▶ 书上第二章,用一系列步骤优化梯度下降法解线性方程组。才发现 PGI community 编译器不支持 Windows 下的 C++ 编译(有 pgCC 命令但是不支持 .cpp 文件,要专业版才支持),以后 OpenACC - C++ 全盘转向 Ubuntu 中。
● 代码
1 // matrix.h 2 #pragma once 3 #include <cstdlib> 4 5 struct matrix 6 { 7 unsigned int num_rows; 8 unsigned int nnz; 9 unsigned int *row_offsets; 10 unsigned int *cols; 11 double *coefs; 12 }; 13 14 void allocate_3d_poission_matrix(matrix &A, int N) 15 { 16 const int num_rows = (N + 1) * (N + 1) * (N + 1); 17 A.num_rows = num_rows; 18 A.row_offsets = (unsigned int*)malloc((num_rows + 1) * sizeof(unsigned int)); 19 A.cols = (unsigned int*)malloc(27 * num_rows * sizeof(unsigned int)); 20 A.coefs = (double*)malloc(27 * num_rows * sizeof(double)); 21 22 const int ystride = N, zstride = N * N; 23 int i, j, n, nnz, offsets[27]; 24 double coefs[27]; 25 26 i = 0; 27 for (int z = -1; z <= 1; z++) 28 { 29 for (int y = -1; y <= 1; y++) 30 { 31 for (int x = -1; x <= 1; x++) 32 { 33 offsets[i] = zstride * z + ystride * y + x; 34 if (x == 0 && y == 0 && z == 0) 35 coefs[i] = 27; 36 else 37 coefs[i] = -1; 38 i++; 39 } 40 } 41 } 42 nnz = 0; 43 for (i = 0; i < num_rows; i++) 44 { 45 A.row_offsets[i] = nnz; 46 for (j = 0; j < 27; j++) 47 { 48 n = i + offsets[j]; 49 if (n >= 0 && n<num_rows) 50 { 51 A.cols[nnz] = n; 52 A.coefs[nnz] = coefs[j]; 53 nnz++; 54 } 55 } 56 } 57 A.row_offsets[num_rows] = nnz; 58 A.nnz = nnz; 59 } 60 61 void free_matrix(matrix &A) 62 { 63 unsigned int *row_offsets = A.row_offsets, *cols = A.cols; 64 double *coefs = A.coefs; 65 free(row_offsets); 66 free(cols); 67 free(coefs); 68 }
1 // matrix_function.h 2 #pragma once 3 #include "vector.h" 4 #include "matrix.h" 5 6 void matvec(const matrix& A, const vector& x, const vector &y) 7 { 8 9 const unsigned int num_rows = A.num_rows; 10 unsigned int *row_offsets = A.row_offsets, *cols = A.cols; 11 double *Acoefs = A.coefs, *xcoefs = x.coefs, *ycoefs = y.coefs; 12 13 for (int i = 0; i < num_rows; i++) 14 { 15 const int row_start = row_offsets[i], row_end = row_offsets[i + 1]; 16 double sum = 0; 17 for (int j = row_start; j < row_end; j++) 18 sum += Acoefs[j] * xcoefs[cols[j]]; 19 ycoefs[i] = sum; 20 } 21 }
1 // vector.h 2 #pragma once 3 #include<cstdlib> 4 #include<cmath> 5 6 struct vector 7 { 8 unsigned int n; 9 double *coefs; 10 }; 11 12 void allocate_vector(vector &v, const unsigned int n) 13 { 14 v.n = n; 15 v.coefs = (double*)malloc(n * sizeof(double)); 16 } 17 18 void free_vector(vector &v) 19 { 20 v.n = 0; 21 free(v.coefs); 22 } 23 24 void initialize_vector(vector &v, const double val) 25 { 26 for (int i = 0; i < v.n; i++) 27 v.coefs[i] = val; 28 }
1 // vector_function.h 2 #pragma once 3 #include<cstdlib> 4 #include "vector.h" 5 6 double dot(const vector& x, const vector& y) 7 { 8 const unsigned int n = x.n; 9 double sum = 0, *xcoefs = x.coefs, *ycoefs = y.coefs; 10 11 for (int i = 0; i < n; i++) 12 sum += xcoefs[i] * ycoefs[i]; 13 return sum; 14 } 15 16 void waxpby(double alpha, const vector &x, double beta, const vector &y, const vector& w) 17 { 18 const unsigned int n = x.n; 19 double *xcoefs = x.coefs, *ycoefs = y.coefs, *wcoefs = w.coefs; 20 21 for (int i = 0; i < n; i++) 22 wcoefs[i] = alpha * xcoefs[i] + beta * ycoefs[i]; 23 }
