bash&shell系列文章:http://www.cnblogs.com/f-ck-need-u/p/7048359.html
1.1 shell函数
在shell中,函数可以被当作命令一样执行,它是命令的组合结构体。可以将函数看成是一个普通命令或者一个小型脚本。
首先给出几个关于函数的结论:
(1).当在bash中直接调用函数时,如果函数名和命令名相同,则优先执行函数,除非使用command命令。例如:定义了一个名为rm的函数,在bash中输入rm执行时,执行的是rm函数,而非/bin/rm命令,除非使用"command rm ARGS"。
(2).如果函数名和命令别名同名,则优先执行别名。也就是说,在优先级方面:别名>函数>命令自身。
(3).当前shell定义的函数只能在当前shell使用,子shell无法继承父shell的函数定义。除非使用"export -f"将函数导出为全局函数。
(4).定义了函数后,可以使用unset -f移除当前shell中已定义的函数。
(5).除非出现语法错误,或者已经存在一个同名只读函数,否则函数的退出状态码是函数内部结构中最后执行的一个命令的退出状态码。
(6).可以使用typeset -f [func_name]或declare -f [func_name]查看当前shell已定义的函数名和对应的定义语句。使用typeset -F或declare -F则只显示当前shell中已定义的函数名。
(7).函数可以递归,递归层次可以无限。
函数的语法结构:
[ function ] name () compound-cmd [redirection]
上面的语法结构中定义了一个名为name的函数,关键字function是可选的,如果使用了function关键字,则name后的括号可以省略。compound-cmd是函数体,通常使用大括号{}包围,由于历史原因,大括号本身也是关键字,所以为了不产生歧义,函数体必须和大括号使用空格、制表符、换行符分隔开来。还可以指定可选的函数重定向功能,这样当函数被调用的时候,指定的重定向也会被执行。
上面的语法结构中定义了一个名为name的函数:
- 关键字function是可选的,如果使用了function关键字,则name后的括号可以省略。
- compound-cmd是函数体,通常使用大括号{}包围。由于历史原因,大括号本身也是关键字,所以为了不产生歧义,函数体和大括号之间必须使用空格、制表符、换行符分隔开来。
- 同理,大括号中的每一个命令都必须使用分号";"、"&"结束或换行书写。如果使用"&"结束某条命令,这表示该命令放入后台执行。
- 还可以指定可选的函数重定向功能,这样当函数被调用的时候,指定的重定向也会被执行。
例如:定义一个名为rm的函数,该函数会将传递的所有文件移动到"~/backup"目录下,目的是替代rm命令,避免误删除的危险操作。
[root@xuexi ~]# function rm () { [ -d ~/rmbackup ] || mkdir ~/rmbackup;/bin/mv -f $@ ~/rmbackup; } &>/dev/null
在调用rm函数时,只需是给rm函数传递参数即可。例如,要删除/tmp/a.log。
[root@xuexi ~]# rm /tmp/a.log
在执行函数时,会将执行可能输出的信息重定向到/dev/null中。
为了让函数在子shell(例如脚本)中也可以使用,使用export的"-f"选项将其导出为全局函数。取消函数的导出则使用export的"-n"选项。
export -f rm export -n rm
另外需要注意的是,函数支持无限递归。这可能在不经意间出错,导致崩溃。例如,写一个名为"ls"的函数。
function ls() { ls -l; }
这时执行ls命令会卡住,和想象中的"ls -l"效果完全不同,因为函数体中的ls也递归成了函数,这将无限递归下去。
关于shell函数,还有几个需要说明的知识点:
(8).shell函数也接受位置变量$0、$1、$2...,但函数的位置参数是调用函数时传递给函数的,而非传递给脚本的参数。所以脚本的位置变量和函数的位置变量是不同的,但是$0和脚本的位置变量$0是一致的。另外,函数也接受特殊变量"$#",和脚本的"$#"一样,它也表示位置变量的个数。
(9).函数体内部可以使用return命令,当函数结构体中执行到return命令时将退出整个函数。return后可以带一个状态码整数,即return n,表示函数的退出状态码,不给定状态码时默认状态码为0。
(10).函数结构体中可以使用local命令定义本地变量,例如:local i=3。本地变量只在函数内部(包括子函数)可见,函数外不可见。
(11).只有先定义了函数,才可以调用函数。不允许函数调用语句在函数定义语句之前。
1.2 条件结构:if
语法结构:
if test-commands1; then
commands1;
[elif test-commands2; then
commands2;]
...
