Cross-Modal & Metric Learning 跨模态检索专题-1
·前言
去年在跨模态检索/匹配 (cross-modal retrieval/matching) 方向开展了一些研究与应用,感觉比较有意思,所以想写点东西记录一下。这个研究方向并不是一个很"干净"的概念,它可以与 representation learning、contrastive learning、unsupervised leraning 等等概念交叉联系。并没有时间和能力写综述,思来想去就以研究较多的图文跨模态检索为切入点来介绍下相关工作。
本专题计划分3个部分介绍图文跨模态检索的一些工作与思考。第一篇将侧重 "multi-modal" 和 "application", 介绍相关概念与研究背景;第二、三篇会侧重"algorithm" 介绍这个方向研究的技术路线,其中第二篇介绍基于 GAN 的追求公共子空间的 cross-modal 检索;第三篇则从 modal 抽象成更一般的 domain,并且将多域扩展到单域,总结分析单/多域匹配问题,主要介绍基于 contrastive learning / instances discrimination的研究思路。专题重点将会在第3篇,可能会用视频的方式介绍。我在实际工作中分别使用过 GAN 和 instance discrimination 这2种思路,近期结合二者尝试了综合模型效果提升明显。
注:本专题内容主要来源于我去年的几次内部分享笔记,当时 PPT引用了一些来自互联网的图片,但是现在出处实在是找不全了,所以不会一个个注明来源,如果有侵权,可以联系删除,谢谢~
本文脉络
- 多模态研究背景介绍
- 跨模态检索的两类研究方法
- 工业界应用中要注意transfer learning
·背景介绍
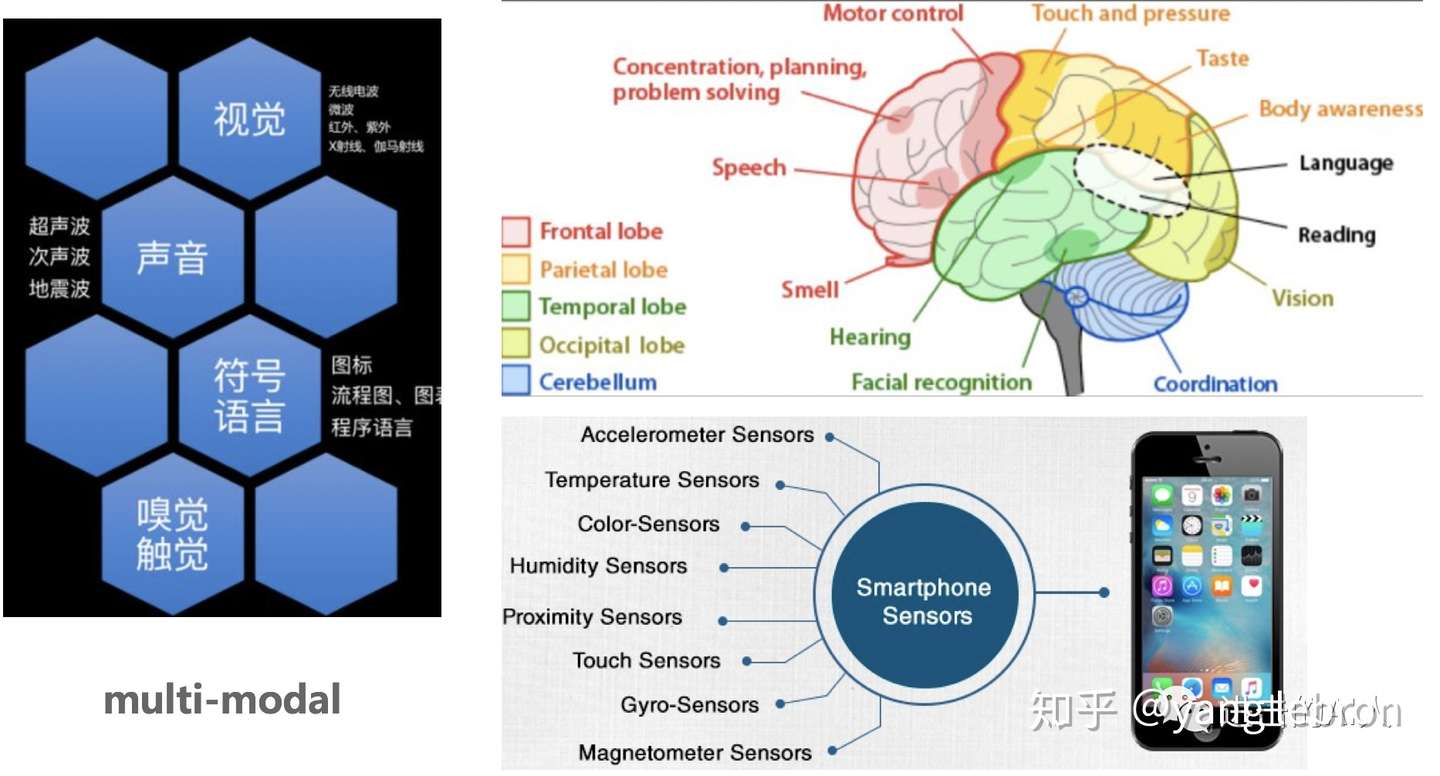 Fig. 多模态信息 everywhere
Fig. 多模态信息 everywhere
此刻的你也许正坐在电脑前,听着喜欢的音乐,看着上面这张图片,读着这段文字,等着香醇扑鼻的热咖啡冷一点再喝。世界是复杂而又多元的,为了理解这个世界,人的大脑就要做到分工明确而又统一指挥。分工明确是指不同区域负责不同的感官,接受图片、文字、气味等外界不同模态的信息;统一指挥是指能够将这些多个模态的信息综合处理互相融合最终得到统一的处理反应。
近几年媒体一直在"炒"人工智能这个概念,学术界和工业界也是在不断的研究与应用(见下图几个顶级会议的文章研究关键词分析),幻想着能够搭建出一个 brain 来逼近人脑的功能。
 Fig. AI相关科研现状
Fig. AI相关科研现状
上图中 CVPR、ACL、ACM MM 分别属于了图像、文本、多媒体3个领域的顶级会议。虽然统计有幸存者偏差,不过还是能说明目前很多研究的对象还是相对独立的单个模态信号。MM 虽然是交叉学科但是 CV 的研究还是明显超过 NLP。当前这样独立发展,很难在一个融合的系统生态中完美的应用。因此基于多模态、跨模态的研究是很重要也很有必要的。
"那应该怎么研究呢?", 一位不愿露面的网友如是问道。
 Fig. 各个模态数据不对应,各自的空间大不相同
Fig. 各个模态数据不对应,各自的空间大不相同
本文主要以图片和文本两个模态的信号来展开介绍。如上图所示,若以左侧小女孩图片为 anchor,那么可以有下方多种相关文本语句来描述;同理如若以图片右侧那句话『放风筝的小女孩』为 anchor/seed,也可以找到周围4幅图片来代表这句话。所以我们可以看到图文不同模态信号之间存在一种多对多的"映射"关系。这里的映射不是普通意义上的 map 函数,有点类似翻译模型(中文和英文两个不同 domain 的信号),但又复杂的多。文本域中的信号不一定能在图片域中找到对应的信号,比如『3只眼睛的男人带着3个头的小孩在遛狗』这句话就找不到一张图片来对应。"杨戬和哪吒拉着哮天犬马上就到",不愿露面的网友这思维挺敏捷的。。。总之可以看到由于不同模态的信息所处的空间差异太大,想要用 id 映射的方式来打通是不可能的。同时,多模态研究的重点也正在于如何将这些截然不同的空间互相关联上?
