https://zhuanlan.zhihu.com/p/54296517
0 前言
去年11月在PyCon China 2018 杭州站分享了 Python 源码加密,讲述了如何通过修改 Python 解释器达到加解密 Python 代码的目的。然而因为笔者拖延症发作,一直没有及时整理成文字版,现在终于战胜了它,才有了本文。
本系列将首先介绍下现有源码加密方案的思路、方法、优点与不足,进而介绍如何通过定制 Python 解释器来达到更好地加解密源码的目的。
由于 Python 的动态特性和开源特点,导致 Python 代码很难做到很好的加密。社区中的一些声音认为这样的限制是事实,应该通过法律手段而不是加密源码达到商业保护的目的;而还有一些声音则是不论如何都希望能有一种手段来加密。于是乎,人们想出了各种或加密、或混淆的方案,借此来达到保护源码的目的。
常见的源码保护手段有如下几种:
- 发行
.pyc文件 - 代码混淆
- 使用
py2exe - 使用
Cython
下面来简单说说这些方案。
1 发行 .pyc 文件
1.1 思路
大家都知道,Python 解释器在执行代码的过程中会首先生成 .pyc 文件,然后解释执行 .pyc文件中的内容。当然了,Python 解释器也能够直接执行 .pyc 文件。而 .pyc 文件是二进制文件,无法直接看出源码内容。如果发行代码到客户环境时都是 .pyc 而非 .py 文件的话,那岂不是能达到保护 Python 代码的目的?
1.2 方法
把 .py 文件编译为 .pyc 文件,是件非常轻松地事情,可不需要把所有代码跑一遍,然后去捞生成的 .pyc 文件。
事实上,Python 标准库中提供了一个名为 compileall 的库,可以轻松地进行编译。
执行如下命令能够将遍历 <src> 目录下的所有 .py 文件,将之编译为 .pyc 文件:
python -m compileall <src> 然后删除 <src> 目录下所有 .py 文件就可以打包发布了:
$ find <src> -name '*.py' -type f -print -exec rm {} ;1.3 优点
- 简单方便,提高了一点源码破解门槛
- 平台兼容性好,
.py能在哪里运行,.pyc就能在哪里运行
1.4 不足
- 解释器兼容性差,
.pyc只能在特定版本的解释器上运行 - 有现成的反编译工具,破解成本低
python-uncompyle6 就是这样一款反编译工具,效果出众。
执行如下命令,即可将 .pyc 文件反编译为 .py 文件:
$ uncompyle6 *compiled-python-file-pyc-or-pyo*2 代码混淆
如果代码被混淆到一定程度,连作者看着都费劲的话,是不是也能达到保护源码的目的呢?
2.1 思路
既然我们的目的是混淆,就是通过一系列的转换,让代码逐渐不让人那么容易明白,那就可以这样下手: - 移除注释和文档。没有这些说明,在一些关键逻辑上就没那么容易明白了。 - 改变缩进。完美的缩进看着才舒服,如果缩进忽长忽短,看着也一定闹心。 - 在tokens中间加入一定空格。这就和改变缩进的效果差不多。 - 重命名函数、类、变量。命名直接影响了可读性,乱七八糟的名字可是阅读理解的一大障碍。 - 在空白行插入无效代码。这就是障眼法,用无关代码来打乱阅读节奏。
2.2 方法
方法一:使用 oxyry 进行混淆
http://pyob.oxyry.com/ 是一个在线混淆 Python 代码的网站,使用它可以方便地进行混淆。
假定我们有这样一段 Python 代码,涉及到了类、函数、参数等内容:
# coding: utf-8
class A(object):
"""
Description
"""
def __init__(self, x, y, default=None):
self.z = x + y
self.default = default
def name(self):
return 'No Name'
def always():
return True
num = 1
a = A(num, 999, 100)