[else
commands3;]
fi
if的判断很简单,一切都以返回状态码是否为0为判决条件。如果test-commands1执行后的退出状态码为0(不是其执行结果为0),则执行commands1部分的结构体,否则如果test-commands2返回0则执行commands2部分的结构体,如果都不满足,则执行commands3的结构体。
常见的test-commands有几种类型:
(1).一条普通的命令。只要该命令退出状态码为0,则执行then后的语句体。例如:
if echo haha &>/dev/null;then echo go;fi
(2).测试语句。例如test、[]、[[]]。
if [ $((1+2)) -eq 3 ];then echo go;fi if [[ "$name" =~ "long" ]];then echo go;fi
(3).使用逻辑运算符,包括!、&&和||。该特性主要是为普通命令而提供,因为测试语句自身就支持逻辑运算。所以,对于测试语句就提供了两种写法,一种是将逻辑运算符作为测试语句的一部分,一种是将逻辑运算符作为if语句的一部分。例如:
if ! id "$name" &>/dev/null;then echo "$name" miss;fi if ! [ 3 -eq 3 ];then echo go;fi if [ ! 3 -eq 3 ];then echo go;fi if [ 3 -eq 3 ] && [ 4 -eq 4 ] ;then echo go;fi if [ 3 -eq 3 -a 4 -eq 4 ];then echo go;fi if [[ 3 -eq 3 && 4 -eq 4 ]];then echo go;fi
注意,在if语句中使用()不能改变优先级,而是让括号内的语句成为命令列表并进入子shell运行。因此,要改变优先级时,需要在测试语句中完成。
1.3 条件结构:case
语法结构:
case word in
[ [(] pattern [| pattern]…)
command-list ;;]
…
esac
sysV风格的服务启动脚本是shell脚本中使用case语句最典型案例。例如:
case "$1" in start) start;; stop) stop;; restart) restart;; reload | force-reload) reload;; status) status;; *) echo $"Usage: $0 {start|stop|status|restart|reload|force-reload}" exit 2 esac
从上面的示例中,可以看出一些结论:
(1).case中的每个小分句都以双分号";;"结尾,但最后一个小分句的双分号可以省略。实际上,小分句除了使用";;"结尾,还可以使用";&"和";;&"结尾,只不过意义不同,它们用的不多,不过为了文章完整性,稍后还是给出说明。
(2).每个小分句中的pattern部分都使用括号"()"包围,只不过左括号"("不是必须的。
(3).每个小分句的pattern支持通配符模式匹配(不是正则匹配模式,因此只有3种通配元字符:"*"、"?"和[...]),其中使用"|"分隔多个通配符pattern,表示满足其中一个pattern即可。例如"([yY] | [yY][eE][sS]])"表示即可以输入单个字母的y或Y,还可以输入yes三个字母的任意大小写格式。
set -- y;case "$1" in ([yY]|[yY][eE][sS]) echo right;;(*) echo wrong;;esac
其中"set -- string_list"的作用是将输入的string_list按照IFS分隔后分别赋值给位置变量$1、$2、$3...,因此此处是为$1赋值字符"y"。
(4).最后一个小分句使用的pattern是"*",表示无法匹配前面所有小分句时,将匹配该小分句。一般最后一个小分句都会使用"*"避免case语句无法匹配的情况,在shell脚本中,此小分句一般用于提示用户脚本的使用方法,即给出脚本的Usage。
(5).附加一个结论:如果任何模式都不匹配,该命令的返回状态是零;否则,返回最后一个被执行的命令的返回值。
如果小分句不是使用双分号";;"结尾,而是使用";&"或";;&"结尾,则case语句的行为将改变。
- ";;"结尾符号表示小分句执行完成后立即退出case语句。
