本文假设你已经完成了安装,并可以运行demo.py
不会安装且用PASCAL VOC数据集的请看另来两篇博客。
caffe学习一:ubuntu16.04下跑Faster R-CNN demo (基于caffe). (亲测有效,记录经历两天的吐血经历)
https://www.cnblogs.com/elitphil/p/11527732.html
caffe学习二:py-faster-rcnn配置运行faster_rcnn_end2end-VGG_CNN_M_1024 (Ubuntu16.04)
https://www.cnblogs.com/elitphil/p/11547429.html
一般上面两个操作你实现了,使用Faster RCNN训练自己的数据就顺手好多。
第一步:准备自己的数据集
(1). 首先,自己的数据集(或自己拍摄或网上下载)分辨率可能太大,不利于训练,通过一顿操作把他们缩小到跟VOC里的图片差不多大小。
在/py-faster-rcnn/data/VOCdevkit2007/VOC2007 (找到你自己文件相对应的目录),新建一个python文件(如命名为trans2voc_format.py)
把以下内容粘贴复制进去,然后执行该python文件即可对你的图片进行裁剪缩放等操作:
#coding=utf-8
import os #打开文件时需要
from PIL import Image
import re
Start_path='./JPEGImages/' # 唯一一处需要修改的地方。把对应的图片目录换成你的图片目录。
iphone5_width=333 # 图片最大宽度
iphone5_depth=500 # 图片最大高度
list=os.listdir(Start_path)
#print list
count=0
for pic in list:
path=Start_path+pic
print path
im=Image.open(path)
w,h=im.size
#print w,h
#iphone 5的分辨率为1136*640,如果图片分辨率超过这个值,进行图片的等比例压缩
if w>iphone5_
print pic
print "图片名称为"+pic+"图片被修改"
h_new=iphone5_width*h/w
w_new=iphone5_width
count=count+1
out = im.resize((w_new,h_new),Image.ANTIALIAS)
new_pic=re.sub(pic[:-4],pic[:-4]+'_new',pic)
#print new_pic
new_path=Start_path+new_pic
out.save(new_path)
if h>iphone5_depth:
print pic
print "图片名称为"+pic+"图片被修改"
w=iphone5_depth*w/h
h=iphone5_depth
count=count+1
out = im.resize((w_new,h_new),Image.ANTIALIAS)
new_pic=re.sub(pic[:-4],pic[:-4]+'_new',pic)
#print new_pic
new_path=Start_path+new_pic
out.save(new_path)
print 'END'
count=str(count)
print "共有"+count+"张图片尺寸被修改"
(2).图片有了,然后我们需要对图片进行重命名(理论上来说你不重命名来说也没影响)。
同样在/py-faster-rcnn/data/VOCdevkit2007/VOC2007 (找到你自己文件相对应的目录),新建一个python文件(如命名为pic_rename.py)
把以下内容粘贴复制进去,然后执行该文件,就可以把图片重命名(如你有一百张图片,则会重命名为:000001~0001000):
# coding=utf-8
import os # 打开文件时需要
from PIL import Image
import re
class BatchRename():
def __init__(self):
self.path = './JPEGImages' # 同样(也是),把图片路径换成你的图片路径
def rename(self):
filelist = os.listdir(self.path)
total_num = len(filelist)
i = 000001 # 还有这里需要注意下,图片编号从多少开始,不要跟VOC原本的编号重复了。
n = 6
for item in filelist:
if item.endswith('.jpg'):
n = 6 - len(str(i))
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path), str(0) * n + str(i) + '.jpg')
try:
os.rename(src, dst)
print 'converting %s to %s ...' % (src, dst)
i = i + 1
except:
continue
print 'total %d to rename & converted %d jpgs' % (total_num, i)
if __name__ == '__main__':
demo = BatchRename()
demo.rename()
(3). 然后需要对图片进行手动标注,建议使用labelImg工具,简单方便。
下载地址:https://github.com/tzutalin/labelImg
使用方法特别简单,设定xml文件保存的位置,打开你的图片目录,然后一幅一幅的标注就可以了
(借用参考链接第二条的一张图)

