MyCat快速入门
第一章 入门概述
MyCat是什么
Mycat 是数据库中间件。
1. 数据库中间件
中间件:是一类连接软件组件和应用的计算机软件,以便于软件各部件之间的沟通。
例子:Tomcat,web中间件。
数据库中间件:连接java应用程序和数据库
2. 为什么要用Mycat ?
① Java与数据库紧耦合。
② 高访问量高并发对数据库的压力。
③ 读写请求数据不一致
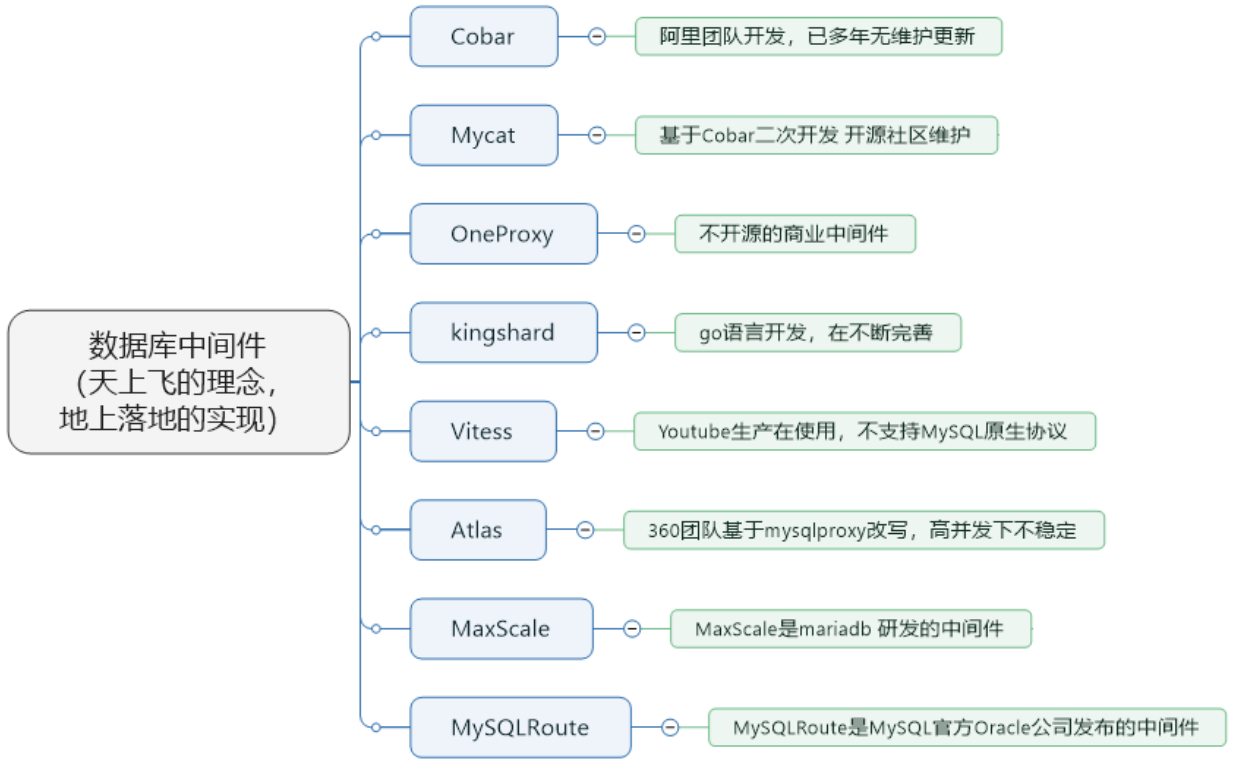
3. 数据库中间件对比
4. Mycat 的 官网
http://www.mycat.io/
MyCat能干什么
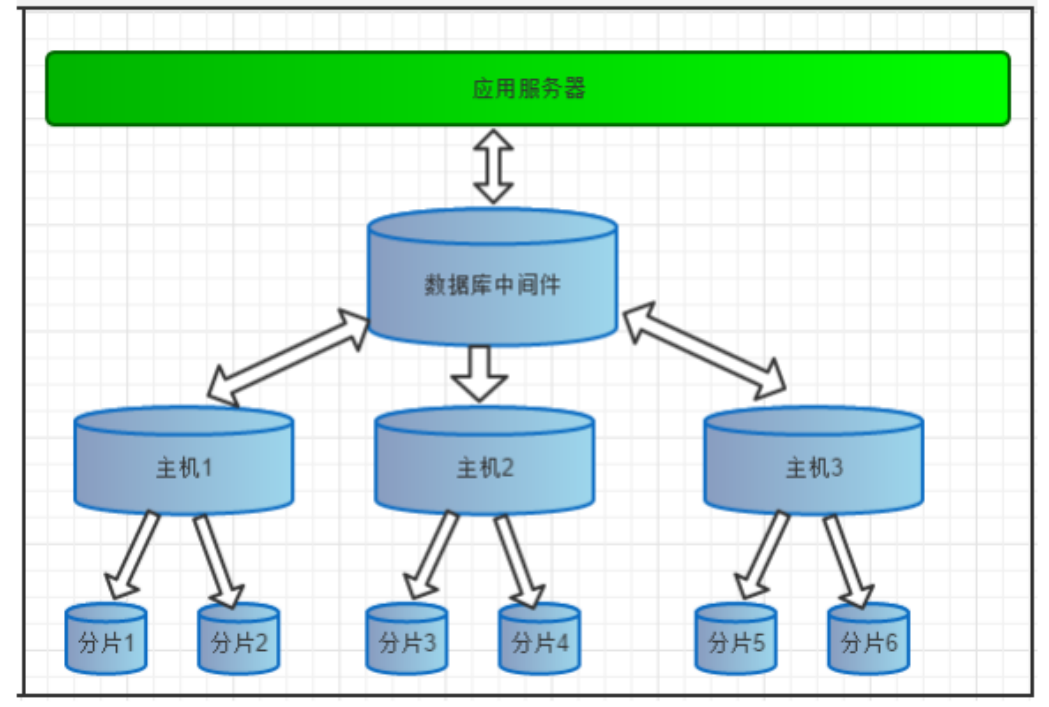
- 1.读写分离
- 2.数据分片
- 垂直拆分(分库)、水平拆分(分表)、垂直+水平拆分(分库分表)
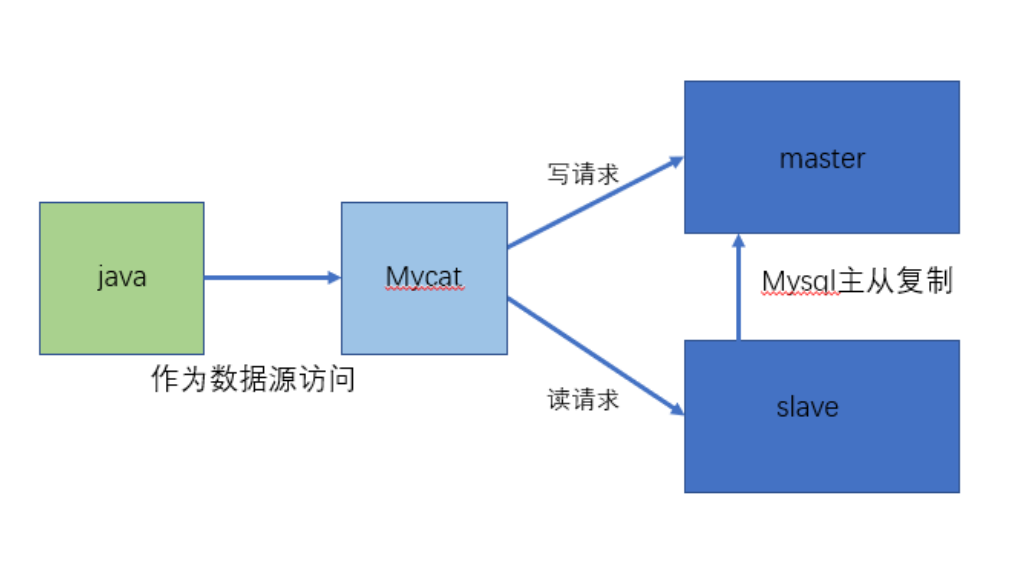
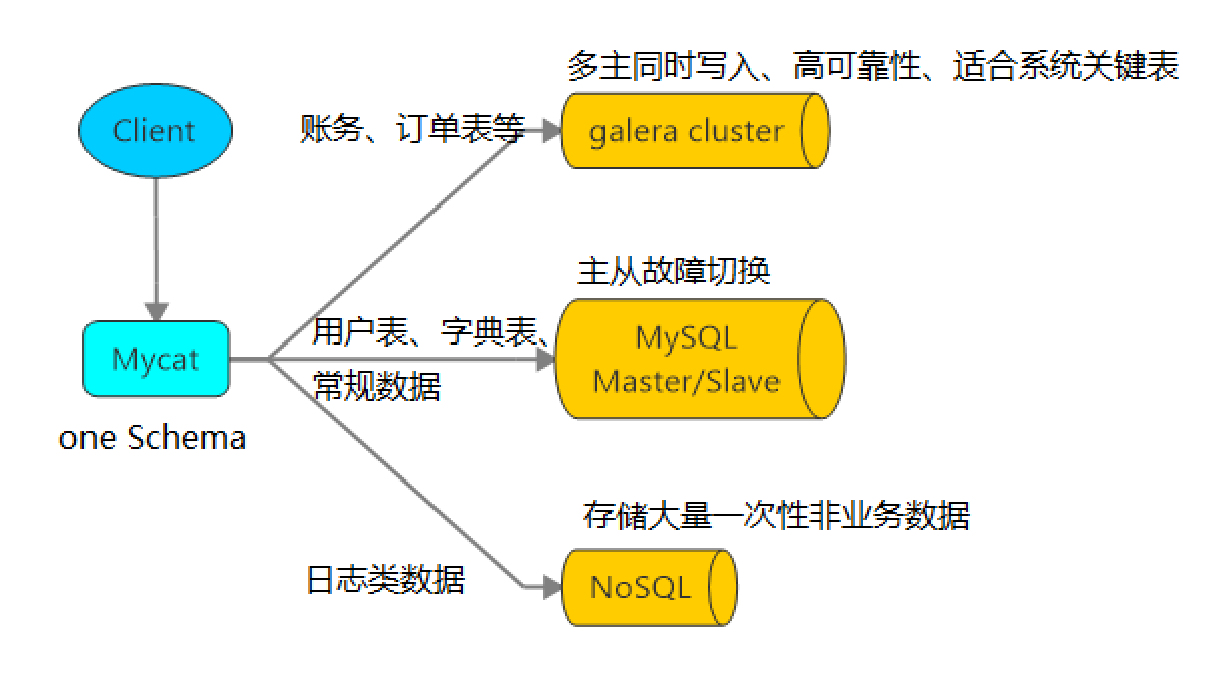
- 3.多数据源整合
MyCat原理
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
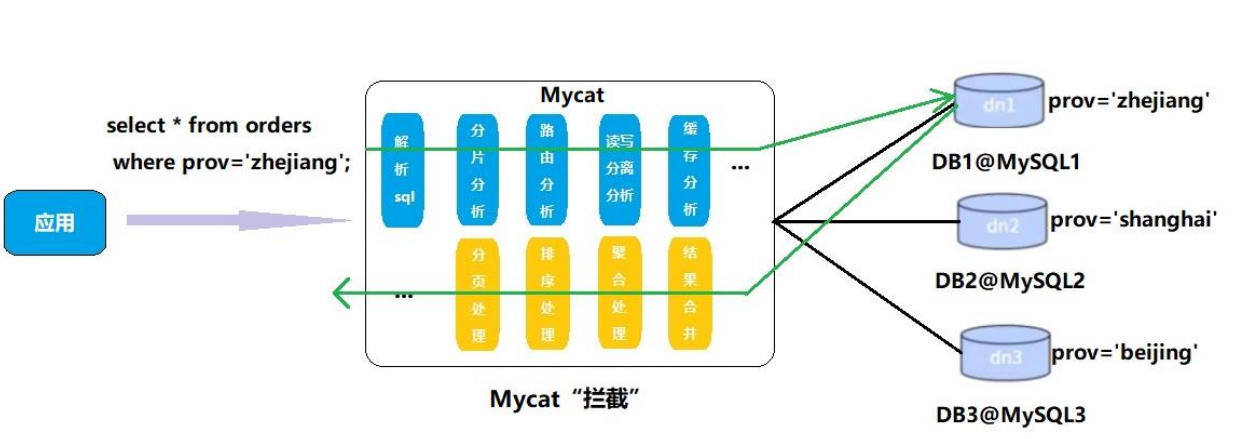
这种方式把数据库的分布式从代码中解耦出来,程序员察觉不出来后台使用 Mycat 还是
MySQL。
第二章 安装启动
安装
- 1 、 解压后即可使用
- 解压缩文件拷贝到 linux 下 /usr/local/
- * 三个配置文件*
- ①schema.xml:定义逻辑库,表、分片节点等内容
- ② rule.xml: 定义分片规则
- ③server.xml:定义用户以及系统相关变量,如端口等
启动
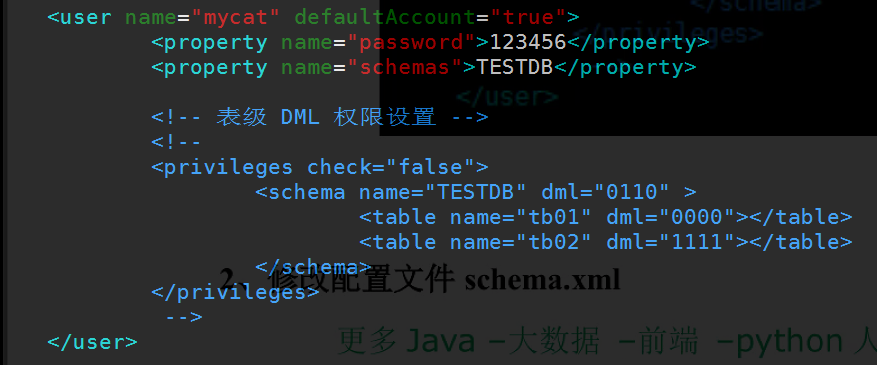
- 修改配置文件 server.xml
- 修改用户信息,与MySQL区分,如下:
-
<user name="mycat"><property name="password">123456</property><property name="schemas">TESTDB</property></user>
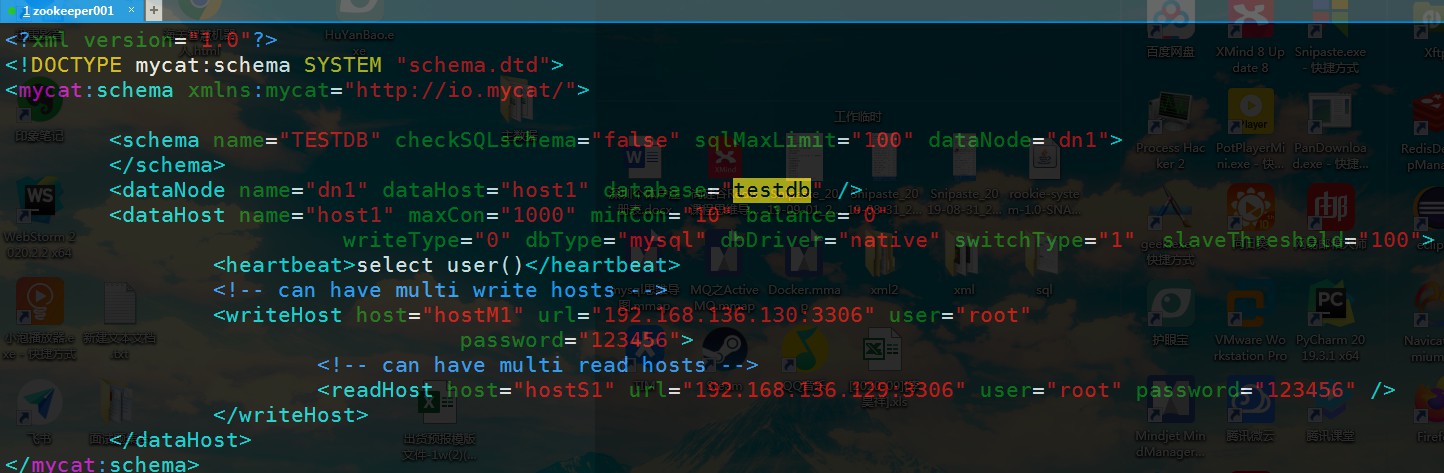
- 修改配置文件 schema.xml
- 删除
<schema>标签间的表信息,<dataNode>标签只留一个,<dataHost>标签只留一个,<writeHost>``<readHost>只留一对 -
