` 字段数据类型 [属性] [索引] [字段注释],
......
`字段名` 字段数据类型 [属性] [索引] [字段注释]
)[表引擎类型] [字符集类型] [表注释]
1.4.1 创建表举例
-- 所有字符使用单引号括起来!
-- 所有的语句后面加,(英文的),最后一个不加,
CREATE TABLE IF NOT EXISTS `student`(
-- id为自动填充4位的整型,非空,自增,注释为学号
`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',
-- name为100长度的字符串,非空,默认为'匿名',注释为姓名
`name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',
`pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码',
`sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别',
`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',
`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址',
`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`)
)ENGINE = INNODB DEFAULT CHARSET = utf8
1.4.2 查看创建表语句
-- 查看创建表语句
SHOW CREATE TABLE `student`;
-- 查询结果如下
CREATE TABLE `student` (
`id` int(4) NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` varchar(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',
`pwd` varchar(20) NOT NULL DEFAULT '123456' COMMENT '密码',
`sex` varchar(2) NOT NULL DEFAULT '女' COMMENT '性别',
`birthday` datetime DEFAULT NULL COMMENT '出生日期',
`address` varchar(100) DEFAULT NULL COMMENT '家庭住址',
`email` varchar(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
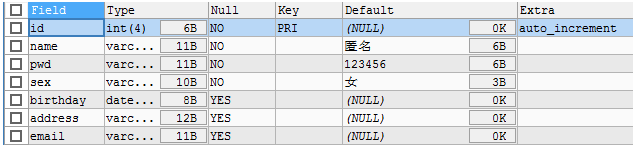
1.4.3 查看表结构
-- 查看表结构
DESC `student`;
-- 查询结果如下
1.5 数据表的类型
1.5.1 数据表的引擎类型
- INNODB 默认使用的引擎
- MYISAM 早期使用的引擎
| MYISAM | INNODB | |
|---|---|---|
| 是否支持事务 | 不支持 | 支持 |
| 数据行锁 | 不支持(只支持表锁) | 支持 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间的大小 | 较小 | 较大,约为MYISAM的两倍 |
常规使用操作:
- MYISAM:节约空间,速度较快
- INNODB:安全性高,事务的处理,夺标多用户操作
在物理空间存在的位置。所有的数据库文件都存在于data文件夹下,一个文件夹就对应一个数据库,本质还是文件的存储。
- InnoDB在数据库表中只有一个*.frm文件,以及上级目录下的ibdata1文件
- MYISAM
- *.frm 表结构的定义文件
- *.MYD 数据文件(data)
- *.MYI 索引文件(index)
1.5.2 数据表的字符集编码
CHARSET = utf8
如果不设置字符集编码的话,表会使用mysql的默认字符集编码Latin1(不支持中文)
还可以在my.ini配置文件中加上一个全局的字符集编码配置:
character-set-server = utf8
1.6 修改表
-- 修改表明
ALTER TABLE `student` RENAME AS `student1`;
-- 增加表的字段
ALTER TABLE `student` ADD `phone` INT(11) ...;
-- 修改表的字段(重命名,修改约束)
ALTER TABLE `student` MODIFY `phone` VARCHAR(10) -- 修改约束(MODIFY不能重命名)
ALTER TABLE `student` CHANGE `phone` `phone1` -- 重命名字段(CHANGE还可以MODIFY,即修改约束)
-- 删除表的字段
ALTER TABLE `student` DROP `phone`
-- 删除表
DROP TABLE IF EXISTS `student`;
2 MySQL数据管理
2.1 外键
-- 首先创建年级表
CREATE TABLE IF NOT EXISTS `grade`(
`gradeid` INT(10) NOT NULL AUTO_INCREMENT COMMENT '年级id',
`gradename` VARCHAR(50) NOT NULL COMMENT '年级名称',
PRIMARY KEY(`gradeid`)
)ENGINE = INNODB DEFAULT CHARSET = utf8
-- 然后再创建学生表
CREATE TABLE `student` (
