参考文献:
http://blog.csdn.net/u013527419/article/details/52822622?locationNum=7&fps=1
一. 基础知识:
1. 概念:时间序列是指一个数据序列,特别是由一段时间内采集的信号组成的序列,序列前面的信号表示采集的时间较早。
2. 前提假设:时间序列分析一般假设我们获得的数据在时域上具有一定的相互依赖关系,例如股票价格在t时刻很高,那么在t+1时刻价格也会比较高(跌停才10%);如果股票价格在一段时间内获得稳定的上升,那么在接下来的一段时间内延续上升趋势的概率也会比较大。
3. 目标:(1)发现这种隐含的依赖关系,并增加我们对此类时间序列的理解;(2)对未观测到的或者尚未发生的时间序列进行预测。
我们认为时间序列由两部分组成:有规律的时间序列(即有依赖关系)+噪声(无规律,无依赖)。所以,,接下来要做的就是过滤噪声—最简单的过滤噪声的方法是 取平均。
二.简单滑动平均(rolling mean)
1. 优点:
当窗口取得越长,噪声被去除的就越多,我们得到的信号就越平稳;但同时,信号的有用部分丢失原有特性的可能性就越大,而我们希望发现的规律丢失的可能性就越大。
2. 缺点:
(1)我们要等到至少获得T个信号才能进行平均,那么得到的新的信号要比原始信号短;
(2)在得到S_t的时候,我们只有到了距离t最近的T个原始信号。但在原始信号中,可能信号之间的相互依赖关系会跨越非常长的时间长度,比如X_1可能会对X_100会产生影响,这样滑动平均就会削弱甚至隐藏这种依赖关系。
三.指数平均(EXPMA)
接下来我们介绍一种稍微复杂但能克服以上缺点并且在现实中应用也更加广泛的方法:指数平均 (exponential smoothing,也叫exponential weighted moving average ),这种平均方法的一个重要特征就是,S_t与之前产生的所有信号有关,并且距离越近的信号所占权重越大。
(一)一阶指数平滑
一阶指数平滑实际就是对历史数据的加权平均,它可以用于任何一种 没有 明显函数规律 但确实存在 某种前后关联 的时间序列的 短期预测。
其预测公式为:
yt+1’=ayt+(1-a)yt’ 式中,yt+1’ 为t+1期的预测值,即本期(t期)的平滑值S_t ;
yt 为t期的实际值; yt’–为t期的预测值,即上期的平滑值S_t-1 。
该公式又可以写作:yt+1’=yt’ + a(yt- yt’)。
可见,下期预测值又是 本期预测值 与 以a为折扣 的 本期实际值 与 预测值误差 之和。
1. 它最突出的优点是方法非常简单,甚至只要样本末期的平滑值,就可以得到预测结果。
2. 一次指数平滑的特点是:能够跟踪数据变化。这一特点所有指数都具有。预测过程中添加最新的样本数据后,新数据应取代老数据的地位,老数据会逐渐居于次要的地位,直至被淘汰。这样,预测值总是反映最新的数据结构。
