1. 伪列
1.1. 什么是伪列
伪列是在ORACLE中的一个虚拟的列。
伪列的数据是由ORACLE进行维护和管理的,用户不能对这个列修改,只能查看。
所有的伪列要得到值必须要显式的指定。
最常用的两个伪列:rownum和rowid。
1.2. ROWNUM
ROWNUM(行号):是在查询操作时由ORACLE为每一行记录自动生成的一个编号。
每一次查询ROWNUM都会重新生成。(查询的结果中Oracle给你增加的一个编号,根据结果来重新生成)
rownum永远按照默认的顺序生成。(不受order by的影响)
rownum只能使用 <、 <= ,不能使用 > 、>= 符号,原因是:Oracle是基于行的数据库,行号永远是从1开始,即必须有第一行,才有第二行。
1.2.1. 行号的产生
--需求:查询出所有员工信息,并且显示默认的行号列信息。
SELECT ROWNUM,t.* FROM emp t; -- * 和指定的列一起显示的时候,必须加别名
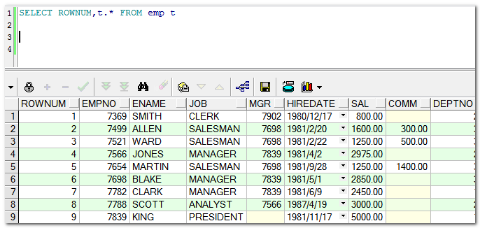
提示两点:
ROWNUM是由数据库自己产生的。ROWNUM查询的时候自动产生的。
1.2.2. 行号的排序
--需求:查询出所有员工信息,按部门号正序排列,并且显示默认的行号列信息。 SELECT ROWNUM,t.* FROM emp t ORDER BY deptno; --order by 原理:将查询结果(此时行号已经有了,已经和每一行数据绑定了)进行排序。 --order by 是查询语句出来的结果之后再排序的,rownu是在查询出来结果的时候产生。order by不会影响到行号 --先排序,再查询

SELECT ROWNUM,t.* FROM ( SELECT * FROM emp ORDER BY deptno ) t

结论:
order by排序,不会影响到rownum的顺序。rownum永远按照默认的顺序生成。
所谓的“默认的顺序”,是指系统按照记录插入时的顺序(其实是rowid)。
1.2.3. 利用行号进行数据分页-重点
回顾mysql如何排序?
select * from table limit m,n 其中m是指记录开始的index,从0开始,表示第一条记录 n是指从第m+1条开始,取n条。 select * from tablename limit 3,3 即取出第4条至第6条,3条记录
Oracle如何分页呢?

结论:Mysql使用limit的关键字可以实现分页,但Oracle没有该关键字,无法使用该方法进行分页。
SELECT ROWNUM,t.* FROM emp t; --查询所有记录 --需求:根据行号查询出第四条到第六条的员工信息。 SELECT ROWNUM,t.* FROM emp t WHERE ROWNUM >=4 AND ROWNUM<=6;--错误 -- rownum只能使用 < 、<=,不能使用 > 、>=符号,原因是:Oracle是基于行的数据库,行号永远是从1开始,即必须有第一行,才有第二行。 SELECT ROWNUM,t.* FROM emp t WHERE ROWNUM<=6; -- 查询1-6条记录 --方案:可以使用子查询(根据行号查询出第四条到第六条的员工信息) SELECT rownum,t2.* FROM ( SELECT ROWNUM r,t.* FROM emp t WHERE ROWNUM<=6 --此时子查询的rownum已经变成了虚表的一个列 ) t2 --尽量让虚表尽量小 WHERE t2.r >=4

Mysql分析: --需求:要分页查询,每页3条记录,查询第二页 /* pageNum=2 当前页码 pageSize=3 最大记录数(即每页显示几条记录) 使用 mysql的分页查询语句,需要两个参数,起始索引和最大记录数 计算: 起始索引:firstIndex=pageSize*(pageNum-1); 最大记录数:maxCount=pageSize; 注意: 1.sql中索引是从1开始的 2.两个参数都是由当前页码和最大记录数计算出来的,所以使用时只定义页码和记录数即可 3.第一页的参数为(0,3),不是说记录的起始索引从0开始,这只是一个参数,实际效果是 从第1条记录开始,记录数为3条,即查询1,2,3三条记录 4.第二页的参数为(3,3),不是说记录的起始索引从3开始,这只是一个参数,实际效果是 从第4条记录开始,记录数为3条,即查询4,5,6三条记录,后面以此类推····· Mysql语句: select * from 表名 limit 起始索引,最大记录数 ------------------------------------------ Oracle分析: //起始行号 firstRownum = pageSize*(pageNum-1)+1 //结束行号 endRownum = firstRownum+pageSize-1 具体计算: firstRownum=3*(2-1)+1=4; endRownum=4+3-1=6; */ --写Oracle的分页,从子查询写起,也就是说从 <= 写起,或者说从endRownum写起 SELECT ROWNUM ,t2.* FROM ( SELECT ROWNUM r,t.* FROM emp t WHERE ROWNUM <=6 ) t2 WHERE t2.r >=4; ------------------------------------------ --优化 --查询所有字段 SELECT * FROM ( SELECT ROWNUM r,t.* FROM emp t WHERE ROWNUM <=6 ) WHERE r >=4; --优化 -- 结果指定字段 SELECT empno,ename,job FROM ( SELECT ROWNUM r,t.* FROM emp t WHERE ROWNUM <=6 ) WHERE r >=4; ------------------------------------------ --需求:按照薪资的高低排序再分页 SELECT * FROM ( SELECT ROWNUM r,t.* FROM emp t WHERE ROWNUM <=6 ORDER BY sal DESC ) WHERE r >=4 ;