`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',
`pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码',
`sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别',
`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',
`gradeid` INT(10) NOT NULL COMMENT '年级id',
`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址',
`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',
-- 下面三步创建外键
PRIMARY KEY (`id`),
KEY `FK_gradeid` (gradeid),
CONSTRAINT `FK_grade` FOREIGN KEY (`gradeid`) REFERENCES `grade`(`gradeid`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
-- 也可以创建表之后建立外键
ALTER TABLE `student` ADD CONSTRAINT `FK_grade` FOREIGN KEY(`gradeid`) REFERENCES `grade`(`gradeid`);
以上的操作都是物理外键,数据库级别的外键,我们不建议使用!(避免数据库过多造成困扰,所以外键的功能了解即可)
最佳实践
- 数据库就是单纯的数据表,只用来存数据,只有行(数据)和列(字段)
- 我们想使用多张表的数据,即想使用外键的功能,我们就通过程序(代码)去实现。
2.2 添加数据
INSERT INTO `表名` (`字段1`, `字段2`, `字段3`...) VALUES ('值1','值2','值3'...);
-- 一般写插入语句,我们一定要数据和字段一一对应
INSERT INTO `student` (`age`, `name`, `sex`) VALUES(21, '小曾', '男');
-- 一次性插入多行
INSERT INTO `grade` (`gradename`) VALUES('大三'), ('大四');
注意事项:
- 字段和字段之间使用英文逗号隔开
- 字段是可以省略的,但是后面的值必须要一一对应,不能少
- 可以同时插入多行数据,VALUES后面的值,需要使用,隔开即可,即使用VALUES (), (), ()
2.3 修改数据
-- 如果不加WHERE限制,那么默认会SET所有的行
UPDATE TABLE `student` SET `name` = '小曾' WHERE `id` = 1;
2.4 删除数据
-- 删除一行,同理,如果不加WHERE限制,那么默认会删除所有的行
DELETE FROM TABLE `student` WHERE 1 = 1;
-- TRUNCATE直接删除整个数据表,然后新建一个空的。自增清零,也就是从0开始重新自增
TRUNCATE TABLE `student`;
3 DQL查询数据(最重要)
3.1 SELECT查询
SELECT语法
SELECT [ALL | DISTINCT]
{* | table.* | [table.filed[as alias1][, table.field2 [as alias2]][, ......]]}
FROM table_name [as table_alias]
[LEFT | RIGHT | INNER JOIN table_name2] -- 联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照哪个字段分组(比如查询每个课程的平均分、最高分、最低分时)
[HAVING ...] -- 和GROUP BY连用,过滤分组的记录需满足的条件
[ORDER BY ...] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
-- 指定查询的记录从哪条至哪条(一般用于查询前x个,或者分页)
3.1.1 条件查询
SELECT * FROM `student` WHERE 1 = 1;
3.1.2 模糊查询
- LIKE
- %可以匹配0个或者任意多个任意字符
- _匹配一个任意字符
- IS NULL,为NULL则返回TRUE
- IS NOT NULL,不为NUL则返回TRUE
3.2 左右内连接查询
- 内连接求交集:INNER JOIN
- 左连接,以左表为准,右表没有则为NULL:LEFT JOIN
- 右连接,以右表为准,左表没有则为NULL:RIGHT JOIN
3.3 自连接查询
自己的表和自己的表连接
SELECT f.`gradename`, s.`gradename` FROM `grade`, `grade`;
3.4 分页和排序
3.4.1 分页LIMIT
- 为什么要分页?
- 缓解数据库压力,给人的体验更好
-- MySQL语法:LIMIT 起始值, 页面大小
-- LIMIT 0, 5 表示1 ~ 5行数据
-- LIMIT 1, 5 表示2 ~ 6行数据
-- LIMIT 5, 5 表示6 ~ 10行数据(如果5行一页的话,其实就是第二页)
-- 网页的做法:当前页、总的页数、每一页的大小,可以在MySQL中如下计算
-- 第一页 LIMIT 0,5 (1-1)*5
-- 第二页 LIMIT 5,5 (2-1)*5
-- 第三页 LIMIT 10,5 (3-1)*5
-- ......