3. 一次指数平滑有局限性。
第一,预测值不能 反映趋势变动、季节波动 等有规律的变动;
第二,这种方法多适用于短期预测,而不适合作中长期的预测;
第三,由于预测值是历史数据的均值,因此 与实际序列的变化相比 有 滞后现象。
平滑系数,指数平滑预测是否理想,很大程度上取决于平滑系数。
EViews提供两种确定指数平滑系数的方法:自动给定和人工确定。
选择自动给定,系统将按照预测误差平方和最小原则自动确定系数。
如果系数接近1,说明该序列 近似纯随机序列,这时 最新的观测值 就是 最理想的预测值。 出于预测的考虑,有时系统给定的系数不是很理想,用户需要自己指定平滑系数值。
一般来说:
如果序列变化比较平缓,平滑系数值 应该 比较小,比如 小于0.l ;
如果序列变化比较剧烈,平滑系数值可以取得大一些,如0.3~0.5。
若平滑系数值 大于0.5 才能跟上序列的变化, 表明序列有很强的趋势, 不能 采用 一次指数平滑进行预测。
(二)二次指数平滑
二次指数平滑是对一次指数平滑的再平滑。它适用于 具有 线性趋势 的时间数列。
(一次指数平滑没有考虑历史数据变化趋势 对当前预测值的影响, 因此无法预测趋势 )
我们可以看到,虽然一次指数平均在产生新的数列的时候考虑了所有的历史数据,但是 仅仅考虑其静态值,即 没有考虑 时间序列 当前的变化趋势。
如果当前的股票处于上升趋势,那么当我们对明天的股票进行预测的时候,好的预测值不仅仅是对历史数据进行”平均“,而且要考虑到当前数据变化的上升趋势。同时考虑历史平均和变化趋势,这便是二阶指数平均:
(三)三次指数平滑预测
1. 与前两种相比,我们多考虑一个因素:季节性效应( Seasonality)
这种平均模型考虑的季节性效应 在股票或者期货价格中都会比较常见,
比如 在过年前A股市场通常会交易比较频繁,在小麦成熟的时候 小麦期货价格 也会有比较明显的波动。
但是,模型本身的复杂度也增加了其使用难度,我们需要一定的经验才能比较合理地设置其中复杂的参数。
2. 三次指数平滑预测是二次平滑基础上的再平滑。
它们的基本思想都是:预测值是以前观测值的加权和,且对不同的数据给予不同的权,新数据给较大的权,旧数据给较小的权。
===================================================================
参考文献:
http://blog.csdn.net/wangrunjie1986/article/details/23842259?locationNum=13&fps=1
算法可以很好的进行时间序列的预测。
时间序列数据一般有以下几种特点:1.趋势(Trend) 2. 季节性(Seasonality)。
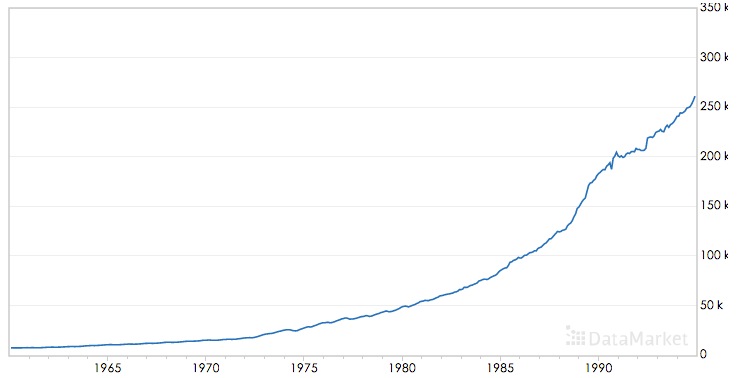
