最近在网上找到了一个使用LSTM 网络解决 世界银行中各国 GDP预测的一个问题,感觉比较实用,毕竟这是找到的唯一一个可以正确运行的程序。
#encoding:UTF-8 import pandas as pd from pandas_datareader import wb import torch import torch.nn import torch.optim #读取数据 countries = ['BR', 'CA', 'CN', 'FR', 'DE', 'IN', 'IL', 'JP', 'SA', 'GB', 'US',] dat = wb.download(indicator='NY.GDP.PCAP.KD', country=countries, start=1970, end=2016) df = dat.unstack().T df.index = df.index.droplevel(0).astype(int) #print(df)
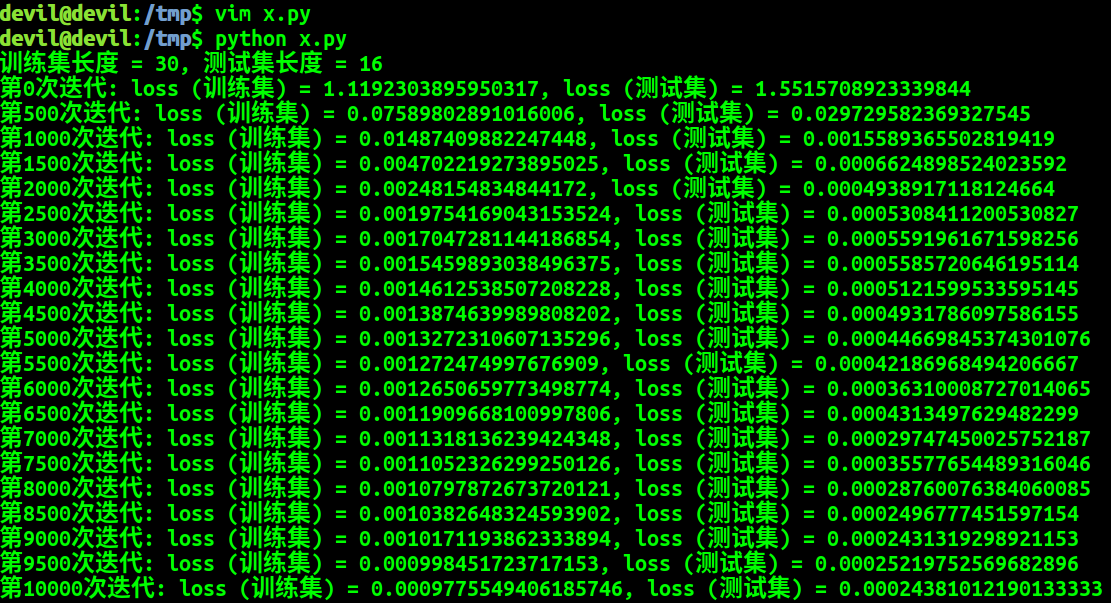
#搭建神经网络 class Net(torch.nn.Module): def __init__(self, input_size, hidden_size): super(Net, self).__init__() self.rnn = torch.nn.LSTM(input_size, hidden_size) self.fc = torch.nn.Linear(hidden_size, 1) def forward( self, x): x = x[:, :, None] x, _ = self.rnn(x) x = self.fc(x) x = x[:, :, 0] return x net = Net(input_size=1, hidden_size=5) #print(net) #训练神经网络 # 数据归一化 df_scaled = df / df.loc[2000] # 确定训练集和测试集 years = df.index train_seq_len = sum((years >= 1971) & (years <= 2000)) test_seq_len = sum(years > 2000) print ('训练集长度 = {}, 测试集长度 = {}'.format( train_seq_len, test_seq_len)) # 确定训练使用的特征和标签 inputs = torch.tensor(df_scaled.iloc[:-1].values, dtype=torch.float32) labels = torch.tensor(df_scaled.iloc[1:].values, dtype=torch.float32) # 训练网络 criterion = torch.nn.MSELoss() optimizer = torch.optim.Adam(net.parameters()) for step in range(10001): if step: optimizer.zero_grad() train_loss.backward() optimizer.step() preds = net(inputs) train_preds = preds[:train_seq_len] train_labels = labels[:train_seq_len] train_loss = criterion(train_preds, train_labels) test_preds = preds[-test_seq_len] test_labels = labels[-test_seq_len] test_loss = criterion(test_preds, test_labels) if step % 500 == 0: print ('第{}次迭代: loss (训练集) = {}, loss (测试集) = {}'.format( step, train_loss, test_loss)) preds = net(inputs) df_pred_scaled = pd.DataFrame(preds.detach().numpy(), index=years[1:], columns=df.columns) df_pred = df_pred_scaled * df.loc[2000] df_pred.loc[2001:]