接前文:
再探 游戏 《 2048 》 —— AI方法—— 缘起、缘灭(2) —— 游戏环境设计篇 - Hello_BeautifulWorld - 博客园 (cnblogs.com)
=========================================
在前文中主要是大致介绍了 https://gitee.com/devilmaycry812839668/highest_vote_2048_ai 中游戏环境部分的内容,其实游戏环境的实现只介绍了很小一部分,原本打算多说一些,不过后来发现意义价值不大,对于有兴趣研究这个游戏的实现逻辑的人知道这个游戏是用64bit的整数来表示一个游戏状态中16个数字并且每个数字是用半字节4bit来进行表示的就已经足够了,其他剩下的就是如何对这个64bit的整数进行移位操作了,如:transpose函数就是把这个64bit的整数按照游戏状态装置的方式变化为另一个游戏状态的64bit整数,move_0, move_1, move_2, move_3, 则是表示对这个64bit的整数进行上下左右移动操作后变化得到的新状态所表示的64bit整数;而对于那些对这个游戏实现逻辑没有兴趣的人来说自然是没有必要多说这个environment的实现细节了;对于我来说这个游戏实现细节确实不好理解但是要完整的说清楚又显得十分的琐碎和费事,于是也就作罢了。
其实这个系列主要的重点不是说这个游戏的实现,而是如何用AI方式来解决这个游戏。
现在很多人一听说AI就知道深度学习,Deep Learning,机器学习之类的,但是AI这个概念其实是一个比较宽泛的,所包容的内容也是很多的,在某种程度上说方式可以仿造人类去实现某个操作,或是具有人类某项功能的部分能力的方法都可以叫做AI方法,而现在的机器学习方法是AI方法中最为流行的方法,对于当前的CV,NLP等领域有很好的解决能力的一种方法,但这绝不是唯一,在这个《2048》游戏中所使用的方法就是AI方法中的启发式方法,启发式方法这个名字也是十分的唬人,其实启发式算法就是按照一定的规则条件来进行运算的算法,大致形式就是:
IF CONDITION:
DO SOMETHING;
ELSE:
DO ANOTHER SOMETHING;
ENDIF;
个人一般把启发式算法看做是根据预定规则(条件)设计好的算法。
启发式算法是听起来很高大上,实际一看又感觉很平民,那么他实际上的原理在哪呢?因为我们希望利用计算机程序来模仿实现人类的某项能力,说到底就是设计一个具备人类某项能力的算法代码,其中最为直接的方法就是把人类处理某个问题所采用的方法(策略)用条件规则写出来,那么我们编写计算机算法时只要按照这个预设的条件规则来进行设计就可以了。
启发式算法:
人类策略 ===》 计算机可识别的条件规则
那么在这个《2048》游戏中这个启发算法时如何设计的呢?
具体的实现代码:
cpp_source/2048_algorithm.cpp · 鬼&泣/2048-ai - 码云 - 开源中国 (gitee.com)
实现的启发式算法核心代码:
static float heur_score_table[65536];
// Heuristic scoring settings
static const float SCORE_LOST_PENALTY = 200000.0f;
static const float SCORE_MONOTONICITY_POWER = 4.0f;
static const float SCORE_MONOTONICITY_WEIGHT = 47.0f;
static const float SCORE_SUM_POWER = 3.5f;
static const float SCORE_SUM_WEIGHT = 11.0f;
static const float SCORE_MERGES_WEIGHT = 700.0f;
static const float SCORE_EMPTY_WEIGHT = 270.0f;
void init_score_table()
{
for (unsigned row = 0; row < 65536; ++row)
{
unsigned line[4] = {
(row >> 0) & 0xf,
(row >> 4) & 0xf,
(row >> 8) & 0xf,
(row >> 12) & 0xf
};
// Heuristic score
float sum = 0;
int empty = 0;
int merges = 0;
int prev = 0;
int counter = 0;
for (int i = 0; i < 4; ++i)
{
int rank = line[i];
sum += pow(rank, SCORE_SUM_POWER);
if (rank == 0)
{
empty++;
}
else
{
if (prev == rank)
{
counter++;
}
else if (counter > 0)
{
merges += 1 + counter;
counter = 0;
}
prev = rank;
}
}
if (counter > 0) {
merges += 1 + counter;
}
float monotonicity_left = 0;
float monotonicity_right = 0;
for (int i = 1; i < 4; ++i) {
if (line[i-1] > line[i]) {
monotonicity_left += pow(line[i-1], SCORE_MONOTONICITY_POWER) - pow(line[i], SCORE_MONOTONICITY_POWER);
} else {
monotonicity_right += pow(line[i], SCORE_MONOTONICITY_POWER) - pow(line[i-1], SCORE_MONOTONICITY_POWER);
}
}
heur_score_table[row] = SCORE_LOST_PENALTY +
SCORE_EMPTY_WEIGHT * empty +