a.name()
always()经过 Oxyry 的混淆,得到如下代码:
class A (object ):#line:4
""#line:7
def __init__ (O0O0O0OO00OO000O0 ,OO0O0OOOO0000O0OO ,OO0OO00O00OO00OOO ,OO000OOO0O000OOO0 =None ):#line:9
O0O0O0OO00OO000O0 .z =OO0O0OOOO0000O0OO +OO0OO00O00OO00OOO #line:10
O0O0O0OO00OO000O0 .default =OO000OOO0O000OOO0 #line:11
def name (O000O0O0O00O0O0OO ):#line:13
return 'No Name'#line:14
def always ():#line:17
return True #line:18
num =1 #line:21
a =A (num ,999 ,100 )#line:22
a .name ()#line:23
always ()混淆后的代码主要在注释、参数名称和空格上做了些调整,稍微带来了点阅读上的障碍。
方法二:使用 pyobfuscate 库进行混淆
pyobfuscate 算是一个颇具年头的 Python 代码混淆库了,但却是“老当益壮”了。
对上述同样一段 Python 代码,经 pyobfuscate 混淆后效果如下:
# coding: utf-8
if 64 - 64: i11iIiiIii
if 65 - 65: O0 / iIii1I11I1II1 % OoooooooOO - i1IIi
class o0OO00 ( object ) :
if 78 - 78: i11i . oOooOoO0Oo0O
if 10 - 10: IIiI1I11i11
if 54 - 54: i11iIi1 - oOo0O0Ooo
if 2 - 2: o0 * i1 * ii1IiI1i % OOooOOo / I11i / Ii1I
def __init__ ( self , x , y , default = None ) :
self . z = x + y
self . default = default
if 48 - 48: iII111i % IiII + I1Ii111 / ooOoO0o * Ii1I
def name ( self ) :
return 'No Name'
if 46 - 46: ooOoO0o * I11i - OoooooooOO
if 30 - 30: o0 - O0 % o0 - OoooooooOO * O0 * OoooooooOO
def Oo0o ( ) :
return True
if 60 - 60: i1 + I1Ii111 - I11i / i1IIi
if 40 - 40: oOooOoO0Oo0O / O0 % ooOoO0o + O0 * i1IIi
I1Ii11I1Ii1i = 1
Ooo = o0OO00 ( I1Ii11I1Ii1i , 999 , 100 )
Ooo . name ( )
Oo0o ( ) # dd678faae9ac167bc83abf78e5cb2f3f0688d3a3相比于方法一,方法二的效果看起来更好些。除了类和函数进行了重命名、加入了一些空格,最明显的是插入了若干段无关的代码,变得更加难读了。
2.3 优点
- 简单方便,提高了一点源码破解门槛
- 兼容性好,只要源码逻辑能做到兼容,混淆代码亦能
2.4 不足
- 只能对单个文件混淆,无法做到多个互相有联系的源码文件的联动混淆
- 代码结构未发生变化,也能获取字节码,破解难度不大
3 使用 py2exe
3.1 思路
py2exe 是一款将 Python 脚本转换为 Windows 平台上的可执行文件的工具。其原理是将源码编译为 .pyc 文件,加之必要的依赖文件,一起打包成一个可执行文件。
如果最终发行由 py2exe 打包出的二进制文件,那岂不是达到了保护源码的目的?
