https://www.cnblogs.com/yushangzuiyue/p/9655847.html
什么是Elastic-Job
Elastic-Job是当当网大牛基于Zookepper,Quartz开发并且开源的Java分布式定时任务,解决Quartz不支持分布式的弊端。它由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成。
基本概念
- 分片概念:任务分布式的执行,需要将一个任务拆分成多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项
- 个性化参数:shardingItemParameter,可以和分片项匹配对应关系。比如:将商品的状态分成上架,下架。那么配置0=上架,1=下架,代码中直接使用上架下架的枚举值即可完成分片项与业务逻辑的对应关系
- 作用高可用:将分片总数设置成1,多台服务器执行作业将采用1主n从的方式执行
- 弹性扩容:将任务拆分为n个任务项后,各个服务器分别执行各自分配到的任务项。一旦有新的服器加入集群或有服务器宕机。Elastic-Job将保留本次任务不变,下次任务开始前重新分片。
- 并行调度:采用任务分片方式实现。将一个任务拆分为n个独立的任务项,由分布式的服务器并行执行各自分配到的分片项。
- 集中管理:采用基于zookepper的注册中心,集中管理和协调分布式作业的状态,分配和监听。外部系统可直接根据Zookeeper的数据管理和监控elastic-job。
- 定制化流程任务:作业可分为简单和数据流处理两种模式,数据流又分为高吞吐处理模式和顺序性处理模式,其中高吞吐处理模式可以开启足够多的线程快速的处理数据,而顺序性处理模式将每个分片项分配到一个独立线程,用于保证同一分片的顺序性,这点类似于kafka的分区顺序性。
整体架构图
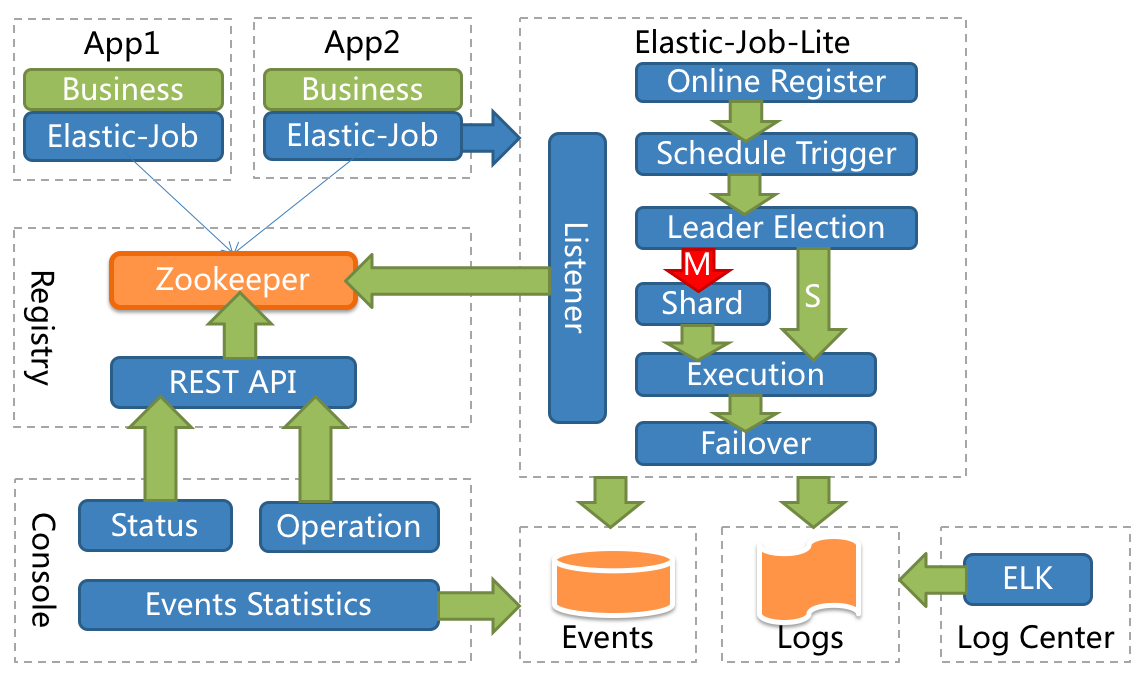
Elastic-Job的具体模块的底层及如何实现
Elastic-Job采用去中心化设计,主要分为注册中心、数据分片、分布式协调、定时任务处理和定制化流程型任务等模块。
- 去中心化:指Elastic-Job没有调度中心这一概念。每个运行在集群中的作业服务器都是对等的,节点之间通过注册中心进行分布式协调。但elastic-job有主节点的概念,主节点用于处理一些集中式任务,如分片,清理运行时信息等,并无调度功能,定时调度都是由作业服务器自行触发。
| 中心化 | 去中心化 | |
| 实现难度 | 难 | 易 |
| 部署难度 | 难 | 易 |
| 触发时间统一控制 | 可以 | 不可以 |
| 触发延迟 | 有 | 无 |
| 异构语言支持 | 容易 | 困难 |
- 注册中心:注册中心模块目前直接使用zookeeper,用于记录作业的配置,服务器信息以及作业运行状态。Zookeeper虽然很成熟,但原理复杂,使用较难,在海量数据支持的情况下也会有性能和网络问题。
- 数据分片:数据分片是elastic-job中实现分布式的重要概念,将真实数据和逻辑分片对应,用于解耦作业框架和数据的关系。作业框架只负责将分片合理的分配给相关的作业服务器,而作业服务器需要根据所分配的分片匹配数据进行处理。服务器分片目前都存储在注册中心中,各个服务器根据自己的IP地址拉取分片。
- 分布式协调:分布式协调模块用于处理作业服务器的动态扩容缩容。一旦集群中有服务器发生变化,分布式协调将自动监测并将变化结果通知仍存活的作业服务器。协调时将会涉及主节点选举,重分片等操作。目前使用的Zookeeper的临时节点和监听器实现主动检查和通知功能。
- 定时任务处理:定时任务处理根据cron表达式定时触发任务,目前有防止任务同时触发,错过任务重出发等功能。主要还是使用Quartz本身的定时调度功能,为了便于控制,每个任务都使用独立的线程池。
- 定制化流程型任务:定制化流程型任务将定时任务分为多种流程,有不经任何修饰的简单任务;有用于处理数据的fetchData/processData的数据流任务;以后还将增加消息流任务,文件任务,工作流任务等。用户能以插件的形式扩展并贡献代码。
作业开发
Elastic-Job提供Simple、Dataflow和Script 3种作业类型。方法参数shardingContext包含作业配置、片和运行时信息。可通过getShardingTotalCount(), getShardingItem()等方法分别获取分片总数,运行在本作业服务器的分片序列号等。
- Simple类型的作业:该类型意为简单实现,只需实现SimpleJob接口,重写它的execute方法即可
- Dataflow类型作业:用于处理数据流,实现DataflowJob接口,并重写两个方法——用于抓取(fetchData方法)和处理(processData方法)数据。比如在fetchData方法里面查询没有上架的商品,在processData方法修改该商品的状态。
