最近在处理新闻、资讯类内容的关键词提取任务,所以就了解了下这方面的情况。现在对这方面进行一个分享:
一、关键词提取
因为关键词能够表达一篇文章的中心内容,在我们写论文的时候,大家都有遇到过,那么在工作中,特别是对于新闻稿件、资讯舆情甚至是视频类,提取好准确的关键词,一方面可以让读者快速了解内容的中心,另一方面也是为了更好的归类和贴标签。
二、关键词提取常用的算法
目前看下来,大家主要用的还是无监督的算法,例如基于统计特征的关键词提取(TF-IDF) 、基于词图模型的关键词提取(TextRank)、基于主题模型的关键词提取(LDA)。
无监督算法因为不需要人工标注数据的原因,所以会更加方便、快速,但是缺陷是无法衡量关键词提取的准确与否,更多的是依靠人的主观来判断关键词是否准确,是否反映文章中心内容。
2.1 TF-IDF关键词算法原理:TF-IDF(term frequency-inverse document frequency,词频-逆文档文件频率),主要根据词语在文件中出现的次数以及该词语在整个语料库中出现的频率来决定。
公式:TF = ($frac{该词语在这篇内容中出现的次数}{这篇内容所有的词语数量}$) , IDF = ($frac{预料库中的文档总数}{包含该词语的文档数+1}$) 分母加1是为了防止分母为0 的情况。
TF-IDF = ($ TFcdot IDF$)
所以,TF-IDF算法的思想其实就是如果一个词在这篇内容中出现的次数多,在其他文档中出现的次数少,那么这个词就是关键词。但是因为有些词语例如出现在标题和第一段落的词语,如果觉得比较重要,则需要对算法稍加修改,增加位置的权重。
TF-IDF的缺点:IDF的计算值,需要语料库来支持,目前主要的语料库主要是基于人民日报的预料库进行训练得到的,而且年代比较久远,大概是2000年的语料。所以如果是在一个专业性很强的领域,用这个语料库计算出来的IDF值就会有出入,导致提取关键词的表现不那么好。所以语料库或者IDF的词库是需要及时更新,并且专业性强的领域建议自己弄一份语料库。
TF-IDF代码实现:
1 import jieba.analyse 2 3 text='关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作' 6 7 keywords=jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=()) 8 print(keywords)
#其中text是需要提取关键词的文本
#topK为返回TF-IDF值最大的几个关键词,数字可以自己设置
#withWeight为是否反馈关键词权重值,默认值为False
#allowPOS仅包括制定词性的词,可以选择关键词的词性 词性表:https://blog.csdn.net/zhuzuwei/article/details/79029904
2.2 TextRank关键词算法原理: TextRank首先会提取词汇,形成节点;然后依据词汇的关联,建立链接。依照连接节点的多少,给每个节点赋予一个初始的权重数值。然后就开始迭代。根据某个词所连接所有词汇的权重,重新计算该词汇的权重,然后把重新计算的权重传递下去。直到这种变化达到均衡态,权重数值不再发生改变。这与Google的网页排名算法PageRank,在思想上是一致的。根据最后的权重值,取其中排列靠前的词汇,作为关键词提取结果。此种算法的优点是可以脱离语料库的背景,相对于TF-IDF方法,可以更充分的利用文本元素之间的关系,缺点是没有考虑整个文档库的语料信息且计算量大。
公式:
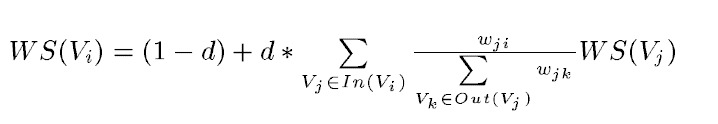
其中,WS(Vi)是i词的权重,WS(Vj)是j词的权重, d是阻尼系数,一般为0.85,In(Vi)是整篇文档中所有指向i的词的集合,Out(Vj)是词语j指向所有其他词语的集合。
TextRank代码实现:
1 import jieba.analyse 2 3 text = '关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作' 4 5 keywords = jieba.analyse.textrank(text, topK=10, withWeight=False, allowPOS=()) 6 print(keyword)
总结:目前所使用的方法主要是以上两类,根据实际效果选择其中之一即可。
参考文献:
1、https://www.cnblogs.com/tan2810/p/11202874.html
2、https://www.cnblogs.com/zhbzz2007/p/6177832.html
3、https://zhuanlan.zhihu.com/p/76051099?utm_source=qq
4、https://www.cnblogs.com/zhbzz2007/p/6177832.html
5、https://blog.csdn.net/asialee_bird/article/details/96894533
6、https://blog.csdn.net/asialee_bird/article/details/96454544
7、https://github.com/liuluyeah/TextRank4ZH-master
8、https://www.jb51.net/article/142460.htm
---------------------------本博客所有内容以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,并且是非商业用途,谢谢!----------------------
作者:enhaofrank
出处:https://www.cnblogs.com/enhaofrank/
中科院硕士毕业
现为深漂打工人