##sample 1
https://blog.csdn.net/CCjedweat/article/details/113752818?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2-113752818-blog-86694412.t5_layer_eslanding_S_0&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2-113752818-blog-86694412.t5_layer_eslanding_S_0&utm_relevant_index=3
Prometheus 监控基础
监控系统基础
监控系统发展史
SNMP监控时代
第一代主要是监控网络流量和网络设置为主的时代,在那个时代主要是通过SNMP协议监控交换机、路由器、网关、操作系统等,通过互联网日益增长的需求,这种简单的通过SNMP协议实现的监控手段并不能满足现有需求,因此这种监控手段逐渐被替代。
当今的监控系统
当今比较流行的监控系统有Prometheus、Zabbix、Nagios、Cacti、Ganglia,它们都有几个基本特点就是对操作系统的监控数据采集、存储及展示。
未来的监控系统
目前一些大厂或多多少的接触到,比如基于Data的DataOps,基于AI的AIOps,他们背后都要或多或少基于一个立体监控系统,完成对于系统运行状态的分析与监控,最后反馈到系统监控中心去。大多数系统现在还处于非自治状态,对于这种非自治状态的系统对于管理者来讲需要对其进行深入的监控,以及了解它的运行特性而后做出响应的决策。我们不但要做事前监控还要做事后监控。监控系统是我们运维体系中不可缺少的基础服务,而且随着人工智能、大数据的发展,基于DataOps、AIOps的未来监控甚嚣尘上。
监控系统组件
指标数据采集
指标数据存储
指标数据分析及可视化
告警通知
监控系统,一般而言,它无非就是对于每一个被监控的目标,或者我们要监控的系统中的组件,(比如一个主机、交换机、网关、应用、基础服务、某个业务特征等),对于这么一个基础设施层,我们要对它内部的运行的各种关键数据,通常是一种随时间变化的数据,我们一般把它叫做指标数据,然后我们采集这些指标数据,通常会得到一些点状数据,这些点状数据我们称之为样本数据,为了能够做事后分析,我们需要把它存储下来,所以对于存储这块,需要具备持续读写的性能的支撑,在存储这些样本数据后,我们需要根据样本数据做一些分析,得出当前系统运行状态,甚至后续预测出是否会出现的问题,通常这些样本数据可以通过一个UI界面服务呈现给我们查看,最后监控系统还需要有告警通知服务,通过设置一些规则我们就能提前得到系统运行状态的信息。
一、Prometheus 监控平台简介
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。2016年5月继Kubernetes之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。
Prometheus作为新一代的云原生监控系统,目前已经有超过650+位贡献者参与到Prometheus的研发工作上,并且超过120+项的第三方集成。
Prometheus的优势
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。 相比于传统监控系统Prometheus具有以下优点:
易于管理
Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
Prometheus基于Pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统。对于一些复杂的情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
监控服务的内部运行状态
Prometheus鼓励用户监控服务的内部状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
强大的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。如下所示:
http_request_status{code='200',content_path='/api/path', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
http_request_status{code='200',content_path='/api/path2', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
1
2
每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识。每条时间序列按照时间的先后顺序存储一系列的样本值。
表示维度的标签可能来源于你的监控对象的状态,比如code=404或者content_path=/api/path。也可能来源于的你的环境定义,比如environment=produment。基于这些Labels我们可以方便地对监控数据进行聚合,过滤,裁剪。
强大的查询语言PromQL
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
高效
对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而Prometheus可以高效地处理这些数据,对于单一Prometheus Server实例而言它可以处理:
数以百万的监控指标
每秒处理数十万的数据点
可扩展
Prometheus是如此简单,因此你可以在每个数据中心、每个团队运行独立的Prometheus Sevrer。
Prometheus对于联邦集群的支持,可以让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)可以对其进行扩展。
易于集成
使用Prometheus可以快速搭建监控服务,并且可以非常方便地在应用程序中进行集成。目前支持: Java、JMX、 Python、 Go、Ruby、 .Net、 Node.js等等语言的客户端SDK,基于这些SDK可以快速让应用程序纳入到Prometheus的监控当中,或者开发自己的监控数据收集程序。同时这些客户端收集的监控数据,不仅仅支持Prometheus,还能支持Graphite这些其他的监控工具。
同时Prometheus还支持与其他的监控系统进行集成:Graphite、Statsd、Collected、Scollector、muini、Nagios等。
Prometheus社区还提供了大量第三方实现的监控数据采集支持:JMX, CloudWatch, EC2, MySQL, PostgresSQL, Haskell, Bash, SNMP, Consul, Haproxy, Mesos, Bind, CouchDB, Django, Memcached, RabbitMQ, Redis, RethinkDB, Rsyslog等等。
可视化
Prometheus Server中自带了一个Prometheus UI,通过这个UI可以方便地直接对数据进行查询,并且支持直接以图形化的形式展示数据。同时Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案Promdash。最新的Grafana可视化工具也已经提供了完整的Prometheus支持,基于Grafana可以创建更加精美的监控图标。基于Prometheus提供的API还可以实现自己的监控可视化UI。
开放性
通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持。因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制。对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于Prometheus来说,使用Prometheus的client library的输出格式不止支持Prometheus的格式化数据,也可以输出支持其它监控系统的格式化数据,比如Graphite。
因此你甚至可以在不使用Prometheus的情况下,采用Prometheus的client library来让你的应用程序支持监控数据采集。
二、初识 Prometheus
Prometheus是一个开放性的监控解决方案,用户可以非常方便的安装和使用Prometheus并且能够非常方便的对其进行扩展。为了能够更加直观的了解Prometheus Server,接下来我们将在本地部署并运行一个Prometheus Server实例,通过Node Exporter采集当前主机的系统资源使用情况。 并通过Grafana创建一个简单的可视化仪表盘。
安装Prometheus Server
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。用户只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启动Prometheus Server。
从二进制包安装
对于非Docker用户,可以从https://prometheus.io/download/找到最新版本的Prometheus Sevrer软件包:
这里我们下载prometheus-2.24.1.linux-amd64.tar.gz,解压,并将Prometheus相关的命令,添加到系统环境变量路径即可:
tar -xzf prometheus-2.24.1.linux-amd64.tar.gz
cd prometheus-2.24.1.linux-amd64
1
2
解压后当前目录会包含默认的Prometheus配置文件promethes.yml:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Promtheus作为一个时间序列数据库,其采集的数据会以文件的形式存储在本地中,默认的存储路径为data/,因此我们需要先手动创建该目录:
mkdir -p data
1
用户也可以通过参数--storage.tsdb.path="/data/promethes-data/"修改本地数据存储的路径。
启动prometheus服务,其会默认加载当前路径下的prometheus.yaml文件:
./prometheus
1
正常的情况下,你可以看到以下输出内容:
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:326 msg="No time or size retention was set so using the default time retention" duration=15d
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:364 msg="Starting Prometheus" version="(version=2.24.1, branch=HEAD, revision=e4487274853c587717006eeda8804e597d120340)"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:369 build_context="(go=go1.15.6, user=root@0b5231a0de0f, date=20210120-00:09:36)"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:370 host_details="(Linux 4.4.0-62-generic #83-Ubuntu SMP Wed Jan 18 14:10:15 UTC 2017 x86_64 sc-stable-ops-tools-001 (none))"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:371 fd_limits="(soft=1024, hard=1048576)"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:372 vm_limits="(soft=unlimited, hard=unlimited)"
level=info ts=2021-01-21T12:23:06.184Z caller=web.go:530 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2021-01-21T12:23:06.185Z caller=main.go:738 msg="Starting TSDB ..."
level=info ts=2021-01-21T12:23:06.186Z caller=tls_config.go:191 component=web msg="TLS is disabled." http2=false
level=info ts=2021-01-21T12:23:06.190Z caller=head.go:645 component=tsdb msg="Replaying on-disk memory mappable chunks if any"
level=info ts=2021-01-21T12:23:06.190Z caller=head.go:659 component=tsdb msg="On-disk memory mappable chunks replay completed" duration=2.863µs
level=info ts=2021-01-21T12:23:06.190Z caller=head.go:665 component=tsdb msg="Replaying WAL, this may take a while"
level=info ts=2021-01-21T12:23:06.191Z caller=head.go:717 component=tsdb msg="WAL segment loaded" segment=0 maxSegment=0
level=info ts=2021-01-21T12:23:06.191Z caller=head.go:722 component=tsdb msg="WAL replay completed" checkpoint_replay_duration=15.9µs wal_replay_duration=220.764µs total_replay_duration=256.654µs
level=info ts=2021-01-21T12:23:06.192Z caller=main.go:758 fs_type=EXT4_SUPER_MAGIC
level=info ts=2021-01-21T12:23:06.192Z caller=main.go:761 msg="TSDB started"
level=info ts=2021-01-21T12:23:06.192Z caller=main.go:887 msg="Loading configuration file" filename=/opt/prometheus/current/prometheus.yml
level=info ts=2021-01-21T12:23:06.194Z caller=main.go:918 msg="Completed loading of configuration file" filename=/opt/prometheus/current/prometheus.yml totalDuration=1.122768ms remote_storage=2.079µs web_handler=488ns query_engine=901ns scrape=220.418µs scrape_sd=37.452µs notify=26.64µs notify_sd=18.238µs rules=5.187µs
level=info ts=2021-01-21T12:23:06.194Z caller=main.go:710 msg="Server is ready to receive web requests."