把所有图片文件标准完毕,并且生成了相对应的.xml文件。
接下来,来到voc207这里,把原来的图片和xml删掉(或备份),位置分别是:
-
/home/py-faster-rcnn/data/VOCdevkit2007/VOC2007/JPEGImages
-
/home/py-faster-rcnn/data/VOCdevkit2007/VOC2007/Annotations
删掉是因为我们不需要别的数据集,只想训练自己的数据集,这样能快一点
(4)数据和图片就位以后,接下来生成训练和测试用需要的txt文件索引,程序是根据这个索引来获取图像的。
在/py-faster-rcnn/data/VOCdevkit2007/VOC2007 (找到你自己文件相对应的目录),新建一个python文件(如命名为xml2txt.py)
把以下内容粘贴复制进去,然后执行该python文件即可生成索引文件:
# !/usr/bin/python
# -*- coding: utf-8 -*-
import os
import random
trainval_percent = 0.8 #trainval占比例多少
train_percent = 0.7 #test数据集占比例多少
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSetsMain' # 生成的索引文集所在路径
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+' '
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
生成的索引文件在这
以上,数据准备完毕。
第二步,修改源代码:
(1). 修改prototxt配置文件
这些配置文件都在models下的pascal_voc下。里面有三种网络结构:ZF、VGG16、VGG_CNN_M_1024,本文选择的是
VGG_CNN_M_1024。每个网络结构中都有三个文件夹,分别是faster_rcnn_end2end、faster_rcnn_alt_opt、faster_rcnn。
使用近似联合训练,比交替优化快1.5倍,并且准确率相近,所以推荐使用这种方法。更改faster_rcnn_end2end文件夹下的
的train.protxt和test.prototxt。其中train.prototxt文件共有四处需要修改(有些文章写的是只有三处需要修改,但是通过我的试验
和百度,最终发现有四处需要修改)
第一处是input-data层,将原先的21改成:你的实际类别+1(背景),我的目标检测一共有1类(为了试验方便,我只选了一类),
所以加上背景这一类,一共2类。

(num_classes: 21, 被我修改为2。 如上图所示 )
第二处是cls_score层:
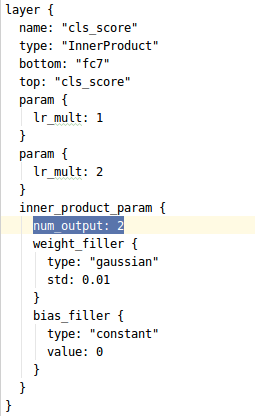
(num_output: 21 被我改成了2。切记,你要根据你的实际类别修改)
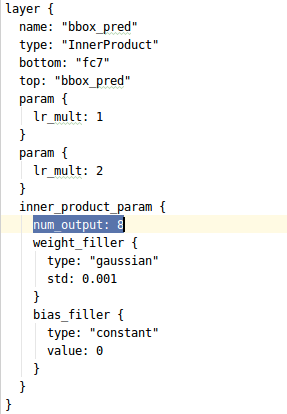
第三处是bbox_pred,这里需将原来的84改成(你的类别数+1)*4, 即(1+1)×4 = 8
还有第四处,roi-data 层(我发现有些博客是没有写这一点的,但是如果我没修改这里则会报错)
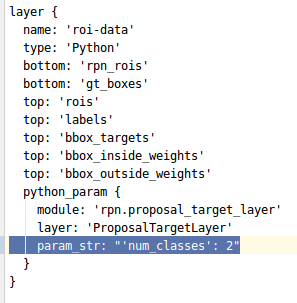
(原先的21被我改成了2)
test.prototxt只需要按照train.prototxt中修改cls_score层以及bbox_pred层即可
(2). 修改lib/datasets/pascal_voc.py,将类别改成自己的类别

如上图所示,我将原本的类别注释掉,换成了自己的类别,以方便日后还原。
这里有一点需要注意的是,这里的类别以及你之前的类别名称最好全部是小写,假如是大写的话,则会报Keyerror的错误。
这时只需要在pascal_voc.py 中的214行的.lower()去掉即可(我没试验,因为我的类名用的小写,所以没有遇到这个问题;
看到别的博客给了这么一个答案)
datasets目录主要有三个文件,分别是
1) factory.py: 这是一个工厂类,用类生成imdb类并且返回数据库供网络训练和测试使用;
2) imdb.py: 是数据库读写类的基类,封装了许多db的操作;
3) pascal_voc.py Ross用这个类操作。
第三步,开始训练
注意:训练前需要将cache中的pkl文件以及VOCdevkti2007中的annotations_cache的缓存删掉
1. cd py-faster-rcnn
2. ./experiments/scripts/faster_rcnn_end2end.sh 0 VGG_CNN_M_1024 pascal_voc
第四步,测试结果
训练完成之后,将output中的最终模型拷贝到data/faster_rcnn_models, 修改tools下的demo.py,
我是使用VGG_CNN_M_1024这个中型网络,不是默认的ZF,所以要修改以下几个地方:
(1) 修改class
同样的手法,将原本的CLASSES注释掉(不建议删除,留在方便日后还原),新增自己的CLASSES