3.2 方法
使用 py2exe 进行打包的步骤较为简便。
1)编写入口文件。本示例中取名为 hello.py:
print 'Hello World'2)编写 setup.py:
from distutils.core import setup
import py2exe
setup(console=['hello.py'])3)生成可执行文件
python setup.py py2exe生成的可执行文件位于 disthello.exe。
3.3 优点
- 能够直接打包成 exe,方便分发和执行
- 破解门槛比 .pyc 更高一些
3.4 不足
- 兼容性差,只能运行在 Windows 系统上
- 生成的可执行文件内的布局是明确、公开的,可以找到源码对应的
.pyc文件,进而反编译出源码
4 使用 Cython
4.1 思路
虽说 Cython 的主要目的是带来性能的提升,但是基于它的原理:将 .py/.pyx 编译为 .c 文件,再将 .c 文件编译为 .so(Unix) 或 .pyd(Windows),其带来的另一个好处就是难以破解。
4.2 方法
使用 Cython 进行开发的步骤也不复杂。
1)编写文件 hello.pyx 或 hello.py:
def hello():
print('hello')2)编写 setup.py:
from distutils.core import setup
from Cython.Build import cythonize
setup(name='Hello World app',
ext_modules=cythonize('hello.pyx'))3)编译为 .c,再进一步编译为 .so 或 .pyd:
python setup.py build_ext --inplace执行 python -c "from hello import hello;hello()" 即可直接引用生成的二进制文件中的 hello() 函数。
4.3 优点
- 生成的二进制 .so 或 .pyd 文件难以破解
- 同时带来了性能提升
4.4 不足
- 兼容性稍差,对于不同版本的操作系统,可能需要重新编译
- 虽然支持大多数 Python 代码,但如果一旦发现部分代码不支持,完善成本较高
下文我们将重点介绍一种新的保护源码的方法。
相关文章:如何保护你的 Python 代码 (二)—— 定制 Python 解释器
0 前言
考虑前文所述的几个方案,均是从源码的加工入手,或多或少都有些不足。假设我们从解释器的改造入手,会不会能够更好的保护代码呢?
由于发行商业 Python 程序到客户环境时通常会包含一个 Python 解释器,如果改造解释器能解决源码保护的问题,那么也是可选的一条路。
假定我们有一个算法,能够加密原始的 Python 代码,这些加密后代码随发行程序一起,可被任何人看到,却难以破解。另一方面,有一个定制好的 Python 解释器,它能够解密这些被加密的代码,然后解释执行。而由于 Python 解释器本身是二进制文件,人们也就无法从解释器中获取解密的关键数据。从而达到了保护源码的目的。
要实现上述的设想,我们首先需要掌握基本的加解密算法,其次探究 Python 执行代码的方式从而了解在何处进行加解密,最后禁用字节码用以防止通过 .pyc 反编译。
1 加解密算法
1.1 对称密钥加密算法
对称密钥加密(Symmetric-key algorithm)又称为对称加密、私钥加密、共享密钥加密,是密码学中的一类加密算法。这类算法在加密和解密时使用相同的密钥,或是使用两个可以简单地相互推算的密钥。
对称加密算法的特点是算法公开、计算量小、加密速度快、加密效率高。
常见的对称加密算法有:DES、3DES、AES、Blowfish、IDEA、RC5、RC6 等。
对称密钥加解密过程如下:

明文通过密钥加密成密文,密文也可通过相同的密钥解密为明文。