--先排序薪资,再分页 SELECT * FROM emp ORDER BY sal DESC; SELECT * FROM ( SELECT ROWNUM r,t.* FROM (SELECT * FROM emp ORDER BY sal DESC) t WHERE ROWNUM <=6 ORDER BY sal DESC ) WHERE r >=4 ;--Hibernate会自动将所有数据封装到实体对象(多余出来的行号那一列不会封装) --如果不需要额外的字段,则只需要指定特定的列名就可以了。 --优化:子查询字段尽量少一些。数据量少。比如,表中有100个字段,但你就想显示5个,那么,你就子查询中直接指定5个就ok了。但使用orm框架的建议都查出来。 SELECT * FROM ( SELECT ROWNUM r,t.* FROM (SELECT ename,job,sal FROM emp ORDER BY sal DESC) t WHERE ROWNUM <=6 ORDER BY sal DESC ) WHERE r >=4 ; --通用查询代码 SELECT * FROM ( SELECT ROWNUM r,t.* FROM (SELECT ename,job,sal FROM emp ORDER BY sal DESC) t WHERE ROWNUM <=endRownum ORDER BY sal DESC ) WHERE r >=firstRownum ; /* 另外一种计算方法(索引算法) firstIndex=pageSize*(pageNum-1); endRownum=firstIndex+pageSize; */ SELECT * FROM ( SELECT ROWNUM r,t.* FROM (SELECT ename,job,sal FROM emp ORDER BY sal DESC) t WHERE ROWNUM <=endRownum ORDER BY sal DESC ) WHERE r > firstIndex;--Hibernate的内置算法
分析原因:
rownum只能使用<、 <=,不能使用>、 >=符号,原因是:Oracle是基于行的数据库,行号永远是从1开始,即必须有第一行,才有第二行。
【提示】:
如何记忆编写Oracle的分页?建议写的时候从里到外来写,即先写小于的条件的子查询(过滤掉rownum大于指定值的数据),再写大于的条件的查询(过滤掉rownum小于的值)。
Oracle的分页中如果需要排序显示,要先排序操作,再分页操作。(再嵌套一个子查询)
性能优化方面:建议在最里层的子查询中就直接指定字段或者其他的条件,减少数据的处理量。

1.3. ROWID
ROWID(记录编号):是表的伪列,是用来唯一标识表中的一条记录,并且间接给出了表行的物理位置,定位表行最快的方式。
主键:标识唯一的一条业务数据的标识。主键是给业务给用户用的。不是给数据库用的。
记录编号rowid:标识唯一的一条数据的。主要是给数据库用的。类似UUID。

1.3.1. ROWID的查看
SELECT t.*,ROWID FROM emp t;

注意:下面这种写法是错的

这两种写法可以:

1.3.2. ROWID的产生
使用insert语句插入数据时,oracle会自动生成rowid 并将其值与表数据一起存放到表行中。
这与rownum有很大不同,rownum不是表中原本的数据,只是在查询的时候才生成的。

提示:rownum默认的排序就是根据rowid


1.3.2. ROWID的作用
这里列举两个常见的应用:
去除重复数据。-- 在plsql Developer工具中,加上rowid可以更改数据。
关于主键和rowid的区别:
相同点:为了标识唯一一条记录的。
不同点:主键:针对业务数据,用来标识不同的一条业务数据。
rowid:针对具体数据的,用来标识不同的唯一的一条数据,跟业务无关。
【示例】需求:删除表中的重复数据,要求保留重复记录中最早插入的那条。(DBA面试题)
--查看rowid SELECT t.*,ROWID FROM emp t; --需求:删除表中的重复数据,要求保留重复记录中最早插入的那条。(DBA面试题) --准备测试表和测试数据: --参考建表语句如下: -- Create table create table test ( id number, name varchar2(50) ); --插入测试数据 INSERT INTO TEST VALUES(1,'xiaoming'); INSERT INTO TEST VALUES(2,'xiaoming'); INSERT INTO TEST VALUES(3,'xiaoming'); COMMIT; SELECT * FROM TEST ; --通过rowid,剔除重复xiaoming,保留最早插入的xiaoming SELECT t.*,ROWID FROM TEST t; --删除的的时候,可以先查询你要删除的东东 SELECT t.*,ROWID FROM TEST t WHERE ROWID > (SELECT MIN(ROWID) FROM TEST); DELETE FROM TEST t WHERE ROWID > (SELECT MIN(ROWID) FROM TEST); --语句有缺点:条件不足,会只保留一条数据,误删其他数据 --重新插入测试数据 INSERT INTO TEST VALUES(1,'xiaoming'); INSERT INTO TEST VALUES(2,'xiaoming'); INSERT INTO TEST VALUES(3,'xiaoming'); INSERT INTO TEST VALUES(4,'Rose'); INSERT INTO TEST VALUES(5,'Rose'); COMMIT; --剔除重复数据 SELECT * FROM TEST WHERE ROWID NOT in(SELECT MIN(ROWID) FROM TEST GROUP BY NAME); DELETE TEST WHERE ROWID NOT in(SELECT MIN(ROWID) FROM TEST GROUP BY NAME);
注意:删除重复记录一定要小心,万一你的条件有问题,就会删错数据.建议删除之前,可以先用查询查一下,看是否是目标数据。
数据一旦删除恢复比较麻烦,但可以恢复,采用日志回滚。一般不要轻易用。