 Fig. 空间映射是本质
Fig. 空间映射是本质
上面说到两个模态的空间映射是这类问题的本质。这个所谓的映射,可以表现为不同的应用形式。比如图文这2个模态,就可以有上图3类常见应用方向:生成、问答、检索。Generate 方向 任务包扩给一张图,让你生成一段话来描述它(image caption);或给一句话,让你生成一张对应的图片(各种GAN)。VQA 类任务则更加重视内容理解,如给一张图片,让你回答图中穿黑衣服的有几个人?Generate 和 VQA 任务更多的是细粒度的研究,所以 attention 这个好东西就会经常用到。而我们这个专题要探讨的是第3类应用--检索/匹配(下面简称检索)。这个任务更多的是语义级别的理解,往往不需要太细粒度。检索任务就是给定一个模态中的信号,让你在另一个模态的空间中找到"对应的"或者最接近的若干个信号。或者给你两个不同模态的信号,让你判断是否相关。听着是不是有点像 metric learning,给二者找到一个度量空间,亦或是设计一个度量方式来衡量不同模态信号间的距离。好吧写到这才引出了本题目中的 metric learning~
这里解释一些名词关系,上面提到了很多 XXX learning。这些learning 之间是什么关系呢,有什么区别与联系呢?其实简单的说这些名词概念并不是同级划分的,是一个类似交叉、包含的关系。根据研究方向的侧重点不同,才有了这些概念。比如 ICLR 更多的关注 representation learning 想要得到一个信号的embedding,而 metric learning 则是一种侧重研究度量相似度的方向,那必然可以对这个 embedding 进行度量研究。同时 contrastive learning 又可以是这个方向里的一类研究方法。总之是没必要也不可能完全区分出来,一些总结会在本专题第3篇中介绍。
·两种研究套路
从上一部分的介绍可以归纳出,所谓"映射"这一跨模态检索的本质就是对不同模态的信号分别进行编码得到其语义表示 embedding,同时要建立一个度量方法用该距离来判断这些 embedding 之间的关系。
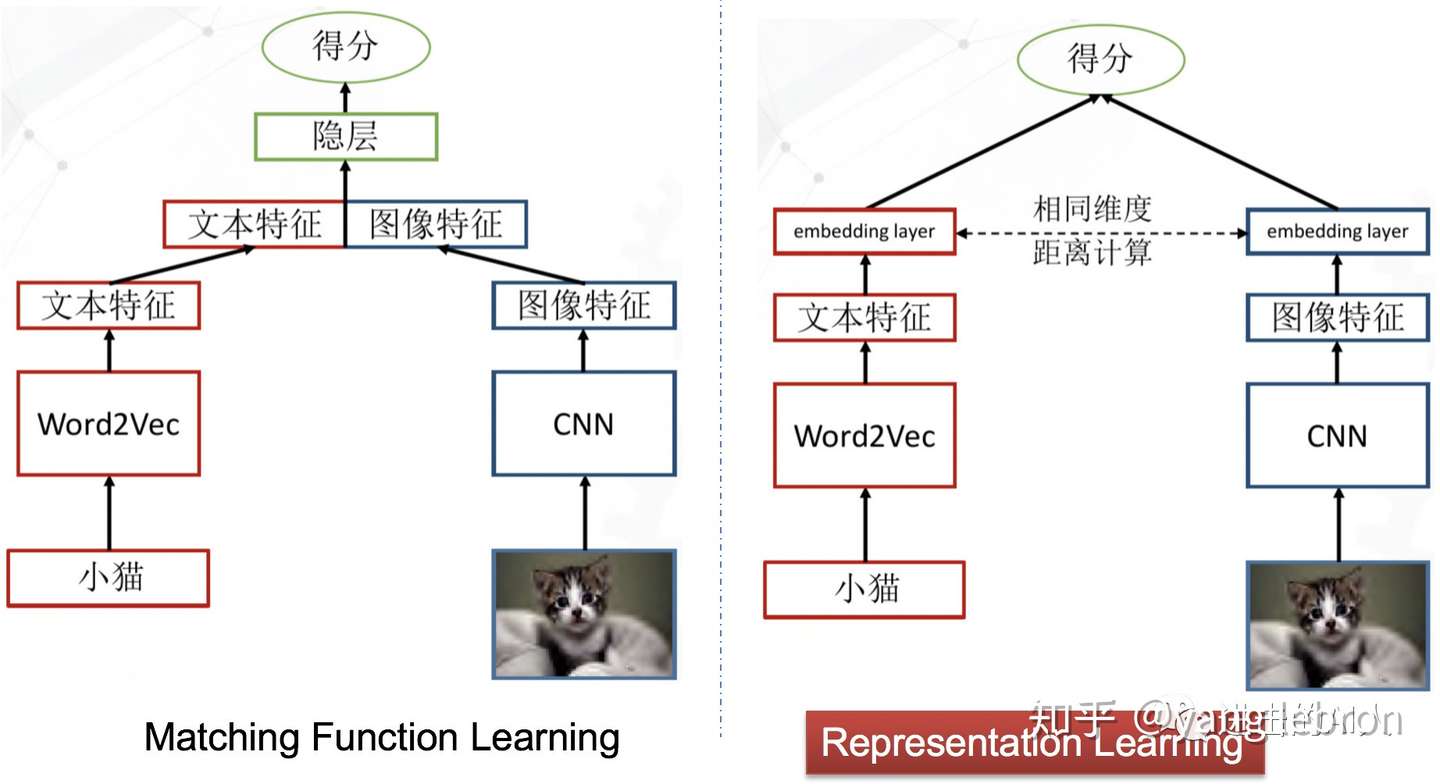 Fig. 跨模态的两种建模思路
Fig. 跨模态的两种建模思路
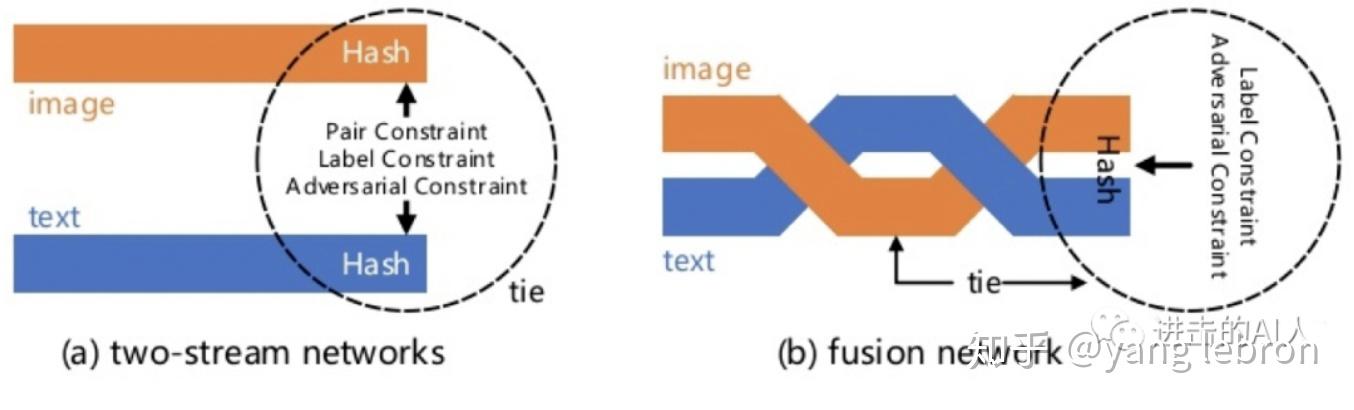
上图是两个极其简洁的图文跨模态匹配模型。虽然简洁,但是代表了这类问题的2种研究思路。后续发展出的一堆复杂的变形金刚模型,其本质还是依照上面这2个"套路"的指导。左侧模型的思想是,图文特征先融合,然后再过隐层,让隐层来学习出一个不可解释的跨模态距离函数,最终得到一个图文关系得分。右侧模型(一般称双塔结构)的思想是,图文特征分别计算得到最终顶层的 embedding,然后用可解释的距离函数(如 cosine、L2等)来约束图文关系。
一般而言,同等条件下,左侧的模型"效果"要优于右侧的模型。因为图文特征组合后可以为模型隐层提供更多的交叉特征信息,所以一般这类模型的准确度会高一点。但是,这个模型存在致命的缺陷就是无法使用顶层 embedding 来独立表示图和文的输入信号。在一个 N 图 M 文输入的检索召回场景下,就需要 N*M 个组合输入到该模型才能得到图搜文或文搜图的结果。再者,在实际线上使用时,计算性能也是很大的瓶颈,特征组合后隐层需要在线计算。又由于交叉组合量非常大,也就无法通告提前存储图文信号的 embedding 向量来cache计算。模型设计的核心是如何交叉组合不同模态特征,属于 Matching function learning 分支。这类模型虽然效果好,但并不是研究应用的主流。
右侧的双塔模型结构是当前最主流的检索结构(阿里有 TDM),由于分隔开个图片和文本两个不同模态的信号,所以可以分别在离线阶段计算出各自的顶层embedding。存储后在线使用时,只要计算2个模态向量的距离即可。如果是pair 相关性过滤,则只要计算2个向量的 cosine/L2距离;如果是在线检索召回,则提前将一个模态的embedding 集合构建成检索空间,使用 ANN 算法去搜就行。这类方法的核心是得到高质量的 embedding,因此可以当做是 representation learning 这一分支。
双塔结构不仅仅存在于图文跨模态场景,在其他场景下也是被广泛的应用。比如广告或推荐场景,广告/内容是一个模态,用户/流量是一个模态。再比如文本相关性场景,虽然是同模态数据,但是也各自代表不同的域 domain,双塔套路依旧有效。
双塔的套路虽然简洁有效,应用广泛。但是缺点也非常明显,模型结构就能看出,不同模态的信号基本没有交互,因此往往很难学习出一个高质量的代表信号语义的 embedding。对应的度量空间/距离也就没那么准确了。
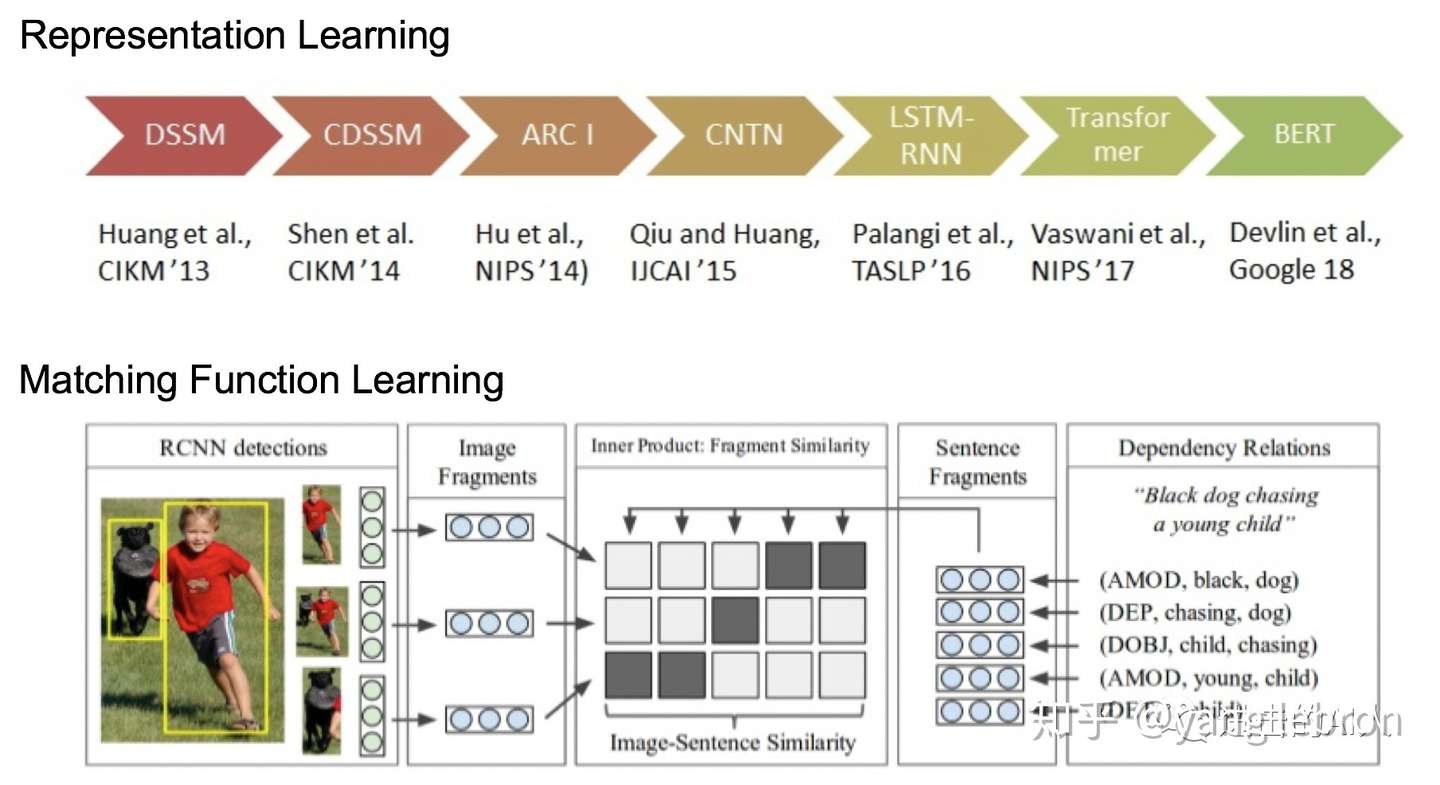 Fig. 两种研究方向的一些代表工作
Fig. 两种研究方向的一些代表工作
上面对比了两种研究思路的优劣。在研究进展上,Matching Function Learning 这一分支会很关注细粒度的 attention和交叉特征。本文只讨论 Representation Learning 这一分支,上图可以看出这一脉络的研究工作还是很多的(不局限于双塔跨模态领域),研究者们都想找到一个方法能够将信号 embedding 化,并且这个 embedding 能完美的『代表』这个信号本身,而这些 embedding 组成的空间则能完美的『代表』这个模态空间。学过泛函分析的话,应该知道"度量空间"以及"完备"这些概念。如果真能将 embedding 构建在一个完备的希尔伯特空间中,那就真的可能是完美的了。
·实际工作中注意 Transfer Learning
目前基于有监督和无监督学习的一些里程碑的工作,已经可以很好的达到 represent 这一目的。比如 resnet、bert 可能分别是图片和文本领域中应用最广泛的 pre-trained 模型了,很多工作都是先用这俩模型得到一个 baseline embedding,然后在下游任务中重新 fine tuning 得到最终的 embedding。
Resnet、Bert 这些为各自模态内部提供了一个很高的 baseline embedding,但是想要用一个模型对多模态信号都能得到一个优秀的embedding 还是很难的。Graph 这种异构思路可以尝试,不过很依赖模态共现关系。
实际工作中,我们应重视借助 transfer learning 的能力来加速/提高模型的训练和效果。理论上,如果有足够的数据,train from scratch 也是可以的,比如文本就是用one-hot表示然后自己搞一套 word2vec。但是跨模态应用场景下,往往这种 pair 数据很难获得,因此需要更多的借助 pre-trained 模型。
在一般情况下,把跨模态匹配问题变成了一个纯粹的空间映射问题(比如2048维的 resnet 图像特征空间 VS 768维的 bert 文本输出空间),这样会简化任务,得到一个基本"能用"的结果。。。
本专题后两篇将介绍如何使用 GAN、metric learning 等思路踩在 resnet、bert 这些巨人的肩膀上来优化跨模态 embedding 的生成。更多的优化细节,可以继续关注本专题的后两部分 ~
推荐阅读
Cross-Modal & Metric Learning 跨模态检索专题-2
Cross-Modal & Metric Learning 跨模态检索专题-3(上)
论文阅读_跨模态模型VILBERT
论文地址:https://arxiv.org/pdf/1908.02265.pdf 相关源码:https://github.com/facebookresearch/vilbert-multi-taskViLBERT是Vision-and-Language BERT的缩写,它源于2019年发表在NIPS(…
CVPR 2020 | 自监督学习与迁移学习在多模态场景下产生了奇妙的化学反应!