通过 openssl 工具,我们能够方便选择对称加密算法进行加解密。下面我们以 AES 算法为例,介绍其用法。
AES 加密
# 指定密码进行对称加密
$ openssl enc -aes-128-cbc -in test.py -out entest.py -pass pass:123456
# 指定文件进行对称加密
$ openssl enc -aes-128-cbc -in test.py -out entest.py -pass file:passwd.txt
# 指定环境变量进行对称加密
$ openssl enc -aes-128-cbc -in test.py -out entest.py -pass env:passwdAES 解密
# 指定密码进行对称解密
$ openssl enc -aes-128-cbc -d -in entest.py -out test.py -pass pass:123456
# 指定文件进行对称解密
$ openssl enc -aes-128-cbc -d -in entest.py -out test.py -pass file:passwd.txt
# 指定环境变量进行对称解密
$ openssl enc -aes-128-cbc -d -in entest.py -out test.py -pass env:passwd1.2 非对称密钥加密算法
密钥加密(英语:public-key cryptography,又译为公开密钥加密),也称为非对称加密(asymmetric cryptography),一种密码学算法类型,在这种密码学方法中,需要一对密钥,一个是私钥,另一个则是公钥。这两个密钥是数学相关,用某用户公钥加密后所得的信息,只能用该用户的私钥才能解密。
非对称加密算法的特点是算法强度复杂、安全性依赖于算法与密钥但是由于其算法复杂,而使得加密解密速度没有对称加密解密的速度快。
常见的对称加密算法有:RSA、Elgamal、背包算法、Rabin、D-H、ECC 等。
非对称密钥加解密过程如下:
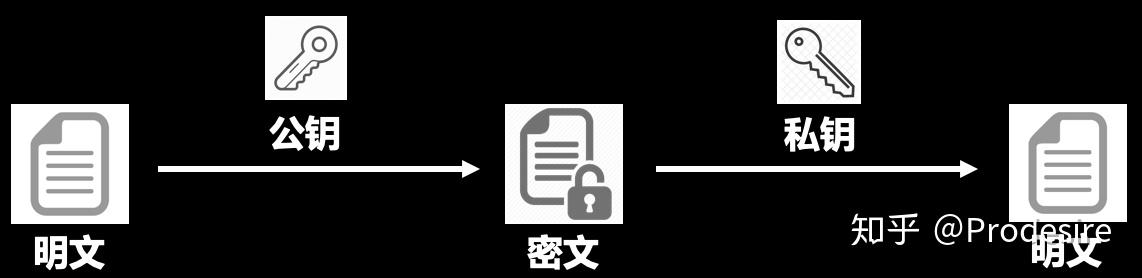
明文通过公钥加密成密文,密文通过与公钥对应的私钥解密为明文。
通过 openssl 工具,我们能够方便选择非对称加密算法进行加解密。下面我们以 RSA 算法为例,介绍其用法。
生成私钥、公钥
# 辅以 AES-128 算法,生成 2048 比特长度的私钥
$ openssl genrsa -aes128 -out private.pem 2048
# 根据私钥来生成公钥
$ openssl rsa -in private.pem -outform PEM -pubout -out public.pemRSA 加密
# 使用公钥进行加密
openssl rsautl -encrypt -in passwd.txt -inkey public.pem -pubin -out enpasswd.txtRSA 解密
# 使用私钥进行解密
openssl rsautl -decrypt -in enpasswd.txt -inkey private.pem -out passwd.txt2 基于加密算法实现源码保护
对称加密适合加密源码文件,而非对称加密适合加密密钥。如果将两者结合,就能达到加解密源码的目的。
2.1 在构建环境进行加密
我们发行出去安装包中,源码应该是被加密过的,那么就需要在构建阶段对源码进行加密。加密的过程如下:
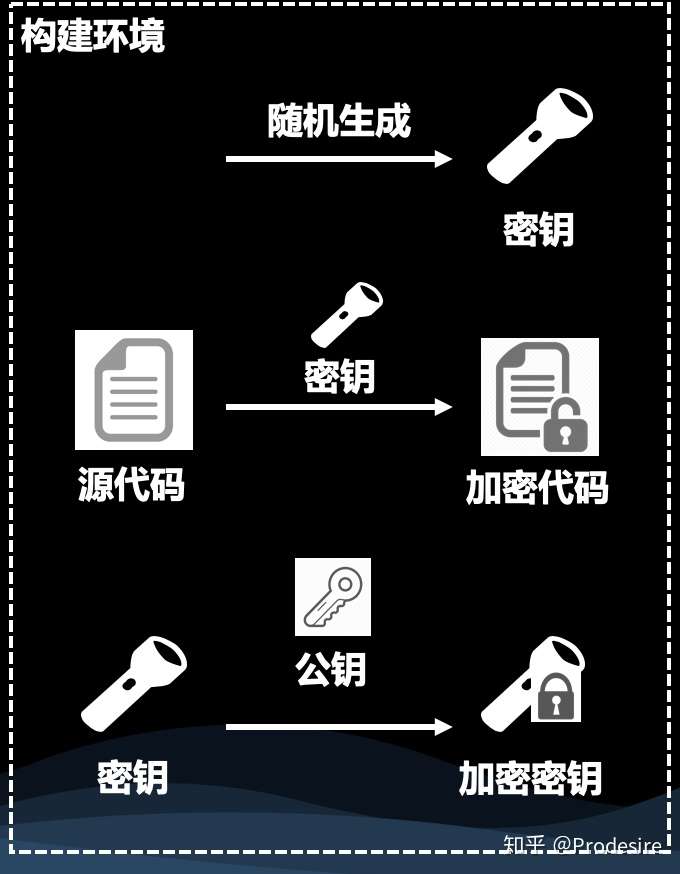
- 随机生成一个密钥。这个密钥实际上是一个用于对称加密的密码。
- 使用该密钥对源代码进行对称加密,生成加密后的代码。
- 使用公钥(生成方法见 非对称密钥加密算法)对该密钥进行非对称加密,生成加密后的密钥。
不论是加密后的代码还是加密后的密钥,都会放在安装包中。它们能够被用户看到,却无法被破译。而 Python 解释器该如何执行加密后的代码呢?