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
使用容器安装
对于Docker用户,直接使用Prometheus的镜像即可启动Prometheus Server:
docker run -p 9090:9090 -v /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
1
启动完成后,可以通过http://localhost:9090访问Prometheus的UI界面:
使用Node Exporter采集主机数据
安装Node Exporter
在Prometheus的架构设计中,Prometheus Server并不直接提供监控特定目标的服务,其主要任务负责数据的收集、存储并且对外提供数据查询支持。因此为了能够监控到服务器状态,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
从上面的描述中可以看出Exporter是一个相对开放的概念,可能是一个独立运行的程序独立于监控目标之外,也可能是直接内置在监控目标中。只要能够向Prometheus提供标准格式的监控样本数据即可。
这里为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/获取最新的node exporter版本的二进制包。
tar xf node_exporter-1.0.1.linux-amd64.tar.gz
cd node_exporter-1.0.1.linux-amd64 && ls
LICENSE node_exporter NOTICE
1
2
3
运行node exporter:
mv node_exporter /usr/local/bin/
node_exporter
1
2
启动成功后,可以看到以下输出:
level=info ts=2021-01-21T12:55:05.965Z caller=node_exporter.go:191 msg="Listening on" address=:9100
1
初始Node Exporter监控指标
本地机器访问127.0.0.1:9100/metrics,我们会看到很多机器状态指标:
curl 127.0.0.1:9100/metrics
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 3.0703125
1
2
3
4
5
6
7
其中HELP用于解释当前指标的含义,TYPE则说明当前指标的数据类型。在上面的例子中node_cpu的注释表明当前指标是cpu0上idle进程占用CPU的总时间,CPU占用时间是一个只增不减的度量指标,从类型中也可以看出node_cpu的数据类型是计数器(counter),与该指标的实际含义一致。又例如node_load1该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为仪表盘(gauge),与指标反映的实际含义一致。
除了这些以外,在当前页面中根据物理主机系统的不同,你还可能看到如下监控指标:
node_boot_time:系统启动时间
node_cpu:系统CPU使用量
node_disk_io_*:磁盘IO
node_filesystem_*:文件系统用量
node_load1:系统负载
node_memory_*:内存使用
node_network*:网络带宽
node_time:当前系统时间
go_*:node exporter中go相关指标
process_*:node exporter自身进程相关运行指标
从Node Exporter收集监控数据
为了能够让Prometheus Server能够从当前node exporter获取到监控数据,这里需要修改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['172.17.40.65:9100', '172.17.40.66:9100', '172.17.40.67:9100']
1
2
3
4
5
6
7
8
重新启动Prometheus Server
访问http://localhost:9090,进入到Prometheus Server。如果输入“up”并且点击执行按钮以后,可以看到如下结果:
如果Prometheus能够正常从node exporter获取数据,则会看到以下结果:
up{instance="localhost:9090",job="prometheus"} 1
up{instance="172.17.40.67:9100",job="node"} 1
1
2
其中“1”表示正常,反之“0”则为异常。
使用PromQL查询监控数据
Prometheus UI是Prometheus内置的一个可视化管理界面,通过Prometheus UI用户能够轻松的了解Prometheus当前的配置,监控任务运行状态等。 通过Graph面板,用户还能直接使用PromQL实时查询监控数据。
切换到Graph面板,用户可以使用PromQL表达式查询特定监控指标的监控数据。如下所示,查询主机负载变化情况,可以使用关键字node_load1可以查询出Prometheus采集到的主机负载的样本数据,这些样本数据按照时间先后顺序展示,形成了主机负载随时间变化的趋势图表:
PromQL是Prometheus自定义的一套强大的数据查询语言,除了使用监控指标作为查询关键字以为,还内置了大量的函数,帮助用户进一步对时序数据进行处理。例如使用rate()函数,可以计算在单位时间内样本数据的变化情况即增长率,因此通过该函数我们可以近似的通过CPU使用时间计算CPU的利用率:
rate(node_cpu_seconds_total[2m])
1
这时如果要忽略是哪一个CPU的,只需要使用without表达式,将标签CPU去除后聚合数据即可:
avg without(cpu) (rate(node_cpu[2m]))
1
那如果需要计算系统CPU的总体使用率,通过排除系统闲置的CPU使用率即可获得:
1 - avg without(cpu) (rate(node_cpu{mode="idle"}[2m]))
1
通过PromQL我们可以非常方便的对数据进行查询,过滤,以及聚合,计算等操作。通过这些丰富的表达书语句,监控指标不再是一个单独存在的个体,而是一个个能够表达出正式业务含义的语言。
监控数据可视化
Prometheus UI提供了快速验证PromQL以及临时可视化支持的能力,而在大多数场景下引入监控系统通常还需要构建可以长期使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如Grafana,Grafana是一个开源的可视化平台,并且提供了对Prometheus的完整支持。
docker run -d -p 3000:3000 grafana/grafana
1
访问http://localhost:3000就可以进入到Grafana的界面中,默认情况下使用账户admin/admin进行登录。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件等主要流程:
这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus并且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示连接成功的信息:
在完成数据源的添加之后就可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard并且为该Dashboard添加一个panel。 并在该面板的“Query”选项下通过PromQL查询需要可视化的数据:
点击界面中的保存选项,就创建了我们的第一个可视化Dashboard了。 当然作为开源软件,Grafana社区鼓励用户分享Dashboard通过https://grafana.com/dashboards网站,可以找到大量可直接使用的Dashboard:
Grafana中所有的Dashboard通过JSON进行共享,下载并且导入这些JSON文件,就可以直接使用这些已经定义好的Dashboard:
任务和实例
通过在prometheus.yml配置文件中,添加如下配置。我们让Prometheus可以从node exporter暴露的服务中获取监控指标数据。
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['172.17.40.65:9100', '172.17.40.66:9100', '172.17.40.67:9100']
1
2
3
4
5
6
7
当我们需要采集不同的监控指标(例如:主机、MySQL、Nginx)时,我们只需要运行相应的监控采集程序,并且让Prometheus Server知道这些Exporter实例的访问地址。在Prometheus中,每一个暴露监控样本数据的HTTP服务称为一个实例。例如在当前主机上运行的node exporter可以被称为一个实例(Instance)。
而一组用于相同采集目的的实例,或者同一个采集进程的多个副本则通过一个一个任务(Job)进行管理。
* job: node
* instance 2: 172.17.40.65:9100
* instance 4: 172.17.40.66:9100
1
2
3
当前在每一个Job中主要使用了静态配置(static_configs)的方式定义监控目标。除了静态配置每一个Job的采集Instance地址以外,Prometheus还支持与DNS、Consul、E2C、Kubernetes等进行集成实现自动发现Instance实例,并从这些Instance上获取监控数据。
除了通过使用“up”表达式查询当前所有Instance的状态以外,还可以通过Prometheus UI中的Targets页面查看当前所有的监控采集任务,以及各个任务下所有实例的状态:
Prometheus核心组件
通过部署Node Exporter我们成功的获取到了当前主机的资源使用情况。接下来我们将从Prometheus的架构角度详细介绍Prometheus生态中的各个组件。
下图展示Prometheus的基本架构:
Prometheus Server
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Server需要对采集到的监控数据进行存储,Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server对外提供了自定义的PromQL语言,实现对数据的查询以及分析。
Prometheus Server内置的Express Browser UI,通过这个UI可以直接通过PromQL实现数据的查询以及可视化。
Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据,因此在大规模监控的情况下,可以通过联邦集群以及功能分区的方式对Prometheus Server进行扩展。
Exporters
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
PushGateway
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
参考链接:
https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/quickstart
————————————————
版权声明:本文为CSDN博主「CCULin」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/CCjedweat/article/details/113752818
###sample 2
https://cloud.tencent.com/developer/article/1725038
使用 prometheus python 库编写自定义指标的方法(完整代码)
虽然 prometheus 已有大量可直接使用的 exporter 可供使用,以满足收集不同的监控指标的需要。例如,node exporter 可以收集机器 cpu,内存等指标,cadvisor 可以收集容器指标。然而,如果需要收集一些定制化的指标,还是需要我们编写自定义的指标。
本文讲述如何使用 prometheus python 客户端库和 flask 编写 prometheus 自定义指标。
安装依赖库
我们的程序依赖于flask 和prometheus client 两个库,其 requirements.txt 内容如下:
flask==1.1.2 prometheus-client==0.8.0
运行 flask
我们先使用 flask web 框架将 /metrics 接口运行起来,再往里面添加指标的实现逻辑。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from flask import Flask
app = Flask(__name__)
@app.route('/metrics')
def hello():
return 'metrics'
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)打开浏览器,输入 http://127.0.0.1:5000/metrics,按下回车后浏览器显示 metrics 字符。
编写指标
Prometheus 提供四种指标类型,分别为 Counter,Gauge,Histogram 和 Summary。
Counter
Counter 指标只增不减,可以用来代表处理的请求数量,处理的任务数量,等。
可以使用 Counter 定义一个 counter 指标:
counter = Counter(‘my_counter’, ‘an example showed how to use counter’)
其中,my_counter 是 counter 的名称,an example showed how to use counter 是对该 counter 的描述。
使用 counter 完整的代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from flask import Flask, Response
from prometheus_client import Counter, generate_latest
app = Flask(__name__)
counter = Counter('my_counter', 'an example showed how to use counter')
@app.route('/metrics')
def hello():
counter.inc(1)