Cross-Modal & Metric Learning 跨模态检索专题 - 2
· 前言
专题链接:
Cross-Modal & Metric Learning 跨模态检索专题 - 1本专题计划分 3 个部分介绍图文跨模态检索的一些工作与思考。第一篇将侧重 "multi-modal" 和 "application", 介绍相关概念与研究背景;第二、三篇会侧重 "algorithm" 介绍这个方向研究的技术路线,其中第二篇介绍基于 GAN 的追求公共子空间的 cross-modal 检索;第三篇则从 modal 抽象成更一般的 domain,并且将多域扩展到单域,总结分析单 / 多域匹配问题,主要介绍基于 contrastivelearning / instances discrimination 的研究思路。
本文脉络
- 双塔结构的缺陷
- "GAN" 出同一个空间
- 其他优化思路与应用效果
· 双塔结构的缺陷
在专题的上一篇中已经提到了双塔结构模型的缺陷:
『... 双塔的套路虽然简洁有效,应用广泛。但是缺点也非常明显,模型结构就能看出,不同模态的信号基本没有交互,因此往往很难学习出一个高质量的代表信号语义的 embedding。对应的度量空间 / 距离也就没那么准确了...』
双塔结构的优点是两种模态特征计算互不干扰,在得到顶层 embedding 后可以更加灵活的应用到下游任务中。而这一点也正是造成双塔结构具有上述缺点的原因。有时候贪婪也是发展的动力,对于双塔结构模型,我们既想要保留其特征计算互不依赖的优点,又想要消除其两种模态互不相识的缺点。总之:
可能有些不熟悉的同学看了上面这些文字表述后,依然对这种结构的缺点不是特别理解。下面以一个实际的例子,用数学语言和可视化数据来进一步解释下。
假设我们研究的双塔结构是下图这样的,图片和文本两个模态的数据分别来自 2048 维的空间 (

那么这两个子空间是同一个语义空间(common subspace)吗?
从上图模型的 Loss 来看,是通过约束图文两个塔的顶层 embedding 的距离来更新权重的。具体一点就是,如果输入样本中的图片和文本是有关联的正例 pair,那么左右两塔的 50 维向量应该距离很近;反之,如果样本中图片和文本是无对应信息的负例 pair,那么距离就应该很远。
虽然还回答不了 "左右 50 维 embedding 是否在共同的子空间?" 这个问题,但是从上面 Loss 的设定来看,我们是希望左右双塔得到的是一个公共子空间的。因为只有在同一个空间中,度量距离才有意义!在同一个公共子空间中去比较两个向量数据,才更准确也更可解释。
那么这 2 个空间到底是否是公共的呢?从数学角度讲肯定是同一个实数空间,但我们这里讨论的是语义空间。还是以上面模型为例,我们将左右两个模态的数据用可视化方法展示出来,如下图所示:

红色的 q 代表文本样本,青色的一簇则代表图片样本。可以直观的看到,上面双塔模型学习出的顶层 embedding,虽然都在 50 维空间中,但是有一条明显的分界线,即从语义角度来看,这是 2 个明显不同的存在模态差异的空间。
想要在这样的空间分布中,只用 cosine / 内积距离来度量两个模态的语义相关性联系,无疑是非常困难且不太准确的。
·GAN 出同一个空间
上面的 case 来看,图片和文本的两个子空间,一眼就能分辨出类别。有什么办法能让这两个空间融合到一起,消除不同模态的差异呢?很容易想到一个很火的方向:GAN。不要怂,就是 GAN!利用它,可以 GAN 出一个公共子空间,让我们无法区分哪个是图片,哪个是文本。
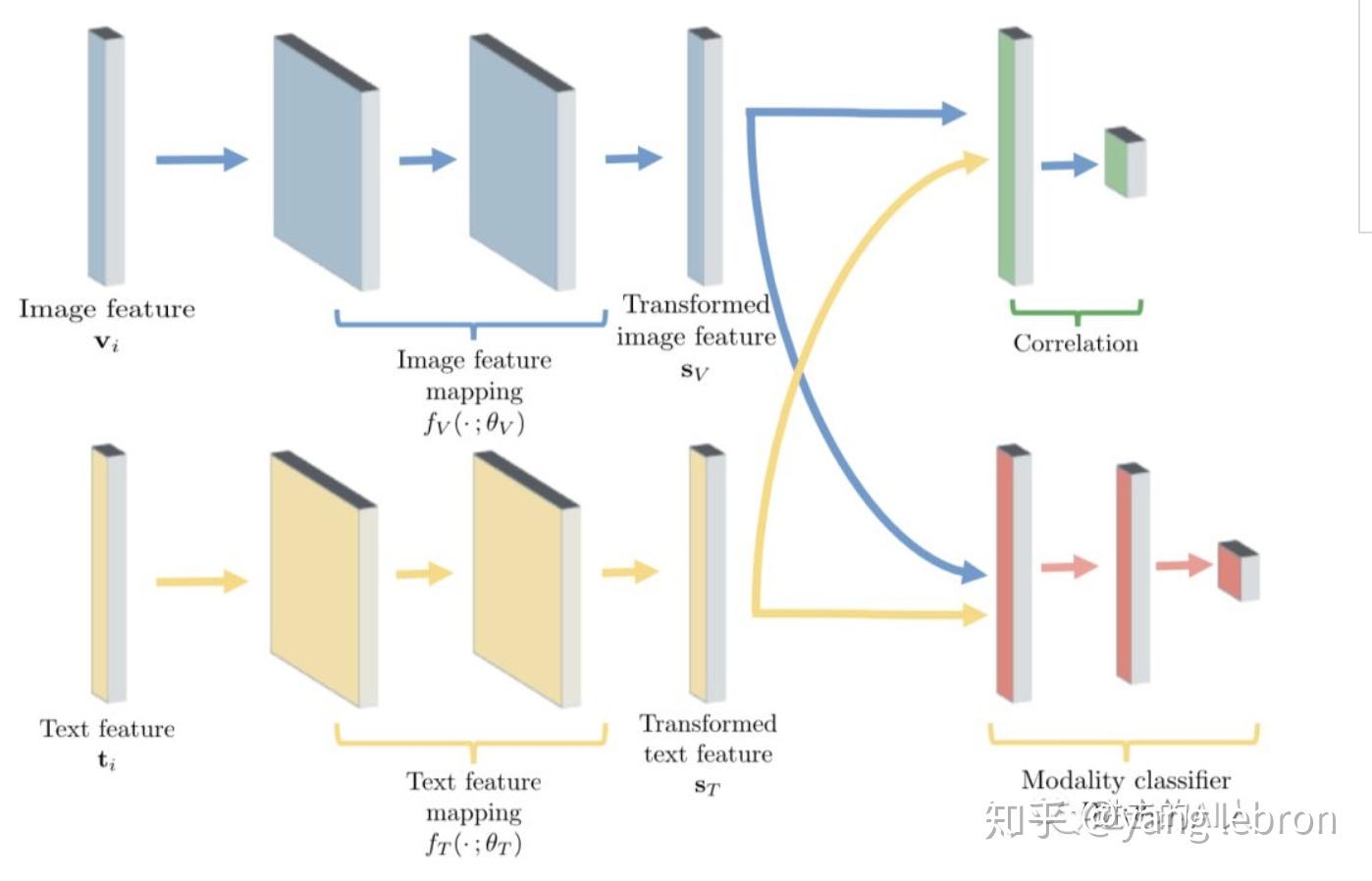
引入 GAN 的目标是很明确的,引入方法也是很简单的。只要在之前的双塔模型上增加一个判别器 Discriminator,即上图中右下角红色部分的 modality classifier。这个判别器 D 的任务是区分输入的 embedding 是图片的还是文本的。