2.2 Python 解释器进行解密
假定我们发行的 Python 解释器中内置了与公钥相对应的私钥,有了它就有了解密的可能。而由于 Python 解释器本身是二进制文件,所以不需要担心内置的私钥会被看到。解密的过程如下:
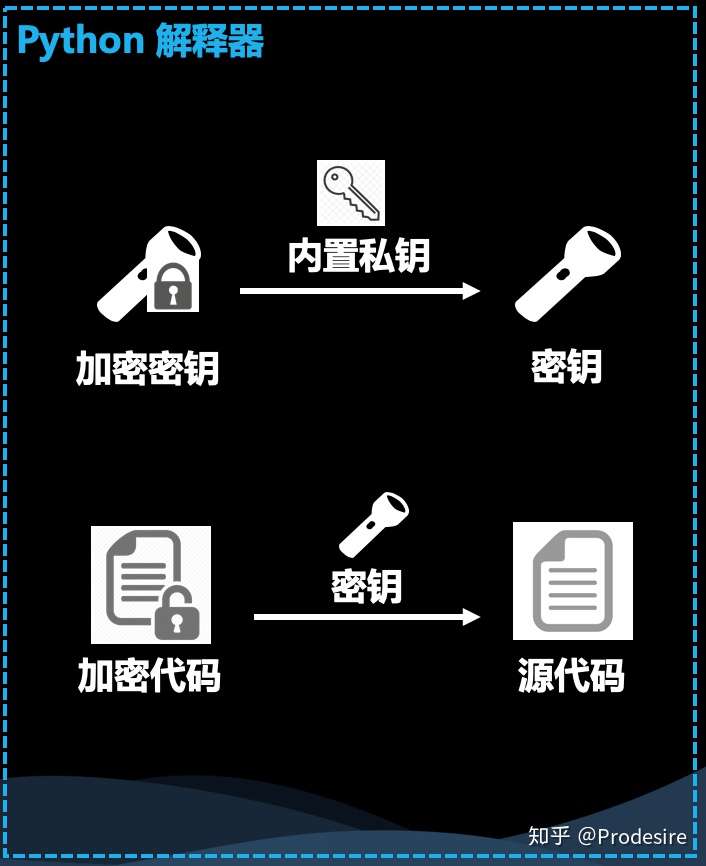
- Python 解释器执行加密代码时需要被传入指示加密密钥的参数,通过这个参数,解释器获取到了加密密钥
- Python 解释器使用内置的私钥,对该加密密钥进行非对称解密,得到原始密钥
- Python 解释器使用原始密钥对加密代码进行对称解密,得到原始代码
- Python 解释器执行这段原始代码
可以看到,通过改造构建环节、定制 Python 解释器的执行过程,便可以实现保护源码的目的。改造构建环节是容易的,但是如何定制 Python 解释器呢?我们需要深入了解解释器执行脚本和模块的方式,才能在特定的入口进行控制。
3 脚本、模块的执行与解密
3.1 执行 Python 代码的几种方式
为了找到 Python 解释器执行 Python 代码时的所有入口,我们需要首先执行 Python 解释器都能以怎样的方式执行代码。
直接运行脚本
python test.py直接运行语句
python -c "print 'hello'"直接运行模块
python -m test导入、重载模块
python
>>> import test # 导入模块
>>> reload(test) # 重载模块直接运行语句 的方式接收的就是明文的代码,我们也无需对这种方式做额外处理。 直接运行模块和导入、重载模块这两种方式在流程上是殊途同归的,所以接下来会一起来看。 因此我们将分两种情况:运行脚本和加载模块来进一步探究各自的过程和解密方式。
3.2 运行脚本时解密
运行脚本的过程 Python 解释器在运行脚本时的代码调用逻辑如下:
main WinMain
[Modules/python.c] [PC/WinMain.c]
/
/
/
/
/
Py_Main
[Moduls/main.c]Python 解释器运行脚本的入口函数因操作系统而异,在 Linux/Unix 系统上,主入口函数是 Modules/python.c 中的 main 函数,在 Windows系统上,则是 PC/WinMain.c 中的 WinMain 函数。不过这两个函数最终都会调用 Moduls/main.c 中的 Py_Main 函数。
我们不妨来看看 Py_Main 函数中的相关逻辑:
[Modules/Main.c]
--------------------------------------
int
Py_Main(int argc, char **argv)
{
if (command) {
// 处理 python -c <command>
} else if (module) {
// 处理 python -m <module>
}
else {
// 处理 python <file>
...
