1.什么是索引
“索引(在mysql中叫键 key),是存储引擎快速找到记录的一种数据结构。” --- 《高性能MySQL》,例如innodb引擎使用的就是B+树。
2.索引类型
命令:show index from table_name; 查看索引详情。
- 主键索引 PRIMARY KEY: 一种特殊的唯一索引,不允许为null,一般建表时会创建主键,若不设置主键,
默认会为每一行生成row_id,查询时row_id不会当作索引使用,所以建表时,建议设置主键。 - 唯一索引 UNIQUE:唯一索引列的值必须唯一,但允许有空值(一般表字段建议设置为 not null)。如果是组合索引,组合值必须唯一。
可以通过ALTER TABLE table_name ADD UNIQUE (column);创建唯一索引;
可以通过ALTER TABLE table_name ADD UNIQUE (column1,column2);创建唯一组合索引; - 普通索引 INDEX:这是最基本的索引,它没有任何限制。可以通过ALTER TABLE table_name ADD INDEX index_name (column);创建普通索引;
- 组合索引 INDEX:即一个索引包含多个列,多用于避免回表查询。可以通过ALTER TABLE table_name ADD INDEX index_name(column1,column2, column3);创建组合索引
- 全文索引 FULLTEXT:也称全文检索,是目前搜索引擎使用的一种关键技术。可以通过ALTER TABLE table_name ADD FULLTEXT (column);创建全文索引
索引一经创建不能修改,如果要修改索引,只能删除重建。可以使用
DROP INDEX index_name ON table_name;删除索引。
3.索引设计原则
1)适合索引的列 出现在where,select子句
2)基数(整个集合中不同的个数)较小的类,索引效果较小,没必要建立索引,例如性别
3)使用短索引,如果长字段列建立索引,建议使用前缀索引,前缀的的位数,可以从区分度和节约索引空间考量
4)不可过度索引,结合业务适量使用。索引需要额外的磁盘空间,同时查询时会加载到内存中。在修改表时会修改甚至重新构建索引,索引列越多,这个时间越长。同时建议删除或插入数据时,不要在自增主键中间段做碎片化的操作。
4.索引优化
explain sql; 常用命令,查看优化器的执行计划
- 返回数据的比例,explain sql时filtered字段。一般返回表中30%内的数据会走索引,超过就全表扫描。30%,只是一个大概的范围。
- 回表,创建索引之后,索引会包含该列的值和对应行所在的主键id,列值作为键,主键id作为值。例如 select * from table where filed = ?;由于还需要其他的列,所以会回表,回到主键索引上的叶子节点(聚簇索引)获取全行的值。
1)优化实战
虽然数据库有索引,但是并不被优化器选择使用。我们可以通过 SHOW STATUS LIKE 'Handler_read%';查看索引的使用情况:
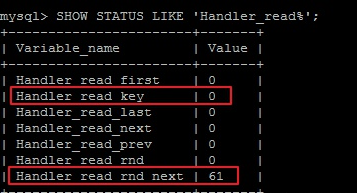
Handler_read_key:如果索引正在工作,Handler_read_key的值将很高。
Handler_read_rnd_next:数据文件中读取下一行的请求数,如果正在进行大量的表扫描,值将较高,则说明索引利用不理想。
- 如果MySQL估计使用索引比全表扫描还慢,则不会使用索引。返回数据的比例超过30%
- 前导模糊查询不能命中索引 。EXPLAIN SELECT * FROM user WHERE name LIKE '%s%';
- 数据类型出现隐式转换的时候不会命中索引 ,EXPLAIN SELECT * FROM user WHERE name=1;(name 是 varchar)
- 复合索引的情况下,查询条件不包含索引列最左边部分(不满足最左原则),最左原则并不是说是查询条件的顺序,
而是字段需要满足复合索引的最左匹配。 - union、in、or都能够命中索引,建议使用in。查询的CPU消耗:or>in>union。 union all 拼接后允许重复值
- 用or分割开的条件,如果or前的条件中列有索引,而后面的列中没有索引,那么涉及到的索引都不会被用到
- 负向条件查询不能使用索引,可以优化为in查询。可以优化为in查询,但是前提是区分度要高,返回数据的比例在30%以内。
- 范围条件查询可以命中索引。范围条件有:<、<=、>、>=、between等。
- where 后 字段执行计算,不会中索引
- 利用覆盖索引进行查询,避免回表。
- 建立索引的列,不允许为null。单列索引不存null值,复合索引不存全为null的值,如果列允许为null,可能会得到“不符合预期”的结果集,所以,请使用not null约束以及默认值。force index(filed)
select * from t force index(a) where (a between 1 and 1000)
关于多个索引的选择
存在多个索引的情况下,优化器一般会通过比较扫描行数、是否需要临时表以及是否需要排序等,来作为选择索引的判断依据。也就是谁消耗少,就用谁。同时也可强制使用某个索引。
总结
- 更新十分频繁的字段上不宜建立索引:因为更新操作会变更B+树,重建索引。这个过程是十分消耗数据库性能的。
- 区分度不大的字段上不宜建立索引。
- 业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。
- 多表关联时,要保证关联字段上一定有索引。
- 创建索引时避免以下错误观念:索引越多越好,认为一个查询就需要建一个索引;宁缺勿滥,认为索引会消耗空间、严重拖慢更新和新增速度;抵制唯一索引,认为业务的唯一性一律需要在应用层通过“先查后插”方式解决;过早优化,在不了解系统的情况下就开始优化。