引入 GAN 思想来改进双塔结构后,模型就有了 2 个任务 / Loss。一个是之前的利用图文 pair 关系约束距离的 Loss,另一个是新增的判别器 Loss。判别器的 Loss 可简单的设计成一个二分类 Cross-Entropy Loss,输入是图片侧的塔和文本侧的塔的顶层 embedding,输出是预估该 embedding 是来自于哪一个分支。上图左侧生成图文顶层 embedding (Sv, St) 的这部分网络相当于是生成器 Generator。
G 想生成 2 个融合的空间,D 想生成的是 2 个有鸿沟的空间,2 个 Loss 是相反的,这样一个对抗网络结构就完成了。当 G 和 D 都训练的稳定后(理想状态就是纳什均衡)此时双塔网络模型得到的顶层 embedding 则会处于一个公共子空间,互相间减少了模态鸿沟。经过 GAN 思路优化前后的空间分布对比图如下
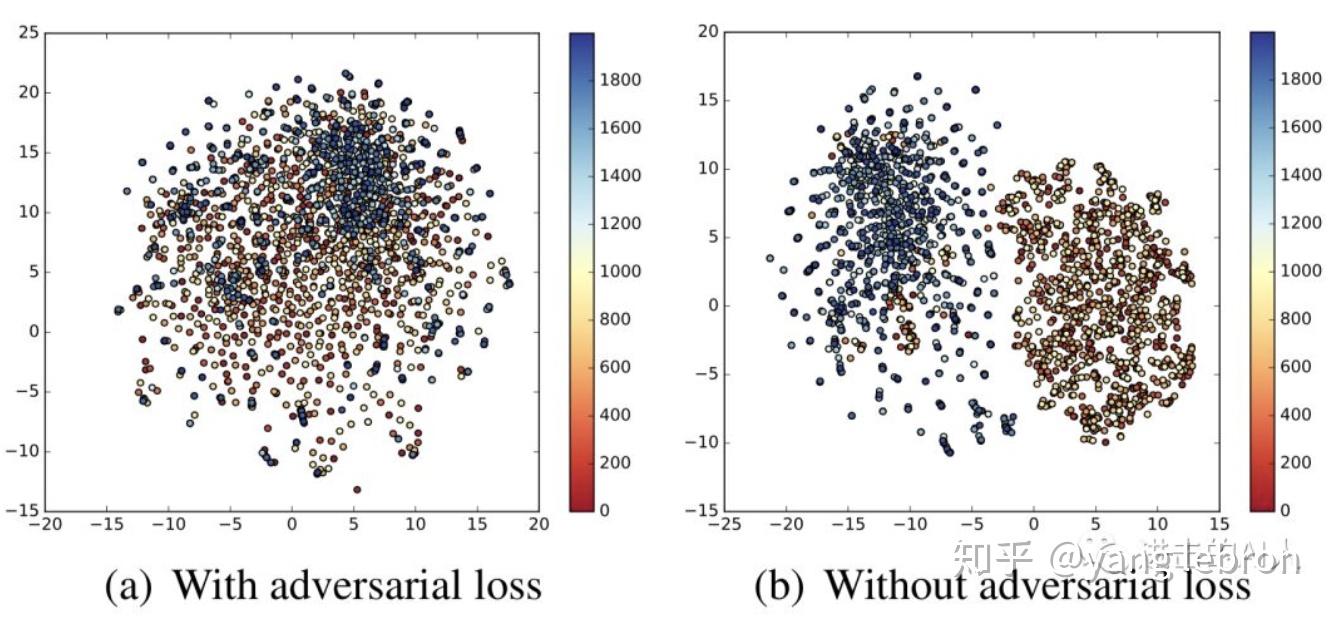
引入 GAN 对抗的思路比较简单,容易想到。但是,实际工作中想要训练成功还是很难的。众所周知 GAN 的训练需要大量的人工介入,hand-design 的痕迹很重。再者,在广告、推荐等场景下的双塔模型,其训练样本可达千万级亿级,所以都是分布式训练。在分布式场景下调整好一个对抗模型就更难了。
这里简单提一个常用的 GAN 训练技巧,即 G 和 D 同时训练。Loss 的符号和梯度的更新范围这些基础就不说了。只提下梯度翻转层 Gradient Reverse Layer (GRL)。在实际应用时,我发现在训练中 GRL 的权重 l,最好做到随着已经进入模型的 instance 的个数而变化,我一般称为 DGRL,动态梯度翻转层。下面提供使用 TensorFlow 的一种实现方式。
class FlipGradientBuilder(object):
def __init__(self):
self.num_calls = 0
#名称只能用一次,故此迭代运行的时候需要更换名称
def __call__(self, x, l=1.0):
grad_name = "FlipGradient%d" % self.num_calls
#自定义 求导, reverse 梯度, 正向时透明,反向时,乘以-l
#下面这个首先定义自己的导数
@ops.RegisterGradient(grad_name)
def _flip_gradients(op, grad):
return [tf.negative(grad) * l]
#下面是forward时,透明,所以重写自定义的导数,直接y=x。用identity是和y=x有一些性质区别,必须用identity
g = tf.get_default_graph()
with g.gradient_override_map({"Identity": grad_name}):
y = tf.identity(x) #tf.identity属于tensorflow中的一个ops,跟x = x + 0.0的性质一样
self.num_calls += 1
return y
flip_gradient = FlipGradientBuilder()
· 其他优化思路与应用效果
运用了对抗学习的思路后,将不同模态数据融合到同一个子空间中,确实有助于消除模态间的鸿沟。但是仅凭这一个优化点是还是很难实现不同模态语义同分布的。我们首先分析下一个合格的公共子空间应该具备拿下性质:
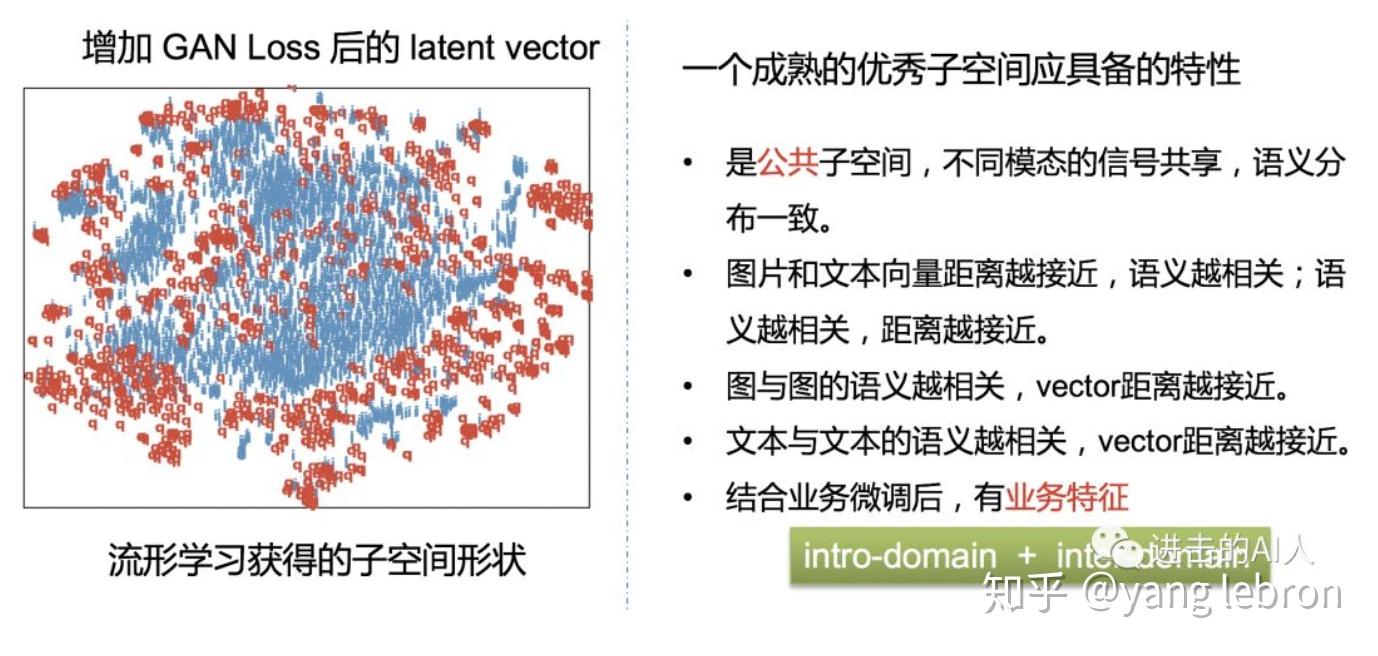
上图中的几点特性都是我们追求的语义同分布的目标。其中业务特征也很重要,举个例子:在文本侧 pre-trained 的模型 embedding 中,在 “华为” 这个词附近的可能是 "小米",但是在检索业务中,我们希望检索 "华为" 时,召回最近的是 "magic book 笔记本"、"荣耀手机" 等相关的图片或者文本,而不是小米相关的东西。
除了使用对抗学习消除模态鸿沟,获得公共子空间外。还有很多其他的优化思路,由于这些内容很多很杂,而且有的属于本专题第 3 篇的范畴内,所以这里只简单的罗列几个常用的代表性方法。