<?xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema><dataNode name="dn1" dataHost="host1" database="testdb" /><dataHost name="host1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM1" url="192.168.136.130:3306" user="root"password="123456"><!-- can have multi read hosts --><readHost host="hostS1" url="192.168.136.129:3306" user="root" password="123456" /></writeHost></dataHost></mycat:schema>
- 验证数据库访问情况
Mycat 作为数据库中间件要和数据库部署在不同机器上,所以要验证远程访问情况。
mysql -uroot -p123123 -h 192.168.140.128 -P 3306
mysql -uroot -p123123 -h 192.168.140.127 -P 3306
如远程访问报错,请建对应用户
grant all privileges on . to root@’缺少的host’ identified by ‘123123’;
- 删除
- 启动程序
- ①控制台启动 :去 mycat/bin 目录下执行 ./mycat console
- ②后台启动 :去 mycat/bin 目录下 ./mycat start
- 为了能第一时间看到启动日志,方便定位问题,我们选择①控制台启动。
- 启动时可能出现报错
- 如果操作系统是 CentOS6.8,可能会出现域名解析失败错误,如下图

- 可以按照以下步骤解决
- ① 用 vim 修改 /etc/hosts 文件, 在 127.0.0.1 后面增加你的机器名

- ② 修改后重新启动网络服务

登录
- 登录后台管理窗口
- 此登录方式用于管理维护 Mycat
mysql -umycat -p123456 -P 9066 -h 192.168.140.128- 常用命令如下:
show database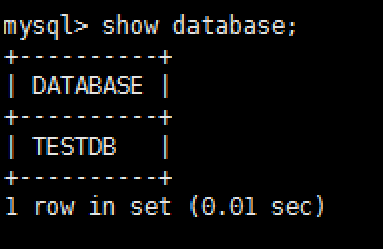
show @@help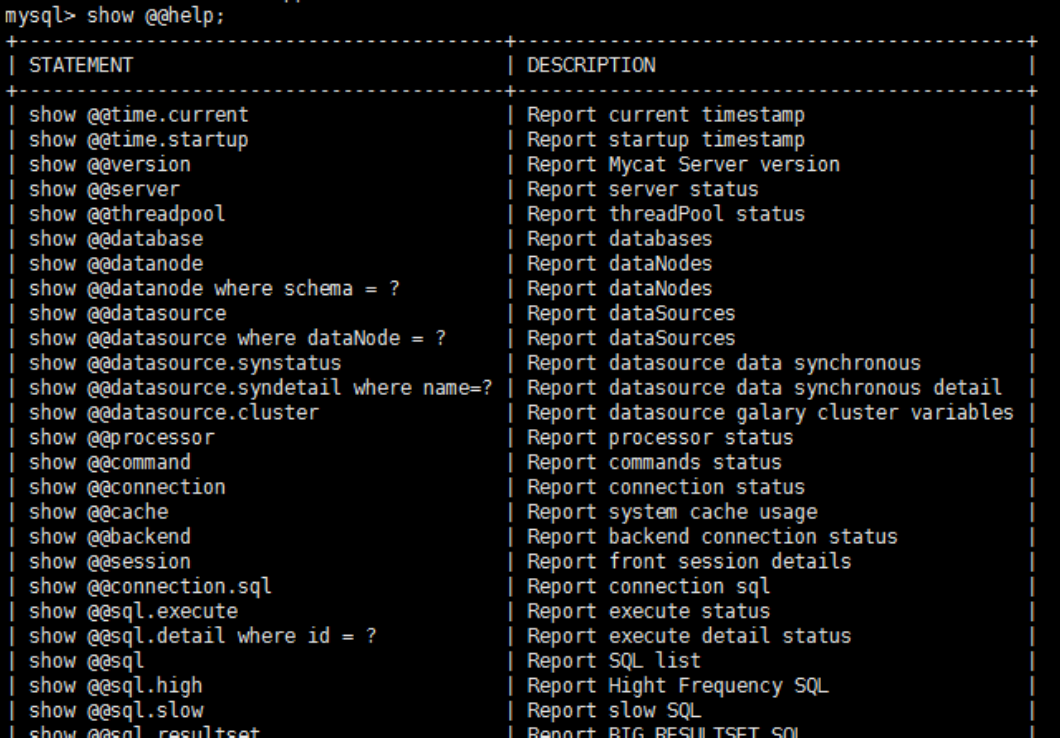
- 登录 数据 窗口
- 此登录方式用于通过 Mycat 查询数据,我们选择这种方式访问 Mycat
mysql -umycat -p123456 -P 8066 -h 192.168.140.128- 如果没有表,需要在逻辑库中创建对应的表!!!
