3. 机器学习在搜索广告中的机遇和挑战 [PDF]
Speaker :刘铁岩 微软 IR& Web Mining 首席科学家
刘铁岩是 learning to rank 领域非常 outstanding 的 expert,但最近一年都在研究计算广告学,并将博弈论引入机器学习中。他最新的研究成果也非常新颖独特。
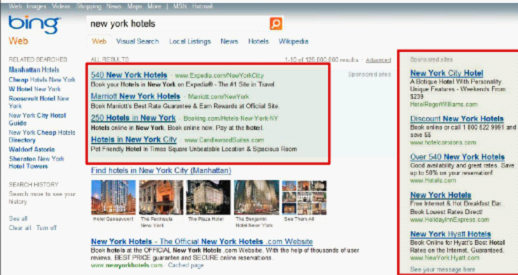
众所周知,互联网投放广告按照点击计价(CPC)相对于传统的硬广(电视广告,报纸等),大大减少了成本,成为大多数企业的首选。因此互联网 70% 的利润来自于在线广告的投放。

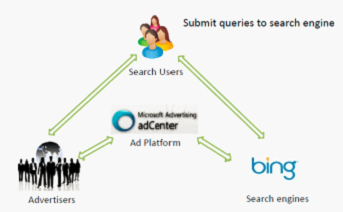
同时在线广告也是搜索引擎的利润来源,如图。搜索引擎对各个关键词进行拍卖(auction),由广告主(advertiser)进行竞价(bid),再按照一定机制进行 Ranking 和 Pricing, 这种拍卖机制就是他研究的主题。
在这个过程中, 广告主,搜索引擎和广告平台之间实际上是在博弈,但与经典博弈论不同,广告主在 campaign 中拥有的只是 partial 的 information,并不是全部信息,事实上他们彼此之间并不知道对方的出价。
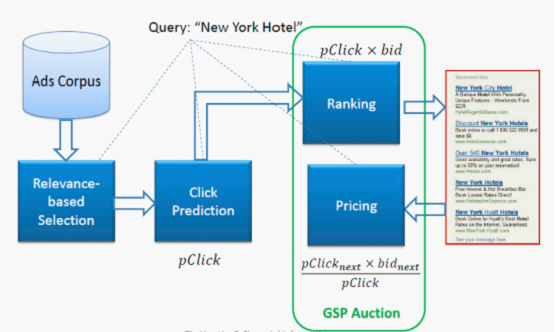
目前广告拍卖中采用的机制是广义第二价格拍卖(GSP: General Second Pricing)。在 GSP 拍卖中,广告主的链接依然按照竞价递减的顺序排列,但是广告主对每次点击的付费并非等于自身的竞价,而是略高于排名紧随其后的广告主开出的竞价 (所谓 “第二价格” 即由此而来) 。 Google 后来又引进了 “点入率”(Click~through Rate,CTR) 概念(即点击该广告的占总页面点击的比率),用来衡量每个广告主的链接与关键词的相关度。Google 通过历史数据估计每个广告主的点入率,以竞价乘以点入率(pClick*bid)得到所谓 “有效竞价”,并以有效竞价排名代替单纯的竞价排名。有效竞价排名的基本思想是按照每个广告主预期带来的总广告费用 (对搜索引擎的收入贡献) 进行排名,从而使得预期对收入贡献越大的广告主排名越靠前。
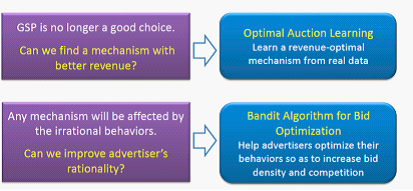
理论上这个机制很好,能够兼顾广告对搜索引擎的贡献率以及 Revenue,是的社会总收益最大化,达到纳什均衡。但是这是建立在用户能充分获取到信息,并且能够基于这些信息做出最优的决策,而实际上并非如此,advertisers 并不能获得完全的信息,并且做出的 bid strategy 并非最优的,事实上有些广告主 are simply too lazy,他们可能不会对信息做出反应。或者没有明确的 utilities 去获得最佳收益。
在这种情况下,GSP 已经不是最好的拍卖策略,我们能否从历史的交易数据 (real data) 中 “学习” 出一种最佳的拍卖机制呢(Learning a Optimal Auction Mechanism from Real Data)?这就转变为一个机器学习的问题。
想法很 Simple 很 Naive,但这和传统的机器学习一样么?答案是否定的。传统的统计机器学习中,要求训练数据集是独立同分布(i.i.d)的,而且不会变化,但是在广告拍卖中广告主 bid 的 distribution 却依赖与我们的拍卖机制,advertisers changes their bid as response to the mechanism, which will generate a different bid distribution.
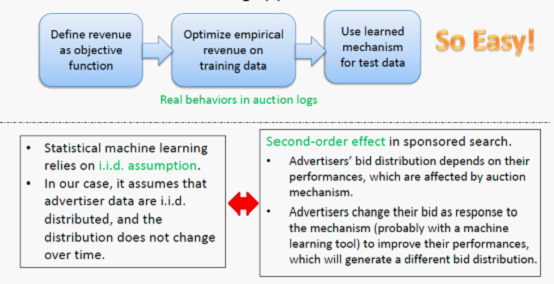
当广告主行为和拍卖机制这两个 variables 相互依赖时,我们可以找出一些参照变量(reference variables)使得广告主的行为相对于拍卖机制而言条件独立。
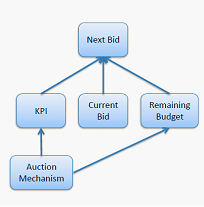
因此我们对 Typical advertiser behaviors 进行分析: 对于一个关键词,广告主给出他们的 bids; 在 t 时刻,根据拍卖的结果,广告主们得到关于他们的 performance 和 payments(known as KPI)的 report; 在 t+1 时刻,广告主根据 他们剩余的预算(remaining budget)重新 place 新的 bids,进行下一轮 auction。
根据以上分析,我们可以找出两个 reference variables : KPI 和 Remaining Budget
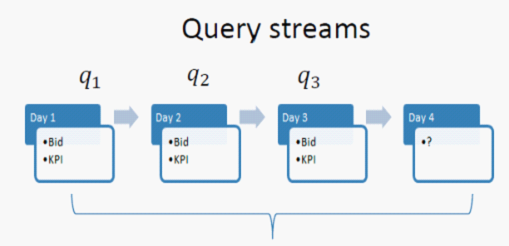
接下来,我们可以用马尔科夫随机过程来对广告主的 bid 行为进行模拟。给定 KPI,Remaining budget(剩余预算),和 current bid(当前竞价),我们可以学习出一个马尔科夫概率转移矩阵,来代表广告主从 bid b 变为 b' 的可能性。
这里用核估计来估计关键词的转移概率。
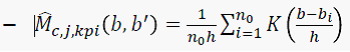
核心在于 条件概率的转化