SCORE_MERGES_WEIGHT * merges -
SCORE_MONOTONICITY_WEIGHT * std::min(monotonicity_left, monotonicity_right) -
SCORE_SUM_WEIGHT * sum;
}
}
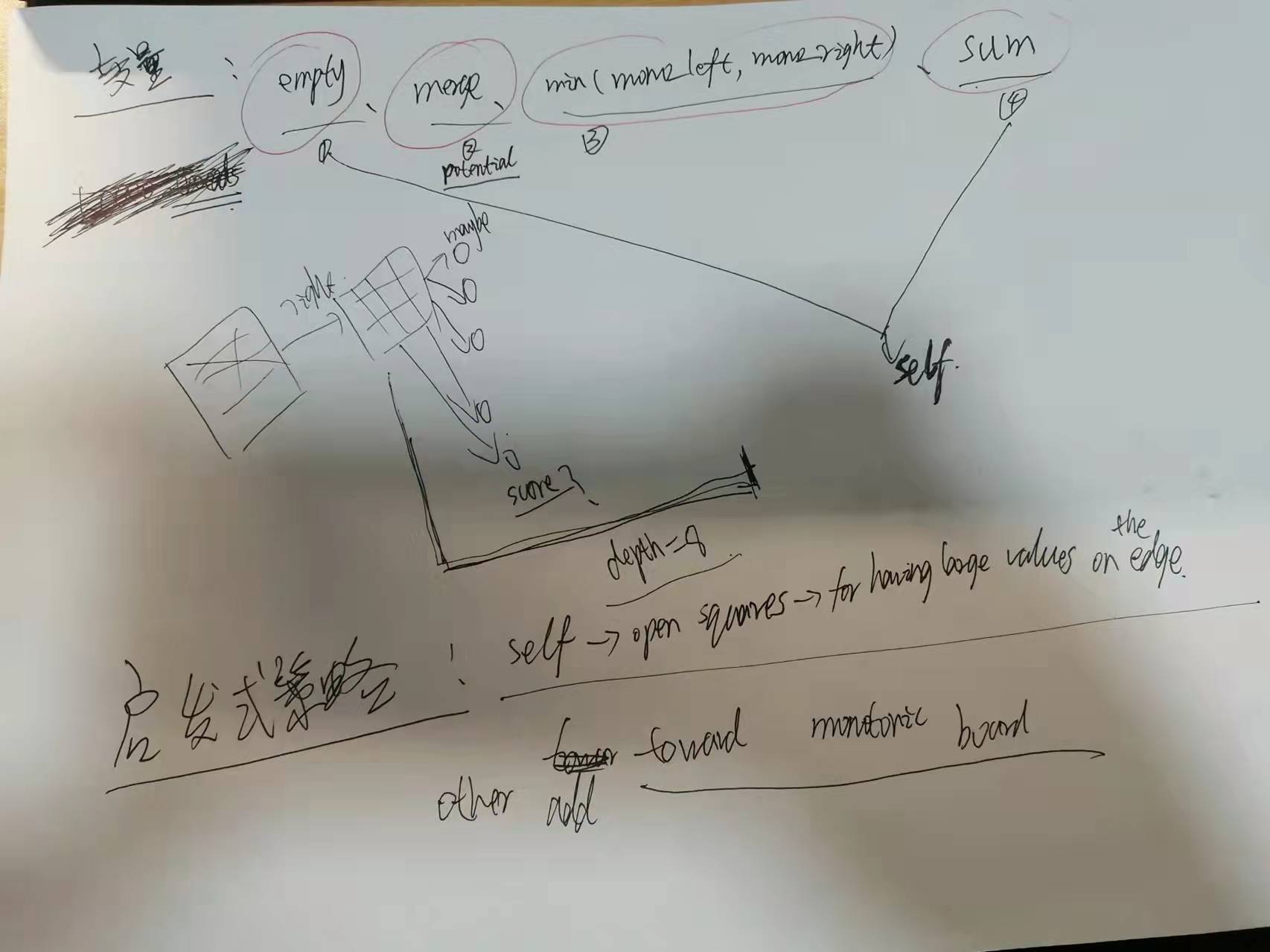
在这里启发式算法设计是按照四个预设规则来进行的:(算法中是计算每一行数据中符合规则的值,列是按照转置后按行的方式计算的)
1. 行中空格的数量, 算法中用变量 int empty 来进行计数,权值为 SCORE_EMPTY_WEIGHT = 270.0f ;
2. 行中可以合并的块数,变量为 merges,权值 float SCORE_MERGES_WEIGHT = 700.0f;
3. 行中数字排列的单调性,变量 std::min(monotonicity_left, monotonicity_right), 权值SCORE_MONOTONICITY_WEIGHT;
4. 行中数字的大小,变量sum,权值SCORE_SUM_WEIGHT 。
由于数字越大越不好合并,因此是 -SCORE_SUM_WEIGHT * sum;由于单调性越不好越不利于合并,因此是
-SCORE_MONOTONICITY_WEIGHT * std::min(monotonicity_left, monotonicity_right) 。
最终给每个游戏状态预设的启发值的计算方式为:

========================================
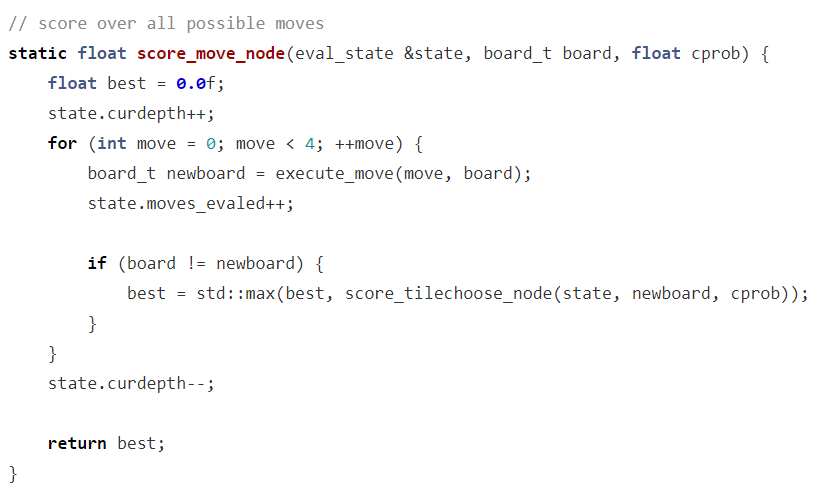
算法设定,每次进行选择时(上下左右四个方向),都要进行一定次数的推演,也就是假设执行在当前游戏状态执行某个移动后到达新的游戏状态,如此往复计算,最终向下推演多少步数(层数)是根据两个条件来判断的,一个是按照当前状态的不同数字个数来给出的,一个是最后探索到的状态其可能达到的概率的值是否满足阈值。
需要注意的是在算法中对游戏的状态其实是分为两种的,一种是移动后到达的游戏状态A,一种是移动后游戏自动生成块后的游戏状态B。我们计算启发值都是根据移动后到达的游戏状态A。
如果移动后到达的游戏状态不满足条件则返回该状态的启发值:

如果当前的移动后状态曾经探索过,并且该状态探索的层数低于现在,那么直接返回保存的值:

因为探索的终止条件是达到一定层数和探索到达的概率小于预设阈值,因为曾经探索过该游戏状态并且层数低于现在那么曾经探索的游戏值一定要比此刻往下探索进行过更多的探索,因此不需要再重新探索直接返回曾经探索后保存的值。
移动后到达的游戏状态后游戏自动生成新数字块,当前移动后的游戏状态的下一层补上新块后游戏状态的返回的期望值作为当前游戏状态的值并进行保存:

生成新块的游戏值为移动(上下左右四个移动)后的最大的游戏返回值。
===================================================