return Response(generate_latest(counter), mimetype='text/plain')
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)访问 http://127.0.0.1:5000/metrics,浏览器输出:
# HELP my_counter_total an example showed how to use counter # TYPE my_counter_total counter my_counter_total 6.0 # HELP my_counter_created an example showed how to use counter # TYPE my_counter_created gauge my_counter_created 1.5932468510424378e+09
在定义 counter 指标时,可以定义其 label 标签:
counter = Counter(‘my_counter’, ‘an example showed how to use counter’, [‘machine_ip’])
在使用时指定标签的值:
counter.labels(‘127.0.0.1’).inc(1)
这时浏览器会将标签输出:
my_counter_total{machine_ip=”127.0.0.1″} 1.0
Gauge
Gauge 指标可增可减,例如,并发请求数量,cpu 占用率,等。
可以使用 Gauge 定义一个 gauge 指标:
registry = CollectorRegistry()
gauge = Gauge('my_gauge', 'an example showed how to use gauge', ['machine_ip'], registry=registry)为使得 /metrics 接口返回多个指标,我们引入了 CollectorRegistry ,并设置 gauge 的 registry 属性。
使用 set 方法设置 gauge 指标的值:
gauge.labels(‘127.0.0.1’).set(2)
访问 http://127.0.0.1:5000/metrics,浏览器增加输出:
# HELP my_gauge an example showed how to use gauge # TYPE my_gauge gauge my_gauge{machine_ip=”127.0.0.1″} 2.0
Histogram
Histogram 用于统计样本数值落在不同的桶(buckets)里面的数量。例如,统计应用程序的响应时间,可以使用 histogram 指标类型。
使用 Histogram 定义一个 historgram 指标:
buckets = (100, 200, 300, 500, 1000, 3000, 10000, float('inf'))
histogram = Histogram('my_histogram', 'an example showed how to use histogram', ['machine_ip'], registry=registry, buckets=buckets)如果我们不使用默认的 buckets,可以指定一个自定义的 buckets,如上面的代码所示。
使用 observe() 方法设置 histogram 的值:
histogram.labels(‘127.0.0.1’).observe(1001)
访问 /metrics 接口,输出:
# HELP my_histogram an example showed how to use histogram # TYPE my_histogram histogram my_histogram_bucket{le=”100.0″,machine_ip=”127.0.0.1″} 0.0 my_histogram_bucket{le=”200.0″,machine_ip=”127.0.0.1″} 0.0 my_histogram_bucket{le=”300.0″,machine_ip=”127.0.0.1″} 0.0 my_histogram_bucket{le=”500.0″,machine_ip=”127.0.0.1″} 0.0 my_histogram_bucket{le=”1000.0″,machine_ip=”127.0.0.1″} 0.0 my_histogram_bucket{le=”3000.0″,machine_ip=”127.0.0.1″} 1.0 my_histogram_bucket{le=”10000.0″,machine_ip=”127.0.0.1″} 1.0 my_histogram_bucket{le=”+Inf”,machine_ip=”127.0.0.1″} 1.0 my_histogram_count{machine_ip=”127.0.0.1″} 1.0 my_histogram_sum{machine_ip=”127.0.0.1″} 1001.0 # HELP my_histogram_created an example showed how to use histogram # TYPE my_histogram_created gauge my_histogram_created{machine_ip=”127.0.0.1″} 1.593260699767071e+09
由于我们设置了 histogram 的样本值为 1001,可以看到,从 3000 开始,xxx_bucket 的值为 1。由于只设置一个样本值,故 my_histogram_count 为 1 ,且样本总数 my_histogram_sum 为 1001。 读者可以自行试验几次,慢慢体会 histogram 指标的使用,远比看网上的文章理解得快。
Summary
Summary 和 histogram 类型类似,可用于统计数据的分布情况。
定义 summary 指标:
summary = Summary(‘my_summary’, ‘an example showed how to use summary’, [‘machine_ip’], registry=registry)
设置 summary 指标的值:
summary.labels(‘127.0.0.1’).observe(randint(1, 10))
访问 /metrics 接口,输出:
# HELP my_summary an example showed how to use summary # TYPE my_summary summary my_summary_count{machine_ip=”127.0.0.1″} 4.0 my_summary_sum{machine_ip=”127.0.0.1″} 16.0 # HELP my_summary_created an example showed how to use summary # TYPE my_summary_created gauge my_summary_created{machine_ip=”127.0.0.1″} 1.593263241728389e+09
附:完整源代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from random import randint
from flask import Flask, Response
from prometheus_client import Counter, Gauge, Histogram, Summary, \
generate_latest, CollectorRegistry
app = Flask(__name__)
registry = CollectorRegistry()
counter = Counter('my_counter', 'an example showed how to use counter', ['machine_ip'], registry=registry)
gauge = Gauge('my_gauge', 'an example showed how to use gauge', ['machine_ip'], registry=registry)
buckets = (100, 200, 300, 500, 1000, 3000, 10000, float('inf'))
histogram = Histogram('my_histogram', 'an example showed how to use histogram',
['machine_ip'], registry=registry, buckets=buckets)
summary = Summary('my_summary', 'an example showed how to use summary', ['machine_ip'], registry=registry)
@app.route('/metrics')
def hello():
counter.labels('127.0.0.1').inc(1)
gauge.labels('127.0.0.1').set(2)
histogram.labels('127.0.0.1').observe(1001)
summary.labels('127.0.0.1').observe(randint(1, 10))
return Response(generate_latest(registry), mimetype='text/plain')
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)参考资料
https://github.com/prometheus/client_python https://prometheus.io/docs/concepts/metric_types/ https://prometheus.io/docs/instrumenting/writing_clientlibs/ https://prometheus.io/docs/instrumenting/exporters/ https://pypi.org/project/prometheus-client/ https://prometheus.io/docs/concepts/metric_types/ http://www.coderdocument.com/docs/prometheus/v2.14/best_practices/histogram_and_summary.html https://prometheus.io/docs/practices/histograms/
总结
到此这篇关于使用 prometheus python 库编写自定义指标的文章就介绍到这了,更多相关prometheus python 库编写自定义指标内容请搜索ZaLou.Cn
#######sample 2.2 监控客户端指标类型和每个指标类型的场景
https://www.jianshu.com/p/5a0242327ec6
时间序列
-》每个时间序列都由其度量名称和称为标签的可选键值对唯一标识,度量名称指定了测得的系统的一般特征(例如http_requests_total-请求接收到的HTTP的总数),标签启用 Prometheus 的维度数据模型,查询语言允许基于这些维度进行过滤和聚合:
-
指标(metric):metric name和描述当前样本特征的labelsets;
-
时间戳(timestamp):一个精确到毫秒的时间戳;
-
样本值(value): 一个float64的浮点型数据表示当前样本的值。
<--------------- metric ---------------------><-timestamp -><-value->
http_request_total{status="200", method="GET"}-》指标类型 1 Counter:只增不减的计数器,常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标
-
通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Prometheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
prometheus_tsdb_compaction_chunk_range_bucket{le="1.6384e+06"} 260
prometheus_tsdb_compaction_chunk_range_bucket{le="6.5536e+06"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="2.62144e+07"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="+Inf"} 780
prometheus_tsdb_compaction_chunk_range_sum 1.1540798e+09
prometheus_tsdb_compaction_chunk_range_count 780
与Summary类型的指标相似之处在于Histogram类型的样本同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义。
Exporters
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
-
直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
-
间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
PushGateway
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
Node Exporter
在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。
特点
-
一个多维数据模型,具有由指标名称和键/值对标识的时间序列数据
-
多维度内置查询语法PromQL
-
通过pull的方式去获取时序数据
-
通过中间网关支持推送时间序列
-
通过服务发现或静态配置发现目标
-
多种图形和仪表板支持模式
时间序列
每个时间序列都由其度量名称和称为标签的可选键值对唯一标识,度量名称指定了测得的系统的一般特征(例如http_requests_total-请求接收到的HTTP的总数),标签启用 Prometheus 的维度数据模型,查询语言允许基于这些维度进行过滤和聚合:
-
指标(metric):metric name和描述当前样本特征的labelsets;
-