-- 第N页 LIMIT (N-1)*pageSize
-- 【pageSize: 页面大小】
-- 【(N-1)*pageSize:起始值】
-- 【N:当前页】
-- 【数据总数 / 页面大小 = 总页数】
3.4.2 排序ORDER BY
-- 升序
ORDER BY `字段` ASC;
-- 降序
ORDER BY `字段` DESC;
思考题
查询 Java第一学年 课程成绩排名前十的学生,并且分数要大于80的学生信息(学号,姓名,课程成绩,分数)
SELECT s.`StudentNo`, `StudentName`, `SubjectName`, `StudentResult`
FROM `student` AS s
INNER JOIN `result` AS r
ON s.StudentNo = r.StudentNo
INNER JOIN `subject` AS sub
ON r.`SubjectNo` = sub.`SubjectNo`
WHERE SubjectName = 'Java第一学年' AND StudentResult >= 80
ORDER BY StudentReslut DESC
-- 下面筛选出成绩排名前十的同学
LIMIT 0, 10;
3.5 子查询
问题:查询 数据库结构-1 的所有考试结果(学号、科目编号、成绩),降序排列
-- 方式一:使用内连接查询
SELECT `StudentNo`, r.`SubjectNo`, `StudentResult`
FROM `result` AS r
INNER JOIN `subject`AS sub
ON r.SubjectNo = sub.subjectNo
WHERE SubjectName = '数据库结构-1'
ORDER BY StudentResult DESC;
-- 方式二:使用子查询(由里到外查询)
SELECT `StudentNo`, r.`SubjectNo`, `StudentResult`
FROM result
WHERE SubjectNo = (
SELECT SubjectNo FROM `subject`
WHERE SubjectName = '数据库结构-1'
)
分数不小于80分的学号和姓名
SELECT DISTINCT `StudentNo`, `StudentName`
FROM student AS s
INNER JOIN result AS r
ON s.StudentNo = r.StudentNo
WHERE r.`StudentResult` >= 80;
-- 在这个基础上增加一个科目,高等数学-2
SELECT DISTINCT `StudentNo`, `StudentName`
FROM student AS s
INNER JOIN result AS r
ON s.StudentNo = r.StudentNo
WHERE r.`StudentResult` >= 80 AND r.`SubjectNo` = (
SELECT `SubjectNo` FROM subject WHERE `SubjectName` = '高等数学-2'
)
3.6 分组和过滤
- GROUP BY 用于分组
- HAVING 用于分组后过滤
-- 查询不同课程的平均分,最高分,最低分
-- 核心难点:根据不同的课程分组
SELECT `SubjectName`, AVG(StudentResult) AS 平均分, MAX(StudentResult) AS 最高分, MIN(StudentResult) AS 最低分
FROM result AS r
INNER JOIN `subject` AS sub
ON r.`SubjectNo` = sub.`SubjectNo`
-- 通过什么字段来分组
GROUP BY r.`SubjectNo`
HAVING 平均分 > 80;
4 MySQL函数
4.1 常用函数
-- 数学运算
SELECT ABS(-8)
-- 向上取整
SELECT CEILING(9.4)
-- 向下取整
SELECT FLOOR(9.4)
-- 随机数,返回一个0~1之间的随机数
SELECT RAND()
-- 判断一个数的符号
SELECT SIGN()
-- 字符串函数
-- 字符串长度
SELECT CHAR_LENGTH()
-- 字符串拼接
SELECT CONCAT('我', '爱', '你们')
-- 插入字符串
SELECT INSERT()
-- 转小写
SELECT LOWER()
-- 转大写
SELECT UPPER()
-- 时间和日期函数(记住)
SELECT CURRENT_DATE()
SELECT CURDATE()
SELECT NOW()
SELECT LOCALTIME()
SELECT SYSDATE()
-- 系统函数
SELECT SYSTEM_USER() -- 当前用户
SELECT USER()
SELECT VERSION
4.2 聚合函数(常用)
| 函数名称 | 描述 |
|---|---|
| COUNT() | 计数 |
| SUM() | 求和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| ... | ... |
-- 聚合函数
-- 以下三种都能统计出表的行数,后两者其实是没区别的
SELECT COUNT(studentname) FROM student -- 指定列(会忽略所有的NULL值)