1)检索系统中有一类是最终基于哈希码的 HASH 方法。这里用 HASH 更多的是出于工程性能的应用,本身并不在我们讨论的算法范围内。不过既然应用的多,那么第一个优化思路就介绍下 18 年 CVPR 的相关工作:自监督对抗哈希 (SSAH)。
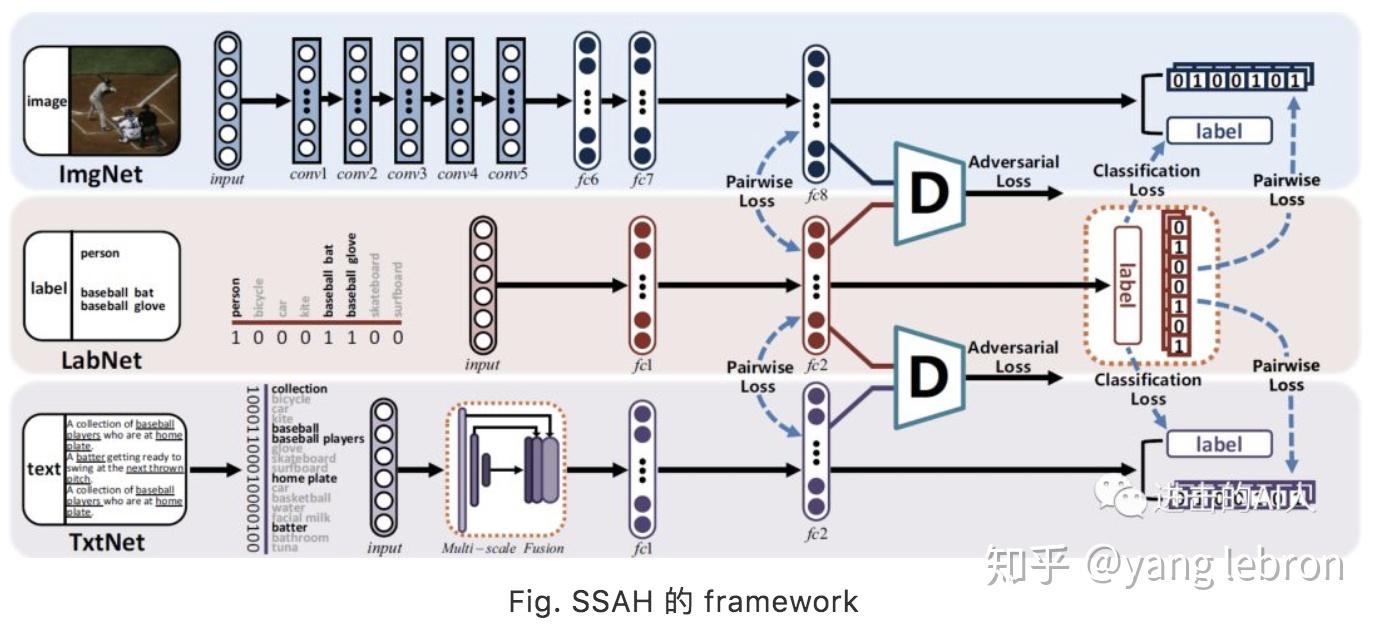
这个也是 GAN 对抗的思路, 只是多了一个 LabNet,有 2 个对抗模块。因为很多业务数据中,并不存在这个 label(这里是要求一个多标签的 label),所以也不是特别好直接套用。主要思路还是 GAN,所以不多介绍了。
2)除了使用 GAN 来追求公共子空间外,还有一类方法是让双塔都经过一个相同权重的 layer,一般会选择最后一层 FC layer 来共享权重。比如 19 年 CVPR 的文章 DSCMR 就使用了这个方法,结合着多个 loss 的设计也得到了一个不错的效果。
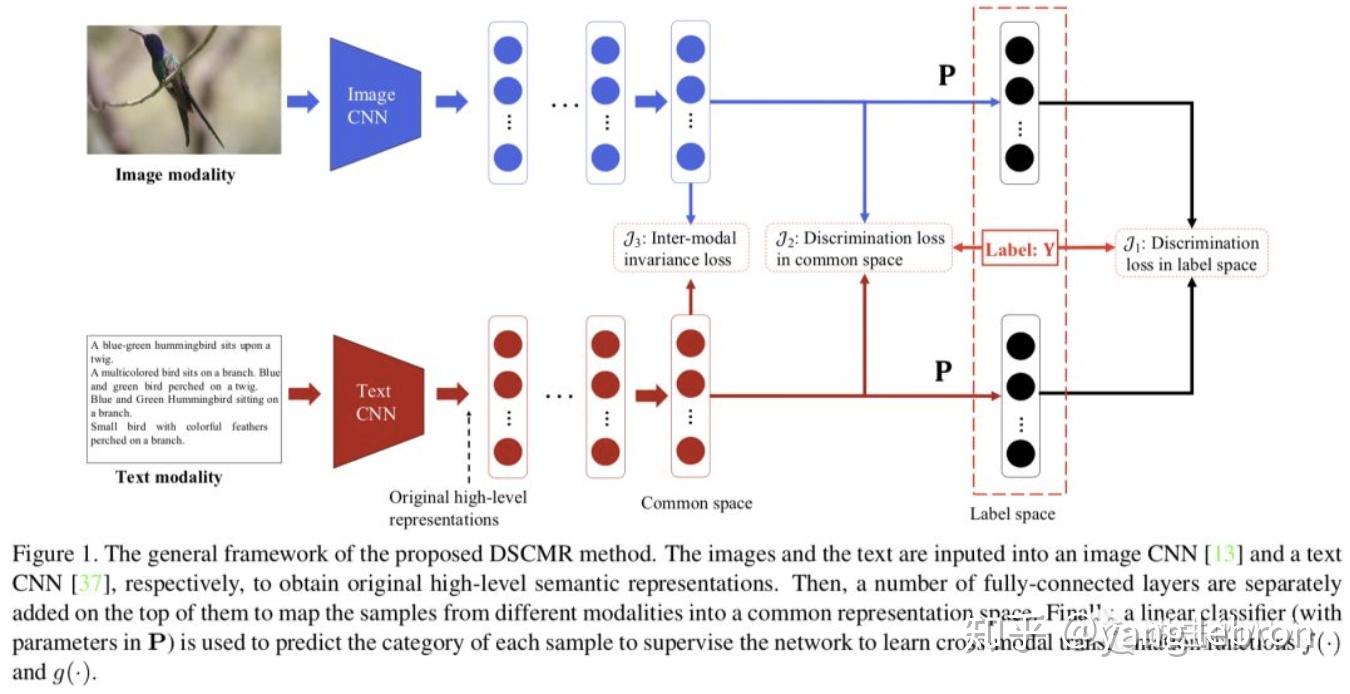
补充一点,共用一个全链接层这个方法,如果 Loss 不做相应的优化设计,很多业务场景中其实没效果。。。
3)让不同模态数据在语义层面融合的更好,这个目标可以拆解成:同模态内部(intro-modal) + 跨模态之间(inter-modal)。同模态内部可以使用模态内数据的 label 来增加一个额外的分类 task 训练,比如图片都有一个 100 类的类别标签。至于跨模态之间的约束,方法就非常多了,比如最通用的 margin-based loss,可以用 pair-wise loss,也可以是 triplet-loss。17 年 MM 的 best paper ACMR 也是在 GAN 基础上用了这 2 点。
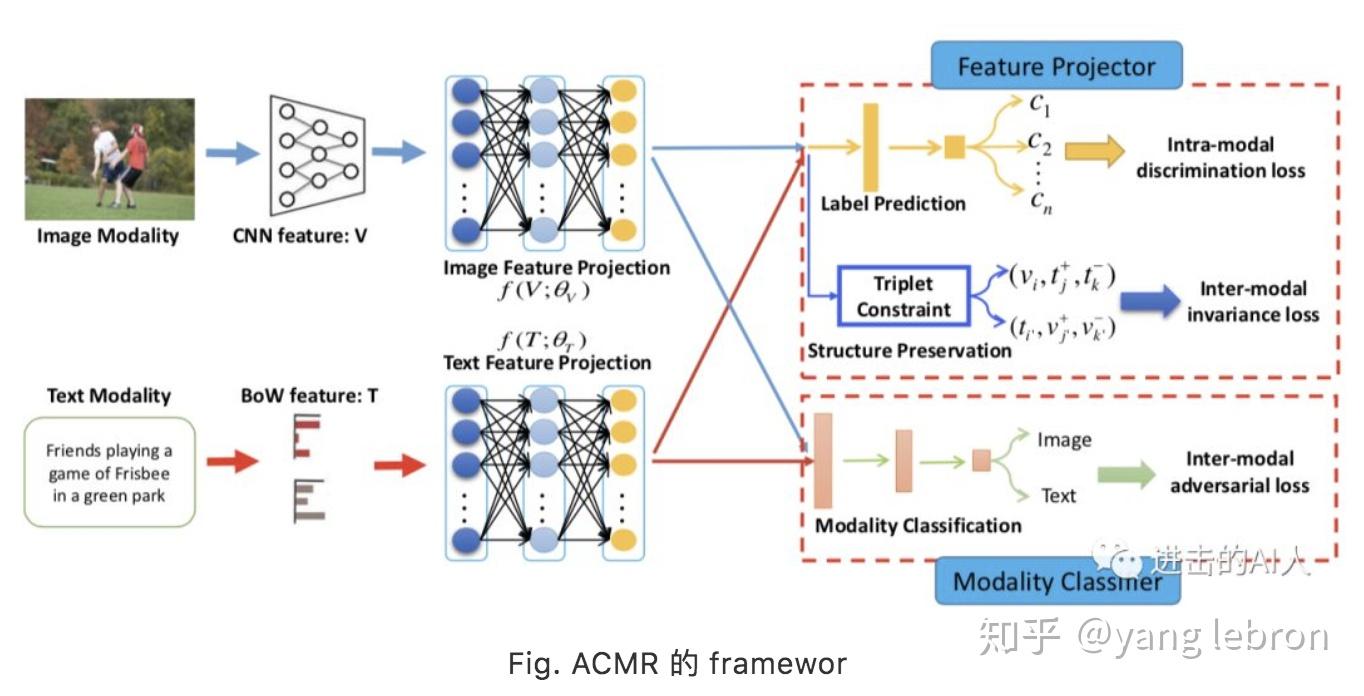
在实际应用时,想补充以下几点。第一点是关于同模态内部的分类 loss。这个实际中,我们都是直接用 pre-trained 模型得到基本特征,所以额外增加这个 loss 基本没有作用,除非 lable 是具有特定的业务特性的。图片和文本的这个 label 体系可以不同,也可以相同。第二点是 GAN 的作用,或者说增加了对抗 Loss 后模型的指标怎么样?如果用 AUC 评估的话,基本没啥提升。用检索指标评估,只能说略有提升吧。。。
我们在实际工作中独立的设计了一个几乎一模一样的模型,后来看到了这篇工作后,也做了对比。我们的模型多了一个 Loss,也更好的利用了 transfer 能力,弱化了这篇文章的个别优化点的影响。所以从一些拆解分析来看,这篇文章提到的个别优化点,在实际工作中都没有什么明显效果。
至于文章用到的 triplet loss,这个不算新东西,在类似任务中几乎每个人都尝试过 triplet Loss、contrastive loss 之类的替代品。本篇不在赘述,将在下篇结合最近很火的无监督表示学习 / contrastive learning 一起详细讨论。
4)还有很多不错的工作,比如 19 年 ICMR 的 TFNH 工作,在 ACMR 的启发下对模型结构做了一些有意思的探索。重点是引入了不成对训练数据,但其实和 ACMR 的模态内部分类 Loss 一样,在运用了 pre-trained 模型后,作用应该不大了。文章思路比较简单,不展开介绍,感兴趣的同学可以自己去搜下 github 代码。
简单小结下:
目前优化思路有 3 类方向:A)利用 GAN 等方法追求公共子空间消除模态差异。B)改进模型结构和增加多任务目标提升模态内部、模态之间的语义同分布能力。C)设计更好的距离 Loss 让模型学习的更充分更高效更准确。这 3 个方向不是互斥的,很多优秀的工作都是同时应用了这 3 点。本专题下一篇会聚焦在 C 方向介绍。
你好,我最近也是在一直看这个方向,有时间可以一起交流吗
你好,可以的,有问题可以交流~
赞楼主,关注了,另外可以推荐一些这些知识的论文来源吗?谢谢
多谢。 可以关注下上面那个微信公众号的内容,我一般会在公众号发一些相关资料,目前知乎我不太用。。。
专题 3 啥时候更新呢
已经在公众号上更新了,可以去公众号上查看。 比较忙,所以等有时间才会转到知乎上。。。
可否分享点代码?