时间戳(timestamp):一个精确到毫秒的时间戳;
-
样本值(value): 一个float64的浮点型数据表示当前样本的值。
<--------------- metric ---------------------><-timestamp -><-value->
http_request_total{status="200", method="GET"}指标类型
在不同的场景下这些metric又有一些细微的差异,例如,在Node Exporter返回的样本中指标node_load1反应的是当前系统的负载状态,随着时间的变化这个指标返回的样本数据是在不断变化的。而指标node_cpu所获取到的样本数据却不同,它是一个持续增大的值,因为其反应的是CPU的累积使用时间,从理论上讲只要系统不关机,这个值是会无限变大的。
-
Counter:只增不减的计数器,常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标
通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])
查询当前系统中,访问量前10的HTTP地址:
topk(10, http_requests_total)
-
Gauge:可增可减的仪表盘,常见指标如,node_memory_MemAvailable
-
Summary和Histogram主用用于统计和分析样本的分布情况
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Prometheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
# HELP prometheus_tsdb_compaction_chunk_range Final time range of chunks on their first compaction
# TYPE prometheus_tsdb_compaction_chunk_range histogram
prometheus_tsdb_compaction_chunk_range_bucket{le="100"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="6400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="25600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="102400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="409600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1.6384e+06"} 260
prometheus_tsdb_compaction_chunk_range_bucket{le="6.5536e+06"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="2.62144e+07"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="+Inf"} 780
prometheus_tsdb_compaction_chunk_range_sum 1.1540798e+09
prometheus_tsdb_compaction_chunk_range_count 780
与Summary类型的指标相似之处在于Histogram类型的样本同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义。
使用PromQL查询监控数据
Prometheus UI是Prometheus内置的一个可视化管理界面,通过Prometheus UI用户能够轻松的了解Prometheus当前的配置,监控任务运行状态等。 通过Graph面板,用户还能直接使用PromQL实时查询监控数据。
通过PromQL我们可以非常方便的对数据进行查询,过滤,以及聚合,计算等操作。通过这些丰富的表达书语句,监控指标不再是一个单独存在的个体,而是一个个能够表达出正式业务含义的语言。
-
监控指标作为查询关键字
- node_load1 查询出Prometheus采集到的主机负载的样本数据
-
函数
-
rate(node_cpu[2m]) 通过CPU使用时间计算CPU的利用率
-
avg without(cpu) (rate(node_cpu[2m])) without表达式,将标签CPU去除后聚合数据即可
-
avg without(cpu) (rate(node_cpu{mode="idle"}[2m])) 排除系统闲置的CPU使用率即可获得
-
作者:chenjigang
链接:https://www.jianshu.com/p/5a0242327ec6
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
###sample 3 promsql 分析 学习PromQL 可以在promtues 服务器端,查看值的曲线。
4.PromQL快速入门_涂作权的博客的博客-CSDN博客_promql 正则
4.PromQL快速入门_涂作权的博客的博客-CSDN博客_promql 正则
PromQL的简单使用_huan_1993的博客-CSDN博客_promql表达式
4.PromQL快速入门
4.1.什么是 PromQL?
4.2.PromQL 基础用法
4.2.1.完全匹配
4.2.2.正则匹配
4.2.3.范围查询
4.2.4.时间位移操作
4.2.5.聚合操作
4.2.6.标量
4.2.7.字符串
4.3.PromQL操作符
4.3.1.数学运算符
4.3.2.布尔运算符
4.3.3.集合运算符
4.3.4.and 与操作
4.3.5.or 或操作
4.3.6.unless 排除操作
4.3.7.操作符优先级
4.4.PromQL 聚合操作
4.4.1.sum 求和
4.4.2.min 最小值
4.4.3.max 最大值
4.4.4.avg 平均值
4.4.5.stddev 标准差
4.4.6.count 计数
4.4.7.bottomk 后几条
4.4.8.topk 前几条
4.5.PromQL 内置函数
4.5.1.rate 增长率
4.5.2.predict_linear 增长预测
4.PromQL快速入门
本文转自:https://www.cnblogs.com/chanshuyi/p/04_quick_start_of_promql.html
中提到可以针对业务指标做自定义监控,其中有一个设置属性为 Metrics,即:
这个 Metrics 属性的值遵守了 PromQL 规则。我们只要学会了 PromQL 表达式,就知道了怎么设置这个属性了。
4.1.什么是 PromQL?
PromQL(Prometheus Query Language)是 Prometheus 内置的数据查询语言,它能实现对事件序列数据的查询、聚合、逻辑运算等。它并且被广泛应用在 Prometheus 的日常应用当中,包括对数据查询、可视化、告警处理当中。
简单地说,PromQL 广泛存在于以 Prometheus 为核心的监控体系中。所以需要用到数据筛选的地方,就会用到 PromQL。例如:监控指标的设置、报警指标的设置等等。
4.2.PromQL 基础用法
当Prometheus通过Exporter采集到相应的监控指标样本数据后,我们就可以通过PromQL对监控样本数据进行查询。
当我们直接使用监控指标名称查询时,可以查询该指标下的所有时间序列。我们这里启动 Prometheus 服务器,并打开 http://localhost:19090/graph 地址。在查询框中,我们输入:prometheus_http_requests_total 并点击执行。
可以看到我们查询出了所有指标名称为 prometheus_http_requests_total的数据。
PromQL 支持户根据时间序列的标签匹配模式来对时间序列进行过滤,目前主要支持两种匹配模式:完全匹配和正则匹配。
4.2.1.完全匹配
PromQL 支持使用 = 和 != 两种完全匹配模式。
等于。通过使用 label=value 可以选择那些标签满足表达式定义的时间序列。
不等于。通过使用 label!=value 则可以根据标签匹配排除时间序列。
例如我们上面查询出了所有指标名称为 prometheus_http_requests_total 的数据。这时候我们希望只查看错误的请求,即过滤掉所有 code 标签不是 200 的数据。那么我们的 PromQL 表达式可以修改为:prometheus_http_requests_total{code!=“200”}。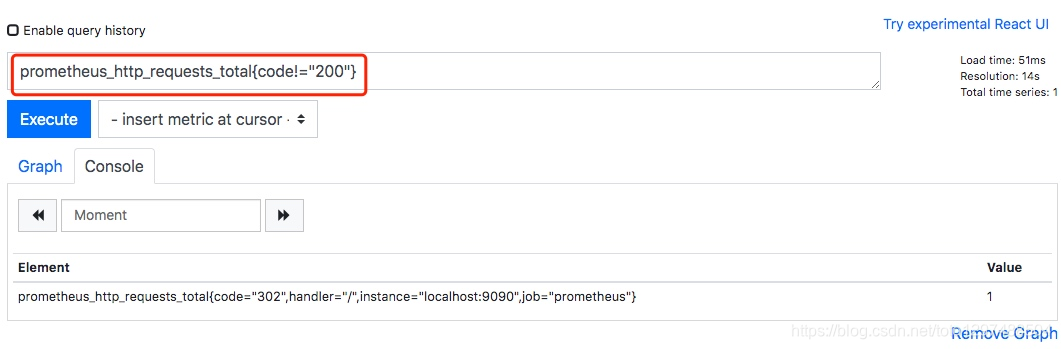
从上图可以看到,查询出的结果已经过滤掉了所有 code 不为 200 的数据。
4.2.2.正则匹配
PromQL 还可以使用正则表达式作为匹配条件,并且可以使用多个匹配条件。
正向匹配。使用 label=~regx 表示选择那些标签符合正则表达式定义的时间序列。
反向匹配。使用 label!~regx 进行排除。
例如我想查询指标 prometheus_http_requests_total 中,所有 handler 标签以 /api/v1 开头的记录,那么我的表达式为:prometheus_http_requests_total{handler=~"/api/v1/.*"}。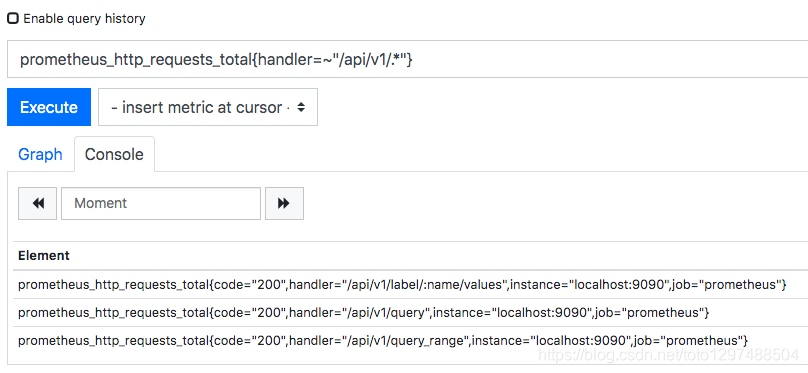
从上面的查询结果可以看出,查询的结果已经只保留了handler 标签以 /api/v1 开头的数据。
4.2.3.范围查询
我们上面直接通过类似 prometheus_http_requests_total 表达式查询时间序列时,同一个指标同一标签只会返回一条数据。这样的表达式我们称之为瞬间向量表达式,而返回的结果称之为瞬间向量。
而如果我们想查询一段时间范围内的样本数据,那么我们就需要用到区间向量表达式,其查询出来的结果称之为区间向量。时间范围通过时间范围选择器 [] 进行定义。例如,通过以下表达式可以选择最近5分钟内的所有样本数据:
prometheus_http_requests_total{}[5m]
- 1
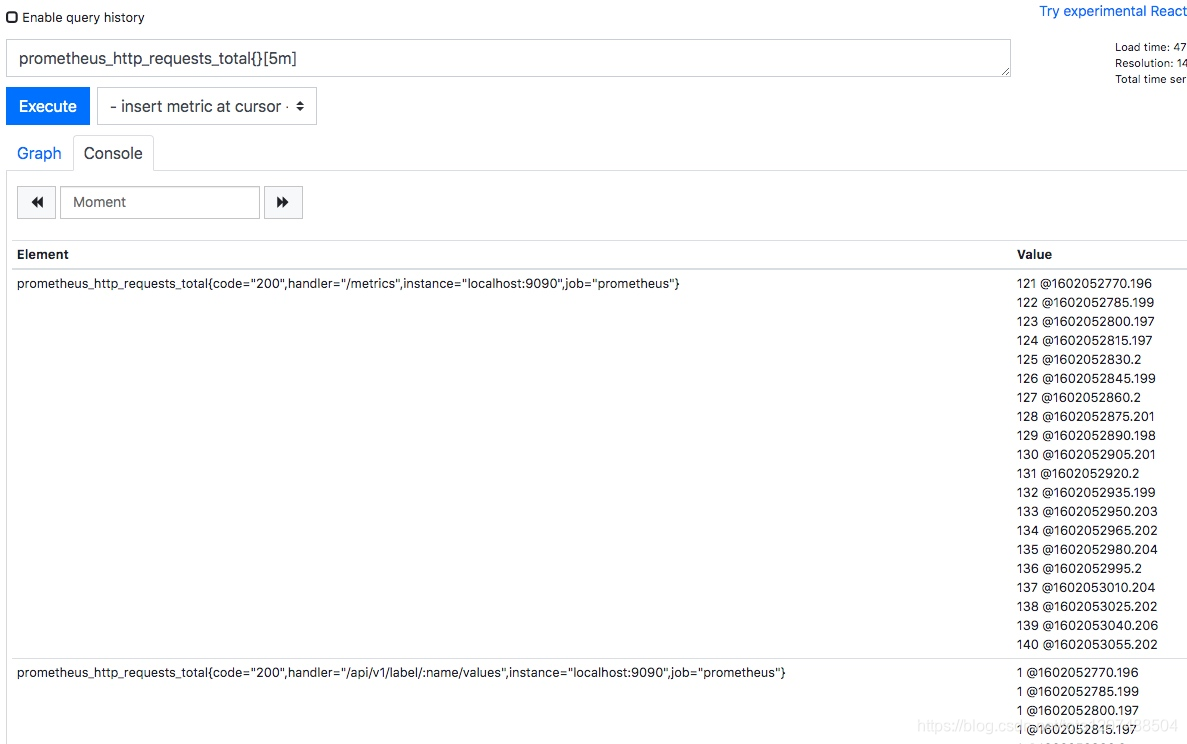
通过查询结果可以看到,此时我们查询出了所有的样本数据,而不再是一个样本数据的统计值。
除了使用m表示分钟以外,PromQL的时间范围选择器支持其它时间单位:
s - 秒
m - 分钟
h - 小时
d - 天
w - 周
y - 年
4.2.4.时间位移操作
在瞬时向量表达式或者区间向量表达式中,都是以当前时间为基准:
# 瞬时向量表达式,选择当前最新的数据
prometheus_http_requests_total{}
# 区间向量表达式,选择以当前时间为基准,5分钟内的数据
prometheus_http_requests_total{}[5m]
- 1
- 2
- 3
- 4
如果我们想查询 5 分钟前的瞬时样本数据,或昨天一天的区间内的样本数据呢? 这个时候我们就可以使用位移操作,位移操作的关键字为 offset。
# 查询 5 分钟前的最新数据
http_request_total{} offset 5m
# 往前移动 1 天,查询 1 天前的数据
# 例如现在是 2020-10-07 00:00:00
# 那么这个表达式查询的数据是:2020-10-05 至 2020-10-06 的数据
http_request_total{}[1d] offset 1d
- 1
- 2
- 3
- 4
- 5
- 6
4.2.5.聚合操作
一般情况下,我们通过 PromQL 查询到的数据都是很多的。PromQL 提供的聚合操作可以用来对这些时间序列进行处理,形成一条新的时间序列。
以我们的 prometheus_http_requests_total 指标为例,不加任何条件我们查询到的数据为: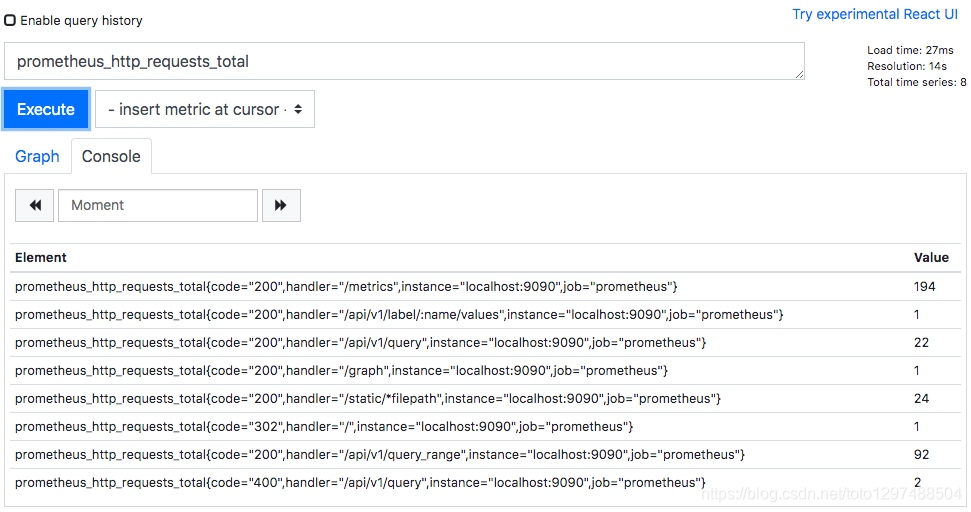
从上图查询结果可以知道,一共有 8 条数据,这 8 条数据的 value 总和为 307。那么我们使用下面两个聚合操作表达式来查询,看看结果对不对。
第一个表达式,计算一共有几条数据:count(prometheus_http_requests_total)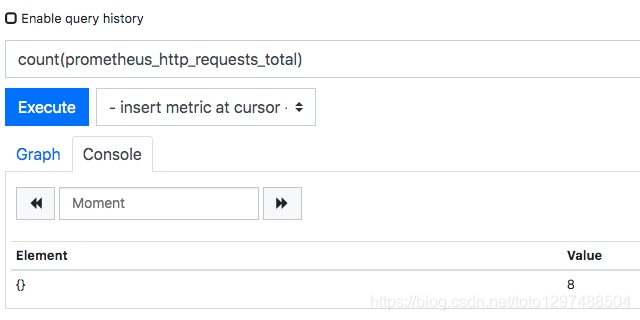
第二个表达式,计算所有数据的 value 总和:sum(prometheus_http_requests_total)
可以看到 count 的数值是一致的,都是 8。但是 sum 的数值有误差,这是因为我们两次查询的时间间隔内,某些记录的数值发生了变化。
4.2.6.标量
在 PromQL 中,标量是一个浮点型的数字值,没有时序。例如:10。
需要注意的是,当使用表达式count(http_requests_total),返回的数据类型,依然是瞬时向量。用户可以通过内置函数scalar()将单个瞬时向量转换为标量。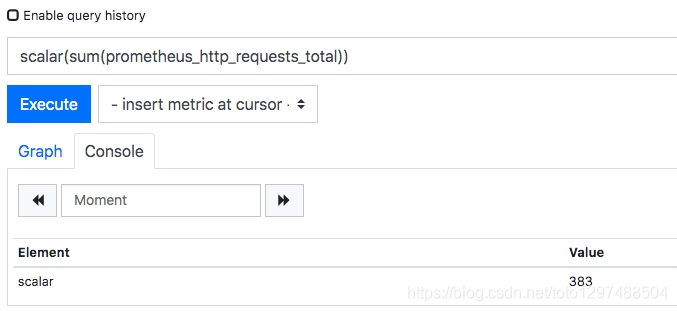
如上图所示,我们将 sum 操作的值用 scalar 转换了一下,最终的结果就是一个标量了。
4.2.7.字符串
在 PromQL 中,字符串是一个简单的字符串值。直接使用字符串作为 PromQL 表达式,则会直接返回字符串。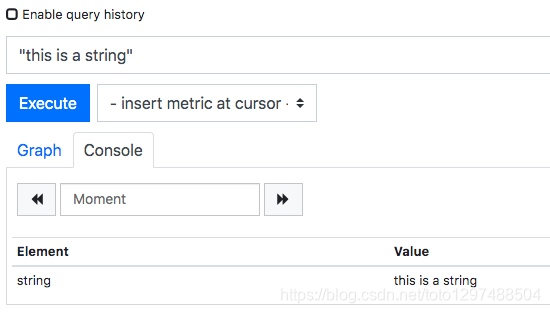
上图中我使用字符串 “this is a string” 直接作为 PromQL 查询表达式,结果返回的是一个字符串。
4.3.PromQL操作符
PromQL 还支持丰富的操作符,用户可以使用这些操作符对进一步的对事件序列进行二次加工。这些操作符包括:数学运算符,逻辑运算符,布尔运算符等等。
4.3.1.数学运算符
数学运算符比较简单,就是简单的加减乘除等。
例如我们通过prometheus_http_response_size_bytes_sum可以查询到Prometheus这个应用的 HTTP 响应字节总和。但是这个单位是字节,我们希望用 MB 显示。那么我们可以这么设置:prometheus_http_response_size_bytes_sum/8/1024
最终显示的数据就是以 MB 作为单位的数值。
PromQL支持的所有数学运算符如下所示:
+ (加法)
- (减法)
* (乘法)
/ (除法)
% (求余)
^ (幂运算)
4.3.2.布尔运算符
布尔运算符支持用户根据时间序列中样本的值,对时间序列进行过滤。例如我们可以通过 prometheus_http_requests_total 查询出每个接口的请求次数,但是如果我们想筛选出请求次数超过 20 次的接口呢?