- ";&"表示继续执行下一个小分句中的command部分,而无需进行匹配动作,并由此小分句的结尾符号来决定是否继续操作下一个小分句。
- ";;&"表示继续向后(不止是下一个,而是一直向后)匹配小分句,如果匹配成功,则执行对应小分句中的command部分,并由此小分句的结尾符号来决定是否继续向后匹配。
示例如下:
set -- y case "$1" in ([yY]|[yY][eE][sS]) echo yes;& ([nN]|[nN][oO]) echo no;; (*) echo wrong;; esac yes no
在此示例中,$1能匹配第一个小分句,但第一个小分句的结尾符号为";&",所以无需判断地直接执行第二个小分句的"echo no",但第二个小分句的结尾符号为";;",于是直接退出case语句。因此,即使$1无法匹配第二个小分句,case语句的结果中也输出了"yes"和"no"。
set -- y case "$1" in ([yY]|[yY][eE][sS]) echo yes;;& ([nN]|[nN][oO]) echo no;; (*) echo wrong;; esac yes wrong
在此示例中,$1能匹配第一个小分句,但第一个小分句的结尾符号为";;&",所以继续向下匹配,第二个小分句未匹配成功,直到第三个小分句才被匹配上,于是执行第三个小分句中的"echo wrong",但第三个小分句的结尾符号为";;",于是直接退出case语句。所以,结果中输出了"yes"和"wrong"。
1.4 条件结构:select
shell中提供菜单选择的条件判断结构。例如:
[root@xuexi ~]# select fname in cat dog sheep mouse;do echo your choice: "$REPLY) $fname";break;done 1) cat 2) dog 3) sheep 4) mouse #? 3 # 在此选择序号3 your choice: "3) sheep" # 将输出序号3对应的内容
语法结构:
select name [ in word ] ; do cmd_list ; done
它的结构几乎和for循环的结构相同。有以下几个要点:
(1).in关键词后的word将根据IFS变量进行分割,分割后的每一项都进行编号,作为菜单序号被输出,如果省略in word,则等价于"in $@",即将位置变量的内容作为菜单项。
(2).当选择菜单序号后,该序号的内容将保存到变量name中,并且所输入的内容(一般是序号值,例如上面的例子中输入的3,但不规定一定要输入序号值,例如随便输入几个字符)保存到特殊变量REPLY中。
(3).每次输入选择后,select语句都将重置,如果输入的菜单序号存在,则cmd_list会重新执行,变量name也将重置。如果没有break命令,则select语句会一直运行,如果遇到break命令,将退出select语句。
仍然是上面的示例:但不使用break
[root@xuexi ~]# select fname in cat dog sheep mouse;do echo your choice: "$REPLY) $fname";done 1) cat 2) dog 3) sheep 4) mouse #? 2 your choice: "2) dog" #? habagou # 随意输入几个字符 your choice: "habagou) " # 变量fname被重置为空,变量REPLY被赋予了输入的值habagou #? 2 3 your choice: "2 3) " #? ^C # 直到杀掉进程select才结束
1.5 循环结构:for
for循环在shell脚本中应用极其广泛,它有两种语法结构:
结构一:for name [ [ in [ word ... ] ] ; ] do cmd_list ; done
结构二:for (( expr1 ; expr2 ; expr3 )) ; do cmd_list ; done
结构一中:将扩展in word,然后按照IFS变量对word进行分割,并依次将分割的单词赋值给变量name,每赋值一次,执行一次循环体cmd_list,然后再继续将下一个单词赋值给变量name,直到所有变量赋值结束。如果省略in word,则等价于"in $@",即展开位置变量并依次赋值给变量name。注意,如果word中使用引号包围了某些单词,这引号包围的内容被分割为一个单词。