(2). 增加你自己训练的模型
myvgg1024为新增的部分
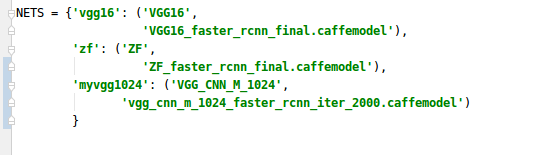
(3) 修改prototxt(demo.py文件的内容), 如果你用的是ZF,就不用修改了
被注释掉的内容是修改前的,后面是我新增的。

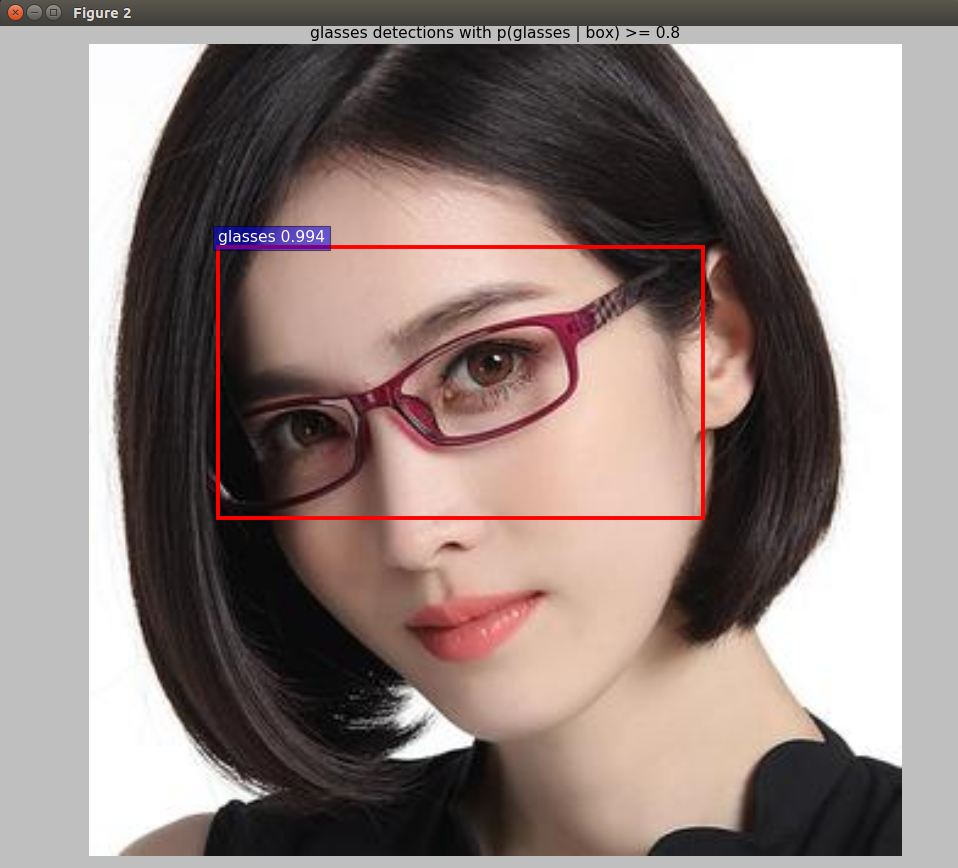
(4) 开始检测
1) 把你需要检测的图片放在data/demo文件夹下
2)demo.py 修改你要检测的图片名称

3)执行命令
1. cd py-fast-rcnn/tools
2. ./demo.py --net myvgg1024

参考博客
https://blog.csdn.net/zhaoluruoyan89/article/details/79088621
https://blog.csdn.net/zcy0xy/article/details/79614862
tf-faster rcnn训练自己的数据参考博客:https://blog.csdn.net/qq_34108714/article/details/89335642