此时我们可以用下面的 PromQL 表达式:
prometheus_http_requests_total > 20
- 1
可以看到我们将所有 value 值超过 20 的数据都筛选了出来,从其指标名称可以看出对应的接口名。
从上面的图中我们可以看到,value 的值还是具体的数值。但如果我们希望对符合条件的数据,value 变为 1。不符合条件的数据,value 变为 0。那么我们可以使用bool修饰符。
我们使用下面的 PromQL 表达式:
prometheus_http_requests_total > bool 20
- 1
从下面的执行结果可以看到,这时候并不过滤掉数据,而是将 value 的值变成了 1 或 0。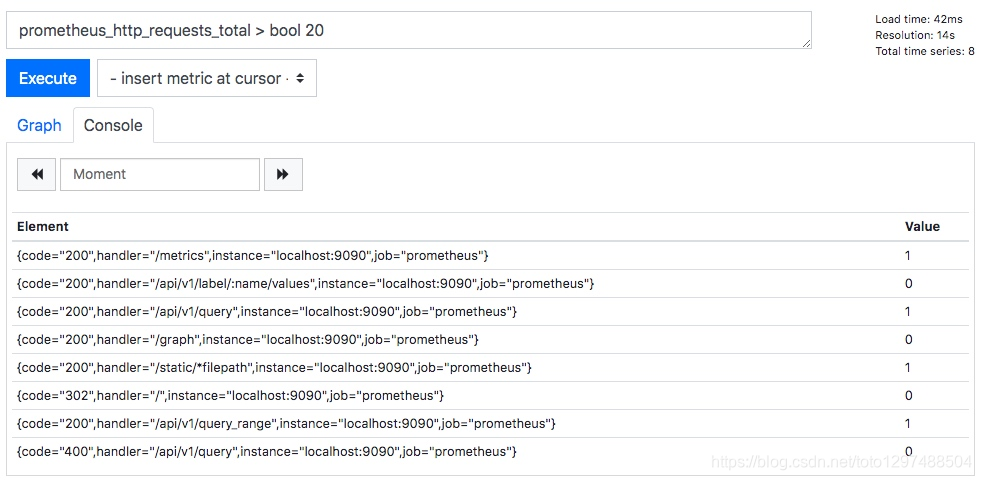
目前,Prometheus支持以下布尔运算符如下:
* == (相等)
!= (不相等)
> (大于)
< (小于)
>= (大于等于)
<= (小于等于)
4.3.3.集合运算符
通过集合运算,可以在两个瞬时向量与瞬时向量之间进行相应的集合操作。目前,Prometheus支持以下集合运算符:
and 与操作
or 或操作
unless 排除操作
4.3.4.and 与操作
vector1 and vector2 进行一个与操作,会产生一个新的集合。该集合中的元素同时在 vector1 和 vector2 中都存在。
例如我们有 vector1 为 A B C,vector2 为 B C D,那么 vector1 and vector2 的结果为:B C。
4.3.5.or 或操作
vector1 and vector2 进行一个或操作,会产生一个新的集合。该集合中包含 vector1 和 vector2 中的所有元素。
例如我们有 vector1 为 A B C,vector2 为 B C D,那么 vector1 or vector2 的结果为:A B C D。
4.3.6.unless 排除操作
vector1 and vector2 进行一个或操作,会产生一个新的集合。该集合首先取 vector1 集合的所有元素,然后排除掉所有在 vector2 中存在的元素。
例如我们有 vector1 为 A B C,vector2 为 B C D,那么 vector1 unless vector2 的结果为:A。
4.3.7.操作符优先级
在PromQL操作符中优先级由高到低依次为:
^
*, /, %
+, -
==, !=, <=, <, >=, >
and, unless
or
4.4.PromQL 聚合操作
Prometheus 还提供了聚合操作符,这些操作符作用于瞬时向量。可以将瞬时表达式返回的样本数据进行聚合,形成一个新的时间序列。目前支持的聚合函数有:
sum (求和)
min (最小值)
max (最大值)
avg (平均值)
stddev (标准差)
stdvar (标准方差)
count (计数)
count_values (对value进行计数)
bottomk (后n条时序)
topk (前n条时序)
quantile (分位数)
4.4.1.sum 求和
用于对记录的 value 值进行求和。
例如:sum(prometheus_http_requests_total) 表示统计所有 HTTP 请求的次数。
4.4.2.min 最小值
返回所有记录的最小值。
prometheus_http_requests_total 指标所有数据如下图所示:
当我们执行如下 PromQL 时,会筛选出最小的记录值。
min(prometheus_http_requests_total)
- 1
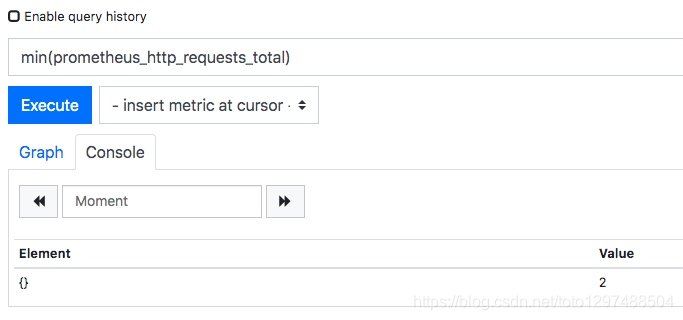
4.4.3.max 最大值
返回所有记录的最大值。
当我们执行如下 PromQL 时,会筛选出最大的记录值。
max(prometheus_http_requests_total)
- 1

4.4.4.avg 平均值
avg 函数返回所有记录的平均值。
当我们执行如下 PromQL 时,会筛选出最大的记录值。
avg(prometheus_http_requests_total)
- 1

4.4.5.stddev 标准差
标准差(Standard Deviation)常用来描述数据的波动大小。例如我们统计篮球队员身高:
两支队伍平均身高都是 180,看起来似乎差不多。但如果画图的话,得到结果如下:
很显然,蓝色队队员身高更加整齐一些,橙色队身高显得参差不齐。为了反映一组数据,偏离平均值的程度,就有了「标准差 」这个概念。
如果数据量很大,比如几万人的身高,我们不容易从折线图看出来,可以直接用公式计算。上图的数据标准差计算结果为:
很明显,橙色队的标准差比蓝色队标准差大很多。这说明橙色队的身高波动更大。
当我们执行如下 PromQL 时,会计算出不同 HTTP 请求的数量波动情况。
stddev(prometheus_http_requests_total)
- 1

从计算结果可以看到,标准差达到了 1100 多,这说明其数据波动非常大。
4.4.6.count 计数
count 函数返回所有记录的计数。
例如:count(prometheus_http_requests_total) 表示统计所有 HTTP 请求的次数。
4.4.7.bottomk 后几条
bottomk 用于对样本值进行排序,返回当前样本值后 N 位的时间序列。
例如获取 HTTP 请求量后 5 位的请求,可以使用表达式:
bottomk(5, prometheus_http_requests_total)
- 1

4.4.8.topk 前几条
topk 用于对样本值进行排序,返回当前样本值前 N 位的时间序列。
例如获取 HTTP 请求量前 5 位的请求,可以使用表达式:
topk(5, prometheus_http_requests_total)
- 1

4.5.PromQL 内置函数
PromQL 提供了大量的内置函数,可以对时序数据进行丰富的处理。例如 irate() 函数可以帮助我们计算监控指标的增长率,不需要我们去手动计算。
4.5.1.rate 增长率
我们知道 counter 类型指标的特点是只增不减,在没有发生重置的情况下,其样本值是不断增大的。为了能直观地观察期变化情况,需要计算样本的增长率。
increase(v range-vector) 函数是 PromQL 中提供的众多内置函数之一。其中参数 v 是一个区间向量,increase 函数获取区间向量中的第一个后最后一个样本并返回其增长量。因此,可以通过以下表达式Counter类型指标的增长率:
increase(node_cpu[2m]) / 120
- 1
这里通过node_cpu[2m]获取时间序列最近两分钟的所有样本,increase计算出最近两分钟的增长量,最后除以时间120秒得到node_cpu样本在最近两分钟的平均增长率。并且这个值也近似于主机节点最近两分钟内的平均CPU使用率。
除了使用increase函数以外,PromQL中还直接内置了rate(v range-vector)函数,rate函数可以直接计算区间向量v在时间窗口内平均增长速率。因此,通过以下表达式可以得到与increase函数相同的结果:
rate(node_cpu[2m])
- 1
需要注意的是使用rate或者increase函数去计算样本的平均增长速率,容易陷入「长尾问题」当中,其无法反应在时间窗口内样本数据的突发变化。
例如,对于主机而言在 2 分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致 CPU 占用 100% 的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。
为了解决该问题,PromQL提供了另外一个灵敏度更高的函数 irate(v range-vector)。irate 同样用于计算区间向量的计算率,但是其反应出的是瞬时增长率。irate 函数是通过区间向量中最后两个样本数据来计算区间向量的增长速率。
这种方式可以避免在时间窗口范围内的「长尾问题」,并且体现出更好的灵敏度,通过 irate 函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
irate(node_cpu[2m])
- 1
irate函数相比于rate函数提供了更高的灵敏度,不过当需要分析长期趋势或者在告警规则中,irate的这种灵敏度反而容易造成干扰。因此在长期趋势分析或者告警中更推荐使用rate函数。
4.5.2.predict_linear 增长预测
在一般情况下,系统管理员为了确保业务的持续可用运行,会针对服务器的资源设置相应的告警阈值。例如,当磁盘空间只剩512MB时向相关人员发送告警通知。 这种基于阈值的告警模式对于当资源用量是平滑增长的情况下是能够有效的工作的。
但是如果资源不是平滑变化的呢? 比如有些某些业务增长,存储空间的增长速率提升了高几倍。这时,如果基于原有阈值去触发告警,当系统管理员接收到告警以后可能还没来得及去处理问题,系统就已经不可用了。
因此阈值通常来说不是固定的,需要定期进行调整才能保证该告警阈值能够发挥去作用。 那么还有没有更好的方法吗?