1 // main.cpp 2 #include <cstdlib> 3 #include <cstdio> 4 #include <chrono> 5 6 #include "vector.h" 7 #include "vector_functions.h" 8 #include "matrix.h" 9 #include "matrix_functions.h" 10 11 using namespace std::chrono; 12 13 #define N 200 14 #define MAX_ITERS 100 15 #define TOL 1e-12 16 17 int main() 18 { 19 int iter; 20 double normr, rtrans, oldtrans, alpha; 21 vector x, p, Ap, b, r; 22 matrix A; 23 high_resolution_clock::time_point t1, t2; 24 25 allocate_3d_poission_matrix(A, N); 26 allocate_vector(x, A.num_rows); 27 allocate_vector(p, A.num_rows); 28 allocate_vector(Ap, A.num_rows); 29 allocate_vector(b, A.num_rows); 30 allocate_vector(r, A.num_rows); 31 printf("Rows: %d, nnz: %d ", A.num_rows, A.row_offsets[A.num_rows]); 32 33 initialize_vector(x, 100000); 34 initialize_vector(b, 1); 35 36 // 计算一个初始 r 37 waxpby(1.0, x, 0.0, x, p); 38 matvec(A, p, Ap); 39 waxpby(1.0, b, -1.0, Ap, r); 40 rtrans = dot(r, r); 41 normr = sqrt(rtrans); 42 43 t1 = high_resolution_clock::now(); 44 for(iter = 0; iter < MAX_ITERS && normr > TOL; iter++) 45 { 46 // 更新 p 和 rtrans 47 if (iter == 0) 48 waxpby(1.0, r, 0.0, r, p); 49 else 50 { 51 oldtrans = rtrans; 52 rtrans = dot(r, r); 53 waxpby(1.0, r, rtrans / oldtrans, p, p); 54 } 55 56 // 计算步长 alpha,用的是上一次的 rtran 57 matvec(A, p, Ap); 58 alpha = rtrans / dot(Ap, p); 59 normr = sqrt(rtrans); 60 61 // 更新 x 和 r 62 waxpby(1.0, x, alpha, p, x); 63 waxpby(1.0, r, -alpha, Ap, r); 64 65 if (iter % 10 == 0) 66 printf("Iteration: %d, Tolerance: %.4e ", iter, normr); 67 } 68 t2 = high_resolution_clock::now(); 69 duration<double> time = duration_cast<duration<double>>(t2 - t1); 70 printf("Iterarion: %d, error: %e, time: %f s ", iter, normr, time.count()); 71 72 free_matrix(A); 73 free_vector(x); 74 free_vector(p); 75 free_vector(Ap); 76 free_vector(b); 77 free_vector(r); 78 //getchar(); 79 return 0; 80 }
● 输出结果,WSL
// WSL: cuan@CUAN:/mnt/d/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ pgc++ -std=c++11 -acc -fast main.cpp -o acc.exe cuan@CUAN:/mnt/d/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ ./acc.exe Rows: 8120601, nnz: 218535025 Iteration: 0, Tolerance: 4.0067e+08 Iteration: 10, Tolerance: 1.8772e+07 Iteration: 20, Tolerance: 6.4359e+05 Iteration: 30, Tolerance: 2.3202e+04 Iteration: 40, Tolerance: 8.3565e+02 Iteration: 50, Tolerance: 3.0039e+01 Iteration: 60, Tolerance: 1.0764e+00 Iteration: 70, Tolerance: 3.8360e-02 Iteration: 80, Tolerance: 1.3515e-03 Iteration: 90, Tolerance: 4.6209e-05 Iterarion: 100, error: 1.993399e-06, time: 17.065934 s // Ubuntu: cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ pgc++ -std=c++11 -acc -fast -Minfo -ta=tesla main.cpp -o no_acc.exe initialize_vector(vector &, double): 6, include "vector.h" 26, Memory set idiom, loop replaced by call to __c_mset8 dot(const vector &, const vector &): 7, include "vector_functions.h" 11, Generated an alternate version of the loop Generated vector simd code for the loop containing reductions Generated 2 prefetch instructions for the loop Generated vector simd code for the loop containing reductions Generated 2 prefetch instructions for the loop FMA (fused multiply-add) instruction(s) generated waxpby(double, const vector &, double, const vector &, const vector &): 7, include "vector_functions.h" 21, Generated 2 alternate versions of the loop Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed Generated 2 prefetch instructions for the loop Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed Generated 2 prefetch instructions for the loop Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed Generated 2 prefetch instructions for the loop Loop unrolled 4 times FMA (fused multiply-add) instruction(s) generated allocate_3d_poission_matrix(matrix &, int): 8, include "matrix.h" 27, Loop not fused: different loop trip count 29, Loop not vectorized/parallelized: loop count too small 31, Loop unrolled 3 times (completely unrolled) 46, Loop not vectorized: data dependency matvec(const matrix &, const vector &, const vector &): 9, include "matrix_functions.h" 17, Generated an alternate version of the loop Generated vector simd code for the loop containing reductions Generated a prefetch instruction for the loop Generated vector simd code for the loop containing reductions Generated a prefetch instruction for the loop FMA (fused multiply-add) instruction(s) generated main: 23, allocate_3d_poission_matrix(matrix &, int) inlined, size=40 (inline) file main.cpp (15) 27, Loop not fused: different loop trip count 29, Loop not vectorized/parallelized: loop count too small 31, Loop unrolled 3 times (completely unrolled) 43, Loop not fused: function call before adjacent loop 46, Loop not vectorized: data dependency 24, allocate_vector(vector &, unsigned int) inlined, size=3 (inline) file main.cpp (13) 25, allocate_vector(vector &, unsigned int) inlined, size=3 (inline) file main.cpp (13) 26, allocate_vector(vector &, unsigned int) inlined, size=3 (inline) file main.cpp (13) 27, allocate_vector(vector &, unsigned int) inlined, size=3 (inline) file main.cpp (13) 28, allocate_vector(vector &, unsigned int) inlined, size=3 (inline) file main.cpp (13) 31, initialize_vector(vector &, double) inlined, size=5 (inline) file main.cpp (25) 26, Memory set idiom, loop replaced by call to __c_mset8 32, initialize_vector(vector &, double) inlined, size=5 (inline) file main.cpp (25) 26, Memory set idiom, loop replaced by call to __c_mset8 35, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size=10 (inline) file main.cpp (17) 21, Memory copy idiom, loop replaced by call to __c_mcopy8 36, matvec(const matrix &, const vector &, const vector &) inlined, size=17 (inline) file main.cpp (7) 13, Loop not fused: dependence chain to sibling loop 17, Generated an alternate version of the loop Generated vector simd code for the loop containing reductions Generated a prefetch instruction for the loop Generated vector simd code for the loop containing reductions Generated a prefetch instruction for the loop FMA (fused multiply-add) instruction(s) generated 37, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size=10 (inline) file main.cpp (17) 21, Loop not fused: dependence chain to sibling loop Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed Generated 2 prefetch instructions for the loop Loop unrolled 8 times Generated 1 prefetches in scalar loop FMA (fused multiply-add) instruction(s) generated 38, dot(const vector &, const vector &) inlined, size=9 (inline) file main.cpp (7) 11, Loop not fused: function call before adjacent loop Generated vector simd code for the loop containing reductions Generated 2 prefetch instructions for the loop FMA (fused multiply-add) instruction(s) generated 42, Loop not vectorized/parallelized: potential early exits 46, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size=10 (inline) file main.cpp (17) 21, Memory copy idiom, loop replaced by call to __c_mcopy8 50, dot(const vector &, const vector &) inlined, size=9 (inline) file main.cpp (7) 11, Loop not fused: dependence chain to sibling loop Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed Generated vector simd code for the loop containing reductions Generated 2 prefetch instructions for the loop FMA (fused multiply-add) instruction(s) generated 51, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size=10 (inline) file main.cpp (17) 21, Loop not fused: different controlling conditions Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed Generated 2 prefetch instructions for the loop Loop unrolled 8 times Generated 1 prefetches in scalar loop FMA (fused multiply-add) instruction(s) generated 55, matvec(const matrix &, const vector &, const vector &) inlined, size=17 (inline) file main.cpp (7) 13, Loop not fused: dependence chain to sibling loop 17, Generated an alternate version of the loop Generated vector simd code for the loop containing reductions Generated a prefetch instruction for the loop Generated vector simd code for the loop containing reductions Generated a prefetch instruction for the loop FMA (fused multiply-add) instruction(s) generated 56, dot(const vector &, const vector &) inlined, size=9 (inline) file main.cpp (7) 11, Loop not fused: dependence chain to sibling loop Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed Generated vector simd code for the loop containing reductions Generated 2 prefetch instructions for the loop FMA (fused multiply-add) instruction(s) generated 60, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size=10 (inline) file main.cpp (17) 21, Loop not fused: dependence chain to sibling loop Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed Loop not vectorized: data dependency Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed Generated 2 prefetch instructions for the loop Loop unrolled 8 times Generated 1 prefetches in scalar loop FMA (fused multiply-add) instruction(s) generated 61, waxpby(double, const vector &, double, const vector &, const vector &) inlined, size=10 (inline) file main.cpp (17) 21, Loop not fused: function call before adjacent loop Generated vector and scalar versions of the loop; pointer conflict tests determine which is executed Generated 2 prefetch instructions for the loop Loop unrolled 8 times Generated 1 prefetches in scalar loop FMA (fused multiply-add) instruction(s) generated 69, free_matrix(matrix &) inlined, size=5 (inline) file main.cpp (62) 70, free_vector(vector &) inlined, size=3 (inline) file main.cpp (19) 71, free_vector(vector &) inlined, size=3 (inline) file main.cpp (19) 72, free_vector(vector &) inlined, size=3 (inline) file main.cpp (19) 73, free_vector(vector &) inlined, size=3 (inline) file main.cpp (19) 74, free_vector(vector &) inlined, size=3 (inline) file main.cpp (19) cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ ./no_acc.exe Rows: 8120601, nnz: 218535025 Iteration: 0, Tolerance: 4.0067e+08 Iteration: 10, Tolerance: 1.8772e+07 Iteration: 20, Tolerance: 6.4359e+05 Iteration: 30, Tolerance: 2.3202e+04 Iteration: 40, Tolerance: 8.3565e+02 Iteration: 50, Tolerance: 3.0039e+01 Iteration: 60, Tolerance: 1.0764e+00 Iteration: 70, Tolerance: 3.8360e-02 Iteration: 80, Tolerance: 1.3515e-03 Iteration: 90, Tolerance: 4.6209e-05 Iterarion: 100, error: 1.993399e-06, time: 17182.560547 ms
