Spark快速大数据分析这本书用Java/Python/Scala三种语言介绍了Spark的基本概念和简单操作,对于入门Spark是一个不错的选择,这里做一个总结,方便以后查看。
首先,要搞清楚Spark是什么?它是一个用来实现快速而通用的集群计算的平台,在速度方面扩展了MapReduce计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark之所以计算速度快主要是在内存中进行计算。不过即使是必须在磁盘上进行的复杂计算,Spark依然比MapReduce更加高效。
Spark的核心是一个对由很多计算任务组成的、运行 在多个工作机器或者是一个计算集群上的应用进行调度、分发以及监控的计算引擎。Spark的包含的组件如下图: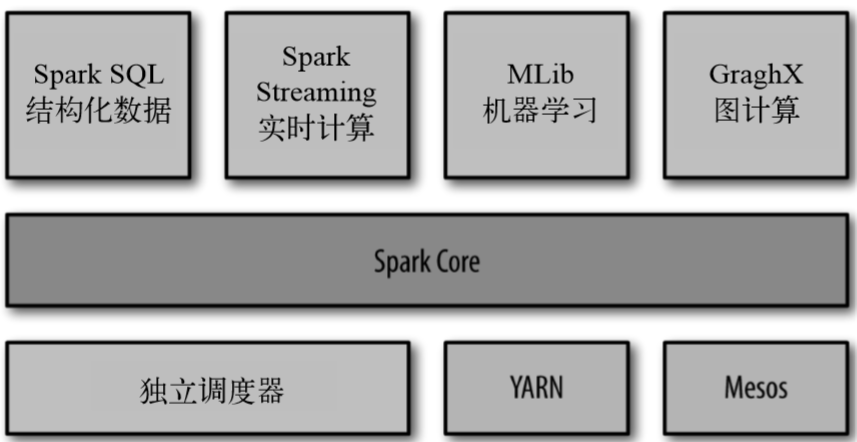
Spark Core 实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(resilient distributed dataset,简 称 RDD)的 API 定义。RDD 表示分布在多个计算节点上可以并行操作的元素集合,是 Spark 主要的编程抽象。Spark Core 提供了创建和操作这些集合的多个 API。
Spark SQL 是 Spark 用来操作结构化数据的程序包。通过Spark SQL可以用SQL或Apache Hive版本的SQL方言查询数据,支持多种数据源。
**Spark Streaming **是 Spark 提供的对实时数据进行流式计算的组件,提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
MLlib是机器学习功能的程序库,提供了很多中机器学习算法。
GraphX用来操作图的程序库,可以进行并行的图计算。GraphX 还支持针对图的各种操作以及,以及一些常用图算法。GraphX 也扩展了 Spark 的 RDD API,能用来创建 一个顶点和边都包含任意属性的有向图。
1 核心概念
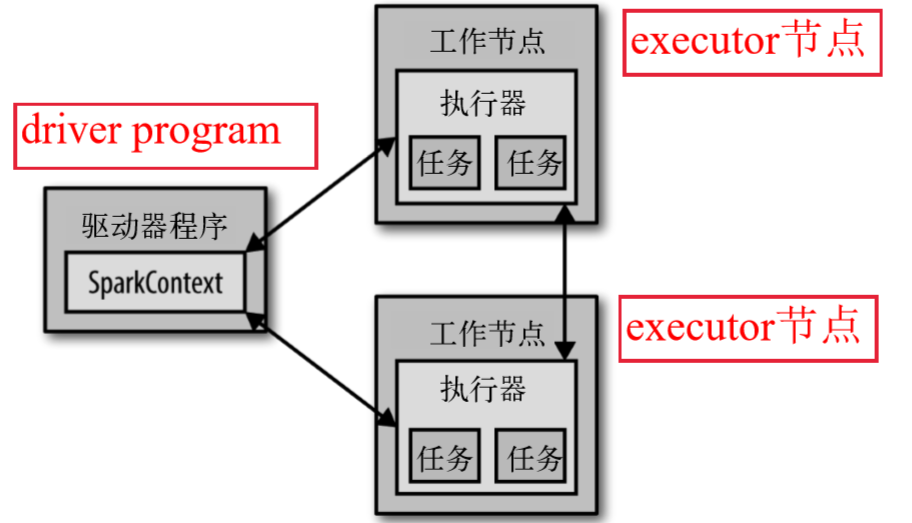
每个spark 应用都由一个驱动器程序(driver program)来发起集群上的各种并行操作
- 驱动器程序包含应用的main 函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作
- 驱动器程序通过一个SparkContext 对象来访问Spark,shell 启动时已经自动创建了一个SparkContext 对象,是一个叫作sc 的变量
- 驱动器程序一般要管理多个执行器(Executor)节点
SparkContext: SparkContext是Spark的入口点,用于连接Spark集群、创建RDD、累加器(accumlator)、广播变量(broadcast variables)
下图展示了 Spark 如何在一个集群上运行:
2 Spark初体验
Spark安装教程比较丰富,这里就不赘述了,来体验下Spark的基本使用。
2.1 启动spark-shell
2.2 执行word count
通过word count示例感受下Spark任务的执行过程。
scala> val lines = sc.textFile("file:///opt/spark/testfile/word.txt")
lines: org.apache.spark.rdd.RDD[String] = file:///opt/spark/testfile/word.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> val words = lines.flatMap(line=>line.split(" "))
words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:25
scala> val ones = words.map(word => (word, 1))
ones: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:25
scala> val counts = ones.reduceByKey(_ + _)
counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:25
scala> counts.foreach(println)
[Stage 0:> (0 + 2) / 2](Spark,3)
(Kafka,2)
(is,1)
(have,1)
(love,1)
(a,1)
(I,2)
(Great,2)
(Hadoop,1)
scala>
3 RDD
弹性分布式数据集(RDD, Resilient Distributed Dataset)是Spark对数据的核心抽象,其实就是不可变的分布式元素集合。在Spark中,对数据的所有操作都是围绕RDD进行的。Spark自动将每个RDD分为多个分区,这些分区运行在集群中的不同节点上,也就是说通过把RDD中的数据分发到集群中的不同节点上,将行动操作并行化执行,实现加速计算。
注:弹性指的是数据的存储方式,即数据在节点中进行存储时候,既可以使用内存也可以使用磁盘。此外,弹性另一个意思是RDD具有很强的容错性。这里容错性指的是spark在运行计算的过程中,不会因为某个节点错误而使得整个任务失败,不同节点中并行运行的数据,如果在某一个节点发生错误时,RDD会自动将其在不同的节点上重试。
3.1 RDD概述
在spark中,RDD相关的函数分三类:
-
创建RDD
- 调用