fp = fopen(filename, "r");
...
}
}处理<command>和<module>的部分我们暂且先不管,在处理文件(通过直接运行脚本的方式)的逻辑中,可以看到解释打开了文件,获得了文件指针。那么如果我们把这里的 fopen 换成是自定义的 decrypt_open 函数,这个函数用来打开一个加密文件,然后进行解密,并返回一个文件指针,这个指针指向解密后的文件。那么,不就可以实现解密脚本的目的了吗?
自定义 decrypt_open 我们不妨新增一个 Modules/crypt.c 文件,用来存放一些自定义的加解密函数。
decrypt_open 函数大概实现如下:
[Modules/crypt.c]
--------------------------------------
/* 以解密方式打开文件 */
FILE *
decrypt_open(const char *filename, const char *mode)
{
int plainlen = -1;
char *plaintext = NULL;
FILE *fp = NULL;
if (aes_passwd == NULL)
fp = fopen(filename, "r");
else {
plainlen = aes_decrypt(filename, aes_passwd, &plaintext);
// 如果无法解密,返回源文件描述符
if (plainlen < 0)
fp = fopen(filename, "r");
// 否则,转换为内存文件描述符
else
fp = fmemopen(plaintext, plainlen, "r");
}
return fp;
}这里的 aes_passwd 是一个全局变量,代表对称加密算法中的密钥。我们暂时假定已经获取该密钥了,后文会说明如何获得。而 aes_decrypt 是自定义的一个使用AES算法进行对称解密的函数,限于篇幅,此函数的实现不再贴出。
decrypt_open 逻辑如下: - 判断是否获得了对称密钥,如果没获得,直接打开该文件并返回文件指针 - 如果获得了,则尝试使用对称算法进行解密 - 如果解密失败,可能就是一段非加密的脚本,直接打开该文件并返回文件指针 - 如果解密成功,我们通过解密后的内容创建一个内存文件对象,并返回该文件指针
实现了上述这些函数后,我们就能够实现在直接运行脚本时,解密执行被加密代码的目的。
3.3 加载模块时解密
加载模块的过程 加载模块的逻辑主要实现在 Python/import.c 文件中,其过程如下:
Py_Main
[Moduls/main.c]
|
builtin___import__ RunModule
| |
PyImport_ImportModuleLevel <----┐ PyImport_ImportModule
| | |
import_module_level └------- PyImport_Import
|
load_next builtin_reload
| |
import_submodule PyImport_ReloadModule
| |
find_module <---------------------------┘- 通过
python -m <module>的方式来加载模块时,其入口函数是Py_Main函数 - 通过
import <module>的方式来加载模块时,其入口函数是builtin___import__函数 - 通过
reload(<module>)的方式来加载模块时,其入口函数是builtin_reload函数
但不论是哪种方式,最终都会调用 find_module 函数,我们看看这个函数中是否暗藏乾坤呢?
