IO详解
参考自:
https://www.cnblogs.com/laughingQing/p/4885142.html
https://www.cnblogs.com/dreamyu/p/6551137.html
一、概览
“流”(stream)有方向:流进(input stream)和流出(output stream)。
“流”有流动的最小单位:①有基于一个字节(single-byte)流动的InputStream和OutputStream家族;②也有基于两个字节流动(two-byte)的Reader和Writer家族。
为什么会有两大家族呢?
1、基于single-byte流动的有两个最基本的抽象类(abstract classes):InputStream和OutputStream。稍后我们会看到以这两个抽象类作为父类,衍生了一个庞大的IO家族。
2、由于基于single-byte的流不方便处理那些用Unicode编码方式存储的字符characters信息。从而java的IO系统中又出现了另外的一个基于Reader和Writer抽象类,用于处理characters信息的家族。
二、读写bytes
抽象类InputStream中有一个抽象读方法:
abstract int read();
每次调用这个方法就会从流中读取一个byte并返回读取到的byte值;如果遇到输入流的末尾,则返回-1。
这个抽象类还重载了其它的read方法,但都是在底层调用了上面这个读取单字节的抽象的read()方法。该抽象类还有如下方法:
①、abstract int read();
②、int read(byte[] b),最大读取b.length个字节数据;实际上调用的是read(b, 0, b.length)方法;
③、int read(byte[] b, int off, int len),最大读取len个字节数据到b字节数组中,从off位置开始存放;
④、long skip(long n),在输入流中跳过n个字节,返回实际跳过的字节数。当遇到末尾的时候实际跳过的数据可能小于n;
⑤、int available(),返回在不阻塞的情况下流中的可以读取的字节数;
⑥、void close(),关闭流;
⑦、void mark(int readlimit),在输入流的当前位置打一个标记(注:不是所有的流都支持这一特性);
⑧、void reset(),返回到最后一个标记处。随后调用read方法会从最后一个标记处重新读取字节数据。如果当前没有标记,则不会有任何变化;
⑨、boolean markSupported(),判断当前流是否支持标记操作;
对应的,抽象类OutputStream中也有一个抽象的写方法:
abstract void write(int b);
OutputStream类有如下方法:
①、abstract void write(int b);
②、void write(byte[] b),将b中存放的所有数据都写入到流中;实际上调用的是write(b, 0, b.length)方法;
③、void write(byte[], int off, int len),将b字节数组中从off位置开始的len个字节数据写入到流中;
④、void close(),关闭和flush输出流;
⑤、void flush,对输出流做flush操作,也就是说,将所有输出流中缓存的数据都写入到实际的目的地;
上面抽象的read()和write()方法都会阻塞,直到byte读写成功为止。这就意味着,如果在读写过程中,如果当前流不可用,那么当前线程就会被阻塞。为解决阻塞的问题InputStream类提供了一个avaliable()方法,可以检测当前可读的字节数。所以,下面这段代码永远不会被阻塞:
int bytesAvailable = in.available(); if(bytesAvailable > 0){ byte[] data = new byte[bytesAvailable]; in.read(data); }
当我们读写完毕以后,应该要调用close()函数来关闭流。这样做,一方面可以释放掉流所持有的系统资源。另外一方面,关闭一个输出流也会将暂存在流中的数据flush到目标文件中去:输出流会持有一个buffer,在其buffer没有满的时候是不会实际将数据传递出去的。特别的,如果你没有关闭一个输出流,那么很有可能会导致最后那些存放在buffer中的数据没有被实际的传递出去。当然,我们也可以通过调用flush()方法手动的将buffer中的数据flush出去。