第三章 搭建读写分离
我们通过 Mycat 和 MySQL 的主从复制配合搭建数据库的读写分离,实现 MySQL 的高可用性。
我们将搭建:一主一从、双主双从两种读写分离模式。
搭建一主一从
一个主机用于处理所有写请求,一台从机负责所有读请求,架构图如下

1.搭建 MySQL 数据库主从复制
- 整体规划如下
| 服务器地址 | 备注 |
| 192.168.136.128 | myCat |
| 192.168.136.130 | mysql写主机 master |
| 192.168.136.129 | mysql读主机 slave |
- ① MySQL 主从复制原理
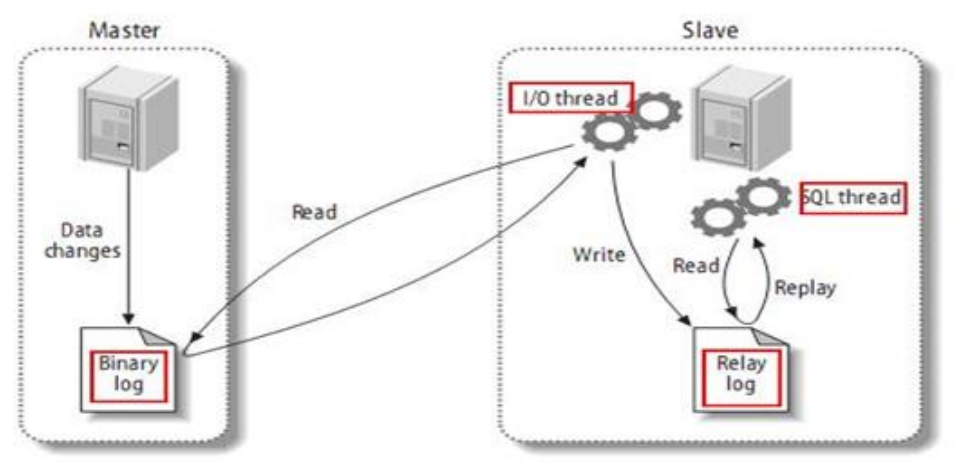
- ② master主机配置(192.168.136.130)
- 修改配置文件:vim /etc/my.cnf
#主服务器唯一IDserver-id=1#启用二进制日志log-bin=mysql-bin# 设置不要复制的数据库(可设置多个)binlog-ignore-db=mysqlbinlog-ignore-db=information_schema#设置需要复制的数据库binlog-do-db=需要复制的主数据库名字#设置logbin格式binlog_format=STATEMENTbinlog 日志的三种格式
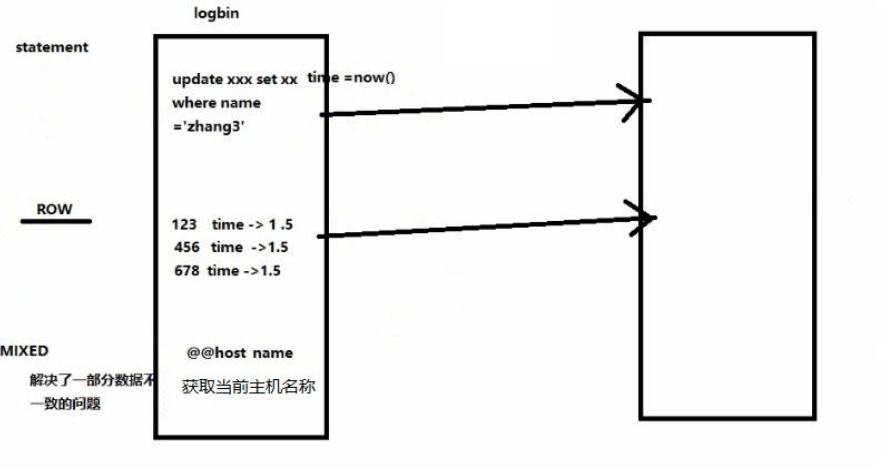
- 修改配置文件:vim /etc/my.cnf
- ③ salve从机配置(192.168.136.129)
修改配置文件:vim /etc/my.cnf
#从服务器唯一IDserver-id=2#启用中继日志relay-log=mysql-relay - ④主机、从机重启 MySQL 服务
- ⑤ 主机从机都关闭防火墙
- ⑥ 在主机上建立帐户并授权 slave
- 在主机MySQL里执行授权命令
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY '123123';- 查询master的状态
show master status;
- 记录下File和Position的值
- 执行完此步骤后不要再操作主服务器MySQL,防止主服务器状态值变化
- ⑦ 在从机上配置需要复制的主机
- 执行复制主机的命令
CHANGE MASTER TO MASTER_HOST='主机的IP地址',MASTER_USER='slave',MASTER_PASSWORD='123123',MASTER_LOG_FILE='mysql-bin.具体数字',MASTER_LOG_POS=具体值;
启动从服务器复制功能start slave;
查看从服务器状态show slave statusG;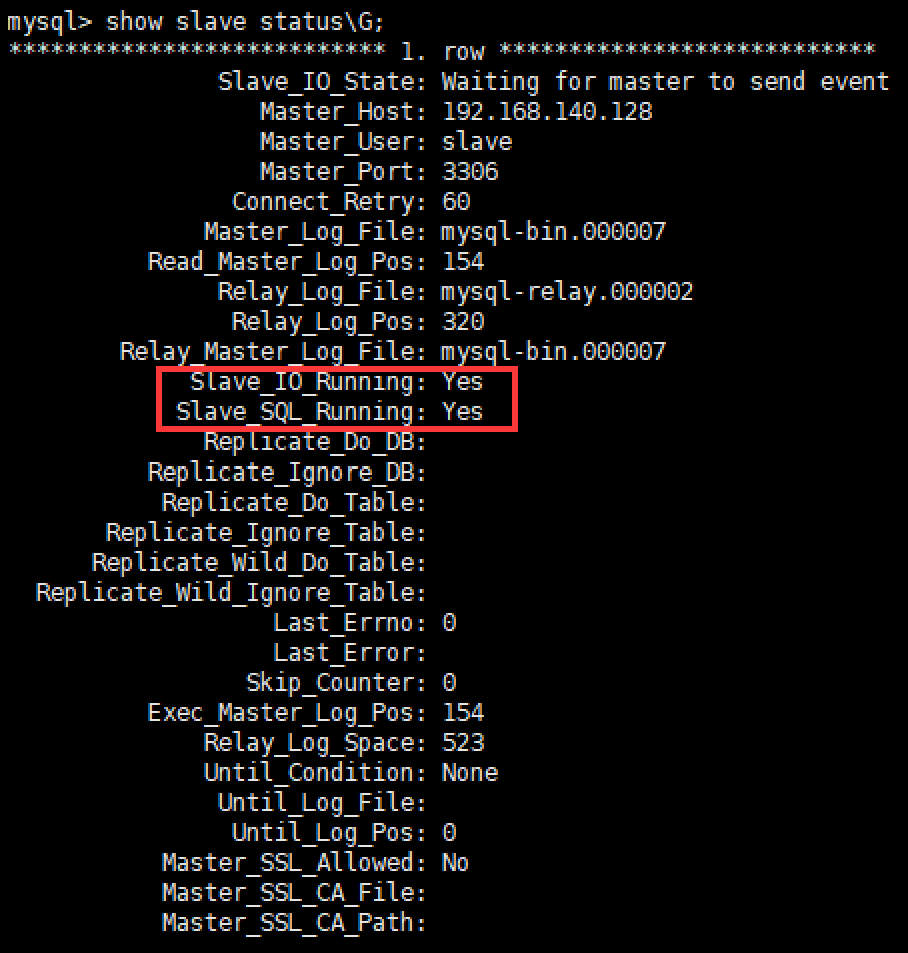
下面两个参数都是Yes,则说明主从配置成功!Slave_IO_Running: YesSlave_SQL_Running: Yes
- 执行复制主机的命令
- ⑧ 主机新建库、新建表、insert 记录,从机复制
此处为视频截图 ip地址为视频中的ip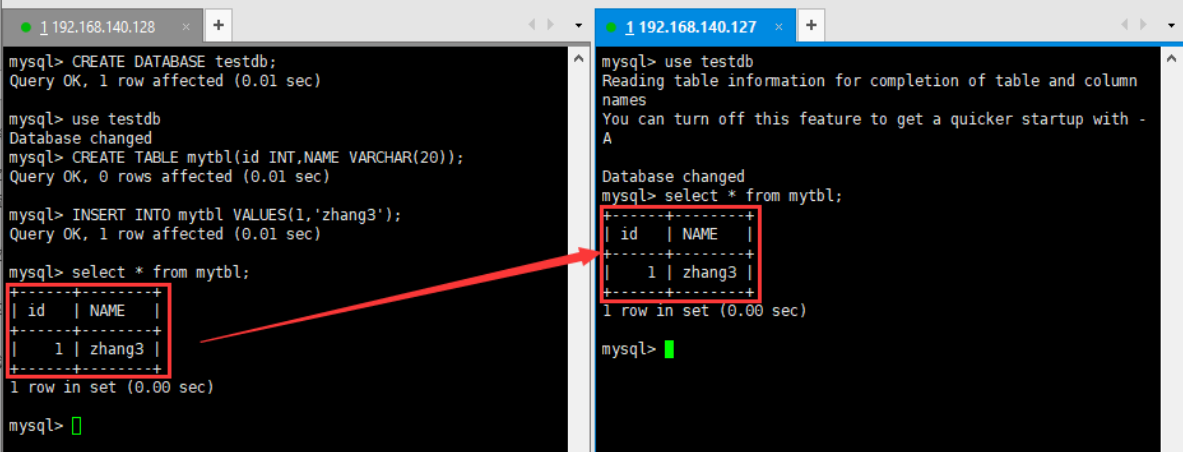
- ⑨ 如何停止从服务复制功能
stop slave; - ⑩ 如何重新配置主从
stop slave;reset master;
2.修改 Mycat 的配置文件 schema.xml
之前的配置已分配了读写主机,是否已实现读写分离?
