博客转载自:http://blog.csdn.net/u012907049/article/details/75004124
前言
本篇文章是机器人自动寻路算法实现的第二章。我们要讨论的是一个在一个M×N的格子的房间中,有若干格子里有灰尘,有若干格子里有障碍物,而我们的扫地机器人则是要在不经过障碍物格子的前提下清理掉房间内的灰尘。具体的问题情景请查看人工智能: 自动寻路算法实现(一、广度优先搜索)这篇文章,即我们这个系列的第一篇文章。在上一篇文章里,我们介绍了通过广度优先搜索算法来实现扫地机器人自动寻路的功能。在这篇文章中,我们要介绍与之相对应的另一种算法:深度优先搜索算法。
正文
算法介绍
深度优先算法,与广度优先搜索算法类似,唯一不同的是,它是沿着树的深度遍历数的节点,尽可能遍历搜索数的分支。也就是说,从根节点开始,它会首先遍历根节点的第一个子节点,接着遍历子节点的第一个子节点,并沿着树的深度一直遍历下去。下面两幅图就是深度优先搜索和广度优先搜索遍历顺序的对比,图中节点上的数字就表示该节点在这个算法中被遍历到的顺序。
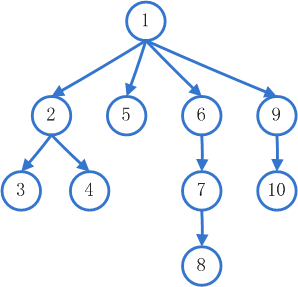
深度优先搜索
广度优先搜索
深度优先搜索的算法伪代码如下:
开始
将顶点入栈
循环
当栈为非空时,继续执行,否则算法结束
取得队栈顶点V;访问并标记为已访问
如果顶点V有未被访问过的子节点
查找顶点V的第一个未被访问过的子节点W1
标记W1为已访问
将W1入栈
否则将顶点V出栈
可以看出相对于上一篇文章中的广度优先搜索算法,深度优先搜索只是更改了一个数据结构:将队列改为栈。这里也是用到了栈的后进先出的特性。
void Robot::caculate(State* state)
{
//获取当前机器人的坐标
int x = state->getRobotPosition().getX();
int y = state->getRobotPosition().getY();
//如果当前的点是灰尘并且没有被清理
if (map[x][y] == '*' && !isCleared(Point(x, y), state->getDirtList()))
{
State* newState = new State();
list<Point> newdirtList;
//在新的state中,将灰尘列表更新,即去掉当前点的坐标
for (Point point : state->getDirtList())
{
if (point.getX() == x && point.getY() == y)
continue;
else
newdirtList.push_back(Point(point.getX(), point.getY()));
}
newState->setDirtList(newdirtList);
newState->setRobotPosition(Point(x, y));
//C代表Clean操作
newState->setRobotOperation("C");
newState->setPreviousState(state);
//若新产生的状态与任意一个遍历过的状态都不同,则进入队列
if (!isDuplicated(newState))
{
//深度搜索
Robot::instance()->depthSearch.push(*newState);
//广度搜索
//Robot::instance()->breadthSearch.push(*newState);
closeList.push_back(*newState);
cost++;
return;
}
}
//若当前机器人坐标下方有格子并且不是障碍物
if (x + 1 < rowNum)
{
if (map[x + 1][y] != '#')
{
State* newState = new State();
newState->setDirtList(state->getDirtList());
newState->setRobotPosition( Point(x + 1, y));
//S代表South,即向下方移动一个格子
newState->setRobotOperation("S");
newState->setPreviousState(state);
if (!isDuplicated(newState))
{
//深度搜索
Robot::instance()->depthSearch.push(*newState);
//广度搜索
//Robot::instance()->breadthSearch.push(*newState);
//加入到closeList中
closeList.push_back(*newState);
cost++;
return;
}
}
}
//若当前机器人坐标上方有格子并且不是障碍物
if (x - 1 >= 0)
{
if (map[x - 1][y] != '#')
{
State* newState = new State();
newState->setDirtList(state->getDirtList());
newState->setRobotPosition(Point(x - 1, y));
//W代表向上方移动一个格子
newState->setRobotOperation("W");
newState->setPreviousState(state);
if (!isDuplicated(newState))
{
//深度搜索
Robot::instance()->depthSearch.push(*newState);
//广度搜索
//Robot::instance()->breadthSearch.push(*newState);
//加入到closeList中
closeList.push_back(*newState);
cost++;
return;
}
}
}
//若当前机器人坐标左侧有格子并且不是障碍物
if (y - 1 >= 0)
{
if (map[x][y - 1] !='#')
{
State* newState = new State();
newState->setDirtList(state->getDirtList());
newState->setRobotPosition(Point(x , y-1));
//A向左侧移动一个格子