● 优化后
1 // matrix.h 2 #pragma once 3 #include <cstdlib> 4 5 struct matrix 6 { 7 unsigned int num_rows; 8 unsigned int nnz; 9 unsigned int *row_offsets; 10 unsigned int *cols; 11 double *coefs; 12 }; 13 14 void allocate_3d_poission_matrix(matrix &A, int N) 15 { 16 const int num_rows = (N + 1) * (N + 1) * (N + 1); 17 A.num_rows = num_rows; 18 A.row_offsets = (unsigned int*)malloc((num_rows + 1) * sizeof(unsigned int)); 19 A.cols = (unsigned int*)malloc(27 * num_rows * sizeof(unsigned int)); 20 A.coefs = (double*)malloc(27 * num_rows * sizeof(double)); 21 22 const int ystride = N, zstride = N * N; 23 int i, j, n, nnz, offsets[27]; 24 double coefs[27]; 25 26 i = 0; 27 for (int z = -1; z <= 1; z++) 28 { 29 for (int y = -1; y <= 1; y++) 30 { 31 for (int x = -1; x <= 1; x++) 32 { 33 offsets[i] = zstride * z + ystride * y + x; 34 if (x == 0 && y == 0 && z == 0) 35 coefs[i] = 27; 36 else 37 coefs[i] = -1; 38 i++; 39 } 40 } 41 } 42 nnz = 0; 43 for (i = 0; i < num_rows; i++) 44 { 45 A.row_offsets[i] = nnz; 46 for (j = 0; j < 27; j++) 47 { 48 n = i + offsets[j]; 49 if (n >= 0 && n<num_rows) 50 { 51 A.cols[nnz] = n; 52 A.coefs[nnz] = coefs[j]; 53 nnz++; 54 } 55 } 56 } 57 A.row_offsets[num_rows] = nnz; 58 A.nnz = nnz; 59 #pragma acc enter data copyin(A) 60 #pragma acc enter data copyin(A.row_offsets[0:num_rows+1],A.cols[0:nnz],A.coefs[0:nnz]) 61 } 62 63 void free_matrix(matrix &A) 64 { 65 unsigned int *row_offsets = A.row_offsets, *cols = A.cols; 66 double *coefs = A.coefs; 67 #pragma acc exit data delete(A.row_offsets,A.cols,A.coefs) 68 #pragma acc exit data delete(A) 69 free(row_offsets); 70 free(cols); 71 free(coefs); 72 }
1 // matrix_function.h 2 #pragma once 3 #include "vector.h" 4 #include "matrix.h" 5 6 void matvec(const matrix& A, const vector& x, const vector &y) 7 { 8 const unsigned int num_rows=A.num_rows; 9 unsigned int *restrict row_offsets=A.row_offsets, *restrict cols=A.cols; 10 double *restrict Acoefs=A.coefs, *restrict xcoefs=x.coefs, *restrict ycoefs=y.coefs; 11 12 #pragma acc kernels copyin(cols[0:A.nnz],Acoefs[0:A.nnz],xcoefs[0:x.n]) 13 #pragma acc loop device_type(nvidia) gang worker(8) 14 for(int i = 0; i < num_rows; i++) 15 { 16 double sum = 0; 17 const int row_start=row_offsets[i], row_end=row_offsets[i+1]; 18 #pragma acc loop device_type(nvidia) vector(32) 19 for(int j = row_start; j < row_end; j++) 20 sum += Acoefs[j] * xcoefs[cols[j]]; 21 ycoefs[i] = sum; 22 } 23 }
1 // vector.h 2 #pragma once 3 #include<cstdlib> 4 #include<cmath> 5 6 struct vector 7 { 8 unsigned int n; 9 double *coefs; 10 }; 11 12 void allocate_vector(vector &v, const unsigned int n) 13 { 14 v.n=n; 15 v.coefs=(double*)malloc(n*sizeof(double)); 16 #pragma acc enter data create(v) 17 #pragma acc enter data create(v.coefs[0:n]) 18 } 19 20 void free_vector(vector &v) 21 { 22 #pragma acc exit data delete(v.coefs) 23 #pragma acc exit data delete(v) 24 v.n = 0; 25 free(v.coefs); 26 } 27 28 void initialize_vector(vector &v, const double val) 29 { 30 for (int i = 0; i < v.n; i++) 31 v.coefs[i] = val; 32 #pragma acc update device(v.coefs[0:v.n]) 33 }
