问题:
一个Django项目需要做多语言支持,需要对所有Model代码做gettext_lazy处理,就像下面这样:
示例(原Model):
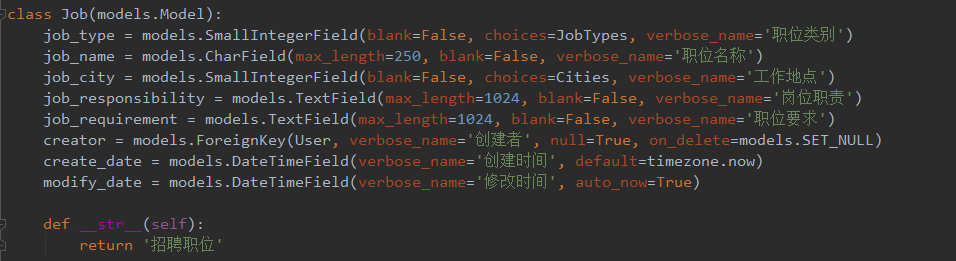
目标(Model):

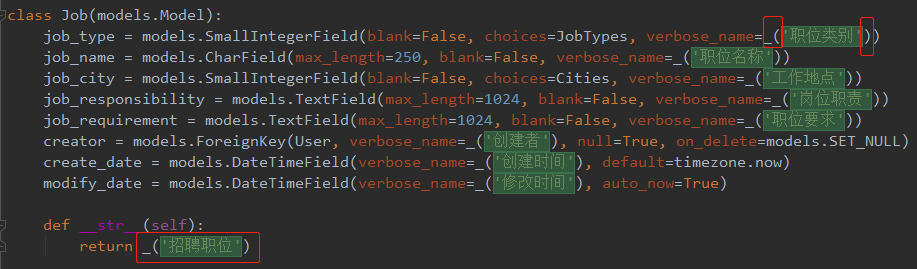
突然发现这是个苦力活,开干。
解决方法:(正则匹配,批量替换)
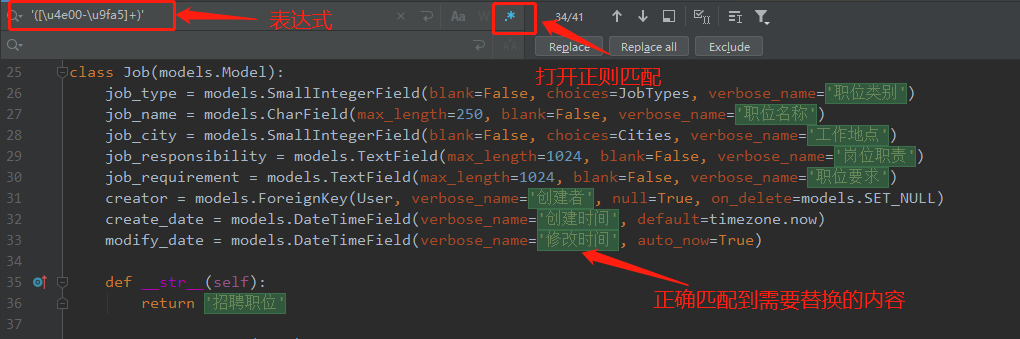
中文正则匹配:u4e00-u9fa5
查找的正则表达式:'([u4e00-u9fa5]+)' (注意有引号的,分组括号,括号内的不替换)
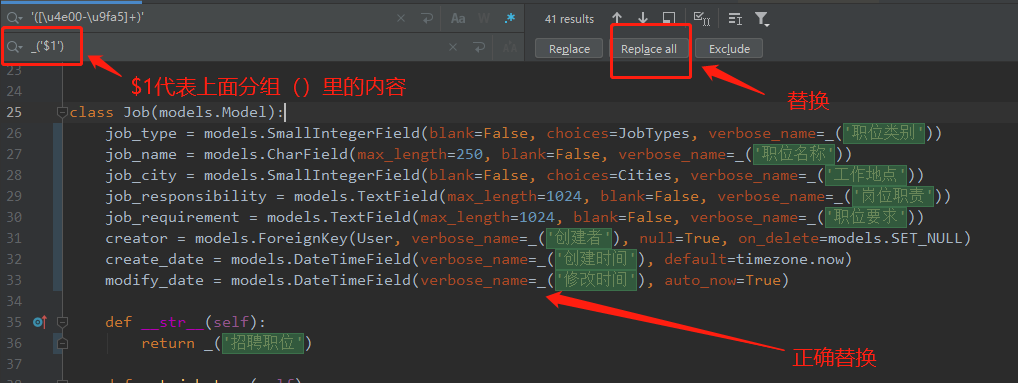
Ctrl + r 打开替换框:
替换的表达式:_('$1')
一个Django项目需要做多语言支持,需要对所有Model代码做gettext_lazy处理,就像下面这样:
示例(原Model):
目标(Model):
突然发现这是个苦力活,开干。
中文正则匹配:u4e00-u9fa5
查找的正则表达式:'([u4e00-u9fa5]+)' (注意有引号的,分组括号,括号内的不替换)
Ctrl + r 打开替换框:
替换的表达式:_('$1')