SELECT COUNT(*) FROM student -- *,不会忽略所有的NULL值
SELECT COUNT(1) FROM student -- 1,不会忽略所有的NULL值
-- 求和等
SELECT SUM(`StudentResult`) AS 总和 FROM result
SELECT AVG(`StudentResult`) AS 平均分 FROM result
SELECT MAX(`StudentResult`) AS 最高分 FROM result
SELECT MIN(`StudentResult`) AS 最低分 FROM result
思考题(重要,GROUP BY出现)
查询不同课程的平均分,最高分,最低分,且平均分大于80分
-- 查询不同课程的平均分,最高分,最低分
-- 核心难点:根据不同的课程分组
SELECT `SubjectName`, AVG(StudentResult) AS 平均分, MAX(StudentResult) AS 最高分, MIN(StudentResult) AS 最低分
FROM result AS r
INNER JOIN `subject` AS sub
ON r.`SubjectNo` = sub.`SubjectNo`
-- 通过什么字段来分组
GROUP BY r.`SubjectNo`
HAVING 平均分 > 80;
4.3 数据库级别的MD5加密(扩展)
-
加密算法(哈希算法)
-
不可逆
CREATE TABLE `testmd5`(
`id` INT(4) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) NOT NULL,
`pwd` VARCHAR(50) NOT NULL,
PRIMARY KEY(`id`)
)ENGINE = INNODB DEFAULT CHARSET = utf8
-- 明文密码
INSERT INTO `testmd5` VALUES(1, 'zhangsan', '123456'),(2, 'lisi', '123456'),(3, 'wangwu', '123456');
-- 加密
UPDATE `testmd5` SET `pwd` = MD5(pwd) WHERE 1 = 1;
-- 我们应该是在插入的时候加密
INSERT INTO `testmd5` VALUES(4, 'laowang', MD5('123456'));
-- 如何校验(判断密码是否正确)?
-- 将用户传递进来的密码进行MD5加密,然后比对加密后的值是否相等
SELECT * FROM `testmd5` WHERE name = 'wangwu' AND pwd = MD5('123456');
5 MySQL事务
什么是事务?两个或多个事务,要么全成功,要么全失败
将一组SQL放在一个批次中去执行
思考题
A余额1000元,B余额200元,A打算给B转账200元。
- SQL执行:A给B转账(A扣200元)
- SQL执行:B收到A的转账(B加200元)
事务原则:ACID,即原子性、一致性、隔离性、持久性
参考博客连接:https://blog.csdn.net/dengjili/article/details/82468576
- 原子性(Atomicity):AB转账,加减操作都要一起执行,或者一起不执行
- 一致性(Consistency):AB转账前的和为1200元,转账之后的和也应该为1200元
- 持久性(Isolation):事务没有提交,则数据恢复到原状;事务已提交,数据持久化到数据库。即事务一旦提交则不可逆
- 隔离性(Durability):A在给B转账,此时C也在给B转账,那么这两个事务互相不会影响
- 事务隔离可能引发的问题
- 脏读:一个事务读取了另外一个事务未提交的数据
- 丢失修改:B事务读取了A事务还未提交的数据
- 不可重复读:在一个事务内读取表中某一行数据,多次读取结果不同
- 幻读:一个事务内读取到了别的事务插入的数据,多次读取结果不同
- 事务的隔离级别
- 读取未提交:可能会导致脏读、幻读或不可重复读
- 读取已提交:可以阻止脏读,但是幻读或不可重复读仍有可能发生
- 可重复读(InnoDB引擎默认级别):可以阻止脏读和不可重复读,但幻读仍有可能发生
- 可串行化:该级别可以防止脏读、不可重复读以及幻读
- 事务隔离可能引发的问题
执行事务
-- MySQL是默认开启事务自动提交的
SET autocommit = 0 -- 关闭事务自动提交
SET autocommit = 1 -- 开启事务自动提交(默认)
-- 手动处理事务
SET autocommit = 0
-- 事务开启
START TRANSACTION
INSERT INTO
-- 提交(表示成功,持久化到数据库文件)
COMMIT
-- 回滚(表示失败回滚到原来的样子)
ROLLBACK
-- 事务结束(还原默认值)
SET autocommit = 1
SAVEPOINT '保存点名称' -- 设置一个事务的保存点,方便事务回滚
RELEASE SAVEPOINT '保存点名称' -- 删除保存点
ROLLBACK TO SAVEPOINT '保存点名称' -- 回滚到保存点
模拟转账事务
-- 创建数据库shop
CREATE DATABASE shop CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 使用数据库