[Python/import.c]
--------------------------------------
static struct filedescr *
find_module(char *fullname, char *subname, PyObject *path, char *buf,
size_t buflen, FILE **p_fp, PyObject **p_loader)
{
...
fp = fopen(buf, filemode);
...
}我们在 find_module 函数中找到了打开文件的逻辑,如果直接改成前文实现的 decrypt_open,岂不是就能达成加载模块时解密的目的了?
总体思路是这样的,但有个细节需要注意,buf 不一定就是 .py 文件,也可能是 .pyc 文件,我们只对 .py 文件做改动,则可以这么写:
[Python/import.c]
--------------------------------------
static struct filedescr *
find_module(char *fullname, char *subname, PyObject *path, char *buf,
size_t buflen, FILE **p_fp, PyObject **p_loader)
{
...
if (fdp->type == PY_SOURCE) {
fp = decrypt_open(buf, filemode);
}
else {
fp = fopen(buf, filemode);
}
...
}经过上述改动,就实现了加载模块时解密的目的了。
3.4 支持指定密钥文件
前文中还留有一个待解决的问题:我们一开始是假定解释器已获取到了密钥内容并存放在了全局变量 aes_passwd 中,那么密钥内容怎么获取呢?
我们需要 Python 解释器能支持一个新的参数选项,通过它来指定已加密的密钥文件,然后再通过非对称算法进行解密,得到 aes_passed。 假定这个参数选项是 -k <filename>,则可使用如 python -k enpasswd.txt 的方式来告知解释器加密密钥的文件路径。其实现如下:
[Modules/main.c]
--------------------------------------
/* 命令行选项,注意k:是新增的内容 */
#define BASE_OPTS "3bBc:dEhiJk:m:OQ:RsStuUvVW:xX?"
...
/* Long usage message, split into parts < 512 bytes */
static char *usage_1 = "
...
-k key : decrypt source file by using key file
...
";
...
int
Py_Main(int argc, char **argv)
{
...
char *keyfilename = NULL;
...
while ((c = _PyOS_GetOpt(argc, argv, PROGRAM_OPTS)) != EOF) {
...
case 'k':
keyfilename = (char *)malloc(strlen(_PyOS_optarg) + 1);
if (keyfilename == NULL)
Py_FatalError(
"not enough memory to copy -k argument");
strcpy(keyfilename, _PyOS_optarg);
keyfilename[strlen(_PyOS_optarg)] = '�';
break;
...
}
...
if (keyfilename != NULL) {
int passwdlen;
char *passwd = NULL;
passwdlen = rsa_decrypt(keyfilename, &passwd);
set_aes_passwd(passwd);
if (passwdlen < 0) {
fprintf(stderr, "%s: parsing key file '%s' error
", argv[0], keyfilename);
free(keyfilename);
return 2;
} else {
free(keyfilename);
}
}
...
}其逻辑如下: - k:中的 k 表示支持 -k 选项;: 表示选项后跟一个参数,即这里的已加密密钥文件的路径 - 解释器在处理到 -k 参数时,获取其后所跟的文件路径,记录在 keyfilename中 - 使用自定义的 rsa_decrypt 函数(限于篇幅,不列出如何实现的逻辑)对已加密密钥文件进行非对称解密,获得密钥的原始内容 - 将该密钥内容写入到 aes_passwd 中
由此,通过显示地指定已加密密钥文件,解释器获得了原始密钥,进而通过该密钥解密已加密代码,再执行原始代码。但是,这里面还潜藏着一个风险:执行代码的过程中会生成 .pyc 文件,通过它反编译出的 .py 文件是未加密的。换句话说,恶意用户可以通过这种手段绕过限制。所以,我们需要 禁用字节码。
4 禁用字节码
4.1 不生成 .pyc 文件
首先要做的就是不生成 .pyc 文件,这样,恶意用户就没法直接根据 .pyc 文件来得到源码。
我们知道,通过 -B 选项可以告知 Python 解释器不生成 .pyc 文件。既然定制的 Python 解释器就不生成 .pyc 我们干脆禁用这个选项:
[Modules/main.c]
--------------------------------------
/* 命令行选项,注意移除了B */
#define BASE_OPTS "3bc:dEhiJm:OQ:RsStuUvVW:xX?"
