由于业务场景的需要,海量的数据需要进行处理、组装,难免会出现冗余的重复数据。如何处理重复的数据就是一个问题。
简单的集合中,去重就可以用linq distinct来完成。对于复杂的集合直接使用distinct就会显得没那么有效了。
-
造数据
构造1M的orderentity,非重复的数据为1M/2.
1 IList<OrderEntity> sourceList = new List<OrderEntity>(); 2 for (int i = 0; i < 1000000; i++) 3 { 4 OrderEntity o = new OrderEntity 5 { 6 OrderNo = i % 500000, 7 Amount = 1, 8 Detail = "test" 9 }; 10 sourceList.Add(o); 11 }
方式一:直接distinct
1 var list = sourceList.Distinct().ToList(); 2 Console.WriteLine(list.Count + " 耗时:" + watch.ElapsedMilliseconds);

结果还是1M,对于复杂的集合 distinct直接使用是没效果的。
方法二:对数据分组
1 var list2 = sourceList.GroupBy(t => new 2 { 3 t.OrderNo, 4 t.Amount, 5 t.Detail 6 7 }).Select(g => g.First()).ToList(); 8 9 Console.WriteLine(list2.Count + " 耗时:" + watch.ElapsedMilliseconds);
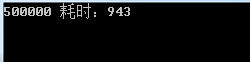
结果是500K, 对集合group处理还是有作用的,可惜的是耗时较高。
方法三:推荐 使用Distinct 重载
1 public class OrderEntityComparer : IEqualityComparer<OrderEntity> 2 { 3 public bool Equals(OrderEntity x, OrderEntity y) 4 { 5 if (Object.ReferenceEquals(x, y)) return true; 6 if (Object.ReferenceEquals(x, null) || Object.ReferenceEquals(y, null)) 7 return false; 8 return x.OrderNo == y.OrderNo && x.Amount == x.Amount && x.Detail == y.Detail; 9 } 10 11 public int GetHashCode(OrderEntity obj) 12 { 13 //Check whether the object is null 14 if (Object.ReferenceEquals(obj, null)) return 0; 15 //Get hash code for the Name field if it is not null. 16 int hashOrderNo = obj.OrderNo.GetHashCode(); 17 18 //Get hash code for the Code field. 19 int hashAmount = obj.Amount.GetHashCode(); 20 21 int hashDetail = obj.Detail == null ? 0 : obj.Detail.GetHashCode(); 22 //Calculate the hash code for the product. 23 return hashOrderNo ^ hashAmount ^ hashDetail; 24 } 25 }
1 var list3 = sourceList.Distinct(new OrderEntityComparer()).ToList(); 2 3 Console.WriteLine(list3.Count + " 耗时:" + watch.ElapsedMilliseconds);

结果:达到去重目的,耗时也可以接受。