链表的定义
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
我们上一节了解了数组,数组是有序的元素序列,在内存中占用了连续完整的存储空间,而链表恰恰与数组相反,链表中的元素可以分布在内存中的不同位置,有效的利用零散的碎片空间。
他们在内存中的区别如下图:
其中的箭头实际上就是指针,也就是说,链表中的每一个节点都含有两个部分,一部分存放数据,另一部分叫做指针,指向下一个节点的内存地址。链表的最后一个节点的指针不指向任何数据,也可以说成是指向空。
查找
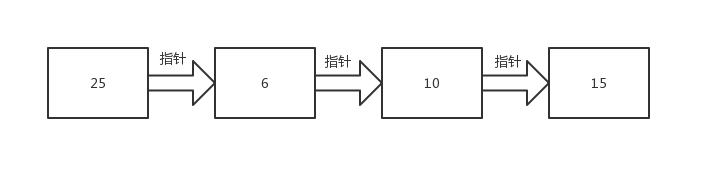
我们来看一下链表是怎么查找数据的,以如下链表为例。
如果我们要查找10这个数据。
由于链表的数据都是分散存储的,所以只能从第一个数据开始,顺着指针一步一步的查找。
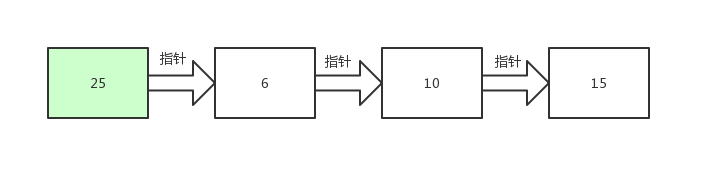
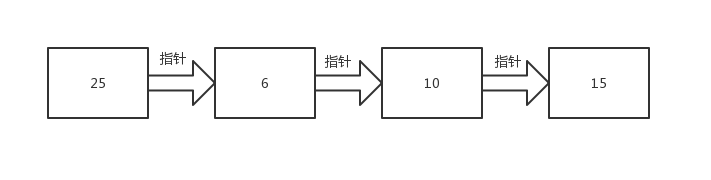
首先将指针定位到链表的头部,找到了25这个数据,继续跟着指针往下找。
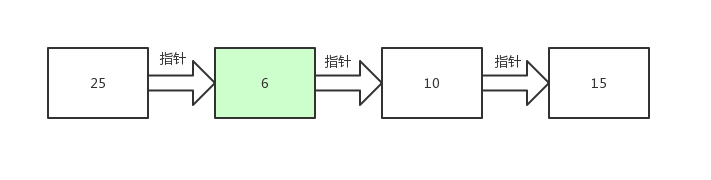
又找到了6这个数据,顺着指针继续找。
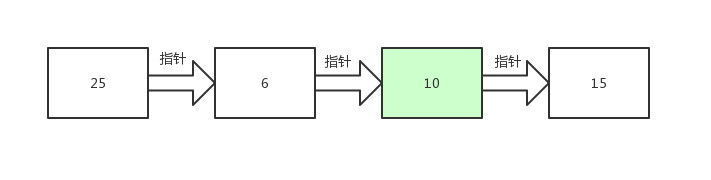
找到10了!
添加
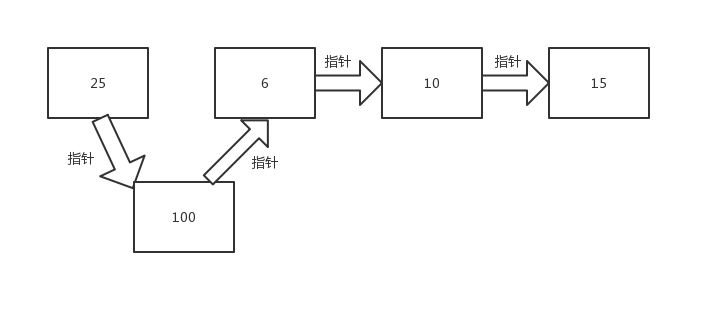
如果我们想在25和6之间添加一个数据100。
实际操作只需要更改前后指针即可:
删除
删除与添加同理,更改指针引用即可完成删除操作。
当然,删除实际上并不是真的删除,而是修改了链表中的指针引用,让目标数据没有被当前链表所引用,不过对于许多高级语言来说,都有自动化的垃圾回收机制会处理这些没有被引用的对象。
循环链表
虽然上文中的链表尾部元素的指针是没有指向其他节点的,但是我们也可以在链表尾部将指针指向链头,形成循环链表,可以在脑海中想象成一个圆圈,没有头尾的概念。
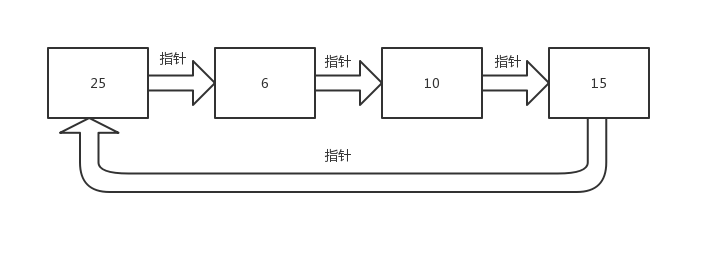
双向链表
我们普遍看到的链表都是单链表,也就是每个节点由两部分组成:数据和指针,指针指向下一个数据的内存地址。
也有一种链表每个节点由三部分组成:数据和双指针,指针分别指向上一个数据的内存地址和下一个数据的内存地址。
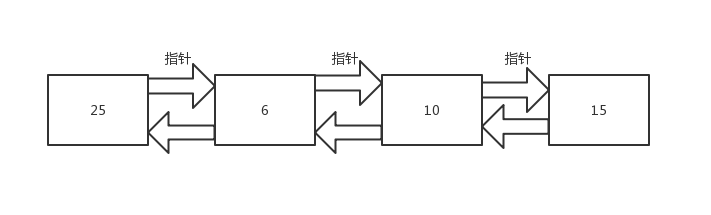
双向链表的优点是可以通过一个节点,快速的追溯到它的上一个节点,从后往前遍历数据显得非常方便。
缺点是比单向链表占用更多的存储空间,并且添加数据和删除数据的时候都要改变更多的指针。
个人疑问
对于单向链表插入数据的效率问题,我查过很多资料,结果都是O(1),我有点不明白。
如下代码:
//插入中间 Node prevNode = get(index-1);//获取前一个节点 insertedNode.next = prevNode.next;//将新节点的指针指向前一个节点的指针目标 prevNode.next = insertedNode;//将前一个节点的指针指向当前节点
光改两个指针当然很简单,但是改之前是不是得找到节点?
假如我要在第3个节点上插入数据,我是不是要找到第2个节点把指针指向目标赋值给新数据的指针,同时也要把第2个节点的指针指向新数据?找第2个节点不需要遍历吗?