例如:
[root@xuexi ~]# for i in 1 2 3 4;do echo $i;done 1 2 3 4
[root@xuexi ~]# for i in 1 2 "3 4";do echo $i;done 1 2 3 4
结构二中:该结构的expr部分只支持数学计算和比较。首先计算expr1,再判断expr2的返回状态码,如果为0,则执行cmd_list,并将计算expr3的值,并再次判断expr2的状态码。直到expr2的返回状态码不为0,循环结束。
例如:
[root@xuexi ~]# for ((i=1;i<=3;++i));do echo $i;done 1 2 3
1.6 循环结构:while
使用while循环尽量要让条件运行到可以退出循环,否则无限循环。一般都在命令体部分加上变量的改变行为。
语法结构:
while test_cmd_list; do cmd_list; done
首先执行test_cmd_list中的命令,当test_cmd_list的最后一个命令的状态码为0时,将执行一次cmd_list,然后回到循环的开头继续执行test_cmd_list。只有test_cmd_list中最后一个测试命令的状态码非0时,循环才会退出。
例如:计算1到10的算术和。
[root@xuexi ~]# let i=1,sum=0;while [ $i -le 10 ];do let sum=sum+i;let ++i;done;echo $sum 55
在此例中,test_cmd_list中只有一个命令[ $i -le 10 ],所以它的状态直接决定整个循环何时退出。
test_cmd_list中可以是多个命令,但千万要考虑清楚,是否要让决定退出循环的测试命令处在列表的尾部,否则将进入无限循环。
[root@xuexi ~]# let i=1,sum=0;while echo $i;[ $i -le 10 ];do let sum=sum+i;let ++i;done;echo $sum 1 2 3 4 5 6 7 8 9 10 11 55
对于while循环,有另外两种常见的写法:
(1).test_cmd_list部分使用一个冒号":"或者true命令,使得while进入无限循环。
while :;do # 或者"while true;do"
...
done
(2).使用read命令从标准输入中按行读取值,然后保存到变量line中(既然是read命令,所以可以保存到多个变量中),读取一行是一个循环。
由于标准输入既可以来源于重定向,也可以来源于管道(本质还是重定向),所以有几种常见的写法:
写法一:使用管道传递内容,这是最烂的写法
echo "abc xyz" | while read field1 field2 # 按IFS分割,并赋给两个变量
do
...
done
写法二:
while read line
do
...
done <<< "abc xyz"
写法三:从文件中读取内容
while read line
do
...
done </path/filename
既然是读取标准输入,于是还可以衍生出几种写法:
方法四:while read var;do ...;done < <(cmd_list) # 采用进程替换
方法五:exec <filename;while read var;do ...;done # 改变标准输入
尽管写法有多种,但注意,它们并不等价。
陷阱一:
方法一中使用的是管道符号,这使得while语句在子shell中执行,这意味着while语句内部设置的变量、数组、函数等在循环外部都不再生效。例如:
#!/bin/bash echo "abc xyz" | while read line do new_var=$line done echo the variable new_var is null: $new_var?
该脚本的执行结果中,$new_var的值将为空。
使用除写法一外的任意一种写法,在while循环外部都能继续获得while内的环境。例如,使用写法二的here string代替写法一:
#!/bin/bash while read line do new_var=$line done <<< "abc xyz" echo the variable new_var is null: $new_var?