验证读写分离
(1)在写主机插入:insert into mytbl values (1,@@hostname);
主从主机数据不一致了
(2)在Mycat里查询:select * from mytbl;
修改<dataHost>的 balance属性,通过此属性配置读写分离的类型
负载均衡类型,目前的取值有4 种:
(1)balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
(2)balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从
模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
(3)balance="2",所有读操作都随机的在 writeHost、readhost 上分发。
(4)balance="3",所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力
为了能看到读写分离的效果,把balance设置成2,会在两个主机间切换查询

3.重新 启动 Mycat
4. 验证读写分离
(1)在写主机数据库表mytbl中插入带系统变量数据,造成主从数据不一致 INSERT INTO mytbl VALUES(2,@@hostname);
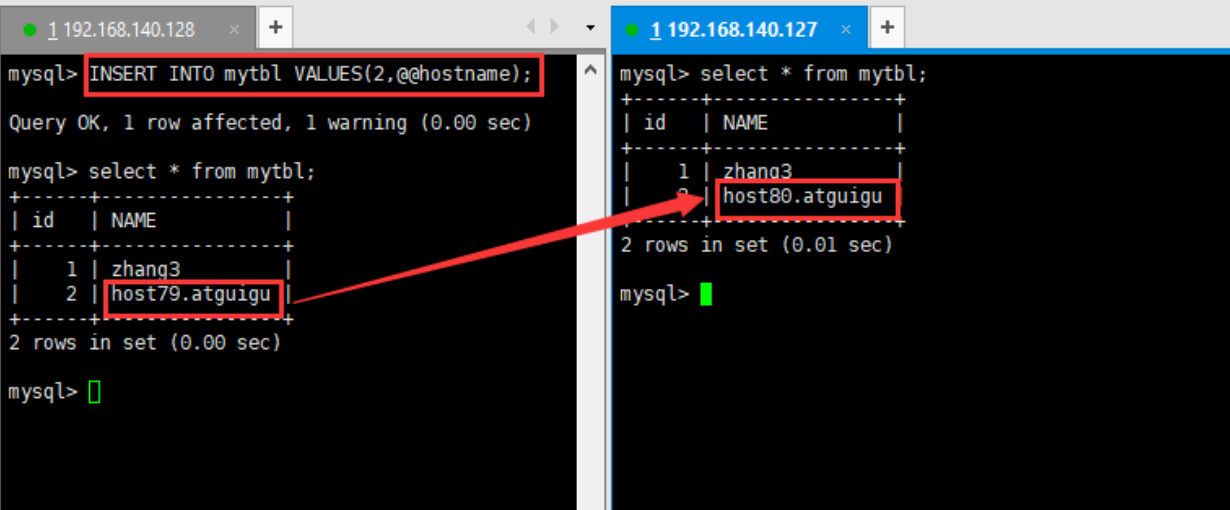
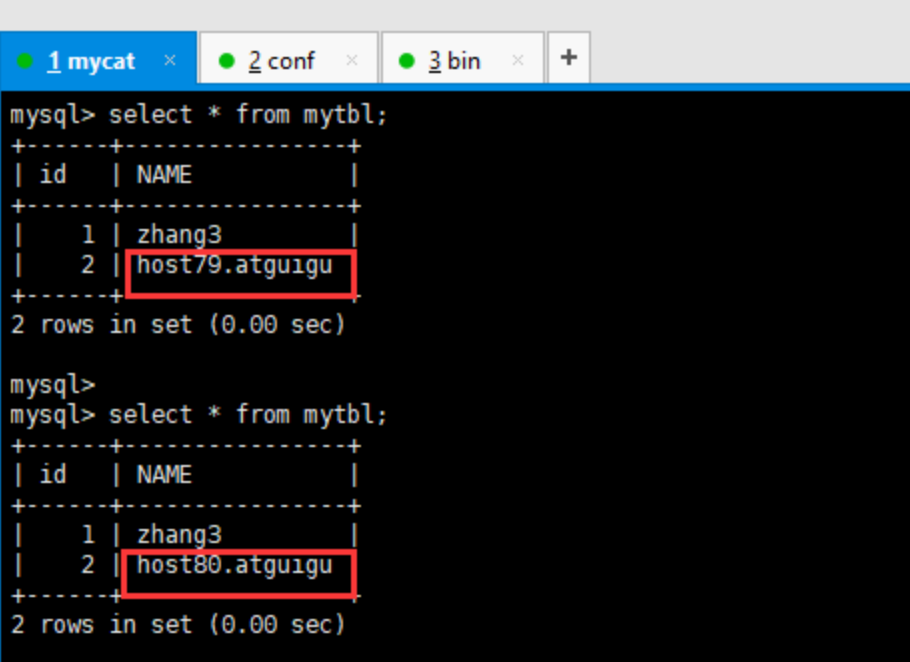
(2)在Mycat里查询mytbl表,可以看到查询语句在主从两个主机间切换
搭建双主双从
第四章 垂直拆分–分库
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,
分布到不同 的数据库上面,这样也就将数据或者说压力分担到不同的库上面,如下图:
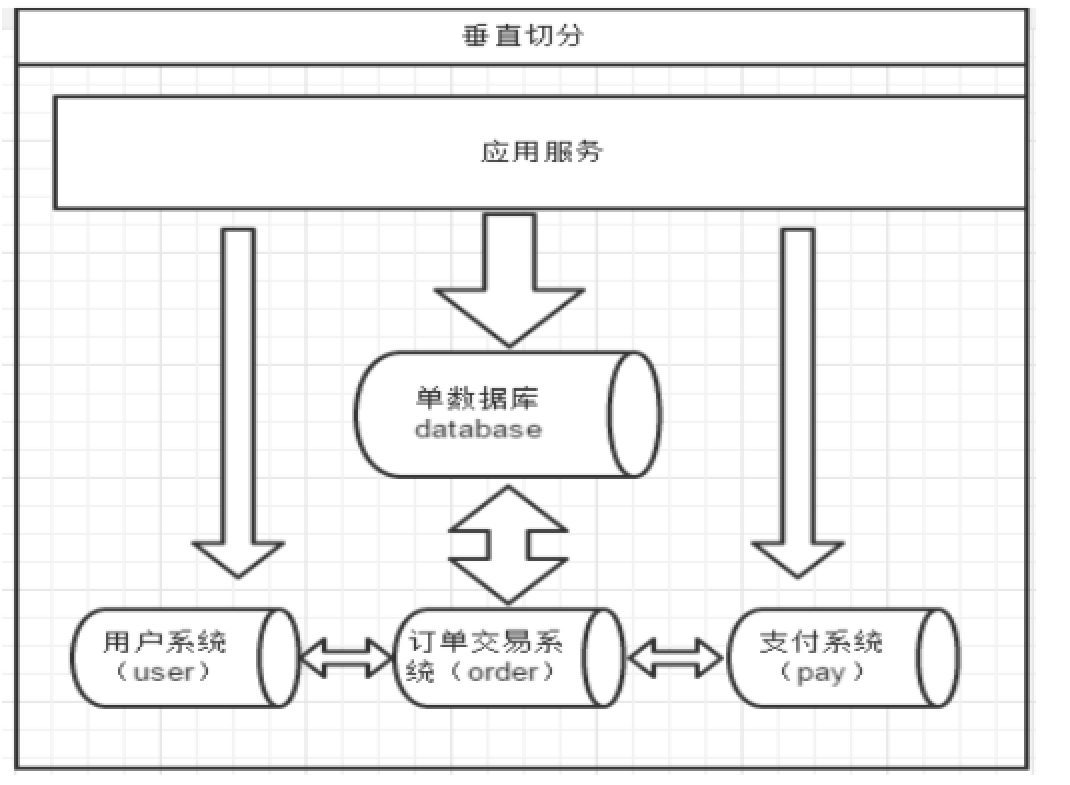
系统被切分成了,用户,订单交易,支付几个模块。
如何划分表
一个问题:在两台主机上的两个数据库中的表,能否关联查询?
