from sklearn.datasets import load_iris
iris=load_iris()
from sklearn.naive_bayes import GaussianNB #高斯分布型
gnb=GaussianNB() #构造
pred=gnb.fit(iris.data,iris.target) #拟合
y_pred=pred.predict(iris.data) #预测
print(iris.data.shape[0],(iris.target !=y_pred).sum()) #iris.target科学家给出的分类,y_pred建模型产生的预测,比较两个有什么不一样,
#然后将不同的值的个数求出来,150个结果中,有6个和科学家的值不同
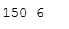
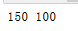
from sklearn.naive_bayes import BernoulliNB #伯努利型 gnb=BernoulliNB() pred=gnb.fit(iris.data,iris.target) y_pred=pred.predict(iris.data) print(iris.data.shape[0],(iris.target !=y_pred).sum()) #150个结果中,有100个值和科学家的值不同,说明此模型不合适
#2.使用sklearn.model_selection.cross_val_score(),对模型进行验证。
from sklearn.naive_bayes import BernoulliNB
from sklearn.model_selection import cross_val_score
gnb=BernoulliNB()
scores=cross_val_score(gnb,iris.data,iris.target,cv=10) #将数据集分为10份,其中9份作为训练模型,1份用来做评估
#score是交叉验证的对象
#结果是返回准确率的概念,结果是33.3%
print("Accuracy:%.3f"%scores.mean())
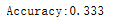
from sklearn.naive_bayes import MultinomialNB
gnb=MultinomialNB()
scores=cross_val_score(gnb,iris.data,iris.target,cv=10)
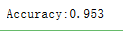
print("Accuracy:%.3f"%scores.mean())

from sklearn.naive_bayes import GaussianNB
gnb=GaussianNB()
scores=cross_val_score(gnb,iris.data,iris.target,cv=10)
print("Accuracy:%.3f"%scores.mean())
3. 垃圾邮件分类 数据准备: 用csv读取邮件数据,分解出邮件类别及邮件内容。 对邮件内容进行预处理:去掉长度小于3的词,去掉没有语义的词等
import csv
file_path=r'I:杜老师SMSSpamCollectionjs.txt'
sms=open(file_path,'r',encoding='utf-8') #将打开的数据放在sms
sms_data=[]
sms_label=[] #此将会作为分类结果传到模型里边
csv_reader=csv.reader(sms,delimiter=' ') #用csv.reader读取出来,读取的对象是打开的sms,以' 'tab键分隔字段,
#因为文本里没有逗号,是以空格分开的
for line in csv_reader: #逐行读取数据,一行是一个邮件
sms_label.append(line[0]) #一行有两个字段,第一个字段是邮件的类别,将邮件的类别放到一个列表里边
sms_data.append(preprocessing(line[1]))
sms.close()
sms_data=str(sms_data)#将列表转化为字符串
sms_data=sms_data.lower()#对大小写进行处理
sms_data=sms_data.split()#变成列表的形式
sms_data1=[]#存放处理后的内容
i=0
for i in sms_data:#去掉长度小于3的单词
if len(i)>4:
sms_data1.append(i)
continue