...
/* Long usage message, split into parts < 512 bytes */
static char *usage_1 = "
...
//-B : don't write .py[co] files on import; also PYTHONDONTWRITEBYTECODE=x
...
";
...
int
Py_Main(int argc, char **argv)
{
...
// 不生成 py[co]
Py_DontWriteBytecodeFlag++;
...
}除此以外,Python 解释器还会从环境变量中获取是否不生成 .pyc 文件,因此也需要做处理:
[Python/pythonrun.c]
--------------------------------------
void
Py_InitializeEx(int install_sigs)
{
...
f ((p = Py_GETENV("PYTHONDEBUG")) && *p != '�')
Py_DebugFlag = add_flag(Py_DebugFlag, p);
if ((p = Py_GETENV("PYTHONVERBOSE")) && *p != '�')
Py_VerboseFlag = add_flag(Py_VerboseFlag, p);
if ((p = Py_GETENV("PYTHONOPTIMIZE")) && *p != '�')
Py_OptimizeFlag = add_flag(Py_OptimizeFlag, p);
// 移除对 PYTHONDONTWRITEBYTECODE 的处理
if ((p = Py_GETENV("PYTHONDONTWRITEBYTECODE")) && *p != '�')
Py_DontWriteBytecodeFlag = add_flag(Py_DontWriteBytecodeFlag, p);
...
}4.2 禁止访问字节码对象 co_code
仅仅是不生成 .pyc 文件还是不够的,恶意用户已然可以访问对象的 co_code 属性来获取字节码,进而通过反编译的手段获取到源码。因此,我们也需要禁止用户访问字节码对象:
[Objects/codeobject.c]
--------------------------------------
static PyMemberDef code_memberlist[] = {
{"co_argcount", T_INT, OFF(co_argcount), READONLY},
{"co_nlocals", T_INT, OFF(co_nlocals), READONLY},
{"co_stacksize",T_INT, OFF(co_stacksize), READONLY},
{"co_flags", T_INT, OFF(co_flags), READONLY},
// {"co_code", T_OBJECT, OFF(co_code), READONLY},
{"co_consts", T_OBJECT, OFF(co_consts), READONLY},
{"co_names", T_OBJECT, OFF(co_names), READONLY},
{"co_varnames", T_OBJECT, OFF(co_varnames), READONLY},
{"co_freevars", T_OBJECT, OFF(co_freevars), READONLY},
{"co_cellvars", T_OBJECT, OFF(co_cellvars), READONLY},
{"co_filename", T_OBJECT, OFF(co_filename), READONLY},
{"co_name", T_OBJECT, OFF(co_name), READONLY},
{"co_firstlineno", T_INT, OFF(co_firstlineno), READONLY},
{"co_lnotab", T_OBJECT, OFF(co_lnotab), READONLY},
{NULL} /* Sentinel */
};到此,一个定制的 Python 解释器完成了。
5 演示
5.1 运行脚本
通过 -k 选项执行已加密密钥文件,Python 解释器可以运行已加密和未加密的 Python 文件。
5.2 加载模块
可以通过 -m <module> 的方式加载已加密和未加密的模块,也可以通过 import <module> 的方式来加载已加密和未加密的模块。

5.3 禁用字节码
通过禁用字节码,我们达到以下效果: - 不会生成 .pyc 文件 - 可以访问函数的 func_code - 无法访问代码对象的 co_code,即本示例中的 f.func_code.co_code - 无法使用dis模块来获取字节码

5.4 异常堆栈信息
尽管代码是加密的,但是不会影响异常时的堆栈信息。

5.5 调试
加密的代码也是允许调试的,但是输出的代码内容会是加密的,这正是我们所期望的。

6 思考
- 如何防止通过内存操作的方式找到对象的co_code?
- 如何进一步提升私钥被逆向工程探知的难度?
- 如何能在调试并希望看到源码的时候看到?