这样就对广告主的行为进行了很好的模拟,然后定义一个使收益最大化的目标函数
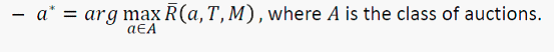
通过多个 T 时刻的 bid 数据进行迭代训练,使之达到收敛, 就能很好的预测出广告主在下一时刻的 bid behavior。(这是机器学习中常用的最优化方法,可以参见李航博士的统计机器学习一书)
http://blog.sciencenet.cn/blog-815321-636126.html
上一篇:MLA 2012 Notes (2) - Transfer Learning and Applications
下一篇:MLA 2012 Notes - 后记
科学网—MLA 2012 Notes (2) - Transfer Learning and Applications - 鞠源的博文2. Transfer Learning and Applications [pdf] Speaker:杨强 & nbs......
2. Transfer Learning and Applications [pdf]
Speaker:杨强 HKUST 教授,General chair of SIGKDD, 华为诺亚方舟实验室主任
杨强还是讲的迁移学习,不过却很有趣,迁移学习可以看做强化学习的一种,将一个领域习得的知识用于另一个领域,用于不同 domain 的 knowledge transfer, 由 labeled data 扩展到 unlabeled dataset,对于一些标注代价昂贵且不易获得的数据集很有用,应用较广泛。
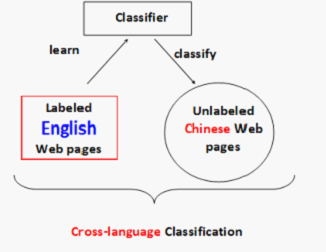
一个简单的例子是,我们要针对中文的网页训练一个数据集,但是我们手上没有或只有少量的中文网页数据,却有充足的标注好的英文的数据集。目标还是一样,对未标注的中文数据集进行分类,这就是所谓的跨语言分类(cross-language classification)如图,显然这有别于传统的文本分类,因为在这里训练数据和测试数据是两种不同的语言。
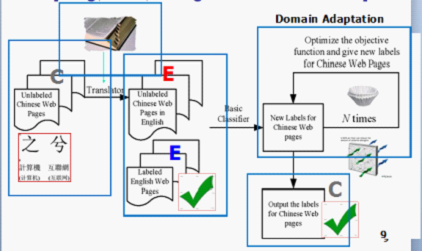
Scenario 就是这样,那我们应该怎么办呢? 在所有异质迁移学习任务中,我们首先需要建立两种异质特征空间的联系,在这里我们有充足的英文语料,但目标是对只有很少标注语料的中文文档进行分类,所以需要对两种语言的数据集建立关联,bridge 两种特征空间((注:在文本分类里,特征空间就是词汇空间)),所以一个直观 solution 是想办法获得两种特征空间(这里表现为中文和英文词汇)的共现(co-occurrence)数据(例如我们手上有个字典,将英文 term 和中文 term match 起来),通过这种方法,我们可以根据他们的共现频率去估计两种数据集在特征(词汇)层面的迁移概率。因而能利用训练得到的英文分类器去分类标注中文文档,进而迭代获得更多的标注数据。
另一个有趣的场景是,如何利用文本训练数据集去对图像做分类? 众所周知图片的标注数据集相对于含有特定主题的文本而言是很难获得的。

