GCN、GAT、GraphSAGE 的优势很明显,想问一下它们分别有什么缺点?

dongZheX
回答你第一个问题。
gcn 增加深度会降低模型效果主要是因为过度平滑的问题。
现在解决这个问题的方法主要就是 skip-connection 的方法,其中包括你说的残差网络。这方面推荐你几篇论文:
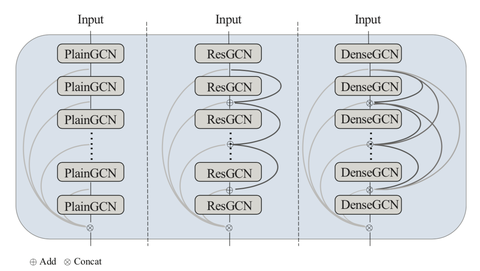
1.DeepGCNs: Can GCNs Gobas Deep as CNNs? 这篇论文主要讨论了 GCN 的深度问题,文中才用了 ResGCN,DenseGCN 和 Dilation 等方法,最后效果比较明显。网络层数可以达到 56 层,并且有 3.7 个点的提升。
2.Deep insights into Graph Convolution Networks for Semi-supervised Learning. 这篇论文只看前面对于过度平滑的分析即可。
3.Representation learning on graphs with jumping knowledge networks. 这篇论文建立一个相对比较深的网络,在网络的最后当一个层聚合器来从所有层的输出中进行选择,来抑制 noise information 的问题。
对于你的第二个问题:
1.GCN 的缺点在于它灵活性差,transductive,并且扩展性非常差,除此之外这篇论文借助验证集来早停帮助性能提升,跟它半监督学习的初中有点相悖。
如何理解 inductive learning 与 transductive learning?6 个回答NTU Machine Learning PhD
实际上我们平时所说的learning一般指的是inductive learning。 考虑普通学习问题,训练集为 半监督学习的情况,训练集为 如果我们不管 简单来说,transductive和inductive的区别在于我们想要预测的样本,是不是我们在训练的时候已经见(用)过的。 通常transductive比inductive的效果要好,因为inductive需要从训练generalize到测试。 Transductive learning:unlabelled data is the testing data inductive learning:unlabelled data is not the testing data 在训练过程中,已知testing data(unlabelled data)是transductive learing 在训练过程中,并不知道testing data ,训练好模型后去解决未知的testing data 是inductive learing 埋头苦干是第一

现在有这个问题,已知ABC的类别,求问号的类别, inductive learning就是只根据现有的ABC,用比如kNN距离算法来预测,在来一个新的数据的时候,还是只根据5个ABC来预测。 transductive learning直接以某种算法观察出数据的分布,这里呈现三个cluster,就根据cluster判定,不会建立一个预测的模型,如果一个新的数据加进来 就必须重新算一遍整个算法,新加的数据也会导致旧的已预测问号的结果改变, 摘自wiki Semi-supervised scenarios where the label of some of the nodes of the same graph as the graph in training is missing (Transductive) and in the scenario that the test is on a completely new graph (Inductive). 匿名用户
和
两位的答案已经非常好了,再做一个总结与补充,有不对的地方希望指正。
通俗地来说inductive learning是特殊到一般的学习,测试数据只是用来测试这个通用模型的好坏;transductive learning是特殊到特殊的学习,目的就是解决target domain的问题。 分类的分法有很多种,如果把半监督学习,即有未标注数据参与训练的学习,分为inductive learning 和 transductive learning的话,如果这个未标注数据同时也是测试数据,则是transductive learning;如果这个未标注数据只是用于帮助训练而不用于测试的话,则是inductive learning。 广告
广告
|
|
2.GraphSage 这篇论文旨在提升 gcn 扩展性和改进训练方法缺陷。它将模型目标定于学习一个聚合器而不是为每个节点学习到一个表示,这中思想可以提升模型的灵活性和泛化能力。除此之外,得益于灵活性,它可以分批训练,提升收敛速度。但是它的问题是因为节点采样个数随层数指数增长,会造成模型在 time per batch 上表现很差,弱于 GCN,这方面的详细讨论可以参考 Cluster-GCN 这篇论文。
3.GAT 这篇论文创新之处是加入 attention 机制,给节点之间的边给予重要性,帮助模型学习结构信息。相对的缺点就是训练方式不是很好,其实这个模型可以进一步改,用 attention 做排序来选取采样节点,这样效果和效率方面应该会有提升。
说的可能不准确,欢迎讨论。