USE shop;
-- 创建表
CREATE TABLE `account`(
`id` INT(4) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) NOT NULL,
`money` DECIMAL(9,2) NOT NULL,
PRIMARY KEY (`id`)
)ENGINE = INNODB DEFAULT CHARSET = utf8
-- 插入一些数据
INSERT INTO `account` (`name`, `money`)
VALUES('A', 2000.00), ('B', 10000.00);
-- 模拟转账
SET autocommit = 0;
START TRANSACTION; -- 开启一个事务(一组事务)
UPDATE account SET money = money - 500 WHERE `name` = 'A'; -- A减500元
UPDATE account SET money = money + 500 WHERE `name` = 'B'; -- B加500元
-- 提交事务(提交之后就被持久化了,无法回滚)
COMMIT;
-- 事务回滚
ROLLBACK;
SET autocommit = 1;
6 索引
MySQL官方对索引的定义:索引(Index)是帮助MySQL高效获取数据的数据结构。
提取句子主干,就可以得到索引的本质:索引是数据结构
6.1 索引的分类
在一个表中,主键索引只能有一个,而唯一索引可以有多个。
- 主键索引:PRIMARY KEY
- 唯一标识,主键不可重复,只能有一个列作为主键
- 唯一索引:UNIQUE KEY
- 避免重复的列出现(比如两行数据的name相同),唯一索引可以重复,也就是多个列都可以标识为唯一索引
- 常规索引:KEY/INDEX
- 默认的,INDEX或者KEY关键字来设置
- 全文索引:FULLTEXT
- 在特定的数据库引擎下才有,比如MYISAM
-- 索引的使用
-- 在创建表的时候给字段增加索引
-- 创建表之后,增加索引
ALTER TABLE `student` ADD FULLTEXT INDEX `studentName` (`studentName`);
-- 创建表之后,增加索引
CREATE INDEX 索引名 ON 表(字段)
CREATE INDEX id_app_user_name ON app_user(`name`);
-- EXPLAIN 分析SQL执行的状况
EXPLAIN SELECT * FROM student; -- 非全文索引
EXPLAIN SELECT * FROM student WHERE MATCH(studentName) AGAINST('刘');
6.2 测试索引
-- 插入100万条数据
-- 创建一个函数来插入
DELIMITER $$; -- 写函数之前必写
CREATE FUNCTION mock_data()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i < num DO
-- 插入语句
INSERT INTO `app_user` (`name`, `email`, `gender`, `pwd`, `age`)
VALUES(CONCAT('用户',i), '448751172@qq.com', CONCAT('18', FLOOR(RAND()*((99999999-10000000)+100000000))), 1, UUID(), 23);
SET i = i + 1;
END WHILE
RETURN i;
END;
-- 最后调用函数
SELECT mock_data();
-- 数据有了,开始测试
SELECT * FROM `app_user` WHERE `name` = '用户9999'; -- 0.993sec
SELECT * FROM `app_user` WHERE `name` = '用户9999'; -- 1.098sec
-- 查看SQL执行情况
EXPLAIN SELECT * FROM `app_user` WHERE `name` = '用户9999'; -- 发现结果中的row字段等于991749,说明找了991749行才找到
-- 然后我们创建一个索引来对比一下
CREATE INDEX id_app_user_name ON app_user(`name`);
-- 然后我们再查一下建立索引之后的查询时间
SELECT * FROM `app_user` WHERE `name` = '用户9999'; -- 0.001sec
-- 查看SQL执行情况
EXPLAIN SELECT * FROM `app_user` WHERE `name` = '用户9999'; -- 发现结果中的row字段等于1,说明只找了1行就找到了
6.3 索引原则
- 索引不是越多越好
- 不要对经常变动的数据加索引
- 小数据量的表不需要加索引
- 索引一般加数据量大的,常用来查询的字段上
索引总结
- 没建索引,基本上就是一行一行地遍历查询,复杂度O(n)
- 建立索引,就先根据索引值查到数据行的地址,然后根据地址定位出一行数据,复杂度O(1)
- 索引在小数据量的时候,区别不大,但是在大数据的查询的时候,优化就很明显了
7 权限管理和备份
7.1 用户管理
7.2 MySQL备份
为什么要备份?