同时在实验中对一个很意思的命题进行了论证: 所谓一图抵千言, 真的是这样么?准确么?那么一幅图究竟能代表多少字呢?

方法还是一样的,首先需要发现图像和文本特征空间的关联,找到沟通他们的桥梁。
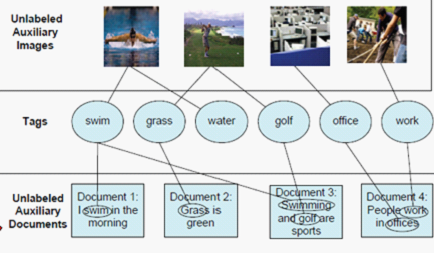
好在这种关联并不难以找到,通过爬取一些社交网站(如 flickr 等)上,人们对图片打上的标签(tag)。获得图像和对应标签注释文本之间的共现数据,从而建立起图像特征空间和文档特征空间之间的关联。
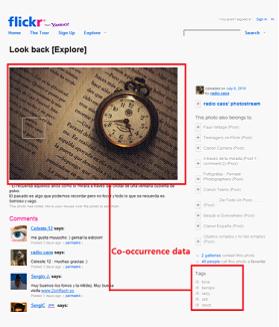

在实验中,如果要达到 75% 的分类准确率,需要 100 多个标注图片,而如果使用文档(document)的话,要达到相同的准确率需要 200 多个文档。因此我们可以得出
each Image = 2 text documents = 1000 words(statistically per documents has average of 500 words) 即所谓的一图抵千字!

http://blog.sciencenet.cn/blog-815321-636118.html
上一篇:MLA2012 Notes (1) - 利用知识智能、数据智能和社会智能
下一篇:MLA 2012 Notes (3) - 机器学习在搜索广告中的机遇和挑战
科学网—MLA2012 Notes (1) - 利用知识智能、数据智能和社会智能 - 鞠源的博文 Use Knowledge Intelligence, Data Intelligence and Social In......
Use Knowledge Intelligence, Data Intelligence and Social Intelligence for Internet Innovations [PDF]
Speaker:周明,微软亚洲研究院首席科学家。
该 presentation 介绍了三种类型数据智能(data-Intel)的区别和联系,以及将三种智慧结合起来实现 QA,MT,和自动对对联的系统。
三种智能:
Knowledge intelligence(KB-Intel) 指专家知识,一些领域内的 rules。优点是质量高,一旦问题(query)在该知识库范畴内搜索到解,往往比较准确。‚因为是固定存储的知识库,所以搜索成本小,速度快,在有适当索引和算法时能较快生成答案,而无需从网上爬取答案和获得用户 log 进行计算。缺点是这些专家知识比较难以获取,代价较大。 ‚专家知识相对静态,不易更新,时效性不高。
Data intelligence 数据智能,主要指从 web 上 data 挖掘得到的知识。 这类 inte 时效性较高,相对容易获得;‚领域宽泛,海量(large scale,general domain) 但质量较低,网上的数据存在噪音干扰,准确率较低 ‚速度慢, 因为要从 online 获得数据,进行挖掘
Social Intelligence 社会智能,主要指与人(用户)的互动得到的数据(众包)。如用户的 feedback 和 log.
Combine 三种 Intelligence 去构建智能系统
主要介绍了微软 Online 的三种系统及其构建,也提到 NLP2.0 的概念以及 Nlp for Search Engine
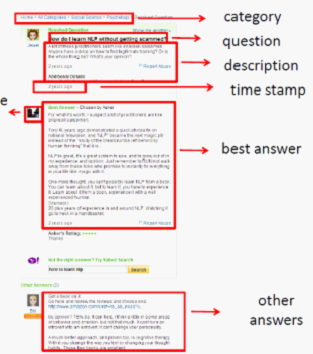
1. Light-QA 问答系统
① 定义提问的类型 如 Person,Location, Works, Time Events. Number, Others。

② 数据获取,知识库构建
已有的专家知识库(KB-QA)
从网上爬去数据,构建知识库 (WEB-QA)
从一些问答社区如百度知道,yahoo Answers 获得数据(Social-QA)。