Riroaki
关于深层的 GCN 和残差连接,我在周界和刘知远老师的《Introduction to Graph Neural Networks》里看到相关讨论,具体可以看个人的翻译和整理:
Riroaki:图神经网络入门(四)GRN 图残差网络zhuanlan.zhihu.com
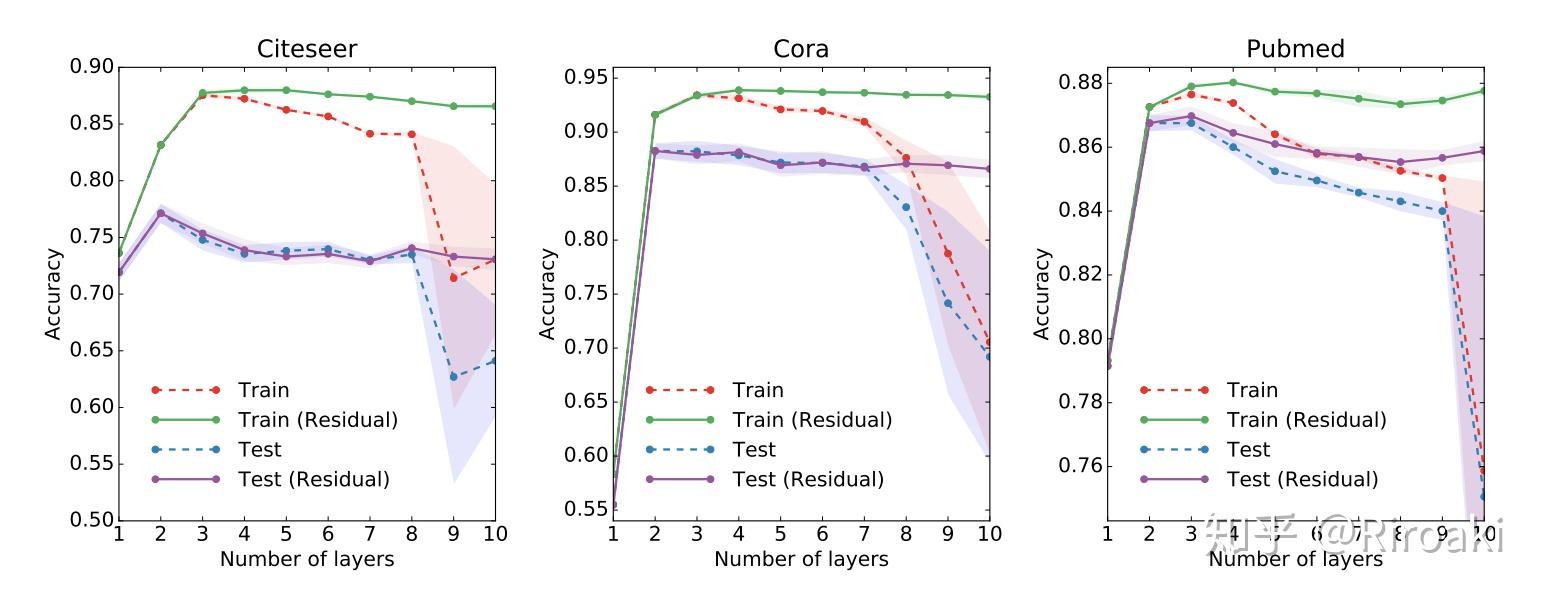
目前有实验证明残差对深层 GCNs 的提升有限,但是确实降低了深层 GCN 网络的训练难度。
目前的残差连接主要有以下几种:
Highway GCN 的层级门控
思路来源是 Highway Netwok,比 ResNet 更早更复杂的残差连接;效果在一定层数后效果不增加(论文中实验为 4 层)。
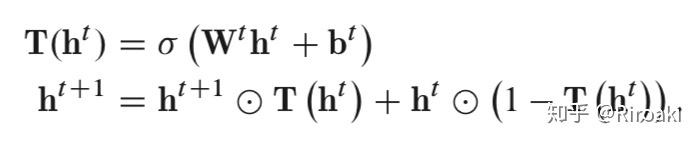
Jump Knowledge Network 的跳跃连接
所有层都可以跳到最后一层并进行聚合(用 GraphSAGE 的聚合方法),让节点自适应选择感受域大小。这一模型思路简单,表现不错。
DeepGCNs 的残差连接和空洞卷积
引入了 ResNet 的残差连接、DenseNet 的前后全连接和空洞卷积(究极缝合怪),网络层数可达数十层。理论上空洞卷积(dilated convolution)解决了过度平滑的问题,具体操作为对当前节点按预定义的度量排序得到的邻居节点列表有间隔的采样。
关于 GCN 和 GAT 的一些内容可以参考同样是本人翻译整理的内容:
Riroaki:图神经网络入门(一)GCN 图卷积网络zhuanlan.zhihu.com
Riroaki:图神经网络入门(三)GAT 图注意力网络zhuanlan.zhihu.com