如果没注意写法一中while是在子shell运行,很可能会一直疑惑,为什么在while循环里设置好的变量或数组在循环一结束就成了空值呢。
陷阱二:
关于这几种while循环的写法,还有一点要注意:写法一和写法四传递数据的源都是一个单独的进程,它们传递的数据一被while循环读取,所有数据就丢弃了,而以实体文件作为重定向传递的数据,while读取了之后并不会丢弃。更标准一些的说法是,当标准输入是非实体文件时(如管道传递的、独立进程产生的)只供一次读取;当标准输入是直接重定向实体文件时,可供多次读取,但只要某一次读取了该文件的全部内容就无法再提供读取。
举个例子,老师让我们听写10个单词,而我记忆力比较烂,他念完10个单词时我可能只写出了3个,剩余的7个因为记不住就没法再写出来。但如果我有小抄,我就可以慢悠悠的一个一个写,写了一个还可以等一段时间再写第二个,但当我写完10个之后,小抄这种东西就应该销毁掉。
回到IO重定向上,无论什么数据资源,只要被读取完毕或者主动丢弃,那么该资源就不可再得。①对于独立进程传递的数据(管道左侧进程产生的数据、进程替换产生的数据),它们都是"虚拟"数据,要不被一次读取完毕,要不读一部分剩余的丢弃,这是真正的一次性资源。②而实体文件重定向传递的数据,只要不是一次性被全部读取,它就是可再得资源,直到该文件数据全部读取结束,这是"伪"一次性资源。其实①是进程间通信时数据传递的现象,只不过这个问题容易被人忽略。
大多数时候,独立进程传递的数据和文件直接传递的数据并没有什么区别,但有些命令可以标记当前读取到哪个位置,使得下次该命令的读取动作可以从标记位置处恢复并继续读取,特别是这些命令用在循环中时。据我到目前的总结,这样的命令有"head -n N"和"grep -m",经测试,tail并没有位置标记的功能,因为tail读取的是后几行,所以它必然要读取到最后一行并计算要输出的行,所以tail的性能比head要差。
说了这么多,现在终于开始验证。下面的循环中,本该head每次读取2行,但实际执行结果中总共就只读取了一次2行。
[root@xuexi ~]# i=0 [root@xuexi ~]# cat /etc/fstab | while head -n 2 ; [[ "$i" -le 3 ]];do echo $i;let ++i;done # 0 1 2 3
使用进程替换的结果是一样的。
[root@xuexi ~]# i=0 [root@xuexi ~]# while head -n 2; [[ "$i" -le 3 ]];do echo $i;let ++i;done < <(cat /etc/fstab) # 0 1 2 3
但如果是直接将实体文件进行重定向传递给head,则结果和上面的不一样。
[root@xuexi ~]# i=0;while head -n 2 ; [[ "$i" -le 3 ]];do echo $i;let ++i;done < /etc/fstab # 0 # /etc/fstab # Created by anaconda on Thu May 11 04:17:44 2017 1 # # Accessible filesystems, by reference, are maintained under '/dev/disk' 2 # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # 3 UUID=b2a70faf-aea4-4d8e-8be8-c7109ac9c8b8 / xfs defaults 0 0 UUID=367d6a77-033b-4037-bbcb-416705ead095 /boot xfs defaults 0 0
可以看到结果中每次读取两行并echo一次"$i",而且每次读取的两行是不同的,后一次读取的两行是从前一次读取结束的地方开始的,这是因为head有"读取到指定行数后做上位置标记"的功能。
要确定命令、工具是否具有做位置标记的能力,只需像下面例子一样做个简单的测试。以head和sed为例,即使sed的"q"命令能让sed匹配到内容就退出,但却不做位置标记,而且数据资源使用一次就丢弃,所以sed测试中,第二个sed完全是废的,因为/etc/fstab这个资源在被第一个sed读取后就丢掉了。
[root@xuexi ~]# (head -n 2;head -n 2) </etc/fstab # # /etc/fstab # Created by anaconda on Thu May 11 04:17:44 2017
[root@xuexi ~]# (sed -n /default/'{p;q}' ;sed -n /default/'{p;q}') </etc/fstab UUID=b2a70faf-aea4-4d8e-8be8-c7109ac9c8b8 / xfs defaults 0 0