我自己工作暂时没有开源,不方便分享。 文章提及到一些工作比如 SSAH 等都是有开源代码的,可以从 paper 链接找一下。
好的,大佬多谢多谢
有启发,多谢
Cross-Modal & Metric Learning 跨模态检索专题-3(上)
·前言
专题链接:
Cross-Modal & Metric Learning 跨模态检索专题-1Cross-Modal & Metric Learning 跨模态检索专题-2本专题计划分3个部分共4篇文章介绍图文跨模态检索的一些工作与思考。第一篇将侧重 "multi-modal" 和 "application", 介绍相关概念与研究背景;第二、三篇会侧重"algorithm" 介绍这个方向研究的技术路线,其中第二篇介绍基于 GAN 的追求公共子空间的 cross-modal 检索;第三篇则从 modal 抽象成更一般的 domain,并且将多域扩展到单域,总结分析单/多域匹配问题,主要介绍基于 contrastive learning / instances discrimination的研究思路。
本篇内容删除了我工作中未公开的信息、也删改了与在投 paper 有关的内容,所以有些地方只能"点到为止"。虽然删减了很多,但是内容实在写的太多了,为了提升速度满足同学催更,所以第3篇拆成上、下两篇发出。
本文脉络
- (上篇)无监督表示学习与Instances discrimination
- (上篇)问题的一般抽象
- (上篇)采样的各种花式组合
- (下篇)配合采样的各类 Loss 函数
01
—
无监督表示学习 & Instance discrimination
前两篇我们基于图、文这两种模态信号进行了一些介绍,所介绍的一些方法和思路都是通用的技术路线,并没有涉及模态信号本身的特性。本篇将"跨模态"(cross-modal)这个概念进一步泛化,首先引申到"跨域"(cross-domain),接着更进一步在"跨个体" instance 级别来进一步介绍基于模型 Loss 设计的这一类优化方法。
从跨模态到跨域是指,检索和被检索的两个信号,可能都是同一个模态的数据,比如都是图片、都是文字、或者同为语音等等,只不过这2个 domian 的样本可能是具有不同的人工定义,比如关键词到文章的检索,虽然都是文本信号,但是一个是较短的 query,一个是很长的 document。
"跨个体"并不是一个成文的叫法,我们还是用"instance discrimination"来代指这一类吧。这类方向研究的问题相当于是个体到个体的检索,举个并不恰当的例子:输入一个词"开心",能够检索出"高兴";给一张老虎头部的图片,能够知道这是代表老虎,是和另一张老虎尾巴的图片是一类的。总之 instance discrimination 可以认为是同域内的样本检索。
无监督表示学习一直是当前研究的热点,尤其从去年开始,何凯明的 MOCO 放出后,我们又看到了 Hinton的相关工作 SimCLR, 近期何凯明又推出了 MOCO2. 一下子把 contrastive learning 推到了一个新的热度。而这些工作所研究的问题就是我们这儿说的 instance discrimination。只不过他们是加了无监督这一限制。
按我个人的理解简单归纳了这类研究的本质,可以用3句话概括:
『 我是谁?我和谁有关?关系如何?』
只要回答了这灵魂三问,就算是弄明白了 instance discrimination 研究的本质了。我们还是以检索系统为例,考虑一个简单的任务:输入一个 query 文本比如"惊喜",然后召回最相关的 top 3的文本结果。 那么我们首先得弄明白"什么叫惊喜",即第一个问题『我是谁』。
知道了我(惊喜)是谁后,第二个问题是我和谁有关?就是说我们要知道有哪些词和惊喜有关。接着想要返回 top 3的结果,还要回答好第三个问题,即关系如何,怎样就能算是 top 3 ?

上面3个问题,不同场景下我们可以采用不同方法来解决,比如可以使用 HSV 、Gabor等特征(feature)来表示一个图片样本(instance);也可以使用12345这样的 id 值来代表一首歌曲样本;可以用id 数字的差异位数来表示两个歌曲样本的关系...更一般的情况,我们会使用一个 embedding 向量来表示这个样本,然后利用向量间的距离或夹角来表示样本间的关系。这类研究所属的范畴可以是 metric learning、contrastive learning 等等。
上面那个"惊喜"的例子,是不是感觉好像很适合 word2vec ?没错,word2vec 就是很经典的 NLP 领域的无监督表示学习,能够根据样本 vector 的分布,描述这个样本的意义以及和周围哪些词类似。在图片任务中也一样,比如 imageNet 1K 的数据集,给一张猫的图片,首先得知道这是猫,然后要知道还有哪些图片也是猫,最后这些猫中,哪几个和给定的猫最相似。

NLP 中无监督的数据集是很容易得到的,比如百度百科、维基百科的所有词条可以作为中文/英文语料。在图像领域,无监督的数据,往往不是那么容易得到的。这个"往往"是指经典的分类、检测、分割这些任务,但是最近就分类任务而言,也逐渐的产生了一个无监督的潮流比如 MOCO 等。图片的无监督数据获得常用的有上图的几个方法:彩色图转灰度图(用于自动上色任务)、图片加噪声(可用于重建)、图片抠掉一些像素(可用于 inpainting)、随机crop 旋转翻折色彩变换等(可用于图片理解、分类)。这些方法不像 NLP 中的那么自然,大多数是根据实际的任务来选择的,一般而言 crop 这一类方法效果最好、能应用的范围也最广。
02
—
问题的一般抽象
经过上面的介绍,我们已经知道了 instance discrimination 可以用于以下几类问题研究:1)单个样本信号的自我辩识(我是谁?如分类问题);2)单个模态内部的样本间匹配检索,如用字数较少的 keyword 去检索出字数较多的段落 sentences;3)不同模态之间的检索召回问题。
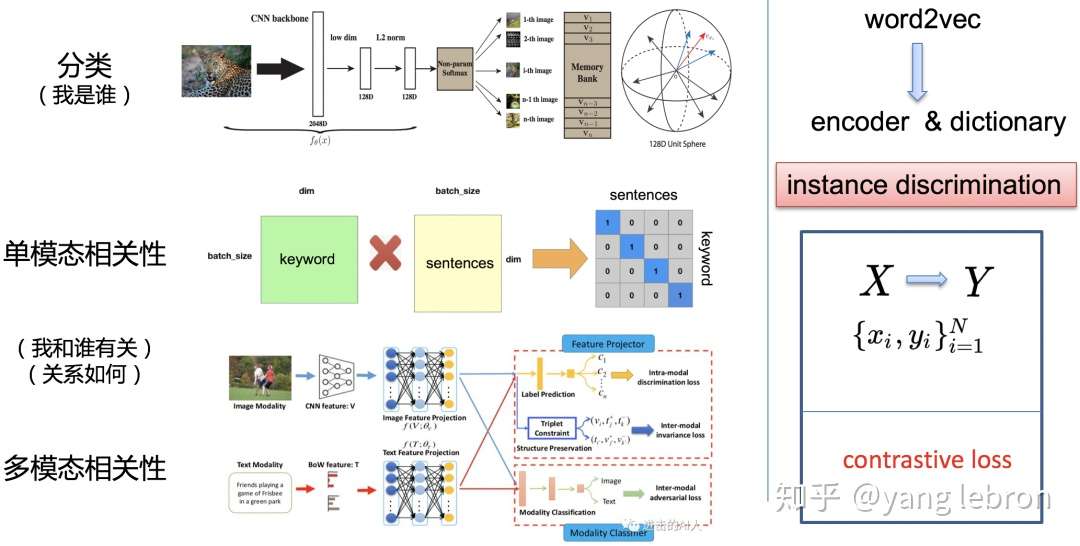
近期的 instance discrimination 研究更多的是应用在第一类问题,因为大家都很热衷挑战无监督的这一限定。上面3类问题"本质上"都是一样的,我们可以从这些任务中,抽象出更一般的数学表达。还是以 word2vec 为例,instance discrimination 简单的说就是要找到一个编码器 encoder(通常用于连续信号或不可枚举信号) 或者说一个词典 dictionary(比如离散输入的一个词语,类似一组基的集合可以是完备或者过完备的)来对我们要研究的信号进行编码后输出 embedding 向量。
这类问题目前聚焦在用 contrastive learning 来解决。用数学表达就是,两个信号集合 X 和 Y(Y 也可以是 X 本身),给定 X 中一个 ,现在从 Y 中找到对应的
则为正样本,和
一起构成一个正样本 pair;其他不相关的 y 则属于负样本。我们通过这个规则,可以构造出N个样本组合
。这些样本组合就是我们的训练数据。比如图片分类任务中,这个
可以是一张图片的一个 random crop,正样本
可以是这张图片的另一个 crop,也可以是同类别的其他图片。其他类别不相关的图片及其变形则为负样本 y。
有了训练数据后,再构造一个 Loss 函数,拉近 和相关的
正样本对之间(准确的说是X 和 Y经过网络后顶层的 embedding 之间)的度量距离,拉远不相关的负样本对的度量距离,这样一个contrastive learning 的框架就完成了。前面这个 loss 关注的度量距离,所以显然是为了解决"我和谁有关?关系如何?"这2个问题。如果只是一个"我是谁?"的任务, Loss 也可以直接对 embedding判断是哪一个类别,产生概率分布。
继续考虑,样本对只能是<X,Y>这样的的2元组吗?