zjwreal
GCN:训练是 full-batch 的,难以扩展到大规模网络,并且收敛较慢;
GAT:参数量比 GCN 多,也是 full-batch 训练;只用到 1-hop 的邻居,没有利用高阶邻居,当利用 2 阶以上邻居,容易发生过度平滑(over-smoothing);
GraphSAGE:虽然支持 mini-batch 方式训练,但是训练较慢,固定邻居数目的 node-wise 采样,精度和效率较低。

全大葱
AAAI20 合肥工业大学吴乐老师课题组发的一篇 paper《Revisiting Graph based Collaborative Filtering 》的文章说了。虽然是用于推荐的,但我觉得对整个图的工作有一定参考意义。第一,非线性导致 gcn 不能 train 太深。第二,拉普拉斯平滑导致图网络层数太深会使得节点失去自身的特性。
所以,paper 中利用线性变换和残差的方式来让图卷积在基于协同过滤的推荐这个场景下结果更好。实验发现,去掉非线性后,模型迭代的层数可以更深(当然,基本也就是从 d=2 变成了 3)。这篇 paper 挺好懂的,虽然 idea 不是说什么很厉害的创新点,但参考价值和分析非常值得学习。希望对你有帮助。
我觉得 gcn 和 gat 这两个模型挺有意思,一个考虑了图空间的关系(概率传导矩阵)但没办法动态学习邻居权重。一个动态学习邻居权重,但忽略了节点之间本身存在的关系。虽然有些工作在算 attention 的时候把两个 node 之间的 weight 作为额外的一维特征,但我觉得应该有更聪明的办法把两种关系合理结合

南桥
缺点是相对的。GCN 先出现的,GraphSAGE 和 GAT 的出现都是为了解决 GCN 的某些缺点,比如原始的 GCN 是 inductive 而不是 transductive 的,并且训练成本相对要高。
其他缺点的话,比如这三种模型针对的图结构都是 homogeneous 的,也就是只有同一种节点和连边,如果是异质网络(heterogeneous)则不能直接处理。能解决的任务目前来说主要是通过 embedding 做节点分类和连边预测,图上的优化问题等其他任务则尚未看到可以应用。

蔡少斐
GCN 和 GraphSAGE 均是各向同性的网络结构,某些情况下学习表示的能力较差一些,只能用于无向图。而 GAT 是各向异性的,考虑了各个邻居节点的权重,可以用于有向图。
GCN 和 GAT 在最开始被提出来的时候,是不考虑自身节点信息的,因此性能比较差,后来人们对图矩阵增加自环的方式来一定程度上缓解这个问题。而 GraphSAGE 被设计出来就考虑了节点本身的信息。
BenchmarkGNN 文章在各个任务上对这几种方法进行了比较,GCN 是性能最差的,GAT 性能介于中间,GraphSAGE 性能较好。另外 GCN 和 GAT 均可以使用残差连接的方式来提升性能。
最后谈一点,即便使用了残差连接,GCN 也不可能做的太深,基本就是 3-5 层左右的样子。这是因为 GCN 可以被看作低通滤波器,叠加低通滤波器具有明显的过度平滑现象。如果想要做的更深,可以考虑一下 DropEdge 的方法,通过在训练过程中随机扔掉一些边来缓解过度平滑的现象,这种方法最近被证明是有效的。