答案:不可以关联查询。
分库的原则:有紧密关联关系的表应该在一个库里,相互没有关联关系的表可以分到不同的库里。
客户表 rows:20万
订单表 rows:600万
订单详细表 rows:600万
订单状态字典表 rows:20
以上四个表如何分库?客户表分在一个数据库,另外三张都需要关联查询,分在另外一个数据库。
实现 分库
1 、 修改 schema 配置文件
2 、 新增两个空白库
分库操作不是在原来的老数据库上进行操作,需要准备两台机器分别安装新的数据库
在数据节点 dn1、dn2 上分别创建数据库 orders CREATE DATABASE orders;
3 、 启动 Mycat
./mycat console
4 、 访问 Mycat 进行分库
访问 Mycat
mysql -umycat -p123456 -h 192.168.140.128 -P 8066
切换到 TESTDB
创建 4 张表
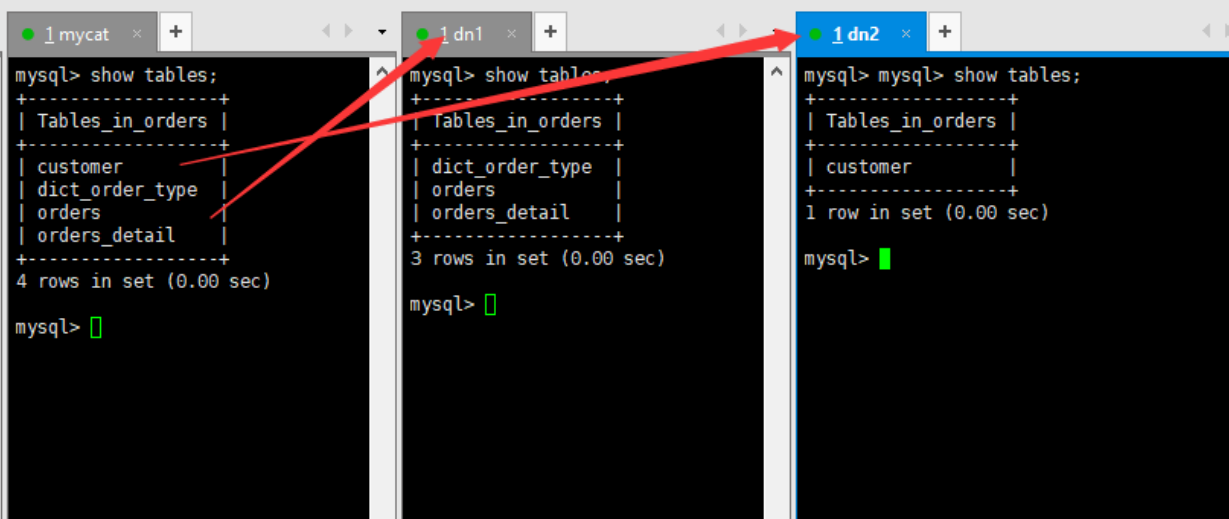
查看表信息,可以看到成功分库
第五章 水平拆分 —— 分表
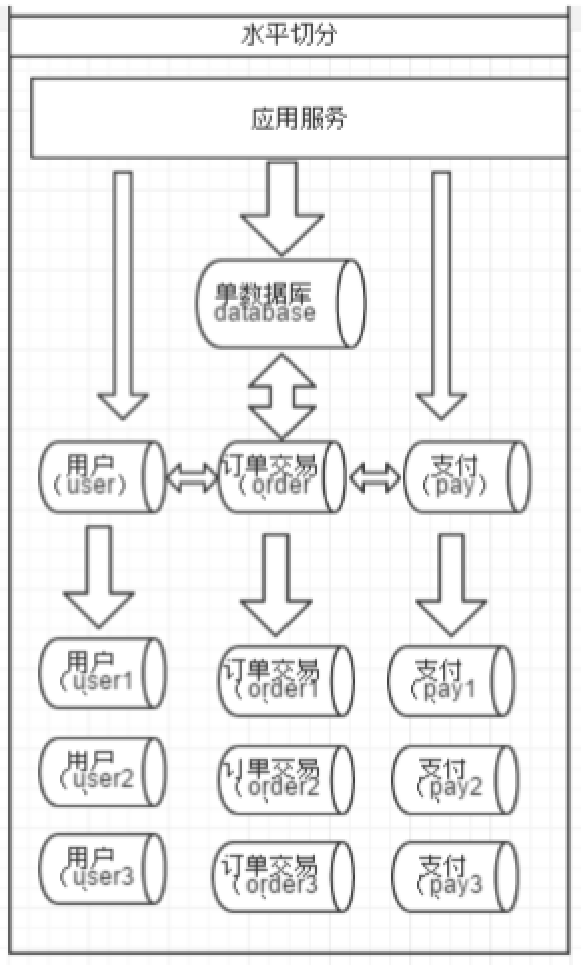
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,
每个表中 包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就
是将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中,如图:
实现 分表
1 、 选择要拆分的表
MySQL 单表存储数据条数是有瓶颈的,单表达到 1000 万条数据就达到了瓶颈,会影响查询效率,
需要进行水平拆分(分表)进行优化。
例如:例子中的 orders、orders_detail 都已经达到 600 万行数据,需要进行分表优化。
2 、 分表
以 orders 表为例,可以根据不同自字段进行分表
| 编号 | 分库字段 | 效果 |
| 1 | id(主键或者创建时间) | 查询订单注重时效,历史订单被查询的次数少,如此分片会造成一个节点访问多,一个访问,不平均 |
| 2 | customer_id(客户 id) | 根据客户 id 去分,两个节点访问平均,一个客户的所 |
有订单都在同一个节点|
3 、 修改配置件 文件 schema.xml
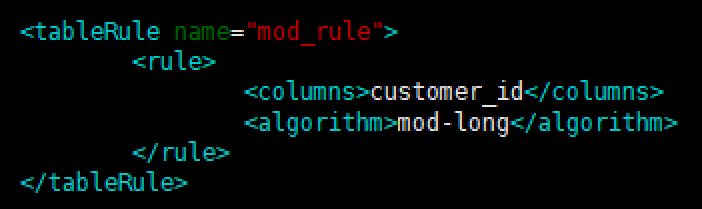
为 orders 表设置数据节点为 dn1、dn2,并指定分片规则为 mod_rule(自定义的名字) <table name="orders" dataNode="dn1,dn2" rule="mod_rule" ></table>
如下图

4 、 修改配置文件 rule.xml
在 rule 配置文件里新增分片规则 mod_rule,并指定规则适用字段为 customer_id,
还有选择分片算法 mod-long(对字段求模运算),customer_id 对两个节点求模,根据结果分片
配置算法 mod-long 参数 count 为 2,两个节点

5 、 在数据节点 dn2 上创建 orders 表
务必保证 两个节点 都要orders表
6 、 重启 Mycat ,让配置生效
7 、 访问 Mycat 实现分片
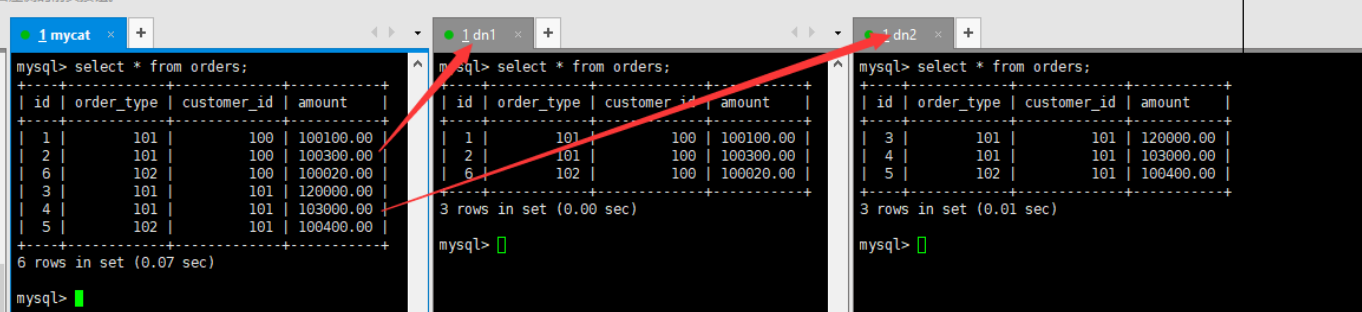
在 mycat 里向 orders 表插入数据,INSERT 字段不能省略
在mycat、dn1、dn2中查看orders表数据,分表成功
Mycat 的分片 “join ”
* Orders 订单表已经进行分表操作了,和它关联的 orders_detail 订单详情表如何进行 join 查询*
我们要对 orders_detail 也要进行分片操作。Join 的原理如下图:

1 、 ER 表
Mycat 借鉴了 NewSQL 领域的新秀 Foundation DB 的设计思路,Foundation DB 创新性的提
出了 Table Group 的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了
JION 的效率和性能问 题,根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所
关联的父表记录存放在同一个数据分片上。
- 修改 schema.xml 配置文件
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" ><childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" /></table>
- 在 dn2 创建 orders_detail 表
- 重启 Mycat
- 访问 Mycat 向 orders_detail 表插入数据
INSERT INTO orders_detail(id,detail,order_id) values(1,'detail1',1);INSERT INTO orders_detail(id,detail,order_id) VALUES(2,'detail1',2);INSERT INTO orders_detail(id,detail,order_id) VALUES(3,'detail1',3);INSERT INTO orders_detail(id,detail,order_id) VALUES(4,'detail1',4);INSERT INTO orders_detail(id,detail,order_id) VALUES(5,'detail1',5);INSERT INTO orders_detail(id,detail,order_id) VALUES(6,'detail1',6); - 在mycat、dn1、dn2中运行两个表join语句
Select o.*,od.detail from orders o inner join orders_detail od on o.id=od.order_id;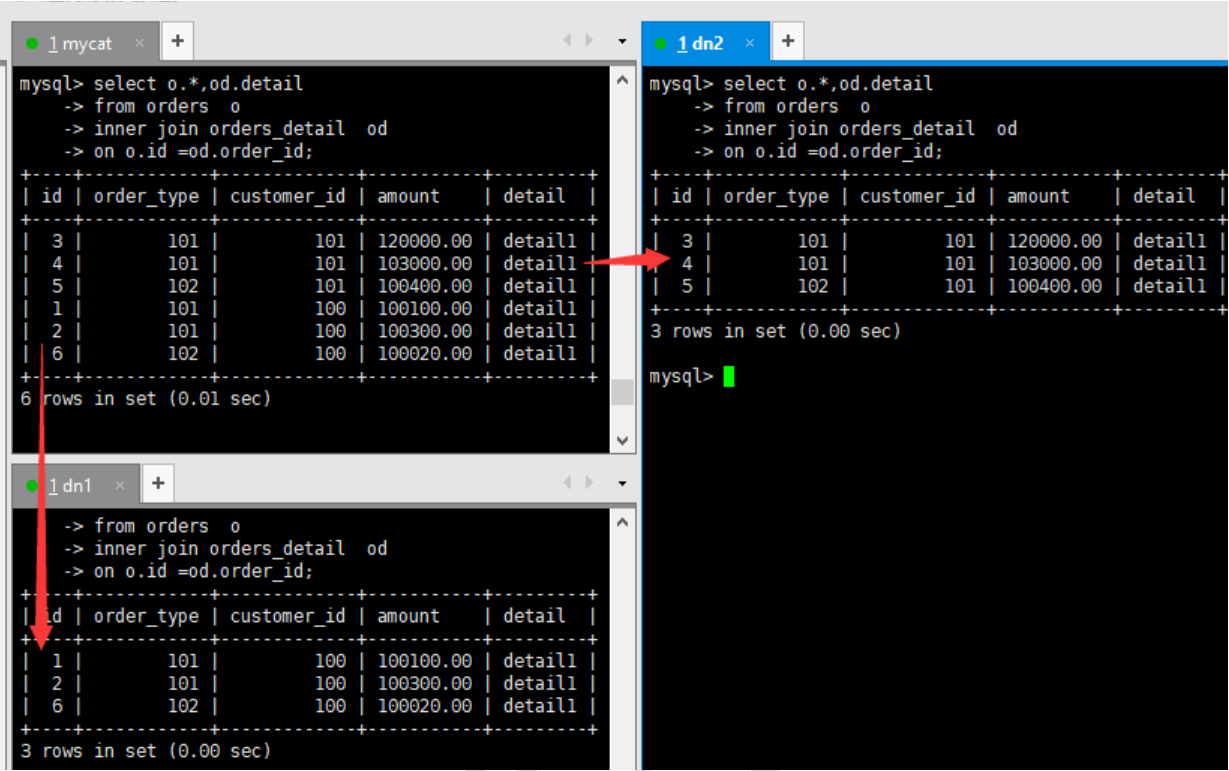
