-
-
c语言开发的 使用最广的解释器
-
-
IPython
-
基于cpython之上的一个交互式计时器 交互方式增强 功能和cpython一样
-
-
PyPy
-
目标是执行效率 采用JIT技术 对python代码进行动态编译,提高执行效率
-
-
JPython
-
运行在Java上的解释器 直接把python代码编译成Java字节码执行
-
-
IronPython
-
Python是一种面向对象、解释型、强类型的脚本语言, 它也是一种功能强大而完善的通用型语言
Python代码非常简单,上手很容易。
Python的两大特色是清晰的语法和可扩展性:
-
Python的语法非常清晰,它甚至不是一种格式自由的语言。例如,它要求if语句的下一行必须向右缩进,否则无法通过编译
-
Python的可扩展性体现为它的模块,Python具有脚本语言中最丰富和强大的类库
Python作为一门解释型语言,它天生具有跨平台的特征,只要为平台提供Python解释器,Python解释器就可以在该平台中运行
解释型语言几乎都是跨平台的
Python自然也具有解释型语言的一些弱点:
-
速度慢: Python比Java, C, C++等程序的运行效率都要慢
-
源代码加密困难:不像编译型语言的源程序会被编译成目标程序,Python直接运行源程序, 因此对源代码加密比较困难
Python是一种解释型的编程语言,因此它具有解释型语言的运行机制。
计算机程序,其实就是一组计算机指令集, 能真正驱动机器运行的是机器指令,但让普通开发者直接编写机器是指是不现实的,因此就出现了计算机高级语言。高级语言允许使用自然语言(通常就是英语)来编程,但高级语言的程序最终必须被翻译成机制指令来执行
高级语言按程序的执行方式可以分为编译型和解释型两种:
编译型语言是指使用专门的编译器,针对特定的平台(操作系统)将某种高级语言源代码一次性“翻译”成可被该平台硬件执行的机器码(包括机器指令和操作数),并包装成该平台所能识别的可执行程序的格式,这个转换的过程称为编译
编译生成的可执行程序可以脱离开发环境,在特定的平台式独立运行。
因为编译型语言是一次性编译成机器码的,所以可以脱离开发环境独立运行,而且通常运行效率较高。但因为编译型语言的程序被编译成特定平台上的机器码,因此编译生成的可执行程序通常无法移植到其他平台上运行,如果需要移植,则必须将代码复制到特定平台上,针对特定平台进行修改,至少需要采用特定平台上的编译器重新编译
解释型语言指使用专门的解释器对源程序逐行解释称特定平台上的机器码并立即执行的语言。解释型语言通常不会进行整体性的编译和链接处理,解释型语言相当于把编译性语言中的编译和解释过程混合到一起同时完成
> pip list 列出pip管理的包 > pip install 包名 安装包 > pip uninstall 包名 卸载 > pip -V 查看版本 > pip freeze > requirements.txt 将项目依赖的包输出到指定的requirements.text文件 > pip install -r requirements.txt 使用pip安装requirements.txt中依赖的包 > pip install --upgrade pip 升级pip
Python命名规则
-
标识符命名规则
-
由字母、数字、下划线组成,不能以数字开头
-
区分大小写
-
不能与关键字重名
-
-
变量的命名规则
-
每个单词都使用小写字母
-
单词与单词之间用英文下划线_连接
-
-
常量的命名规范
-
一般采用全部单词大写
-
单词与单词之间用英文下划线_连接
-
-
函数的命名规则
-
每个单词都使用小写字母
-
单词之间用下划线连接
-
-
类的命名规则
-
大驼峰命名法(每个单词首字母大写,单词之间没有下划线)
-
-
全局变量和局部变量的命名规则
-
全局变量:采用gl或g加变量名
-
局部变量:同变量的命名规则
-
Python3与Python2的字符集的比较
Python3.X支持UTF-8字符集, 因此Python3的标识符可以使用UTF-8所能表示的多种语法的字符。Python语法是区分大小写的,因此abc和Abc是两个不同的标识符