三、结合stream filters
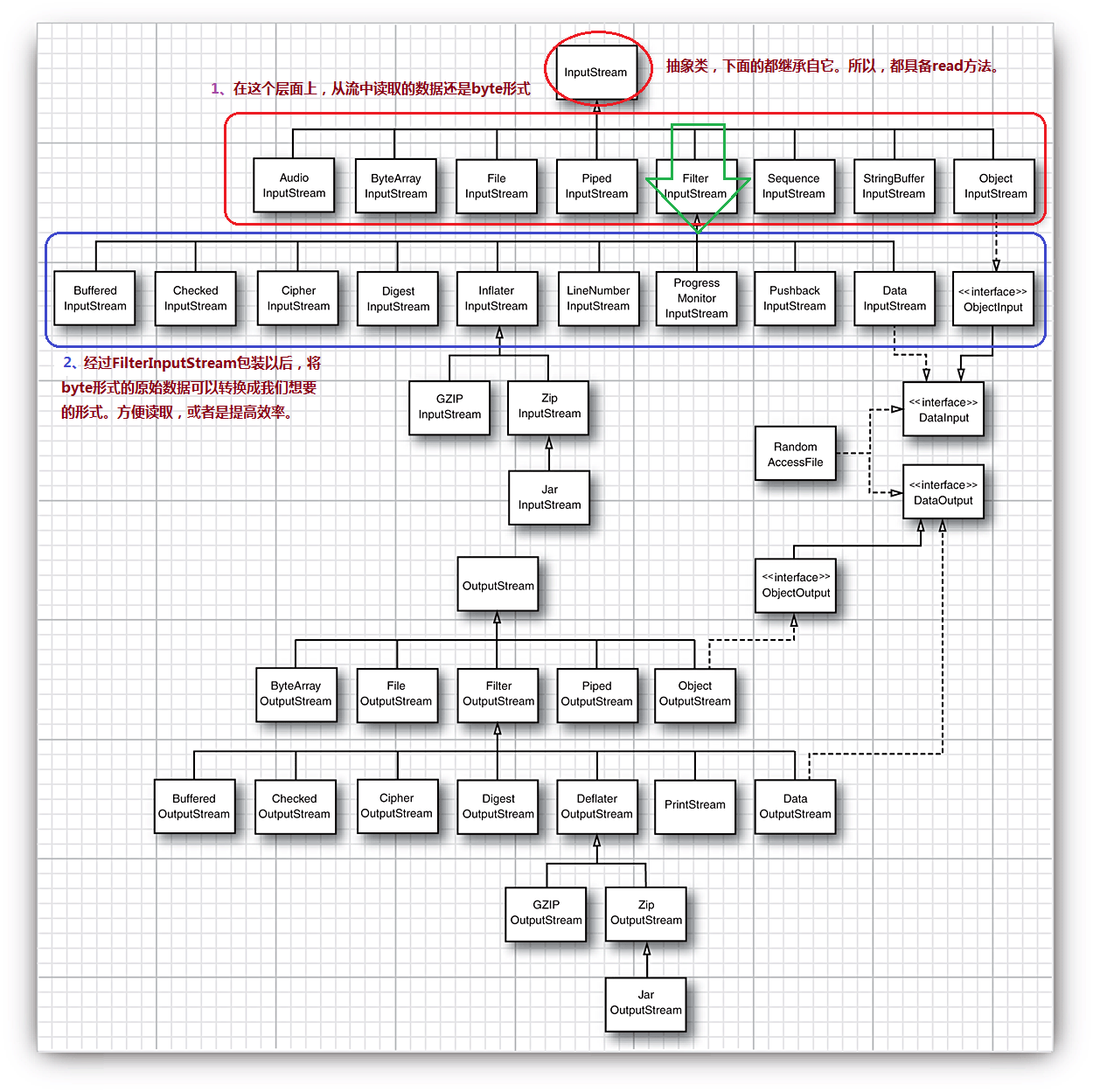
我们从第一个层面上看(直接继承自InputStream或OutputStream的这些类),FileInputStream能够让你得到一个附着在磁盘文件上的输入流,FileOutputStream能够得到一个对磁盘文件的输出流。比如用下面的方式:
FileInputStream fin = new FileInputStream("employee.dat"); FileOutputStream fout = new FileOutputStream("employee.dat");
和InputStream、OutputStream抽象类一样,FileInputStream和FileOutputStream也只提供基于byte的读写方法。
但是,我们如果能够得到一个DateInputStream,那么我们就可以从流中读取numeric types了,比如我们可以从流中读取一个double类型的数据:
FileInputStream fin = new FileInputStream("employee.dat"); DataInputStream din = new DataInputStream(fin); Double s = din.readDouble();
java使用了一种很好的机制将对底层和对上层的操作分开,这样既方便了流向底层写byte,也方便了我们使用我们习惯的numeric types类型。
再介绍一对很重要的流,它对提高读写效率有很大的帮助:BufferedInputStream和BufferedOutputStream,他们分别为输入和输出流提供了一个缓冲区。比如在上面的流中添加一个缓冲区,让它更快一些:
FileInputStream fin = new FileInputStream("employee.dat"); BufferedInputStream bin = new BufferedInputStream(fin); DataInputStream din = new DataInputStream(bin); Double s = din.readDouble();
有了上面的分层介绍以后,你当然会很明白为什么要将BufferedInputStream放在中间层,而不是很杀马特的将其放在最外层了。你可知道,BufferedInputStream和BufferedOutputStream只提供对byte的读写方法。
理解到这里,我们可以放心的相信一件事情了:关闭流的时候,只需要关闭最外层的流即可。因为,它自己会一层一层的往里面调用close()方法。
四、IO操作
IO流的本质是对字节和字符的处理,那么我们平时也是用来处理文件的,就从文件处理开始接触这方面的知识。
1、文件操作(创建文件和文件夹,查看文件)
public class FileExample { public static void main(String[] args) throws FileNotFoundException { String filePath1 = "/Users/dongyp/Documents/test/111.txt"; File file1 = new File(filePath1); if(file1.exists()){ System.out.println("文件" + filePath1 + "存在"); }else{ try { System.out.println("创建文件" + filePath1); // 创建文件, 若目录不存在报错 No such file or directory; 若目录存在且文件不存在就创建文件,文件存在不会被覆盖; file1.createNewFile(); } catch (IOException e) { e.printStackTrace(); } } String filePath2 = "/Users/dongyp/Documents/test"; File file2 = new File(filePath2); if(file2.isDirectory()){ System.out.println("文件" + filePath2 + "是一个目录"); System.out.println("打印" + filePath2 + "下所有文件"); File[] files = file2.listFiles(); for (int i = 0; i < files.length; i++){ System.out.println("文件" + (i+1) + ":" + files[i].getName()); } }else { System.out.println("创建目录" + filePath2); // 创建目录, 若目录不存在则创建目录 file2.mkdir(); } } }