PromQL 中内置的 predict_linear(v range-vector, t scalar) 函数可以帮助系统管理员更好的处理此类情况,predict_linear 函数可以预测时间序列v在t秒后的值。
它基于简单线性回归的方式,对时间窗口内的样本数据进行统计,从而可以对时间序列的变化趋势做出预测。例如,基于2小时的样本数据,来预测主机可用磁盘空间的是否在4个小时候被占满,可以使用如下表达式:
predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0
####sample 3 promsql 使用实际例子
(55条消息) Prometheus 监控基础_CCULin的博客-CSDN博客
Prometheus 监控基础
监控系统基础
监控系统发展史
SNMP监控时代
第一代主要是监控网络流量和网络设置为主的时代,在那个时代主要是通过SNMP协议监控交换机、路由器、网关、操作系统等,通过互联网日益增长的需求,这种简单的通过SNMP协议实现的监控手段并不能满足现有需求,因此这种监控手段逐渐被替代。
当今的监控系统
当今比较流行的监控系统有Prometheus、Zabbix、Nagios、Cacti、Ganglia,它们都有几个基本特点就是对操作系统的监控数据采集、存储及展示。
未来的监控系统
目前一些大厂或多多少的接触到,比如基于Data的DataOps,基于AI的AIOps,他们背后都要或多或少基于一个立体监控系统,完成对于系统运行状态的分析与监控,最后反馈到系统监控中心去。大多数系统现在还处于非自治状态,对于这种非自治状态的系统对于管理者来讲需要对其进行深入的监控,以及了解它的运行特性而后做出响应的决策。我们不但要做事前监控还要做事后监控。监控系统是我们运维体系中不可缺少的基础服务,而且随着人工智能、大数据的发展,基于DataOps、AIOps的未来监控甚嚣尘上。
监控系统组件
指标数据采集
指标数据存储
指标数据分析及可视化
告警通知
监控系统,一般而言,它无非就是对于每一个被监控的目标,或者我们要监控的系统中的组件,(比如一个主机、交换机、网关、应用、基础服务、某个业务特征等),对于这么一个基础设施层,我们要对它内部的运行的各种关键数据,通常是一种随时间变化的数据,我们一般把它叫做指标数据,然后我们采集这些指标数据,通常会得到一些点状数据,这些点状数据我们称之为样本数据,为了能够做事后分析,我们需要把它存储下来,所以对于存储这块,需要具备持续读写的性能的支撑,在存储这些样本数据后,我们需要根据样本数据做一些分析,得出当前系统运行状态,甚至后续预测出是否会出现的问题,通常这些样本数据可以通过一个UI界面服务呈现给我们查看,最后监控系统还需要有告警通知服务,通过设置一些规则我们就能提前得到系统运行状态的信息。
一、Prometheus 监控平台简介
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。2016年5月继Kubernetes之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。
Prometheus作为新一代的云原生监控系统,目前已经有超过650+位贡献者参与到Prometheus的研发工作上,并且超过120+项的第三方集成。
Prometheus的优势
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。 相比于传统监控系统Prometheus具有以下优点:
易于管理
Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
Prometheus基于Pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统。对于一些复杂的情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
监控服务的内部运行状态
Prometheus鼓励用户监控服务的内部状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
强大的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。如下所示:
http_request_status{code='200',content_path='/api/path', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
http_request_status{code='200',content_path='/api/path2', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
1
2
每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识。每条时间序列按照时间的先后顺序存储一系列的样本值。
表示维度的标签可能来源于你的监控对象的状态,比如code=404或者content_path=/api/path。也可能来源于的你的环境定义,比如environment=produment。基于这些Labels我们可以方便地对监控数据进行聚合,过滤,裁剪。
强大的查询语言PromQL
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
高效
对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而Prometheus可以高效地处理这些数据,对于单一Prometheus Server实例而言它可以处理:
数以百万的监控指标
每秒处理数十万的数据点
可扩展
Prometheus是如此简单,因此你可以在每个数据中心、每个团队运行独立的Prometheus Sevrer。
Prometheus对于联邦集群的支持,可以让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)可以对其进行扩展。
易于集成
使用Prometheus可以快速搭建监控服务,并且可以非常方便地在应用程序中进行集成。目前支持: Java、JMX、 Python、 Go、Ruby、 .Net、 Node.js等等语言的客户端SDK,基于这些SDK可以快速让应用程序纳入到Prometheus的监控当中,或者开发自己的监控数据收集程序。同时这些客户端收集的监控数据,不仅仅支持Prometheus,还能支持Graphite这些其他的监控工具。
同时Prometheus还支持与其他的监控系统进行集成:Graphite、Statsd、Collected、Scollector、muini、Nagios等。
Prometheus社区还提供了大量第三方实现的监控数据采集支持:JMX, CloudWatch, EC2, MySQL, PostgresSQL, Haskell, Bash, SNMP, Consul, Haproxy, Mesos, Bind, CouchDB, Django, Memcached, RabbitMQ, Redis, RethinkDB, Rsyslog等等。
可视化
Prometheus Server中自带了一个Prometheus UI,通过这个UI可以方便地直接对数据进行查询,并且支持直接以图形化的形式展示数据。同时Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案Promdash。最新的Grafana可视化工具也已经提供了完整的Prometheus支持,基于Grafana可以创建更加精美的监控图标。基于Prometheus提供的API还可以实现自己的监控可视化UI。
开放性
通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持。因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制。对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于Prometheus来说,使用Prometheus的client library的输出格式不止支持Prometheus的格式化数据,也可以输出支持其它监控系统的格式化数据,比如Graphite。
因此你甚至可以在不使用Prometheus的情况下,采用Prometheus的client library来让你的应用程序支持监控数据采集。
二、初识 Prometheus
Prometheus是一个开放性的监控解决方案,用户可以非常方便的安装和使用Prometheus并且能够非常方便的对其进行扩展。为了能够更加直观的了解Prometheus Server,接下来我们将在本地部署并运行一个Prometheus Server实例,通过Node Exporter采集当前主机的系统资源使用情况。 并通过Grafana创建一个简单的可视化仪表盘。
安装Prometheus Server
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。用户只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启动Prometheus Server。
从二进制包安装
对于非Docker用户,可以从https://prometheus.io/download/找到最新版本的Prometheus Sevrer软件包:
这里我们下载prometheus-2.24.1.linux-amd64.tar.gz,解压,并将Prometheus相关的命令,添加到系统环境变量路径即可:
tar -xzf prometheus-2.24.1.linux-amd64.tar.gz
cd prometheus-2.24.1.linux-amd64
1
2
解压后当前目录会包含默认的Prometheus配置文件promethes.yml:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Promtheus作为一个时间序列数据库,其采集的数据会以文件的形式存储在本地中,默认的存储路径为data/,因此我们需要先手动创建该目录:
mkdir -p data
1
用户也可以通过参数--storage.tsdb.path="/data/promethes-data/"修改本地数据存储的路径。
启动prometheus服务,其会默认加载当前路径下的prometheus.yaml文件:
./prometheus
1
正常的情况下,你可以看到以下输出内容:
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:326 msg="No time or size retention was set so using the default time retention" duration=15d
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:364 msg="Starting Prometheus" version="(version=2.24.1, branch=HEAD, revision=e4487274853c587717006eeda8804e597d120340)"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:369 build_context="(go=go1.15.6, user=root@0b5231a0de0f, date=20210120-00:09:36)"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:370 host_details="(Linux 4.4.0-62-generic #83-Ubuntu SMP Wed Jan 18 14:10:15 UTC 2017 x86_64 sc-stable-ops-tools-001 (none))"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:371 fd_limits="(soft=1024, hard=1048576)"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:372 vm_limits="(soft=unlimited, hard=unlimited)"
level=info ts=2021-01-21T12:23:06.184Z caller=web.go:530 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2021-01-21T12:23:06.185Z caller=main.go:738 msg="Starting TSDB ..."
level=info ts=2021-01-21T12:23:06.186Z caller=tls_config.go:191 component=web msg="TLS is disabled." http2=false
level=info ts=2021-01-21T12:23:06.190Z caller=head.go:645 component=tsdb msg="Replaying on-disk memory mappable chunks if any"
level=info ts=2021-01-21T12:23:06.190Z caller=head.go:659 component=tsdb msg="On-disk memory mappable chunks replay completed" duration=2.863µs
level=info ts=2021-01-21T12:23:06.190Z caller=head.go:665 component=tsdb msg="Replaying WAL, this may take a while"
level=info ts=2021-01-21T12:23:06.191Z caller=head.go:717 component=tsdb msg="WAL segment loaded" segment=0 maxSegment=0
level=info ts=2021-01-21T12:23:06.191Z caller=head.go:722 component=tsdb msg="WAL replay completed" checkpoint_replay_duration=15.9µs wal_replay_duration=220.764µs total_replay_duration=256.654µs
level=info ts=2021-01-21T12:23:06.192Z caller=main.go:758 fs_type=EXT4_SUPER_MAGIC
level=info ts=2021-01-21T12:23:06.192Z caller=main.go:761 msg="TSDB started"
level=info ts=2021-01-21T12:23:06.192Z caller=main.go:887 msg="Loading configuration file" filename=/opt/prometheus/current/prometheus.yml
level=info ts=2021-01-21T12:23:06.194Z caller=main.go:918 msg="Completed loading of configuration file" filename=/opt/prometheus/current/prometheus.yml totalDuration=1.122768ms remote_storage=2.079µs web_handler=488ns query_engine=901ns scrape=220.418µs scrape_sd=37.452µs notify=26.64µs notify_sd=18.238µs rules=5.187µs
