-
Supervised 监督学习
-
Unsuperivised 非监督学习
-
Reinforcement 强化学习(alphago,我将Action给环境,环境给我Reward))
-
Supervised Learning
- Classification 分类
- Regression 回归
-
Unsupervised Learning
- Clustering 聚类
- Compression 降维(压缩)
-
如何选择一个模型

- 大体流程
```
//训练集x(N * d), y(N * 1); 测试集x, y(同分布的)
train_x, train_y, test_x, test_y = getData() // MNIST
model = somemodel() // SVM(),LASSO()
model.fit(train_x, train_y) // 学习参数
predictions = model.predict(test_x) // 预测模型
//验证模型
//分类任务: 分对的百分比
//回归任务: 计算MSE等
//11种评价指标
//一个预测的数,和真实数据之间的差距
score = score_function(test_y, predictions)
```
# iris 花的数据集
from sklearn.datasets import load_iris
iris = load_iris()
from sklearn.datasets import load_iris
iris = load_iris()
# The resulting dataset is a Bunch object: you can see what's available using the method keys():
In [4]: iris.keys()
Out[4]:
dict_keys(['target', 'data', 'target_names', 'DESCR', 'feature_names'])
-
Generating Synthetic Data 自己造数据
In [5]: from sklearn.datasets import make_regression # 自己造出来数据
I. Supervised 监督学习
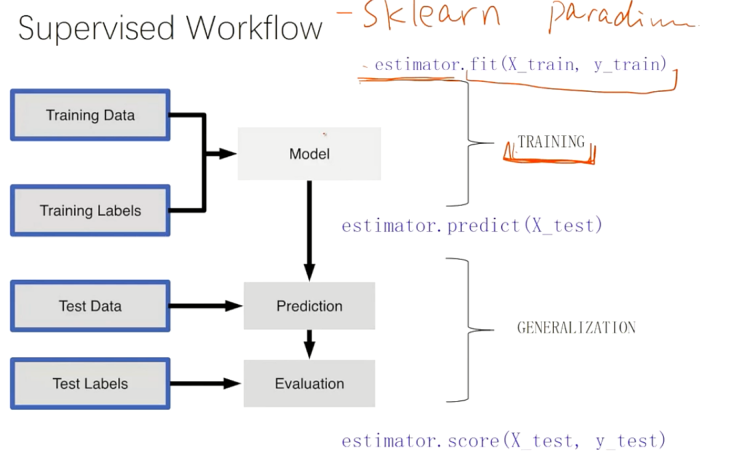
- estimator.fit(X_train, y_train)
- estimator.predict(X_test)
- estimator.score(X_test, y_test) #评估
监督学习的工作流程
II.Unsupervised Transformers (无监督)
transformer.fit(X_train) # 进行一个拟合
X_train_transf = transformer.transform(X_train) # 降维到所期待的维度
X_test_transf = transformer.transform(X_test) # n component, trans = TSN(n_col=3, [..])
-
Feature Scaling (特征规则化)
- min-max scalling
- "normalization" (归到0~1之间)
-
Principal Component Analysis (PCA)
把一个高维空间映射 到 XTX 的 最大的两个特征值(对应的两个特征向量正交) 的投影上
-
PCA for Dimensionality Reduction (降维)
-
K-means Clustering (聚类手法)
- 需要告诉他分成 N 类
- 欧几里得距离 ( d(x,y)=∑2j=1(xj−yj)2=||x−y||22 )
# ### Scikit-learn API
estimator.fit(X_train, [y_train])
estimator.predict(X_test) estimator.transform(X_test)
Classification Preprocessing (预处理:图像灰度值归一化等 )
Regression Dimensinality Reduction (降维)
Clustering Feature Extraction (特征提取)
Feature selection (特征选择)
-
Preprocessing & Classification Overview (预处理 和 分类概述)
- 略
-
训练数据集、验证数据集、测试数据集

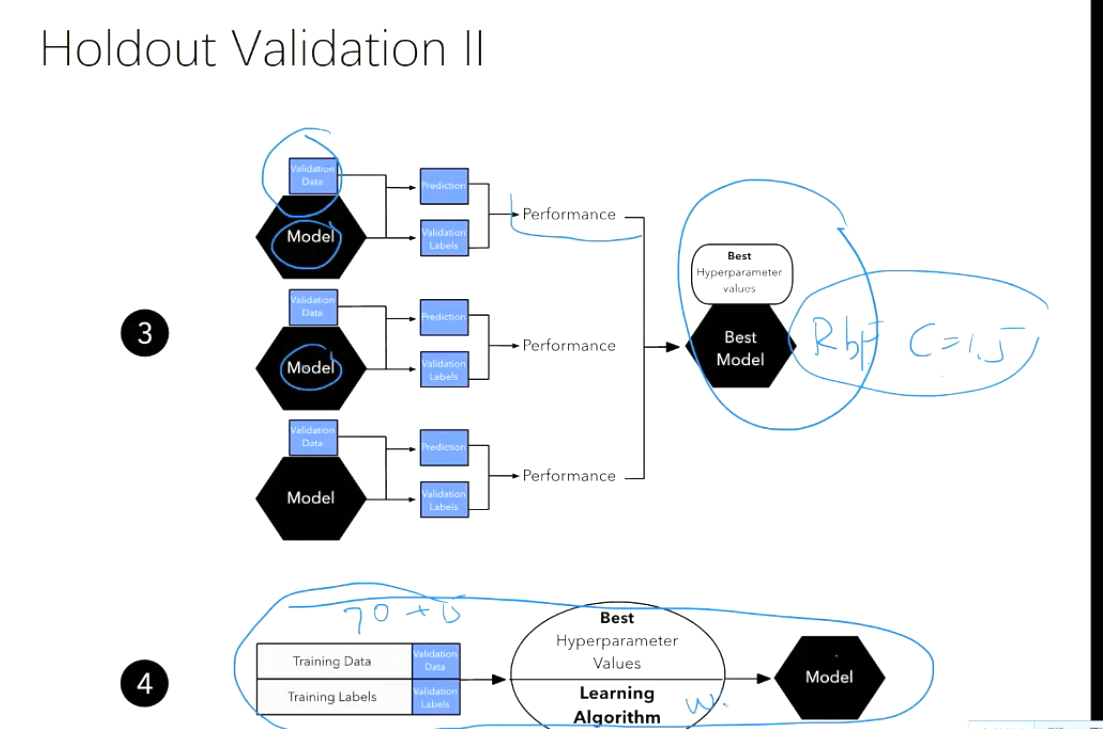
(对不同模型,或者相同模型的不同参数,用验证集进行训练选择;比较出更好的模型+参数时, 再在70+15 %的训练数据集上训练)

(最后在测试集上训练,如果训练效果好,就在全部数据集上再训练一遍)