注意:可通过DataflowJobConfiguration配置是否流式处理。当配置成流式处理,fetchData方法返回值(返回值是集合)是null或长度是0,作业才停止抓取,否则将一直运行。非流式的则每次作业只执行一次这两个方法就结束该作业。 - Script类型作业:意为脚本类型作业,支持shell、python、perl等类型脚本。只需通过控制台或代码配置scriptCommandLine即可,无需编码。
引入Maven依赖

<!-- 引入elastic-job-lite核心模块 -->
<dependency>
<groupId>io.elasticjob</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>${latest.release.version}</version>
</dependency>
<!-- 使用springframework自定义命名空间时引入 -->
<dependency>
<groupId>io.elasticjob</groupId>
<artifactId>elastic-job-lite-spring</artifactId>
<version>${latest.release.version}</version>
</dependency>
作业配置
Elasti-Job配置分成3个层级,Core, Type和Root。
- Core对应JobCoreConfiguration,用于提供作业核心配置信息,如:作业名称、分片总数、CRON表达式等。
- Type对应JobTypeConfiguration,有三个子类分别对应SIMPLE, DATAFLOW和SCRIPT类型作业,供3种作业需要的不同配置,如:DATAFLOW类型是否流式处理或SCRIPT类型的命令行等。
- Root对应JobRootConfiguration,有两个子类分别对应Lite和Cloud部署类型,提供不同部署类型所需的配置,如:Lite类型的是否需要覆盖本地配置或Cloud占用CPU或Memory数量等。
与Spring结合
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:reg="http://www.dangdang.com/schema/ddframe/reg"
xmlns:job="http://www.dangdang.com/schema/ddframe/job"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.dangdang.com/schema/ddframe/reg
http://www.dangdang.com/schema/ddframe/reg/reg.xsd
http://www.dangdang.com/schema/ddframe/job
http://www.dangdang.com/schema/ddframe/job/job.xsd
">
<!--配置作业注册中心-->
<reg:zookeeper id="regCenter" server-lists="127.0.0.1:2181" namespace="dd-job" base-sleep-time-milliseconds="1000" max-sleep-time-milliseconds="3000" max-retries="3" />
<!-- 配置简单作业-->
<job:simple id="simpleElasticJob" class="xxx.MySimpleElasticJob" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C" />
<bean id="yourRefJobBeanId" class="xxx.MySimpleRefElasticJob">
<property name="fooService" ref="xxx.FooService"/>
</bean>
<!-- 配置关联Bean作业-->
<job:simple id="simpleRefElasticJob" job-ref="yourRefJobBeanId" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C" />
<!-- 配置数据流作业-->
<job:dataflow id="throughputDataflow" class="xxx.MyThroughputDataflowElasticJob" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C" />