很显然可以不是2元组,现在 metric learning 已经研究的很多了,关于如何构造样本 pair,以及上面说的度量距离如何设计等这些问题都有很多经典工作。我这里一会用 contrastive learning 一会又用 metric learning 目的就是让大家知道在本篇讨论的范畴内,这些都是指一个概念。
这类问题的核心套路就是,构造<X,Y>的样本组合采样,再定义一个距离如 cosine,然后配组合采样方式选择合适的 Loss 函数来更新模型。比如组合采样是 <X,Y> 2元组,Loss 则可以用 contrastive loss 或者cross entropy。组合采样是 <X,Y+,Y-> 这样的一个anchor 和一正一负的3元组,则 loss 可以用 triplet loss。组合采样是 <X,Y1,Y2,...,Yn> 的一正 N 负的结构,则 Loss 可以用 softmax。当然特定任务中还可以设计 N 正 M 负的组合, 甚至也可以加入对 X 的组合比如 loss 里同时考虑同模态内部两个 X 样本的距离,这些非常重要,但是我们暂不讨论。
那么上面这些方式,那个效果更好呢?
一般任务而言,或者说理论而言,当我们对一个正样本采样到越多的负样本,模型效果会更好。关于这个理论其实就是互信息量 mutual information estimation,这个会在下面的小节中简单推导介绍。补充2点:1)不同任务,可能会存在不同的结论;2)模型效果好坏的标准,不能仅仅看 AUC,有的2元组 loss 天然有利于auc。
简单归纳下当前 contrastive learning 的核心就是研究下面2个问题:

从大家的研究方向来看,还是倾向于增加大量负样本采样,同时配合一些常规的类似 无参softmax 或者negative log-likehood 函数当做 Loss 即可。下面就简单介绍下一些经典采样组合和 loss 设计。
03
—
采样的各种花式组合
上一小节已经提到了构造组合时可以有多种采样方式,本小节挑选经典的几个结构介绍下研究脉络。
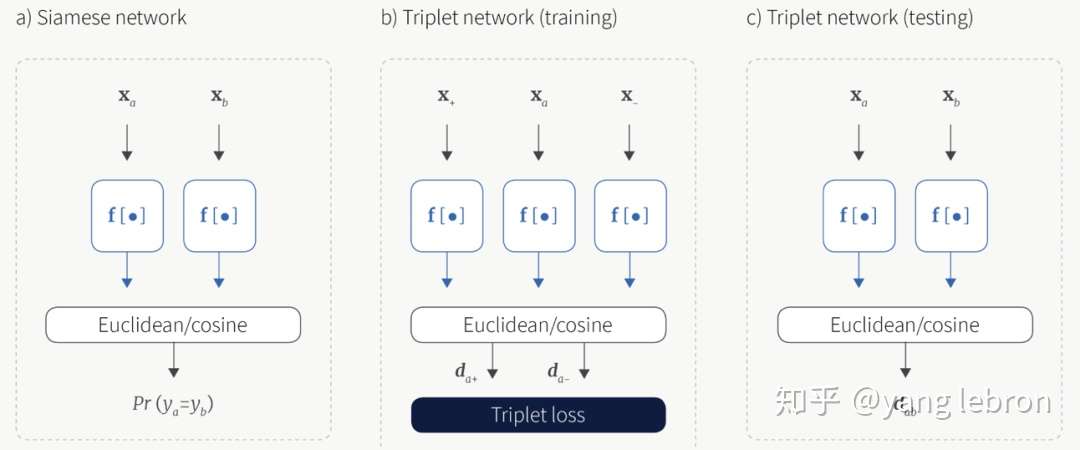
最常用的采样组合就是上图这2种了,即二元组和三元组。二元组的数据通常都是提前组合好的,比如在图文相关性任务中,可以搜集一系列相关的图文二元组,和随机交叉的一系列不相关的图文二元组。而对于三元组这种采样组合,大多数场景还是输入的 <anchor,positive> 二元组当做训练数据,然后在一个 batch size 内寻找一个 negative 的 样本来构成<anchor, pos,neg> 三元组。这种 batch 内构造 triplet pair 有多种方法,可以随机,可以挑选距离最近的等等,网上有很多成熟的开源代码。
这里提前补充下,二元组的方式由于可以提前构造负样本,所以这种情况下,可以很方便的实现 hard negative mining 和 fine-tuning,只要把额外的难分样本 pair 和需要微调的样本 pair 加入训练数据即可。 而对于三元组组合,虽然也可以直接加到训练样本里(这是因为我们实际输入的就是二元组 pair),但是要清楚实际上我们在 batch 内部仅仅对<anchor,pos>进行了构造,而无法对<anchor, neg>构造3元组。无法直接在训练数据中增加指定的负例样本的问题,在下面的几个组合采样中会更明显。
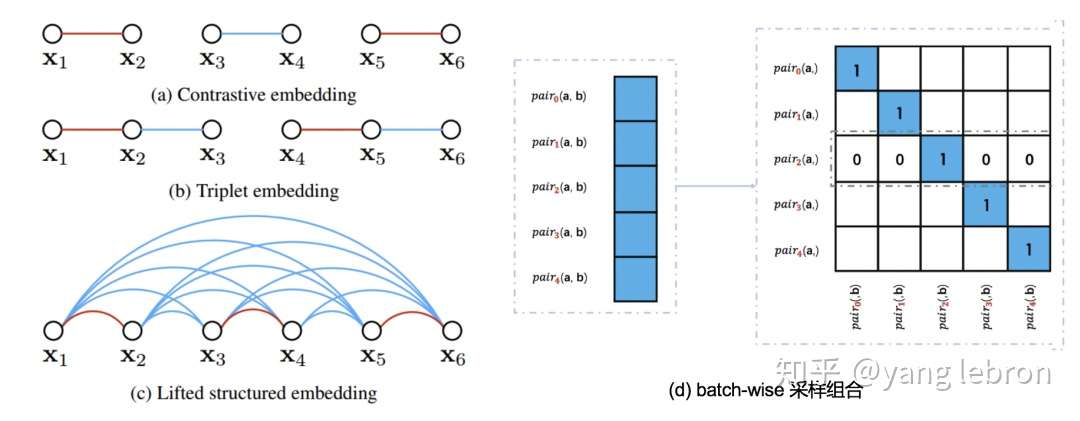
上图中 contrastive embedding 和 tripet embedding 就是分别指二元组和三元组的组合方式。除此外,还有一个比较花哨的复杂组合(c) Lifted structured,这个采样组合里,同时考虑了跨域关系和同域内各样本关系。下一节会结合它的 loss 再介绍,这里我们知道组合可以多种多样就行,大胆的设计,只要有道理就可以,不要局限于跨域或者有限的pair。
lifted structured 的组合方式有点过于复杂,对训练数据要求也很高,因此很多场景下都不适用。目前大家研究的主流还是上图(d)这种在一个 batch-size 数据内部,对每一个输入正例 pair(a,b),充分交叉组合,得到所有叉乘的负例组合,i.e. , <a1,b1>是正例输入那么交叉后<a1,b2>就是不相关的负例组合。这里的交叉可以是 cosine 距离,也可以是内积,内积的方式更简单,计算量和代码都容易一点。当然如果对 embedding 做归一化,那么 cosine 就等于内积。
我们可以看到 batch-wise 这种采样组合方式的目的是获得更多的负样本组合。那么也就是说,batch-size 越大,模型效果越好,是这样吗? 还有,如果负样本组合越多,效果越好,是不是可以更大胆一点,做一个 beyond batch 的采样,把其他历史的 batch 内数据也拿到本次 batch 中进行交叉组合?
这里就有2个问题:A)是不是负样本越多越好?B)如果是,怎么构造出更多的负样本组合?