2 、 全局表
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,
就成了比较 棘手的问题,考虑到字典表具有以下几个特性:
- ① 变动不频繁
- ② 数据量总体变化不大
- ③ 数据规模不大,很少有超过数十万条记录
鉴于此,Mycat 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
- ① 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
- ② 全局表的查询操作,只从一个节点获取
- ③ 全局表可以跟任何一个表进行 JOIN 操作
将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据
JOIN 的难题。通过全局表+基于 E-R 关系的分片策略,Mycat 可以满足 80%以上的企业应用开发
- 1.修改 schema.xml 配置文件
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" ><childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" /></table><table name="dict_order_type" dataNode="dn1,dn2" type="global" ></table>
- 2.在 dn2 创建 dict_order_type 表
- 3.重启 Mycat
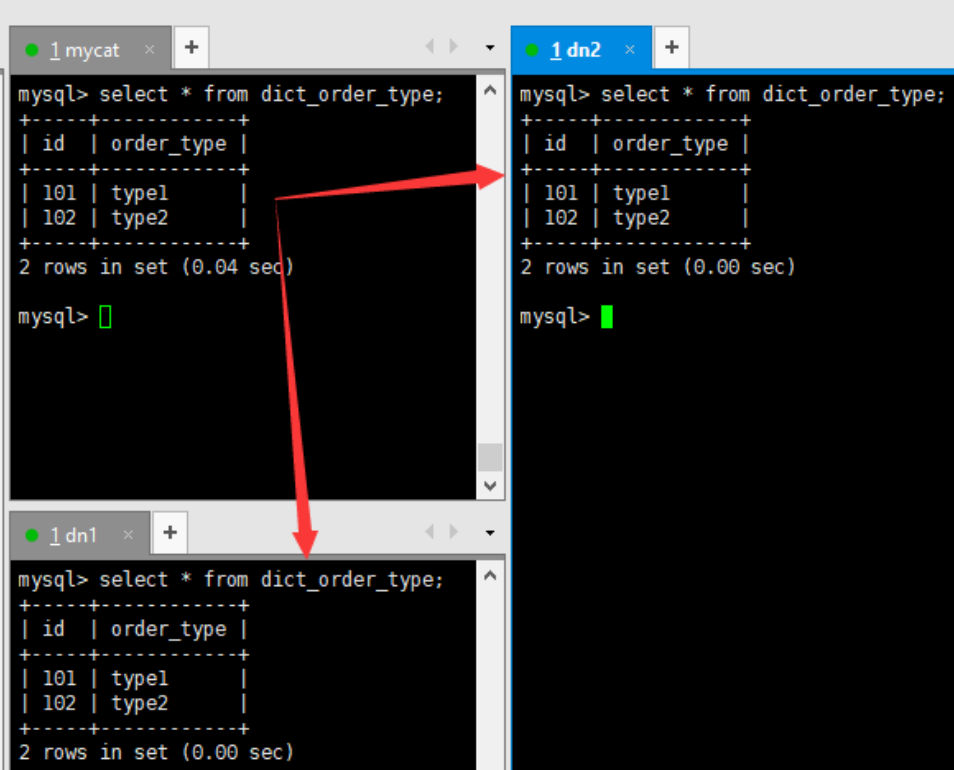
- 4.访问 Mycat 向 dict_order_type 表插入数据
INSERT INTO dict_order_type(id,order_type) VALUES(101,'type1');INSERT INTO dict_order_type(id,order_type) VALUES(102,'type2'); - 5.在Mycat、dn1、dn2中查询表数据
常用分片规则
1 、 取模
此规则为对分片字段求摸运算。也是水平分表最常用规则。5.1 配置分表中,orders 表采用了此规
则。
2 、 分片枚举
通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务
需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则。
- (1)修改schema.xml配置文件
<table name="orders_ware_info" dataNode="dn1,dn2" rule="sharding_by_intfile" ></table> - (2)修改rule.xml配置文件
<tableRule name="sharding_by_intfile"><rule><columns>areacode</columns><algorithm>hash-int</algorithm></rule></tableRule><function name="hash-int"class="io.mycat.route.function.PartitionByFileMap"><property name="mapFile">partition-hash-int.txt</property><property name="type">1</property><property name="defaultNode">0</property></function>columns:分片字段,algorithm:分片函数
mapFile:标识配置文件名称,type:0为int型、非0为String,
defaultNode:默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点,
设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就报错 - (3)修改partition-hash-int.txt配置文件
110=0
120=1 - (4)重启 Mycat
- (5)访问Mycat创建表
订单归属区域信息表
CREATE TABLE orders_ware_info(`id` INT AUTO_INCREMENT comment '编号',`order_id` INT comment '订单编号',`address` VARCHAR(200) comment '地址',`areacode` VARCHAR(20) comment '区域编号',PRIMARY KEY(id)); - (6)插入数据
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (1,1,'北京','110');INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (2,2,'天津','120'); - (7)查询Mycat、dn1、dn2可以看到数据分片效果
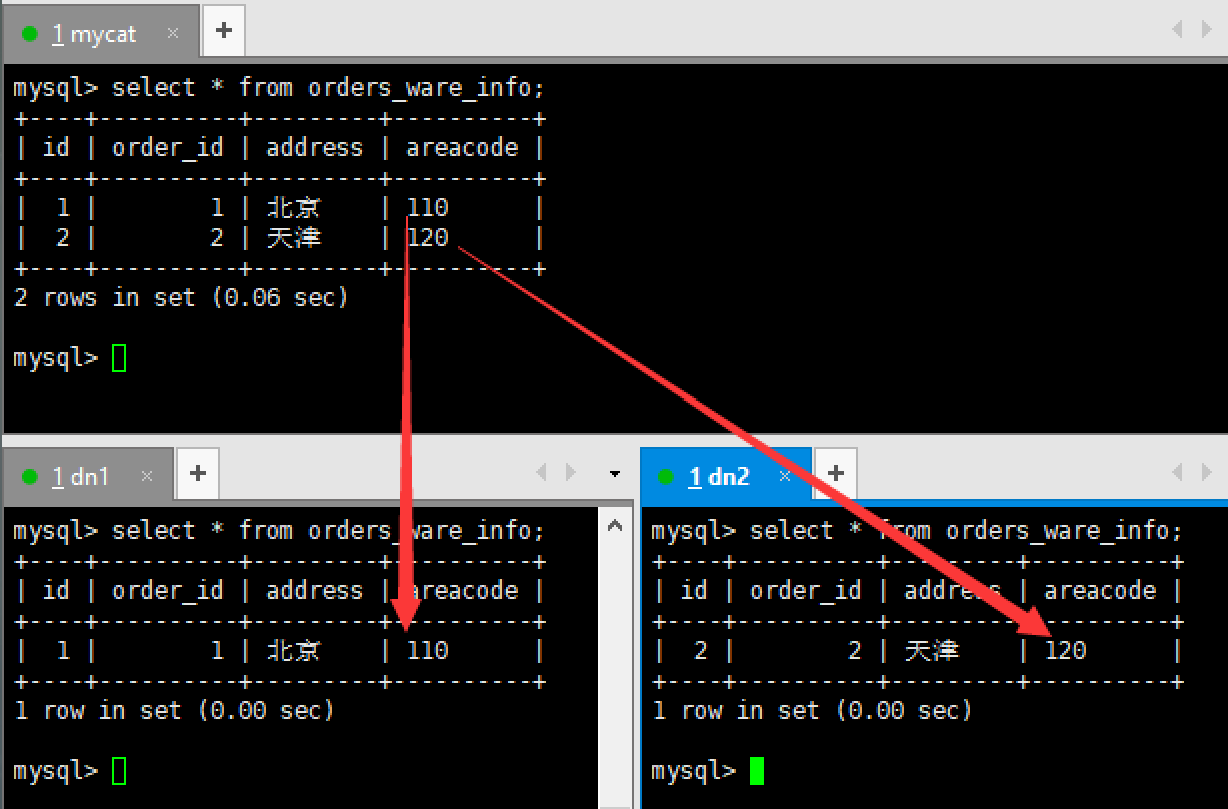
3 、 范围约定
此分片适用于,提前规划好分片字段某个范围属于哪个分片。
- (1)修改schema.xml配置文件
<table name="payment_info" dataNode="dn1,dn2" rule="auto_sharding_long" ></table> - (2)修改rule.xml配置文件
<tableRule name="auto_sharding_long"><rule><columns>order_id</columns><algorithm>rang-long</algorithm></rule></tableRule><function name="rang-long"class="io.mycat.route.function.AutoPartitionByLong"><property name="mapFile">autopartition-long.txt</property><property name="defaultNode">0</property></function>columns:分片字段,algorithm:分片函数