newState->setRobotOperation("A");
newState->setPreviousState(state);
if (!isDuplicated(newState))
{
//深度搜索
Robot::instance()->depthSearch.push(*newState);
//广度搜索
//Robot::instance()->breadthSearch.push(*newState);
//加入到closeList中
closeList.push_back(*newState);
cost++;
return;
}
}
}
//若当前机器人坐标右侧有格子并且不是障碍物
if (y + 1 < coloumnNum)
{
if (map[x][y + 1] != '#')
{
State* newState = new State();
newState->setDirtList(state->getDirtList());
newState->setRobotPosition(Point(x, y + 1));
newState->setRobotOperation("D");
newState->setPreviousState(state);
if (!isDuplicated(newState))
{
//深度搜索
Robot::instance()->depthSearch.push(*newState);
//广度搜索
//Robot::instance()->breadthSearch.push(*newState);
//加入到closeList中
closeList.push_back(*newState);
cost++;
return;
}
}
}
Robot::instance()->depthSearch.pop();
}
代码与广度优先搜索大体相同,但也有一部分差异。除了运用栈来代替队列的数据结构之外,主要的差异在于calculate方法。在每一个可能产生的节点代码之后多了一个return语句。我们可以回顾文章开头的算法伪代码:
开始
将顶点入栈
循环
当栈为非空时,继续执行,否则算法结束
取得队栈顶点V;访问并标记为已访问
如果顶点V有未被访问过的子节点
查找顶点V的第一个未被访问过的子节点W1
标记W1为已访问
将W1入栈
否则将顶点V出栈
查找第一个未被访问过的子节点。所以每次只遍历一个子节点。我们的return就体现出了这一点:当一个节点符合要求,我们将它入栈并标记为已访问之后,就结束这次遍历。我们还可以看到方法的最后多了一个
Robot::instance()->depthSearch.pop();
语句。这里就对应伪代码中的“否则将顶点V出栈”:当方法执行到这一步的时候,说明这个节点已经没有未遍历过的子节点(如果有的话一定会在前面的某一步骤return而执行不到这一步),那么此时就要将这个节点(state)出栈。
运行结果与广度优先搜索的对比
对于如下的一个地图:
@#* *__ #*_
本算法的结果为:
Please Enter Row Number: 3 Please Enter Colomn Number: 3 Please Enter the Elements in row 1: @#* Please Enter the Elements in row 2: *__ Please Enter the Elements in row 3: #*_ S C E S C N E N C 14
其中14是遍历的节点数量。
对比一下上一篇文章中广度优先搜索的结果:
Please Enter Row Number: 3 Please Enter Colomn Number: 3 Please Enter the Elements in row 1: @#* Please Enter the Elements in row 2: *__ Please Enter the Elements in row 3: #*_ S C E S C N E N C 45
可以看出遍历的节点明显少了很多。这也是深度优先搜索的一个优点。不过,深度优先搜索也有自己的不足。比如我们来看一下上一篇文章中的里一个例子:
*#_* _*__ _#_@
本算法的输出为
Please Enter Row Number: 3 Please Enter Colomn Number: 4 Please Enter the Elements in row 1: *#_* Please Enter the Elements in row 2: _*__ Please Enter the Elements in row 3: _#_@ N N C S S W N W C W N C 15
对比一下广度优先搜索的结果:
Please Enter Row Number: 3 Please Enter Colomn Number: 4 Please Enter the Elements in row 1: *#_* Please Enter the Elements in row 2: _*__ Please Enter the Elements in row 3: _#_@ N N C S W W C W N C 56
可以看出虽然遍历了节点仍然少了很多,但是机器人所用的步骤要多了一些。这就是深度优先搜索的另一个特性:找到的解并不是最优解。这是由深度搜索的“深度遍历”所决定的。比如,当最优解存在于根节点的右侧子节点,而我们的程序先遍历的是左侧子节点。如果在遍历左侧子节点的过程中找到了一个解,就算这个解不是最优解,程序依然结束。此时我们找到的显然不是最优解。
我们可以再考虑另外一种极端的情况:最优解依然存在于右侧子节点,而我们的程序遍历的是左侧子节点。如果此时左侧的子节点有无限多个,并且其中没有解的话,那么我们的程序将永远遍历左侧的节点,并且永远找不到解。所以我们可以分析出深度优先搜索的特点:当一个问题有解的时候,深度优先搜索并不一定能找到解。并且就算找到了解,也并不一定是最优解。
由此可见,深度优先搜索的应用场景应该是不需要找到最优解的问题,并且问题的可能性应该是有限的。在我们遍历的树有很多分支节点的情况下,深度优先搜索的效率显然要比广度优先搜索高。
深度优先搜索的空间复杂度为
结束语
这个系列的前两篇文章比较了广度优先搜索与深度优先搜索在自动寻路问题中的体现。下一篇文章中,我将介绍另一种算法: A*算法。