level=info ts=2021-01-21T12:23:06.194Z caller=main.go:710 msg="Server is ready to receive web requests."
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
使用容器安装
对于Docker用户,直接使用Prometheus的镜像即可启动Prometheus Server:
docker run -p 9090:9090 -v /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
1
启动完成后,可以通过http://localhost:9090访问Prometheus的UI界面:
使用Node Exporter采集主机数据
安装Node Exporter
在Prometheus的架构设计中,Prometheus Server并不直接提供监控特定目标的服务,其主要任务负责数据的收集、存储并且对外提供数据查询支持。因此为了能够监控到服务器状态,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
从上面的描述中可以看出Exporter是一个相对开放的概念,可能是一个独立运行的程序独立于监控目标之外,也可能是直接内置在监控目标中。只要能够向Prometheus提供标准格式的监控样本数据即可。
这里为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/获取最新的node exporter版本的二进制包。
tar xf node_exporter-1.0.1.linux-amd64.tar.gz
cd node_exporter-1.0.1.linux-amd64 && ls
LICENSE node_exporter NOTICE
1
2
3
运行node exporter:
mv node_exporter /usr/local/bin/
node_exporter
1
2
启动成功后,可以看到以下输出:
level=info ts=2021-01-21T12:55:05.965Z caller=node_exporter.go:191 msg="Listening on" address=:9100
1
初始Node Exporter监控指标
本地机器访问127.0.0.1:9100/metrics,我们会看到很多机器状态指标:
curl 127.0.0.1:9100/metrics
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 3.0703125
1
2
3
4
5
6
7
其中HELP用于解释当前指标的含义,TYPE则说明当前指标的数据类型。在上面的例子中node_cpu的注释表明当前指标是cpu0上idle进程占用CPU的总时间,CPU占用时间是一个只增不减的度量指标,从类型中也可以看出node_cpu的数据类型是计数器(counter),与该指标的实际含义一致。又例如node_load1该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为仪表盘(gauge),与指标反映的实际含义一致。
除了这些以外,在当前页面中根据物理主机系统的不同,你还可能看到如下监控指标:
node_boot_time:系统启动时间
node_cpu:系统CPU使用量
node_disk_io_*:磁盘IO
node_filesystem_*:文件系统用量
node_load1:系统负载
node_memory_*:内存使用
node_network*:网络带宽
node_time:当前系统时间
go_*:node exporter中go相关指标
process_*:node exporter自身进程相关运行指标
从Node Exporter收集监控数据
为了能够让Prometheus Server能够从当前node exporter获取到监控数据,这里需要修改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['172.17.40.65:9100', '172.17.40.66:9100', '172.17.40.67:9100']
1
2
3
4
5
6
7
8
重新启动Prometheus Server
访问http://localhost:9090,进入到Prometheus Server。如果输入“up”并且点击执行按钮以后,可以看到如下结果:
如果Prometheus能够正常从node exporter获取数据,则会看到以下结果:
up{instance="localhost:9090",job="prometheus"} 1
up{instance="172.17.40.67:9100",job="node"} 1
1
2
其中“1”表示正常,反之“0”则为异常。
使用PromQL查询监控数据
Prometheus UI是Prometheus内置的一个可视化管理界面,通过Prometheus UI用户能够轻松的了解Prometheus当前的配置,监控任务运行状态等。 通过Graph面板,用户还能直接使用PromQL实时查询监控数据。
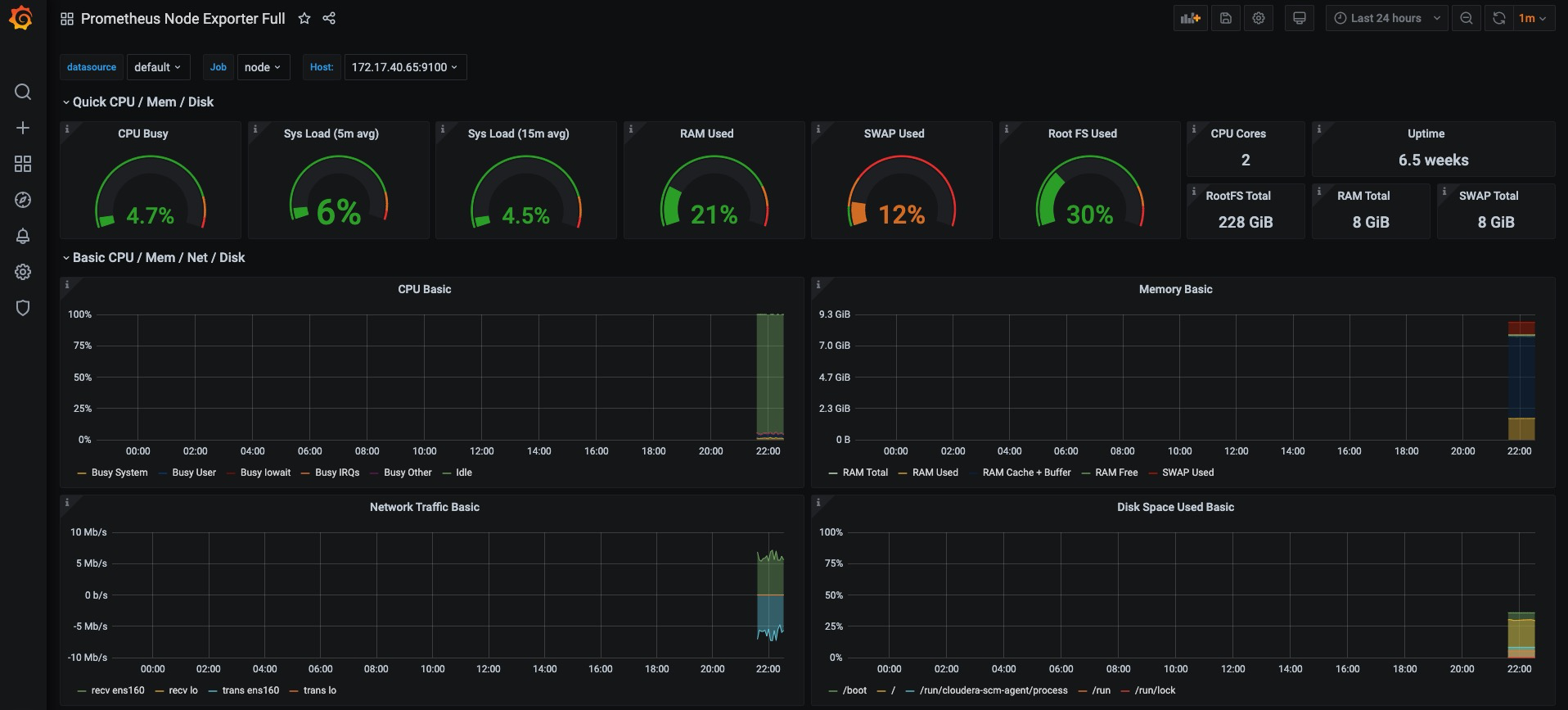
切换到Graph面板,用户可以使用PromQL表达式查询特定监控指标的监控数据。如下所示,查询主机负载变化情况,可以使用关键字node_load1可以查询出Prometheus采集到的主机负载的样本数据,这些样本数据按照时间先后顺序展示,形成了主机负载随时间变化的趋势图表:
PromQL是Prometheus自定义的一套强大的数据查询语言,除了使用监控指标作为查询关键字以为,还内置了大量的函数,帮助用户进一步对时序数据进行处理。例如使用rate()函数,可以计算在单位时间内样本数据的变化情况即增长率,因此通过该函数我们可以近似的通过CPU使用时间计算CPU的利用率:
rate(node_cpu_seconds_total[2m])
1
这时如果要忽略是哪一个CPU的,只需要使用without表达式,将标签CPU去除后聚合数据即可:
avg without(cpu) (rate(node_cpu[2m]))
1
那如果需要计算系统CPU的总体使用率,通过排除系统闲置的CPU使用率即可获得:
1 - avg without(cpu) (rate(node_cpu{mode="idle"}[2m]))
1
通过PromQL我们可以非常方便的对数据进行查询,过滤,以及聚合,计算等操作。通过这些丰富的表达书语句,监控指标不再是一个单独存在的个体,而是一个个能够表达出正式业务含义的语言。
监控数据可视化
Prometheus UI提供了快速验证PromQL以及临时可视化支持的能力,而在大多数场景下引入监控系统通常还需要构建可以长期使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如Grafana,Grafana是一个开源的可视化平台,并且提供了对Prometheus的完整支持。
docker run -d -p 3000:3000 grafana/grafana
1
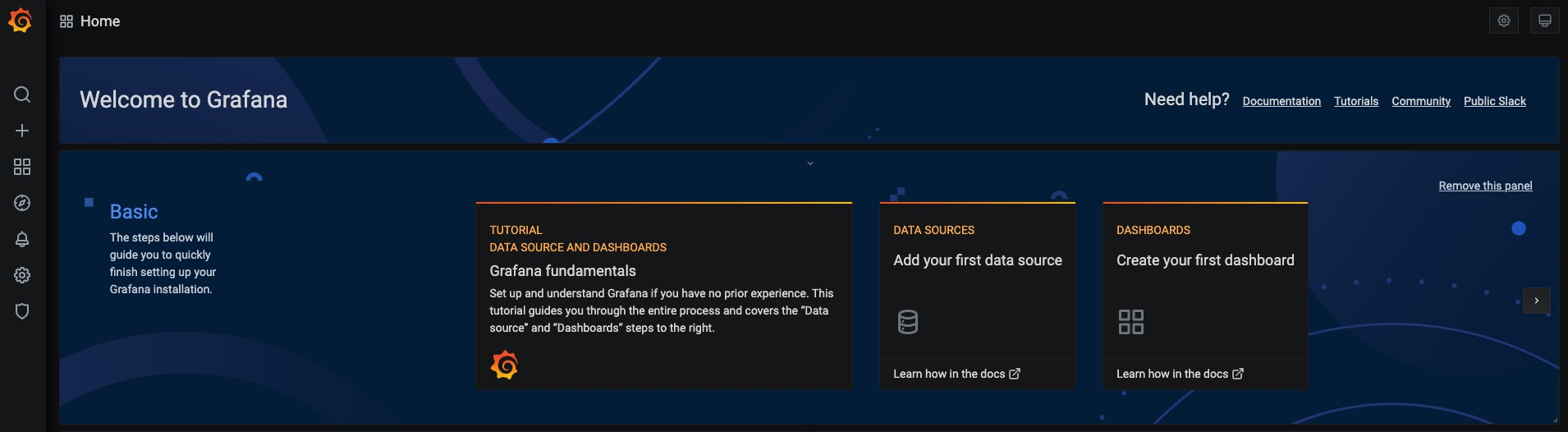
访问http://localhost:3000就可以进入到Grafana的界面中,默认情况下使用账户admin/admin进行登录。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件等主要流程:
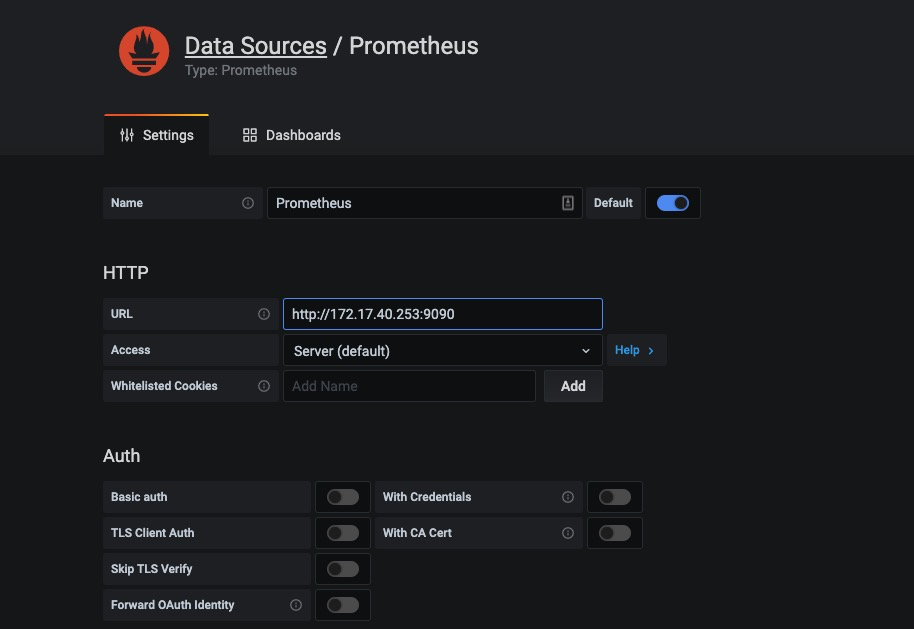
这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus并且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示连接成功的信息:
在完成数据源的添加之后就可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard并且为该Dashboard添加一个panel。 并在该面板的“Query”选项下通过PromQL查询需要可视化的数据:
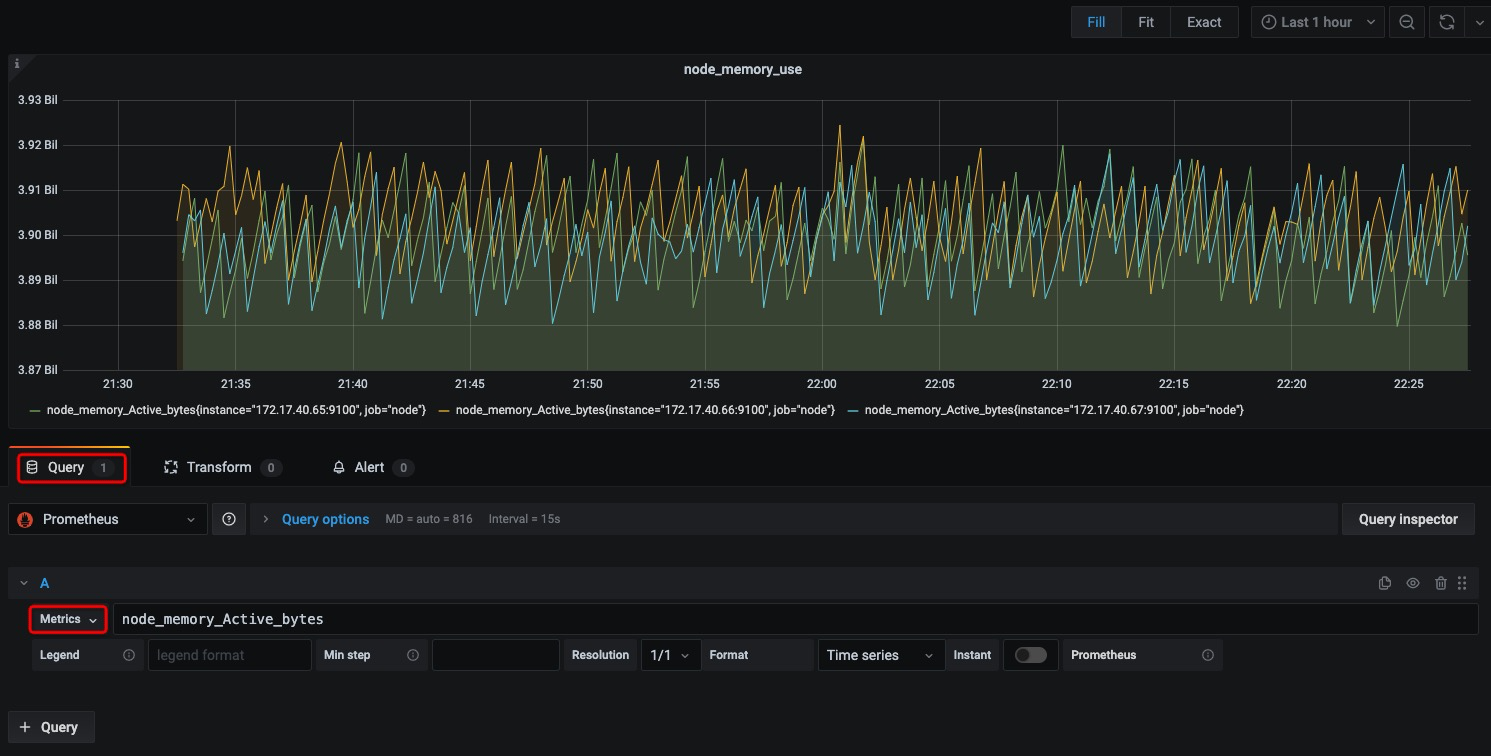
点击界面中的保存选项,就创建了我们的第一个可视化Dashboard了。 当然作为开源软件,Grafana社区鼓励用户分享Dashboard通过https://grafana.com/dashboards网站,可以找到大量可直接使用的Dashboard:
Grafana中所有的Dashboard通过JSON进行共享,下载并且导入这些JSON文件,就可以直接使用这些已经定义好的Dashboard:
任务和实例
通过在prometheus.yml配置文件中,添加如下配置。我们让Prometheus可以从node exporter暴露的服务中获取监控指标数据。
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['172.17.40.65:9100', '172.17.40.66:9100', '172.17.40.67:9100']
1
2
3
4
5
6
7
当我们需要采集不同的监控指标(例如:主机、MySQL、Nginx)时,我们只需要运行相应的监控采集程序,并且让Prometheus Server知道这些Exporter实例的访问地址。在Prometheus中,每一个暴露监控样本数据的HTTP服务称为一个实例。例如在当前主机上运行的node exporter可以被称为一个实例(Instance)。
而一组用于相同采集目的的实例,或者同一个采集进程的多个副本则通过一个一个任务(Job)进行管理。
* job: node
* instance 2: 172.17.40.65:9100
* instance 4: 172.17.40.66:9100
1
2
3
当前在每一个Job中主要使用了静态配置(static_configs)的方式定义监控目标。除了静态配置每一个Job的采集Instance地址以外,Prometheus还支持与DNS、Consul、E2C、Kubernetes等进行集成实现自动发现Instance实例,并从这些Instance上获取监控数据。
除了通过使用“up”表达式查询当前所有Instance的状态以外,还可以通过Prometheus UI中的Targets页面查看当前所有的监控采集任务,以及各个任务下所有实例的状态:
Prometheus核心组件
通过部署Node Exporter我们成功的获取到了当前主机的资源使用情况。接下来我们将从Prometheus的架构角度详细介绍Prometheus生态中的各个组件。
下图展示Prometheus的基本架构:
Prometheus Server
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Server需要对采集到的监控数据进行存储,Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server对外提供了自定义的PromQL语言,实现对数据的查询以及分析。
Prometheus Server内置的Express Browser UI,通过这个UI可以直接通过PromQL实现数据的查询以及可视化。
Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据,因此在大规模监控的情况下,可以通过联邦集群以及功能分区的方式对Prometheus Server进行扩展。
Exporters
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
PushGateway
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
参考链接:
https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/quickstart
————————————————
版权声明:本文为CSDN博主「CCULin」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/CCjedweat/article/details/113752818
监控数据可视化Prometheus UI提供了快速验证PromQL以及临时可视化支持的能力,而在大多数场景下引入监控系统通常还需要构建可以长期使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如Grafana,Grafana是一个开源的可视化平台,并且提供了对Prometheus的完整支持。
docker run -d -p 3000:3000 grafana/grafana1访问http://localhost:3000就可以进入到Grafana的界面中,默认情况下使用账户admin/admin进行登录。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件等主要流程:
这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus并且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示连接成功的信息:
在完成数据源的添加之后就可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard并且为该Dashboard添加一个panel。 并在该面板的“Query”选项下通过PromQL查询需要可视化的数据:
点击界面中的保存选项,就创建了我们的第一个可视化Dashboard了。 当然作为开源软件,Grafana社区鼓励用户分享Dashboard通过https://grafana.com/dashboards网站,可以找到大量可直接使用的Dashboard:
Grafana中所有的Dashboard通过JSON进行共享,下载并且导入这些JSON文件,就可以直接使用这些已经定义好的Dashboard:
任务和实例————————————————版权声明:本文为CSDN博主「CCULin」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/CCjedweat/article/details/113752818
### sample 5 prometheus promql查询表达式
https://www.cnblogs.com/ZhongzhouChen/p/11696792.html
sample 5 prometheus promql查询表达式
Basics
即时矢量选择器
=:匹配与标签相等的内容
!=:不匹配与标签相等的内容
=~: 根据正则表达式匹配与标签符合的内容
!~:根据正则表达式不匹配与标签符合的内容
示例:
http_requests_total{environment=~"staging|testing|development",method!="GET"} #这将匹配method不等于GET,environment匹配到staging,testing或development的http_requests_total请求内容。
向量选择器必须指定一个名称或至少一个与空字符串不匹配的标签匹配器。以下表达式是非法的
{job=~"."} # Bad!