mapFile:标识配置文件名称
defaultNode:默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点,设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就报错 - (3)修改autopartition-long.txt配置文件
0-102=0
103-200=1 - (4)重启 Mycat
- (5)访问Mycat创建表
支付信息表
CREATE TABLE payment_info(`id` INT AUTO_INCREMENT comment '编号',`order_id` INT comment '订单编号',`payment_status` INT comment '支付状态',PRIMARY KEY(id)); - (6)插入数据
INSERT INTO payment_info (id,order_id,payment_status) VALUES (1,101,0);INSERT INTO payment_info (id,order_id,payment_status) VALUES (2,102,1);INSERT INTO payment_info (id,order_id ,payment_status) VALUES (3,103,0);INSERT INTO payment_info (id,order_id,payment_status) VALUES (4,104,1); - (7)查询Mycat、dn1、dn2可以看到数据分片效果
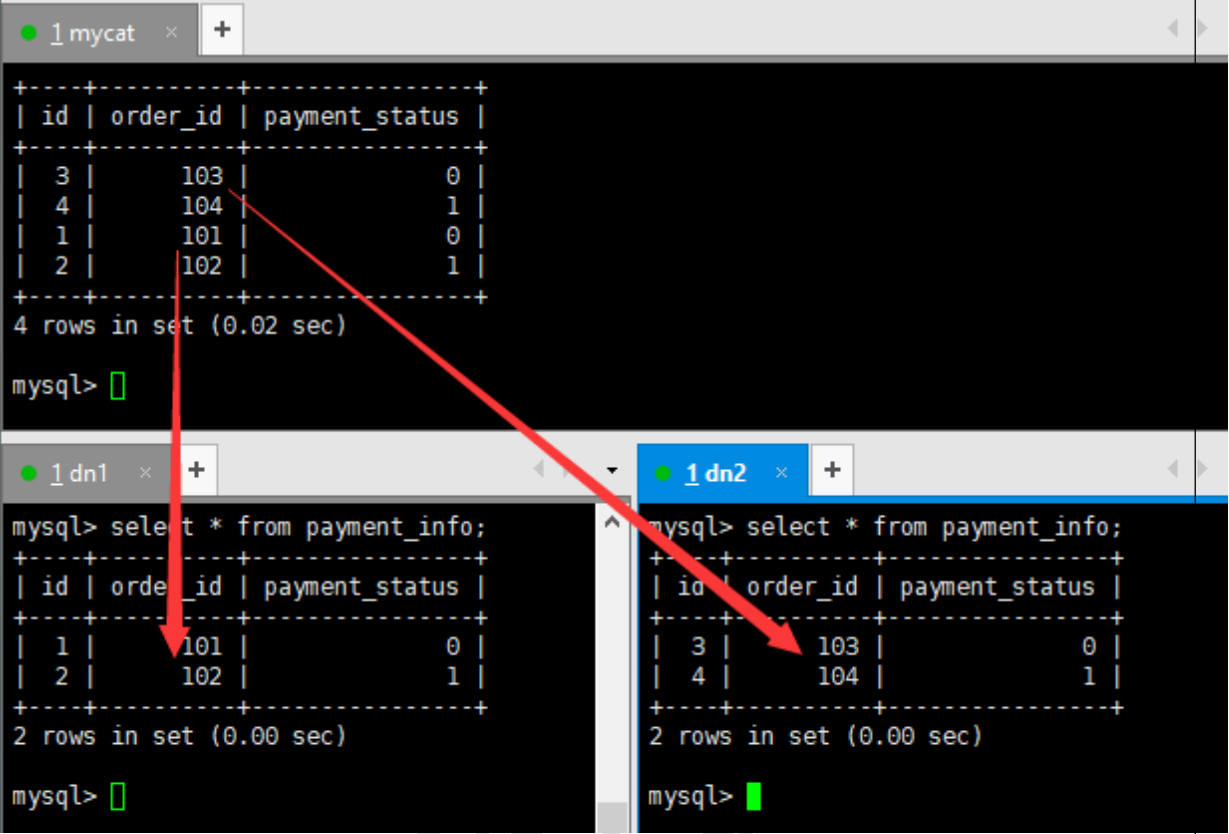
4 、 按日期(天)分片
- (1)修改schema.xml配置文件
<table name="login_info" dataNode="dn1,dn2" rule="sharding_by_date" ></table> - (2)修改rule.xml配置文件
<tableRule name="sharding_by_date"><rule><columns>login_date</columns><algorithm>shardingByDate</algorithm></rule></tableRule><function name="shardingByDate" class="io.mycat.route.function.PartitionByDate"><property name="dateFormat">yyyy-MM-dd</property><property name="sBeginDate">2019-01-01</property><property name="sEndDate">2019-01-04</property><property name="sPartionDay">2</property></function>columns:分片字段,algorithm:分片函数
dateFormat :日期格式
sBeginDate :开始日期
sEndDate:结束日期,则代表数据达到了这个日期的分片后循环从开始分片插入
sPartionDay :分区天数,即默认从开始日期算起,分隔 2 天一个分区 - (3)重启 Mycat
- (4)访问Mycat创建表
用户信息表
CREATE TABLE login_info(`id` INT AUTO_INCREMENT comment '编号',`user_id` INT comment '用户编号',`login_date` date comment '登录日期',PRIMARY KEY(id)); - (6)插入数据
INSERT INTO login_info(id,user_id,login_date) VALUES (1,101,'2019-01-01');INSERT INTO login_info(id,user_id,login_date) VALUES (2,102,'2019-01-02');INSERT INTO login_info(id,user_id,login_date) VALUES (3,103,'2019-01-03');INSERT INTO login_info(id,user_id,login_date) VALUES (4,104,'2019-01-04');INSERT INTO login_info(id,user_id,login_date) VALUES (5,103,'2019-01-05');INSERT INTO login_info(id,user_id,login_date) VALUES (6,104,'2019-01-06'); - (7)查询Mycat、dn1、dn2可以看到数据分片效果
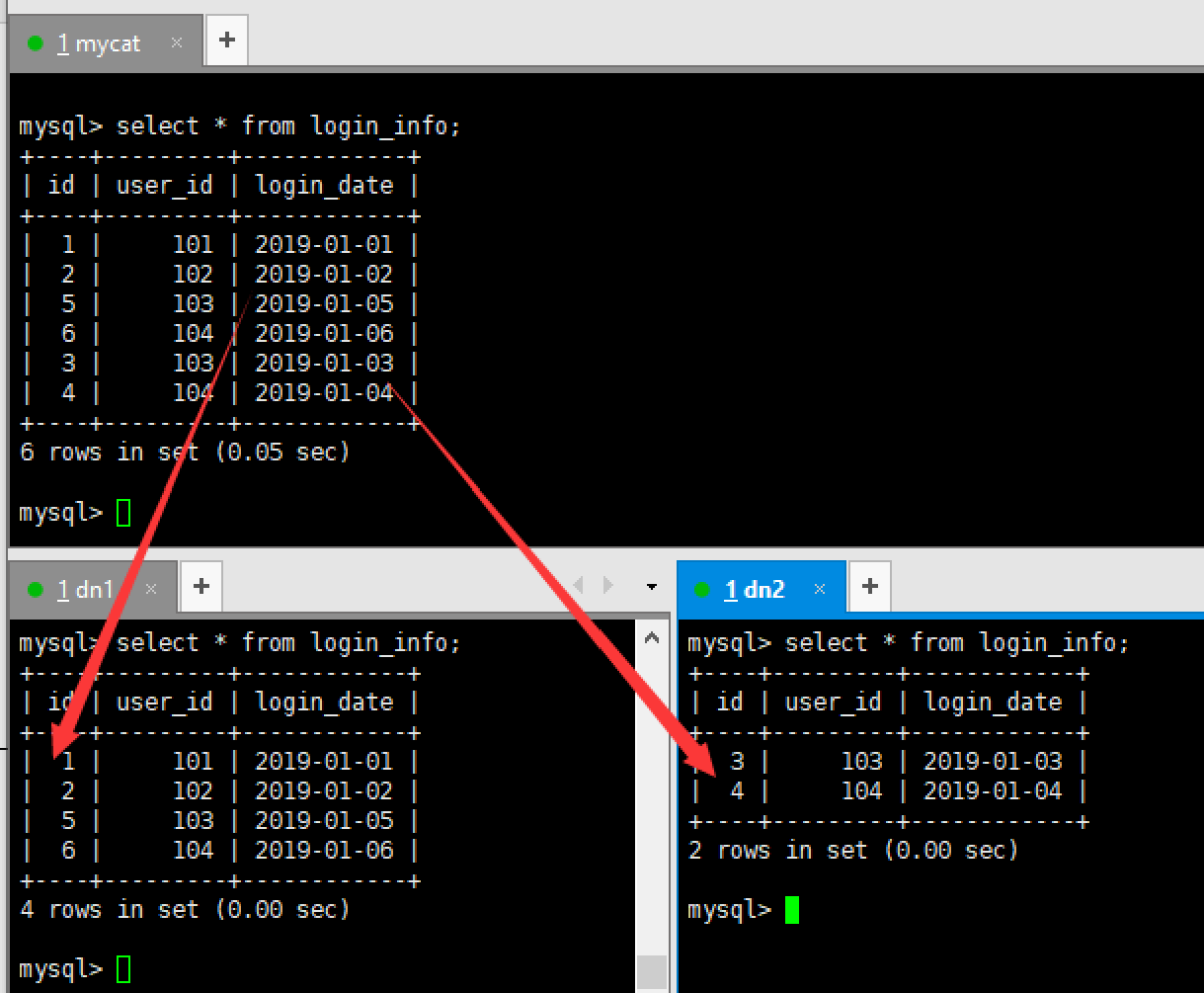
全局序列
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为此,Mycat 提供
了全局 sequence,并且提供了包含本地配置和数据库配置等多种实现方式
1 、 本地文件
此方式 Mycat 将 sequence 配置到文件中,当使用到 sequence 中的配置后,Mycat 会更下
classpath 中的 sequence_conf.properties 文件中 sequence 当前的值。
① 优点:本地加载,读取速度较快
② 缺点:抗风险能力差,Mycat 所在主机宕机后,无法读取本地文件。
2 、 数据库方式
利用数据库一个表 来进行计数累加。但是并不是每次生成序列都读写数据库,这样效率太低。
Mycat 会预加载一部分号段到 Mycat 的内存中,这样大部分读写序列都是在内存中完成的。
如果内存中的号段用完了 Mycat 会再向数据库要一次。
问:那如果 Mycat 崩溃了 ,那内存中的序列岂不是都没了?