其实在实际应用过程中,这根本就不是个问题,因为搜索和处理文本数据的工具虽然不少,但绝大多数都是用一次文本就"丢"一次,几乎不可能因此而产生问题。之所以说这么多废话,主要是想说上面的5种while写法中,使用最广泛的写法一虽然最简单、方便,但其实是最烂的一种。
1.7 循环结构:until
until和while循环基本一致,所不同的仅仅只是test_cmd_list的意义。
语法结构:
until test_cmd_list; do cmd_list; done
首先判断test_cmd_list中的最后一个命令,如果状态码为非0,则执行一次cmd_list,然后再返回循环的开头再次执行test_cmd_list,直到test_cmd_list的最后一个命令状态码为0时,才退出循环。
当判断test_cmd_list最后一个命令的状态满足退出条件时直接退出循环,也就是说循环是在test_cmd_list最后一个命令处退出的。
例如:
[root@xuexi ~]# i=5;until echo haha;[ "$i" -eq 0 ];do let --i;echo $i;done haha 4 haha 3 haha 2 haha 1 haha 0 haha
1.8 exit、break、continue和return
exit [n] :退出当前shell,在脚本中应用则表示退出整个脚本(子shell)。其中数值n表示退出状态码。
break [n] :退出整个循环,包括for、while、until和select语句。其中数值n表示退出的循环层次。
continue [n] :退出当前循环进入下一次循环。n表示继续执行向外退出n层的循环。默认n=1,表示继续当前层的下一循环,n=2表示继续上一层的下一循环。
return [n] :退出整个函数。n表示函数的退出状态码。
唯一需要注意的是,return并非只能用于function内部,绝大多数人都有这样的误解。如果return用在function之外,但在 . 或者 source 命令的执行过程中,则直接停止该执行操作,并返回给定状态码n(如果未给定,则为0)。如果return在function之外,且不在source或" . "的执行过程中,则这是一个错误用法。
[root@xuexi ~]# return -bash: return: can only `return' from a function or sourced script
可能有些人不理解为什么不直接使用exit来替代这时候的return。下面给个例子就能清楚地区分它们。
#!/bin/bash if [ "$1" = "exit" ];then echo "exit current shell..." exit 0 else echo "return 0" return 0 fi
当执行 source c.sh 的时候,直接return,而当给定exit参数,即 source c.sh exit 的时候,将直接退出当前shell。
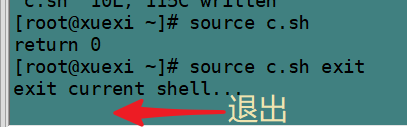
如果了解source的特性"在当前shell而非子shell执行指定脚本中的代码"的话,就能理解为什么会这样。
可能你想象不出在source执行中的return有何用处。从source来考虑,它除了用在某些脚本中加载其他环境,更主要的是在bash环境初始化脚本中使用,例如/etc/profile、~/.bashrc等,如果你在/etc/profile中用exit来替代function外面的return(想象一下将上面c.sh中的"return 0"换成"exit 0",然后在profile中source这个文件),那么你永远也登陆不上bash。
以下是/etc/profile.d/proxy.sh的内容,用于看情况设置代理的环境变量。
proxy="http://127.0.0.1:8118" function exp_proxy() { export http_proxy=$proxy export https_proxy=$proxy export ftp_proxy=$proxy export no_proxy=localhost } case $1 in set) exp_proxy;; unset) unset http_proxy https_proxy ftp_proxy no_proxy;; *) return 0 esac
当进入bash时,什么代理环境变量都不会设置。如果需要设置,使用 source /etc/profile.d/proxy.sh set 即可,如果想取消设置,使用unset参数即可。