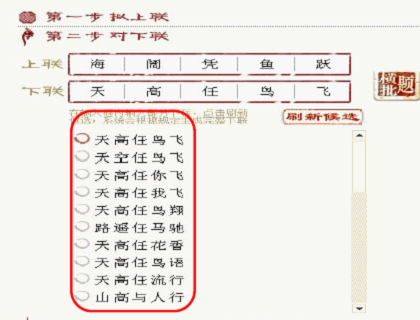
2. Chinese Couplets 自动对对联系统,并扩展到诗词生成 (NLP2.0 )
Chinese Couplets(http://duilian.msra.cn).
Demo (http://video.sina.com.cn/v/b/10937201-1452530713.html)
用户输入上联,系统利用已有的文学知识库中,通过一些算法(如 HMM,N-gram)等生成候选下联的列表,利用一些平仄规则,加以过滤。最终生成 ranked candidate couplet list。供用户选择。再利用用户操作行为的 logs 对模型进行强化(Encode User's Wisdom into the System)。
3. EngKoo 词典 http://dict.bing.com.cn 和个性化同声翻译系统。(MT)
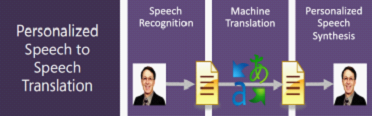
同声翻译比较牛逼,综合了语音识别 (将奥巴马演讲时的声音信号识别成 text),机器翻译(将英文翻译成对应的中文),最后合成转化成演讲者本身的声音特质,播放出来。速度很快,几乎实时。
http://blog.sciencenet.cn/blog-815321-636116.html
下一篇:MLA 2012 Notes (2) - Transfer Learning and Applications
科学网—MLA 2012 Notes - 后记 - 鞠源的博文4. 图像处理及可视化领域 & nbsp; 这里的几个 session,讲得都比较诘曲聱牙,对 mathematics 尤其是矩阵的要求特别高,我都忘了,实在没听懂 ... , 科学网
4. 图像处理及可视化领域
这里的几个 session,讲得都比较诘曲聱牙,对 mathematics 尤其是矩阵的要求特别高,我都忘了,实在没听懂,谁看懂了教教我哈,简单介绍下
4.1 Parallel Field Ranking [PDF]
浙大何晓飞教授介绍了将流形嵌入应用于机器学习中的 ranking,在实验数据集上达到比 SVM 更优的效果。
4.2 Rank Minimization – Theories, Algorithms and Applications [PDF]
北大林宙辰 教授介绍了利用秩最小化解决矩阵稀疏性的问题,并用他的算法对图像进行 segmentation 和 adjustment。实验应用效果很 inspiring。

红色是正常的,绿色是算法调整后的。很实用。
林宙辰先前是微软亚洲研究院 图像可视化 领域的首席科学家, 可见微软在 Vis 领域确实做的工作确实很 solid. 包括故宫的数字版清明上河图。
5. AAAI'12,KDD'12, ICML'12,NIPS'11,SIGIR'12, WWW12 等会议
这个 Session 就比较轻松了,也比较扯,先是刘铁岩讲今年在北京举行的 SIGKDD 1299 人参加,创历史最高(因为在北京举行所以涌现大批华人学者),由于租的国家会议中心,地方太大,坐不满,所有 tutorial 免费向学生开放,后来全坐满了。kddcup 获奖的是两个团队,一个是中科院的一个班,一个是 libsvm 发明者林智仁的一个班,但用的方法都不是最好的。所以比较失败。 然后李航说,SIGIR 由于和 KDD 重了,所以只有 399 人参加,他一个人去了爱丁堡,是真正的 SIGIR 的人。。。
然后朱军说 NIPS'11 的 Best Paper 还是 John Lafferty (CRF 的提出者,CMU 教授,翟成祥的老师)。最后杨强宣传了下华为才创立的诺亚方舟实验室,很多牛人都去了,包括微软研究院的李航,还有 IBM Watson 实验室的范伟。
这里值得提下的是 John Lafferty 这个人,后来听张长水和朱军说,他竟然是大数学家陈省身的 post docs,在中国待了很多年攻读数理统计。后来去美国,带了两个中国的好学生:一个是 IR 领域大名鼎鼎的翟成祥,一个是 liu han。由此可见, IR or Data Mining 和数理统计的渊源。这些人一脉相承,可能真的是有非凡的数学功底,才能把一些算法演变的很炫。对我们而言,算是心有余,而力不足。反观韩佳炜,他成名则有所不同,靠的是扎实的数据库 expertise,看他的一些算法,如 Sim-Path, trajectory mining 等有一种 大朴似简的感觉,却被誉为 Data Mining 领域的 “张三丰 “,他的方法和途径是可以借鉴的。
http://blog.sciencenet.cn/blog-815321-636128.html
上一篇:MLA 2012 Notes (3) - 机器学习在搜索广告中的机遇和挑战
下一篇:KDD-CUP Proposal