是的。如果是这样,那么 Mycat 启动后会向数据库申请新的号段,原有号段会弃用。
也就是说如果 Mycat 重启,那么损失是当前的号段没用完的号码,但是不会因此出现主键重复
- ① 建库序列脚本
在 dn1 上创建全局序列表
CREATE TABLE MYCAT_SEQUENCE (NAME VARCHAR(50) NOT NULL,current_value INT NOTNULL,increment INT NOT NULL DEFAULT 100, PRIMARY KEY(NAME)) ENGINE=INNODB;创建全局序列所需函数
DELIMITER $$CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)DETERMINISTICBEGINDECLARE retval VARCHAR(64);SET retval="-999999999,null";SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retval FROMMYCAT_SEQUENCE WHERE NAME = seq_name;RETURN retval;END $$DELIMITER ;DELIMITER $$CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNSVARCHAR(64)DETERMINISTICBEGINUPDATE MYCAT_SEQUENCESET current_value = VALUEWHERE NAME = seq_name;RETURN mycat_seq_currval(seq_name);END $$DELIMITER ;DELIMITER $$CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)DETERMINISTICBEGINUPDATE MYCAT_SEQUENCESET current_value = current_value + increment WHERE NAME = seq_name;RETURN mycat_seq_currval(seq_name);END $$DELIMITER ;初始化序列表记录
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('ORDERS', 400000,100);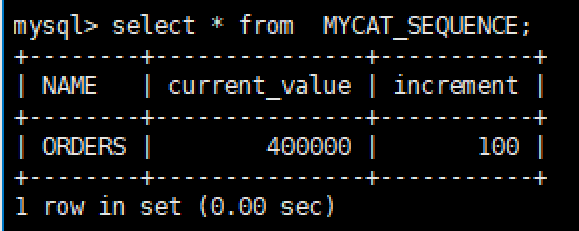
- ② 修改 Mycat 配置
修改 sequence_db_conf.properties
vim sequence_db_conf.properties
意思是 ORDERS这个序列在dn1这个节点上,具体dn1节点是哪台机子,请参考schema.xml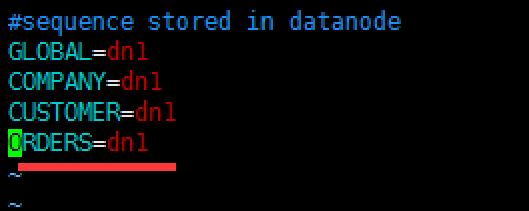
修改 server.xml
vim server.xml
全局序列类型:0-本地文件,1-数据库方式,2-时间戳方式。此处应该修改成1。
重启Mycat - ③ 验证全局序列
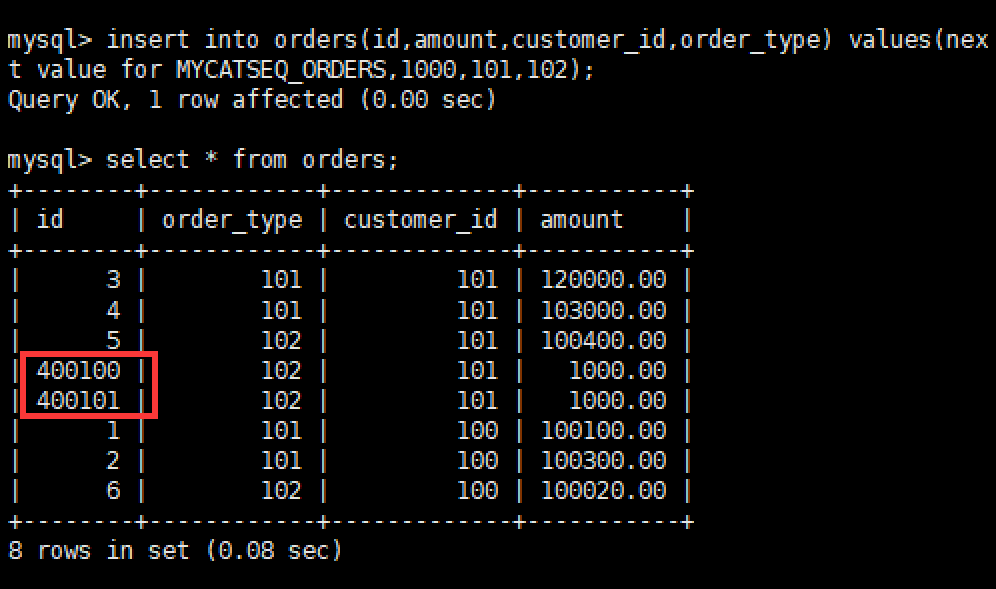
登录 Mycat,插入数据insert into orders(id,amount,customer_id,order_type) values(next value for MYCATSEQ_ORDERS,1000,101,102);
查询数据
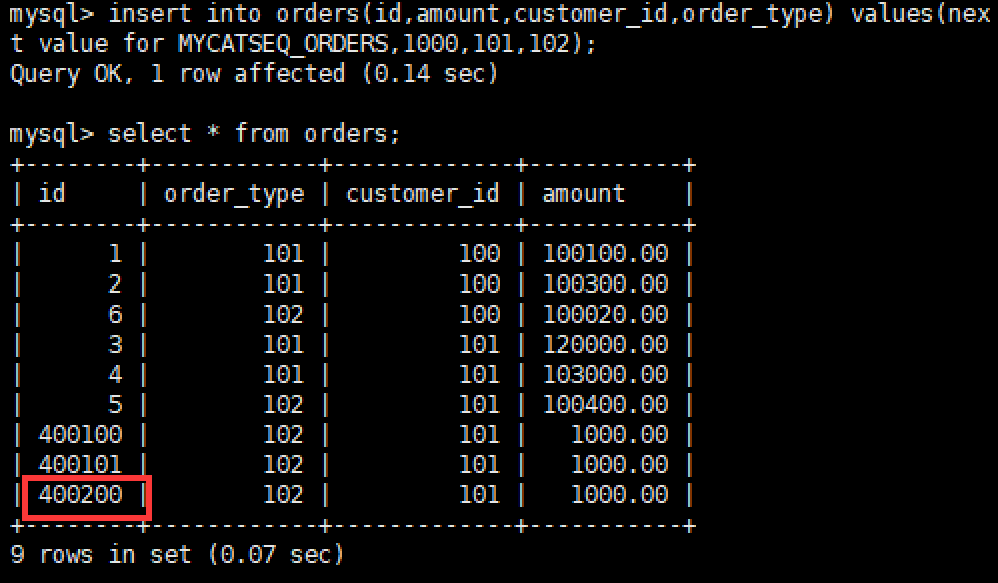
重启Mycat后,再次插入数据,再查询
3 、 时间戳方式
全局序列ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加) 换算成十进制为 18 位数的
long 类型,每毫秒可以并发 12 位二进制的累加。
① 优点:配置简单
② 缺点:18 位 ID 过长
4 、 自主生成 全局 序列
可在 java 项目里自己生成全局序列,如下:
① 根据业务逻辑组合
② 可以利用 redis 的单线程原子性 incr 来生成序列
但,自主生成需要单独在工程中用 java 代码实现,还是推荐使用 Mycat 自带全局序列。