趋势描述的是时间序列的整体走势,比如总体上升或者总体下降。下图所示的时间序列是总体上升的:
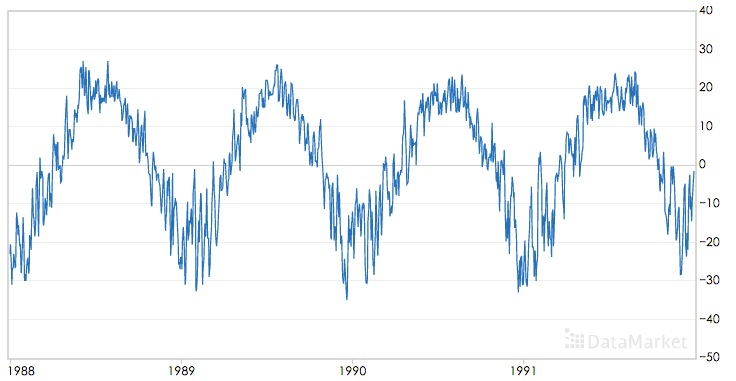
季节性描述的是数据的周期性波动,比如以年或者周为周期,如下图:
三次指数平滑算法可以对同时含有趋势和季节性的时间序列进行预测,该算法是基于一次指数平滑和二次指数平滑算法的。
一次指数平滑算法基于以下的递推关系:
si=αxi+(1-α)si-1
其中α是平滑参数,si是之前i个数据的平滑值,取值为[0,1],α越接近1,平滑后的值越接近当前时间的数据值,数据越不平滑,α越接近0,平滑后的值越接近前i个数据的平滑值,数据越平滑,α的值通常可以多尝试几次以达到最佳效果。
一次指数平滑算法进行预测的公式为:xi+h=si,其中i为当前最后的一个数据记录的坐标,亦即预测的时间序列 为 一条直线,不能反映 时间序列 的趋势和季节性。
二次指数平滑保留了趋势的信息,使得预测的时间序列可以包含之前数据的趋势。
二次指数平滑通过添加一个新的 变量t 来表示 平滑后的趋势:
si=αxi+(1-α)(si-1+ti-1)
ti=ß(si-si-1)+(1-ß)ti-1
二次指数平滑的预测公式为 xi+h=si +h ti 二次指数平滑的预测结果是 一条斜的直线。
三次指数平滑有累加和累乘两种方法, 下面是累加的三次指数平滑
si=α(xi-pi-k)+(1-α)(si-1+ti-1)
ti=ß(si-si-1)+(1-ß)ti-1
pi=γ(xi-si)+(1-γ)pi-k
其中k为周期
累加三次指数平滑的预测公式为: xi+h=si+hti+pi-k+(h mod k) 注意:数据之魅P88此处有错误,根据Wikipedia修正。
下式为累乘的三次指数平滑:
si=αxi/pi-k+(1-α)(si-1+ti-1)
ti=ß(si-si-1)+(1-ß)ti-1
pi=γxi/si+(1-γ)pi-k
其中k为周期
累乘三次指数平滑的预测公式为: xi+h=(si+hti)pi-k+(h mod k) 注意:数据之魅P88此处有错误,根据Wikipedia修正。
α,ß,γ的值都位于[0,1]之间,可以多试验几次以达到最佳效果。
s,t,p初始值的选取对于算法整体的影响不是特别大,通常的取值为 s0=x0, t0=x1-x0, 累加时 p=0, 累乘时 p=1.
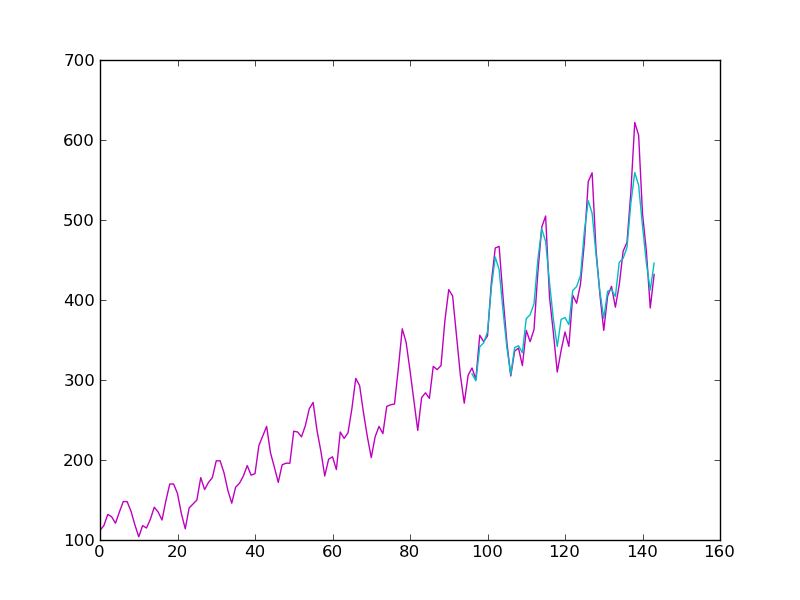
测试累加和累乘三次指数平滑算法的性能,该数据记录的是每月的国际航线乘客数:
下图为使用累加三次指数平滑进行预测的效果:其中红色为源时间序列,蓝色为预测的时间序列,α,ß,γ的取值为0.45,0.2,0.95:
下图为累乘三次指数平滑进行预测的效果,α,ß,γ的取值为0.4,0.05,0.9:

[1]. 数据之魅:基于开源工具的数据分析