- 保证重要的数据不丢失
- 数据转移
MySQL数据库备份的方式
- 直接拷贝物理文件(data文件夹)
- 在可视化工具比如SQLyog中导出sql
- 使用mysqldump命令行导出
8 规范地设计数据库
9 三大范式
第一范式
原子性:保证每一列不可再分
第二范式
前提:满足第一范式的前提下,每张表只描述一件事情
第二范式需要确保数据表中的每一列数据都和主键相关
第三范式
前提:满足第一范式、第二范式
第三范式需要确保数据表中的每一列数据都和主键直接相关,不能间接相关
规范性和性能的问题
关键的表不能超过三张
- 考虑商业化的需求和目标,数据库的性能更加重要
- 在规范性能的问题时,需要适当的考虑一下规范性
- 有时我们会故意给某些表增加一些冗余的字段(从多表查询变为单表查询)
- 有时我们会故意增加一些计算列(从大数据量降低为小数据量的查询:索引)
10 JDBC(重点)
10.1 数据库驱动
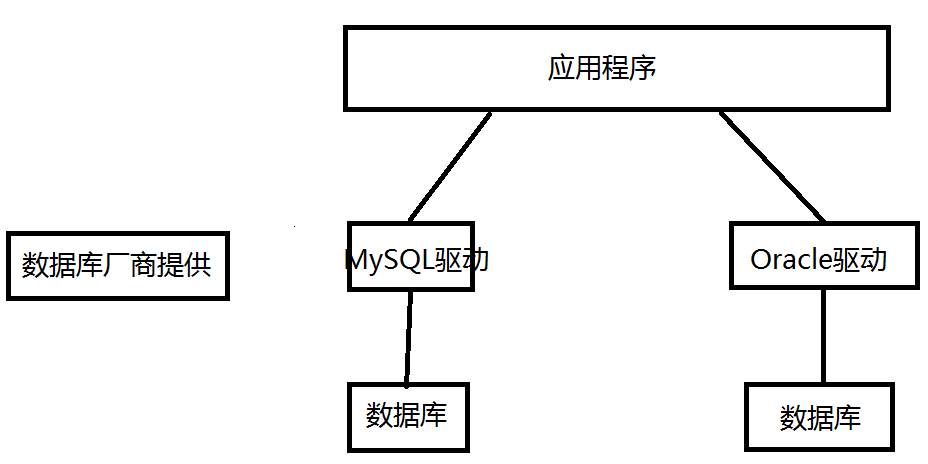
我们的程序会通过数据库驱动,和数据库打交道!
10.2 JDBC的引入
Sun公司为了简化开发人员的(对数据库的统一)操作,提供了一套(Java操作数据库的)规范,俗称JDBC。
这些规范的实现由具体的厂商去做,比如MySQL驱动的由MySQL的厂商去实现,Oracle驱动由Oracle厂商去实现。
对于开发人员来说,我们只需要掌握JDBC的操作规范即可。
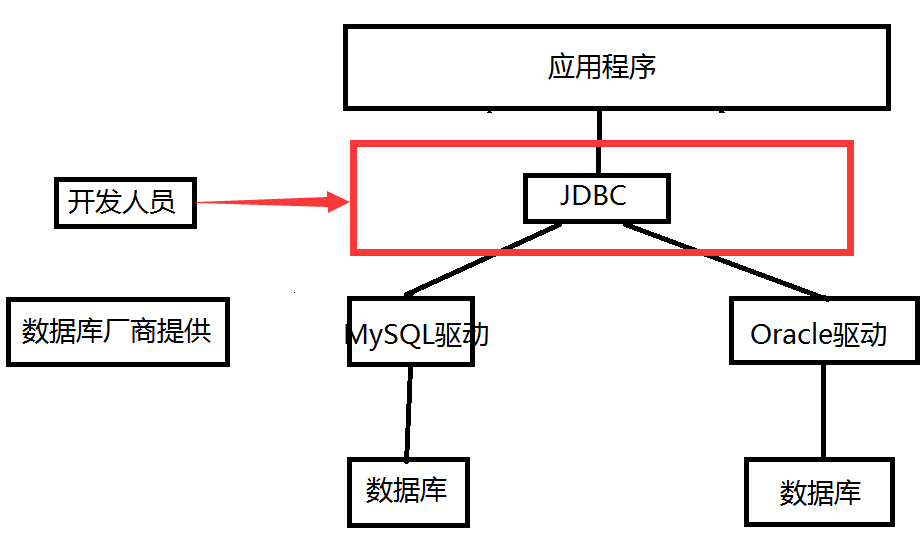
- java.sql
- javax.sql
- 还需要导入一个数据库驱动包mysql-connector-java-5.1.14.jar
10.3 第一个JDBC程序
创建测试数据库
1、加载驱动
2、获取用户信息和URL
3、获取执行SQL的对象Statement或者PrepareStatement
4、获取返回的结果集
5、释放连接
DriverManager
// 固定写法,加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 获取数据库连接对象
Connection connection = DriverManager.getConnection(url, username, pwd);
// connection代表数据库
// 数据库设置自动提交
connection.setAutoCommit(true);
// 数据库事务提交
connection.commit();
// 数据库事务回滚
connection.rollback();
URL
String url = "jdbc:mysql://127.0.0.1:3306/shop?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8&useSSL=true";
String username = "root";
String pwd = "123456";
Statement/PrepareStatement 执行SQL的对象
// 先编写SQL
String sql = "SELECT * FROM ......";
statement.executeQuery(); // 查询操作返回结果集
statement.execute(); // 执行任何SQL
statement.executeUpdate(); // 更新、插入、删除都是用这个,返回一个受影响的行数
ResultSet 查询的结果集
resultSet.next(); // 移动到下一行数据
resultSet.previous(); // 移动到前一行数据
释放资源
// 很消耗资源,用完即释放
resultSet.close();
statement.close();
connection.close();
10.4 JdbcUtils工具类
package zr.utils;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
public class JdbcUtils {
private static String driver = null;
private static String url = null;
private static String username = null;
private static String password = null;
static {
try{
// 通过反射可以拿到src目录下的所有文件
InputStream in = JdbcUtils.class.getClassLoader().getResourceAsStream("db.properties");
Properties properties = new Properties();
properties.load(in);