<!-- 配置脚本作业-->
<job:script id="scriptElasticJob" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C" script-command-line="/your/file/path/demo.sh" />
<!-- 配置带监听的简单作业-->
<job:simple id="listenerElasticJob" class="xxx.MySimpleListenerElasticJob" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C">
<job:listener class="xx.MySimpleJobListener"/>
<job:distributed-listener class="xx.MyOnceSimpleJobListener" started-timeout-milliseconds="1000" completed-timeout-milliseconds="2000" />
</job:simple>
<!-- 配置带作业数据库事件追踪的简单作业-->
<job:simple id="eventTraceElasticJob" class="xxx.MySimpleListenerElasticJob" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C" event-trace-rdb-data-source="yourDataSource">
</job:simple>
</beans>
补充:启动zookepper,通过spring启动配置,作业就能加载。
Spring部分配置参数说明
注册中心配置(只支持zookepper)
- id:注册中心在Spring容器中的主键
- server-lists:IP地址加端口号,可配置多个,用逗号隔开
- namespace:zookepper的命名空间
- max-retries:最大重置次数
作业配置
JobCoreConfiguration属性
- id:作业名称
- class:作业实现类,需实现ElasticJob接口
- cron:cron表达式,控制作用触发时间
- sharding-total-count:作业分片总数
- registry-center-ref:注册中心bean的引用
- sharding-item-parameters:分片序列号和参数用等号分隔,多个键值对用逗号分隔片,序列号从0开始,不可大于或等于作业分片总数如:0=a,1=b,2=c
- failover:是否开启失效转移
补充:开启失效转移的情况下,如果任务执行过程中一台服务器失去连接,那么已经分配到该服务器的任务,将会在下次任务执行之前被当前集群中正常的服务器获取分片并执行,执行结束后再进行下一次任务;未开启失效转移,那么服务器丢失后,程序将不作任务处理,任由其丢失,但下次任务会重新分片。 - disabled:作业是否禁止启动
- overwrite:本地配置是否可覆盖注册中心配置,如果可覆盖,每次启动作业都以本地配置为准
- event-trace-rdb-data-source:作业事件追踪的数据源Bean引用
- streaming-process:dataflow特有的——是否流式处理数据
- job-sharding-strategy-class:作业分片策略实现类全路径
分片策略
- AverageAllocationJobShardingStrategy:平均分配,默认分配策略,不能整除的多余分片将依次追加到序号小的服务器
- OdevitySortByNameJobShardingStrategy:根据作业名的哈希值奇偶数决定IP升降序算法的分片策略。作业名的哈希值为奇数则IP升序,偶数则IP降序
- RotateServerByNameJobShardingStrategy:根据作业名的哈希值对服务器列表进行轮转的分片策略
- 自定义策略:实现JobShardingStrategy接口并实现sharding方法,接口方法参数为作业服务器IP列表和分片策略选项,分片策略选项包括作业名称,分片总数以及分片序列号和个性化参数对照表
对比
与Spring Batch比较
- Spring Batch 是一款批处理应用框架,不是调度框架。如果我们希望批处理任务定期执行,可结合 Quartz 等成熟的调度框架实现。Elastic-Job集成了调度框架,不需要额外添加
- Spring Batch提供了丰富的读写组件,适用于复杂的流程化作业
- Elastic-Job采用分片的方式,是分布式调度解决方案。适用场景是:相对于流程比较简单,但是任务可以拆分到多个线程去执行。