相反,这些表达式是有效的,因为它们都有一个与空标签值不匹配的选择器。
{job=~".+"} # Good!
{job=~".",method="get"} # Good!
范围矢量选择器
持续时间仅限于数字,接下来是以下单位之一:
s - seconds
m - minutes
h - hours
d - days
w - weeks
y - years
在此示例中,我们选择在过去5分钟内为度量标准名称为http_requests_total且标签设置为job=prometheus的所有时间序列记录的所有值:
http_requests_total{job="prometheus"}[5m]
偏移量修改器
偏移修改器允许更改查询中各个即时和范围向量的时间偏移。
例如,以下表达式相对于当前查询5分钟前的http_requests_total值:
http_requests_total offset 5m
注意,偏移修改器需要立即跟随选择器,即以下内容是正确的:
sum(http_requests_total{method="GET"} offset 5m) // GOOD.
以下内容是不正确的:
sum(http_requests_total{method="GET"}) offset 5m // INVALID.
同样适用于范围向量。这将返回http_requests_total一周前的5分钟增长率:
rate(http_requests_total[5m] offset 1w)
OPERATORS
二元运算符
算术二元运算符
Prometheus中存在以下二进制算术运算符:
(addition)
(subtraction)
(multiplication)
/ (division)
% (modulo)
^ (power/exponentiation)
比较二元运算符
== (equal)
!= (not-equal)
(greater-than)
< (less-than)
= (greater-or-equal)
<= (less-or-equal)
逻辑/集二进制运算符
and (intersection)
or (union)
unless (complement)
一对一矢量匹配
一对一从操作的每一侧找到唯一的条目对。在默认情况下,这是格式为vector1 vector2之后的操作。如果两个条目具有完全相同的标签集和相应的值,则它们匹配。 ignore关键字允许在匹配时忽略某些标签,而on关键字允许将所考虑的标签集减少到提供的列表:
ignoring()
on()
Example input:
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
Example query:
method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m
这将返回一个结果向量,其中包含每个方法的状态代码为500的HTTP请求部分,在过去5分钟内测量。在不忽略(代码)的情况下,由于度量标准不共享同一组标签,因此不会匹配。方法put和del的条目没有匹配,并且不会显示在结果中:
{method="get"} 0.04 // 24 / 600
{method="post"} 0.05 // 6 / 120
多对一和一对多矢量匹配
多对一和一对多匹配指的是"一"侧的每个向量元素可以与"多"侧的多个元素匹配的情况。必须使用group_left或group_right修饰符明确请求,其中left/right确定哪个向量具有更高的基数。
ignoring() group_left()
ignoring() group_right()
on() group_left()
on() group_right()
Example query:
method_code:http_errors:rate5m / ignoring(code) group_left method:http_requests:rate5m
在这种情况下,左向量每个方法标签值包含多个条目。因此,我们使用group_left表明这一点。右侧的元素现在与多个元素匹配,左侧具有相同的方法标签:
{method="get", code="500"} 0.04 // 24 / 600
{method="get", code="404"} 0.05 // 30 / 600
{method="post", code="500"} 0.05 // 6 / 120
{method="post", code="404"} 0.175 // 21 / 120
多对一和一对多匹配是高级用例,应该仔细考虑。通常正确使用忽略()可提供所需的结果。
聚合运算符
Prometheus支持以下内置聚合运算符,这些运算符可用于聚合单个即时向量的元素,从而生成具有聚合值的较少元素的新向量:
sum (calculate sum over dimensions) #范围内求和
min (select minimum over dimensions) #范围内求最小值
max (select maximum over dimensions) #范围内求最大值
avg (calculate the average over dimensions) #范围内求最大值
stddev (calculate population standard deviation over dimensions) #计算标准偏差
stdvar (calculate population standard variance over dimensions) #计算标准方差
count (count number of elements in the vector) #计算向量中的元素数量
count_values (count number of elements with the same value) #计算向量中相同元素的数量
bottomk (smallest k elements by sample value)#样本中最小的元素值
topk (largest k elements by sample value)#样本中最大的元素值
quantile (calculate φ-quantile (0 ≤ φ ≤ 1) over dimensions) #计算 0-1 之间的百分比数量的样本的最大值
这些运算符可以用于聚合所有标签维度,也可以通过包含without或by子句来保留不同的维度。
([parameter,] ) [without|by ()]
parameter仅用于count_values,quantile,topk和bottomk。without从结果向量中删除列出的标签,而所有其他标签都保留输出。 by相反并删除未在by子句中列出的标签,即使它们的标签值在向量的所有元素之间是相同的
例:如果http_requests_total具有按application,instance和group标签列出的时间序列,我们可以通过以下方式计算每个应用程序和组在所有实例上看到的HTTP请求总数:
sum(http_requests_total) without (instance)
等于:
sum(http_requests_total) by (application, group)
如果我们只对我们在所有应用程序中看到的HTTP请求总数感兴趣,我们可以简单地写:
sum(http_requests_total)
要计算运行每个构建版本的二进制文件的数量,我们可以编写:
count_values("version", build_version)
要在所有实例中获取5个最大的HTTP请求计数,我们可以编写:
topk(5, http_requests_total)
FUNCTIONS
abs(v instant-vector) #返回其绝对值
absent() # 如果传递给它的向量具有该元素,则返回空向量;如果传递给它的向量没有元素,则返回传入的元素。
Example query:
nginx_server_connections
nginx_server_connections{endpoint="metrics",instance="192.168.43.5:9913",job="nginx-vts",namespace="dev",pod="nginx-vts-9fcd4d45b-sdqds",service="nginx-vts",status="accepted"} 89061
nginx_server_connections{endpoint="metrics",instance="192.168.43.5:9913",job="nginx-vts",namespace="dev",pod="nginx-vts-9fcd4d45b-sdqds",service="nginx-vts",status="handled"} 2
absent(nginx_server_connections{job="nginx-vts"}) => {}
absent(nginx_server_connections{job="nginx-vts123"}) => {job="nginx-vts123"}
ceil(v instant-vector) #返回向量中所有样本值(向上取整数)
round(v instant-vector, to_nearest=1 scalar) #返回向量中所有样本值的最接近的整数,to_nearest是可选的,默认为1,表示样本返回的是最接近1的整数倍的值, 可以指定任意的值(也可以是小数),表示样本返回的是最接近它的整数倍的值
floor(v instant-vector) #返回向量中所有样本值(向下取整数)
changes(v range-vector) #对于每个输入时间序列,返回其在时间范围内(v range-vector)更改的次数
clamp_max(v instant-vector, max scalar) #限制v中所有元素的样本值,使其上限为max
clamp_min(v instant-vector, min scalar) #限制v中所有元素的样本值,使其下限为min
year(v=vector(time()) instant-vector) #返回UTC中给定时间的年份
day_of_month(v=vector(time()) instant-vector) #返回UTC中给定时间的月中的某一天,返回值为1到31
day_of_week(v=vector(time()) instant-vector) #返回UTC中给定时间的当周中的某一天,返回值为0到6
days_in_month(v=vector(time()) instant-vector) #返回UTC中给定时间的一个月的天数,返回值28到31
hour(v=vector(time()) instant-vector) #返回UTC中给定时间的当天中的某一小时,返回值为0到23
minute(v=vector(time()) instant-vector) #返回UTC中给定时间的小时中的某分钟,返回值为0到59
delta(v range-vector) #返回一个即时向量,它计算每个time series中的第一个值和最后一个值的差别
deriv(v range-vector) #计算每个time series的每秒的导数(derivative)
exp(v instant-vector) #计算v中所有元素的指数函数
histogram_quantile(φ float, b instant-vector) #从buckets类型的向量中计算φ(0 ≤ φ ≤ 1)百分比的样本的最大值
holt_winters(v range-vector, sf scalar, tf scalar) #根据范围向量中的范围产生一个平滑的值
idelta(v range-vector) #计算最新的2个样本值之间的差别
increase(v range-vector) #计算指定范围内的增长值, 它会在单调性发生变化时(如由于目标重启引起的计数器复位)自动中断
irate(v range-vector) #计算每秒的平均增长值, 基于的是最新的2个数据点
rate(v range-vector) #计算每秒的平均增长值
resets(v range-vector) #对于每个 time series , 它都返回一个 counter resets的次数
sort(v instant-vector) #对向量按元素的值进行升序排序
sort_desc(v instant-vector) #对向量按元素的值进行降序排序
sqrt(v instant-vector) #返回v中所有向量的平方根
time() #返回从1970-1-1起至今的秒数,UTC时间
###sample 6
Grafana 图不动态移动
Amb*_*ari 3 spring-boot influxdb grafana
我正在尝试创建一个可用于监控 Spring Boot 应用程序的平台。我选择了infulxdb作为数据可视化的TSDB和grafana的选择。
我用 spring boot 创建了一个解决方案,它能够在称为堆的测量中推送 influxDB 中的数据。
我也在 Grafana 中配置了一个数据源

接下来我创建了一个仪表板并添加了一个带有如下指标的图表面板

这里的问题是每次我必须看到那个图表时,我必须点击缩小旁边的右箭头,图表应该自动移动,并以最新的时间为焦点。它保持不变,有人可以建议我在这里缺少什么吗?