SparkContext的parallelize方法 如val rdd = sc.parallelize(Array(1,2,2,4),4)其中第一个参数表示待并行化的对象集合,第二个参数代表分区个数,当要对一个分区内的对象进行计算时,Spark从驱动程序进程里获取对象集合的一个子集 textFile方法读取外部数据集 如val rdd2 = sc.textFile("hdfs:///some/path.txt")
- 调用
-
转换(transformation)RDD:从一个RDD转换成一个新的RDD,这个过程不会求值,也不改变输入的RDD,只是创建并返回一个新的RDD 转换函数有:
map()、filter()、flatMap()、intersection()、union()、distinct()、substract()、reduceByKey()、sortByKey()...... -
执行动作(action): 对RDD计算求值,并将结果返回到驱动程序中或者存储到HDFS中 行动操作函数有:
reduce()、collect()、count()、first()、take()、fold()、saveAsTextFile()、countByKey()、foreach()......
注:
1)两种方式创建RDD中,生产环境常用textFile方法,parallelize用于开发和测试,因为parallelize方式需要把整个数据集先放到驱动程序所在的机器的内存中
2)转换操作是惰性的(包括textFile()),也就是说从一个RDD转换成一个新的RDD的操作不会马上执行,先记录,只有在行动操作用到这些RDD时才会真正计算,即计算RDD时,它所有依赖的中间RDD也会被计算
3)默认情况下,spark的RDD会在每次对它进行行动操作时重新计算
- 如果在多个行动操作中需要重用同一个RDD,可以使用
persist()方法,将这个RDD缓存起来 - 第一次对持久化的RDD计算之后,Spark 会把RDD 的内容保存到内存中(以分区的方式存储到集群的各个机器上)。然后在此后的行动操作中,可以重用这些数据
lines = sc.textFile("xxx.md")
lines.persist()
lines.count() #计算 lines,此时将 lines 缓存
lines.first() # 使用缓存的 lines
- 默认不缓存RDD的计算结果,因为spark可以直接遍历一遍数据再计算出结果,没必要缓存起来浪费存储空间
3.2 pairRDD
spark为包含键值对类型的RDD提供了专有的操作,这些RDD被称为pair RDD。键值对RDD的元素通常时一个二元元组,常用于聚合计算,spark为键值对RDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口。
Pair RDD 的创建:
* 对常规RDD 执行转化来创建Pair RDD,从常规RDD 中抽取某些字段,将该字段作为Pair RDD的键
* 对于很多存储键值对的数据格式,当读取该数据时,直接返回由其键值对数据组成的Pair RDD
* 当数据集已经在内存时,如果数据集由二元元组组成,那么直接调用sc.parallelize() 方法就可以创建Pair RDD
scala> val rdd = sc.parallelize(Array("java","scala"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[2] at parallelize at <console>:24
scala> val pairRDD = rdd.map(w => (w,"code"))
pairRDD: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[3] at map at <console>:25
scala> pairRDD.foreach(println)
(java,code)
(scala,code)
3.3 向Spark传递函数
spark 中的大部分转化操作和一部分行动操作需要用户传入一个可调用对象。在python 中,有三种方式:lambda 表达式(传递比较短的函数)、全局定义的函数、局部定义的函数。注意:python可能会把函数所在的对象也序列化传出去。
当传递的函数是某个对象的成员,或者包含了某个对象中一个字段的引用(如self.xxx 时),spark 会把整个对象发送到工作节点上。如果传递的类里面包含Python不知道如何序列化传输的对象,会导致程序运行失败。
class SearchFunction(object):
def __init__(self, query):
self.query = query
def isMatch(self, s):
return self.query in s
def getMatchesFunctionReference(self, rdd):
#问题:在"self.isMath"中引用了整个self
return rdd.filter(self.isMath)
替代方案,把需要的字段从对象中拿出来放到一个局部变量中,然后传递这个局部变量
class SearchFunction(object):
def __init__(self, query):
self.query = query
def isMatch(self, s):
return self.query in s
def getMatchesFunctionReference(self, rdd):
#把需要的"self.isMath"字段提取到局部变量中
isMath = self.isMath
return rdd.filter(isMath)
参考:Spark快速大数据分析