问题A其实上一个小节中已经给出答案了,从实际实验效果来看,一定范围内增大batch-size 可以提升效果,通过 beyond batch 的方式获得更多负例,也会提升效果。下一小节,在介绍对应的 Loss 函数时,我们再从互信息量的角度去给出数学推导。本小节我们先看下怎么获得更多的负例组合。
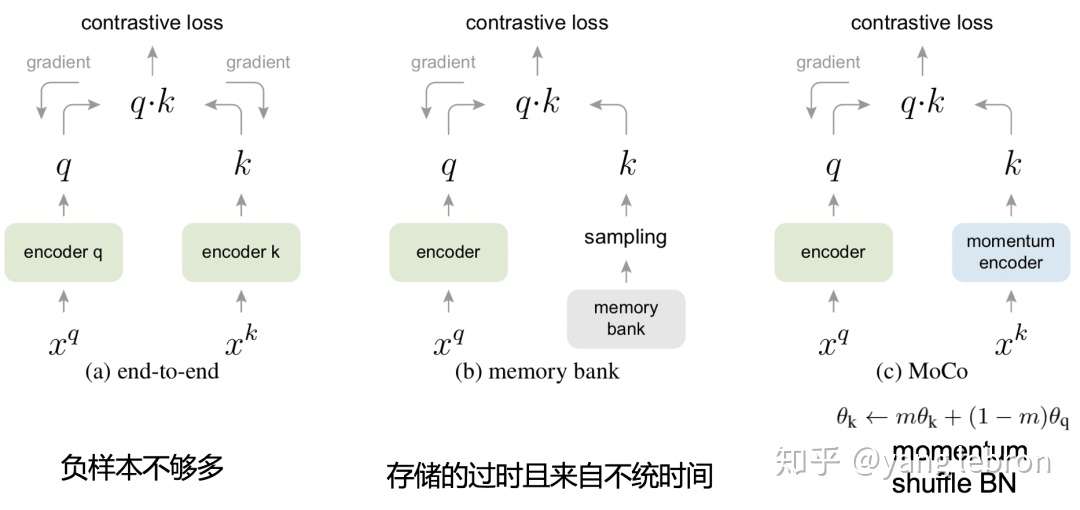
像上图(d)中在一个 batch 内部,将所有 pair 充分交叉可以获得大量的负样本,这种方式只使用了一个 batch 内的数据,无法运用其他 batch 的数据。因此想要增加负样本数,就只能增大 batch-size,但是随着 batch-size 的增大,会带来2个问题,一个是 GPU 显存不够,一个是超大 batch-size 优化问题(太大时很难训练优化)。我们称这种方式为end-to-end 的模式,因为这样每次梯度更新的时候都会把对应batch 内的 embedding都更新一下,如下图(a)所示。
上图中的 和
,就是我们输入的一个 pair,即<X,Y>,分别通过编码器 encoder 后(两个 encoder 可以是一样,也可以不一样)得到其表示学习的顶层 embedding:q, k. 再利用 q,k 计算一个 loss 来反向更新参数。上图(a)的模式就是代表着前文说的 batch-wise 采样,是通过反向传播对计算查询和键的表征进行端到端更新,所以很优雅,但是负样本还是不够,毕竟一个 batch 内数量是有限的。
于是在18年的 CVPR 中,Wu 等人提出了上图(b)这种采样模式,即使用一个 memory bank 机制。简单的说就是维护一个很大的池子,把历史的一些 batch 数据存下来,然后只有被采样到 K 才会更新。这个模式的好处是,极大的扩大负样本的空间,但是问题是这样存储的编码 k 都是过时的(不是每个K都更新),且来自不同时间的(被采样的批次不同,被更新的时间也就不同)。
最近凯明大神的 MoCo 问世后,引起了很大的关注。上图(c)这个模式就是 Moco(Momentum Contrast),这个模式则是通过基于动量更新的编码器对键进行动态编码,并维持键的队列。其实这个思路在强化学习里就有。再提一下MoCo中还有一个比较重要的点是 shuffle BN。
上面的 memory bank 和 MoCo 没有讲太多,感兴趣的同学可以读下 MoCo 的文章,比较清晰易懂的。我们这里只要了解到这种采样方式即可。看下实验的对比结果:
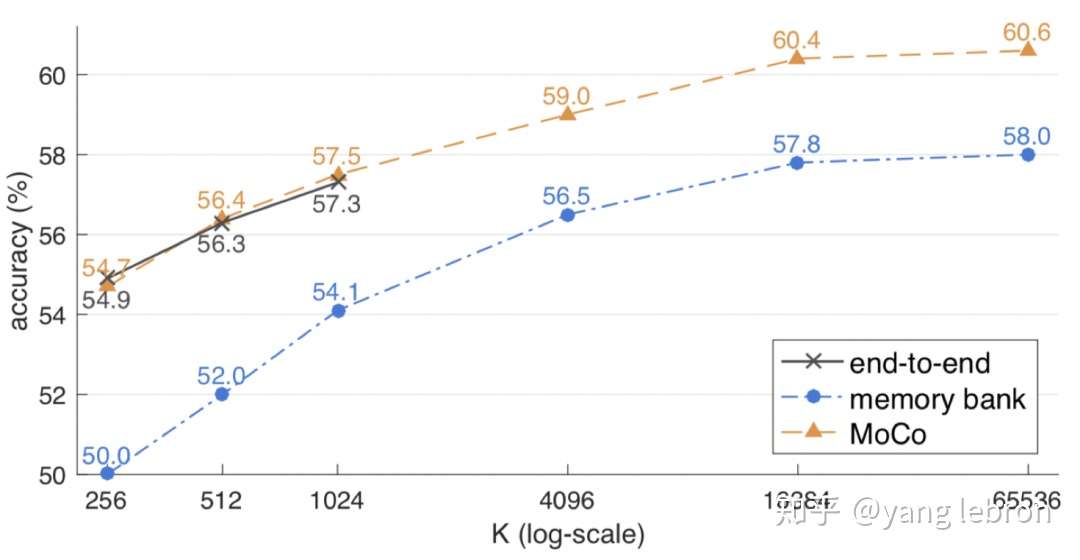
从上图实验比较来看,当 负样本个数 K 较小时,一个 batch 能存下时,end-to-end 的效果和 MoCo 的差不多,都要远好于 memory bank。而随着 K 增大,MoCo 的效果也在逐渐变好,不过到65536左右,逐渐开始收敛了,提升空间不大了。这里个人理解是,当负样本多到一定程度,再增加负样本都是一些不重要的信息了,用 SVM 的定义来理解就是这时候,需要的是难分样本,再增加非边界样本,意义不大。这里又不得不提二元组的优势了,可以直接在样本中增加重要的负例。
前面提到的构造样本对时,以图片理解为例,正样本一般就是crop、mirror 等等常规的 data augmentation。这种方式得到的正样本变化还是不够充分,这里介绍一个最近看的工作,Watching the World Go By:Representation Learning from Unlabeled Videos,(https://arxiv.org/pdf/2003.07990.pdf)看视频理解世界。
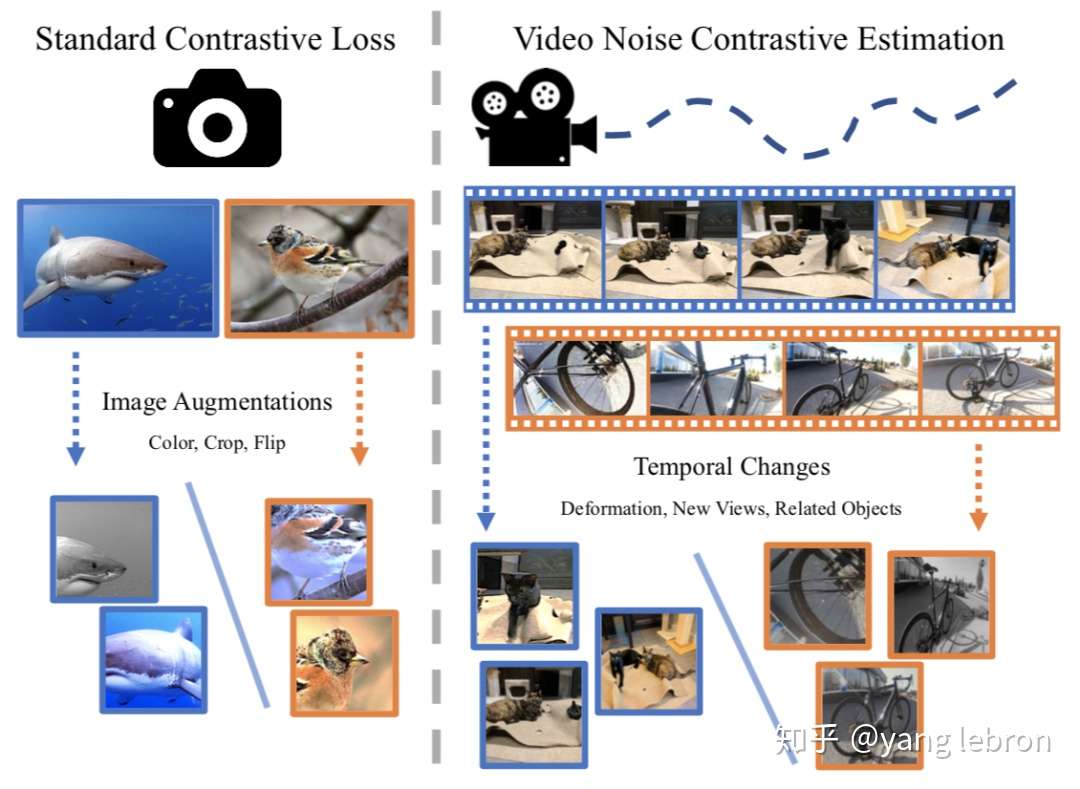
简单的说就是把视频多帧信息利用起来,这样一个物体的多个视角都能当做 augmentation 了。同理,多了 time 这一维度,采样也可以再上升一个级别:
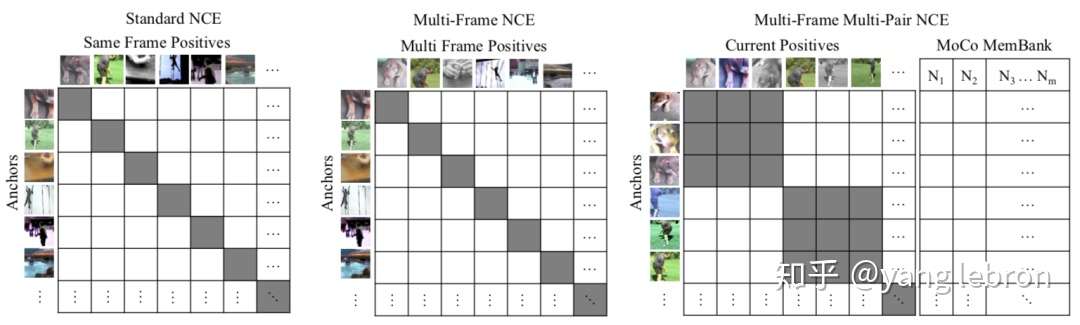
本小节介绍了各种采样组合,从原始的简单二元组,到最后复杂的视频版 NCE。大家需要了解脉络即可,同时也要辨别实际工作中哪个才是最合适的。可以明确的说,memory bank, MoCo, video-wise这些新模式大多数场景中没啥性价比可言。。。实际工作中,应该更多的重视 batch-wise 的采样方式。
04
—
配合采样的各类 Loss 函数
第3小节介绍了很多采样组合方式,本小节将介绍这些经典的采样可使用的 Loss 函数,同时会从互信息量的角度介绍为什么要增加负样本采样数量。
详见下篇~
推荐阅读
小样本学习(Few-shot Learning)综述
ACL2020 | 香侬科技提出使用Dice Loss缓解数据集数据不平衡问题
标注样本少怎么办?「文本增强+半监督学习」总结(从PseudoLabel到UDA/FixMatch)
ICML(2020)自然语言处理(NLP)论文汇总
本文整理了ICML2020关于NLP的论文,没想到ICML的NLP文章居然有这么多= =。没有链接的是还没有放出来的论文,有遗漏或错误欢迎指正。 机器翻译:Aligned Cross Entropy for Non-Autoregressi…
Cross-Modal & Metric Learning 跨模态检索专题-1
Cross-Modal & Metric Learning 跨模态检索专题-2
Cross-Modal & Metric Learning 跨模态检索专题-3(上)

5 条评论
请问Fig.两种研究方向的一些代表工作中Matching Function Learning那个图是出自那篇论文呢,谢谢
我也在找,请问你找到了吗
搜一下 Deep Fragment