2、常用字节流FileInputStream和FileOutputStream:
FileInputStream:
public class InputStreamExample { public static void main(String[] args) { FileInputStream fin = null; try { fin = new FileInputStream("/Users/dongyp/Documents/test/testData.txt"); byte[] bytes = new byte[1024]; int n = 0; // n 用来存储 bytes 的长度 while((n=fin.read(bytes))!= -1){ String str = new String(bytes,0,n); System.out.print(str); } } catch (IOException e) { e.printStackTrace(); } finally { try { fin.close(); } catch (IOException e) { e.printStackTrace(); } } } }
文件:

输出结果:

FileOutputStream:
public class OutputStreamExample { public static void main(String[] args) { FileOutputStream fout = null; try { // 若是文件不存在会创建文件,且会覆盖原文件中的内容 // 传递一个true参数,代表不覆盖已有文件,并在文件末尾处进行续写 例:new FileOutputStream(path,true) fout = new FileOutputStream("/Users/dongyp/Documents/test/111.txt"); String str = "难道就是这样 "; byte[] bytes = str.getBytes(); fout.write(bytes); } catch (IOException e) { e.printStackTrace(); } finally { try { fout.close(); } catch (IOException e) { e.printStackTrace(); } } } }
输出结果:
![]()
3、字符流FileReader和FileWriter:
public class FileReaderAndWriter { public static void main(String[] args) { FileReader freader = null; FileWriter fwriter = null; try { freader = new FileReader("/Users/dongyp/Documents/test/testData.txt"); // 文件不存在会创建一个 fwriter = new FileWriter("/Users/dongyp/Documents/test/123.txt"); char[] chars = new char[1024]; int n = 0; while((n = freader.read(chars)) != -1){ String str = new String(chars, 0 , n); System.out.println(str); fwriter.write(chars); } } catch (IOException e) { e.printStackTrace(); } finally { try { freader.close(); fwriter.close(); } catch (IOException e) { e.printStackTrace(); } } } }