driver = properties.getProperty("driver");
url = properties.getProperty("url");
username = properties.getProperty("username");
password = properties.getProperty("password");
// 1. 驱动只需要加载一次
Class.forName(driver);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取数据库连接
* @return
* @throws SQLException
*/
public static Connection getConnection() throws SQLException {
return DriverManager.getConnection(url, username, password);
}
/**
* 释放连接
* @param conn
* @param st
* @param rs
*/
public static void release(Connection conn, Statement st, ResultSet rs){
if(rs != null){
try{
rs.close();
} catch (SQLException e){
e.printStackTrace();
}
}
if(st != null){
try{
st.close();
} catch (SQLException e){
e.printStackTrace();
}
}
if(conn != null){
try{
conn.close();
} catch (SQLException e){
e.printStackTrace();
}
}
}
}
10.5 Statement对象
执行SQL的对象,容易出现SQL注入的问题,因为是直接在字符串中写sql,可能会将一些逻辑符号也作为string复制进去执行
package zr.mysql.test;
import zr.utils.JdbcUtils;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class TestInsert {
public static void main(String[] args) {
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try{
// 获取数据库连接
conn = JdbcUtils.getConnection();
// 获取SQL的执行对象
st = conn.createStatement();
String sql = "INSERT INTO account (`name`, `money`) VALUES('C', 2000.0)";
int i = st.executeUpdate(sql);
if(i > 0){
System.out.println("插入成功...");
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
JdbcUtils.release(conn, st, rs);
}
}
}
10.6 PrepareStatement对象
可以防止SQL注入, 并且效率更高。将所有的参数全作为string处理,所以不会出现将逻辑符号参数作为逻辑符号处理。
package zr.mysql.test;
import zr.utils.JdbcUtils;
import java.sql.*;
public class TestPrepareST {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement st = null;
ResultSet rs = null;
try{
// 获取数据库连接
conn = JdbcUtils.getConnection();
String sql = "INSERT INTO account (`name`, `money`) VALUES(?, ?)";
// 区别,使用?占位符代替参数
st = conn.prepareStatement(sql); // 预编译SQL,先写SQL,不执行
// 手动给参数赋值
st.setString(1, "D");
st.setDouble(2, 3000.0);
// 注意,这里不用再传参了
int i = st.executeUpdate();
if(i > 0){
System.out.println("插入成功...");
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
JdbcUtils.release(conn, st, rs);
}
}
}