Python2.X对中文支持较差, 如果要在Python2.X中使用中文字符或中文变量, 则需要在Python源程序第一行增加"#coding: utf-8", 然后将源文件保存为UTF-8字符集
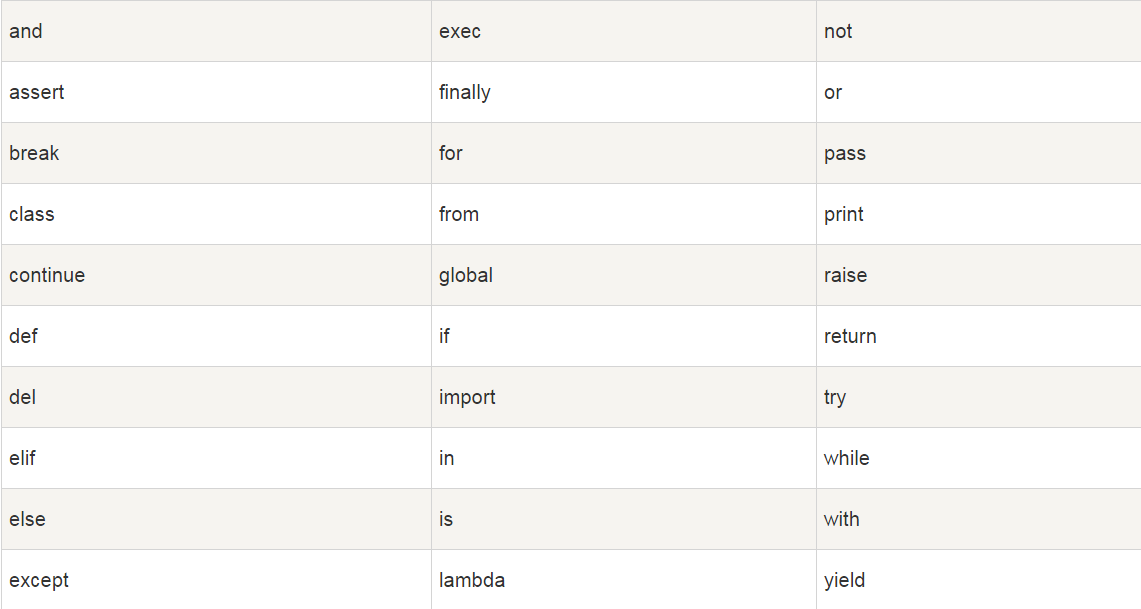
Python保留字
Python保留字,也叫关键字,是Python语言官方确定的用作语法功能的专用标识符,不能把它们用作任何自定义标识符名称。关键字只包含小写字母。Python的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字:
>>> import keyword >>> keyword.kwlist ['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield
如表所示
注释
我们写的程序里,不光有代码,还要有很多注释。注释有说明性质的、帮助性质的,它们在代码执行过程中相当于不存在,透明的,不参与任何工作。但在代码维护、解释、测试等等方面,发挥着不可或缺的重要作用。
- 单行注释
Python中,以符号“#”为单行注释的开始,从它往后到本行的末尾,都是注释内容。
# 下面这个方法的作用是….. # 第一个注释 # 我是单行注释
-
多行注释
Python没有真正意义上的多行注释(块注释)语法。你只能在每行的开头打上#号,然后假装自己是个多行注释
# 第一行注释 # 第二行注释 # 第三行注释
-
注释文档
在某些特定的位置,用三引号包括起来的部分,也被当做注释。但是,这种注释有专门的作用,用于为__doc__提供文档内容,这些内容可以通过现成的工具,自动收集起来,形成帮助文档。比如,函数和类的说明文档
def func(a, b): """ 这个是函数的说明文档。 :param a: 加数 :param b: 加数 :return: 和 """ return a + b class Foo: """ 这个类初始化了一个age变量 """ def __init__(self, age): self.age = age
代码头两行说明
很多时候,我们在一些py脚本文件的开头都能看到类似的以#开头的这样两行代码,它们不是注释,是一些设定。
#!/usr/bin/env python # -*- coding:utf-8 -*-
第一行: 用于指定运行该脚本的Python解释器,Linux专用,windows不需要。env方式下,系统会自动使用环境变量里指向的Python。还有一种方式,#!/usr/bin/python3.6,这会强制要求使用系统中的python3.6解释器执行文件,这种方式不好,一旦你本地的Python3.6版本删除了,会出现找不到解释器的错误。无论两种方式的哪一种,都指的是在linux下使用./test.py的方式执行脚本时的设置,在使用类似python test.py或者python3 test.py的执行方式时,这一行不起作用。
第二行: 代码的编码方式。不是程序要处理的数据的编码方式,而是程序自己本身的字符编码。在Python3中,全面支持Unicode,默认以UTF-8编码,我们不用再纠结中文的问题,乱码的问题,所以本行其实可以不需要。但在Python2中,对字符的编码是个非常令人头疼的问题,通常都需要指定这么一行。如果要自定义别的编码类型的话,可以像这样:# -- coding: cp-1252 --,但如果没有强制需求的话,不要自己作死,请坚持使用utf-8编码。
这两行要在文件的顶行,顶左,不要空格和空行, utf8和utf-8都行。
语句与缩进
语句:在代码中,能够完整表达某个意思、操作或者逻辑的最短代码,被称为语句。语句通常不超过一行,超过一行的称为多行语句。
Python的标准语句不需要使用分号或逗号来表示语句结束,简简单单的换个行就表示本语句已经结束,下一句开始。
代码块:为完成某一特定功能而联系在一起的一组语句构成一个代码块。有判断、循环、函数、类等各种代码块。代码块的首行通常以关键字开始,以冒号( : )结束。比如:
# 这是一个判断流程代码块 if expression : pass elif expression : pass else : pass
又比如
# 这是一个类代码块 class Foo: def __init__(self, name, age): self.name = name self.age = age def get_name(self): return self.name # 这是一个函数代码块 def func(a, b): summer = a+b return summer*2
Python最具特色的语法就是使用缩进来表示代码块,不需要使用大括号({})
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。
如果缩进数的空格数不一致,会抛出缩进异常
PEP8(Python官方的代码规范):建议使用四个空格作为缩进!在文本编辑器中,需要设置把Tab自动转换为4个空格,确保不混用Tab和空格。在Pycharm中:tab键被自动转换成4个空格的缩进。linux环境中,如vim编辑器,请一定使用空格,不要使用tab键!
那么怎么才是正确的缩进方式呢?
- 所有的普通语句,顶左开始编写,不需要缩进
- 所有的语句块,首行不用缩进,从冒号结束后开始下一行,都要缩进
- 直到该语句块结束,就退回缩进,表示当前块已结束
- 语句块可以嵌套,所以缩进也可以嵌套
同一行写多条语句:
Python一行通常就是一条语句,一条语句通常也不会超过一行。其实,从语法层面,Python并没有完全禁止在一行中使用多条语句,也可以使用分号实现多条语句在一行,比如:
import sys; x = ‘多条语句'; sys.stdout.write(x + ' ')
多行语句:
前面是多条语句在一行,但如果一条语句实在太长,也是可以占用多行的,可以使用反斜杠()来实现多行语句:
string = "i love this country," +"because it is very beautiful!" + "how do you think about it?" + "Do you like it too?"
在 [], {}, 或 () 中的多行语句,可以不需要使用反斜杠(),直接回车,接着写。例如:
result = subprocess.Popen("ipconfig /all", stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True, check=True)
pass语句
pass语句是占位语句,它什么都不做,只是为了保证语法的正确性而写。以下场景中,可以使用pass语句:
- 当你不知道后面的代码怎么写的时候
- 当你不需要写代码细节的时候
- 当语法必须,又没有实际内容可写的时候
- 其它的一些你觉得需要的场景
# 说明这个func函数需要三个参数,具体执行什么并不重要 # 但是函数体内如果什么都没有,会出现语法错误 # 这个时候,pass就是最好的选择。 def func(a,b,c): pass
空白字符与空白行
空白行、空白字符与代码缩进不同,并不是Python语法的一部分。空行或者空白字符会被当做空气一样的忽略。连续的空行或空白字符和单独的空白行几字符没有区别。书写时不插入空白行或空白字符,Python解释器运行也不会出错。但是空白的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
PEP8对于空行留白有专门的建议。
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
变量赋值的时候等号左右各给一个空白。逗号后面跟一个空白。
看下面的代码,作为标准的代码规范,在规定的地方留有规定的空白行和空白字符。
class Foo: pass def func(a, b): pass if __name__ == '__main__': pass