1 // vector_functions.h 2 #pragma once 3 #include<cstdlib> 4 #include "vector.h" 5 6 double dot(const vector& x, const vector& y) 7 { 8 const unsigned int n = x.n; 9 double sum = 0, *xcoefs = x.coefs, *ycoefs = y.coefs; 10 11 #pragma acc kernels 12 for (int i = 0; i < n; i++) 13 sum += xcoefs[i] * ycoefs[i]; 14 return sum; 15 } 16 17 void waxpby(double alpha, const vector &x, double beta, const vector &y, const vector& w) 18 19 const unsigned int n = x.n; 20 double *restrict xcoefs = x.coefs, *ycoefs = y.coefs, *wcoefs = w.coefs; 21 22 #pragma acc kernels copy(wcoefs[:w.n],ycoefs[0:y.n]) copyin(xcoefs[0:x.n]) 23 { 24 #pragma acc loop independent 25 for (int i = 0; i<n; i++) 26 wcoefs[i] = alpha * xcoefs[i] + beta * ycoefs[i]; 27 } 28 }
● 输出结果
// Ubuntu: cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ pgc++ -fast -acc -Minfo main.cpp -ta=tesla allocate_vector(vector &, unsigned int): 7, include "vector.h" 16, Accelerator clause: upper bound for dimension 0 of array 'v' is unknown Generating enter data create(v[:1],v->coefs[:n]) free_vector(vector &): 7, include "vector.h" 22, Generating exit data delete(v[:1],v->coefs[:1]) initialize_vector(vector &, double): 7, include "vector.h" 28, Memory set idiom, loop replaced by call to __c_mset8 31, Generating update device(v->coefs[:v->n]) dot(const vector &, const vector &): 8, include "vector_functions.h" 9, Generating implicit copyin(ycoefs[:n],xcoefs[:n]) 12, Loop is parallelizable Accelerator kernel generated Generating Tesla code 12, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */ 13, Generating implicit reduction(+:sum) waxpby(double, const vector &, double, const vector &, const vector &): 8, include "vector_functions.h" 33, Generating copyin(xcoefs[:x->n]) Generating copy(ycoefs[:y->n],wcoefs[:w->n]) 35, Loop is parallelizable Accelerator kernel generated Generating Tesla code 35, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */ allocate_3d_poission_matrix(matrix &, int): 9, include "matrix.h" 26, Loop not fused: different loop trip count 28, Loop not vectorized/parallelized: loop count too small 42, Loop not fused: function call before adjacent loop 45, Loop not vectorized: data dependency 60, Accelerator clause: upper bound for dimension 0 of array 'A' is unknown Generating enter data copyin(A[:1],A->row_offsets[:num_rows+1],A->coefs[:nnz],A->cols[:nnz]) free_matrix(matrix &): 9, include "matrix.h" 68, Generating exit data delete(A->coefs[:1],A->cols[:1],A[:1],A->row_offsets[:1]) matvec(const matrix &, const vector &, const vector &): 10, include "matrix_functions.h" 10, Generating copyin(Acoefs[:A->nnz]) Generating implicit copyin(row_offsets[:num_rows+1]) Generating copyin(xcoefs[:x->n]) Generating implicit copyout(ycoefs[:num_rows]) Generating copyin(cols[:A->nnz]) 14, Loop is parallelizable Accelerator kernel generated Generating Tesla code 14, #pragma acc loop gang, worker(8) /* blockIdx.x threadIdx.y */ 19, #pragma acc loop vector(32) /* threadIdx.x */ 20, Generating implicit reduction(+:sum) 19, Loop is parallelizable main: 43, Loop not vectorized/parallelized: potential early exits cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/cpp$ ./a.out Rows: 8120601, nnz: 218535025 Iteration: 0, Tolerance: 4.0067e+08 Iteration: 10, Tolerance: 1.8772e+07 Iteration: 20, Tolerance: 6.4359e+05 Iteration: 30, Tolerance: 2.3202e+04 Iteration: 40, Tolerance: 8.3565e+02 Iteration: 50, Tolerance: 3.0039e+01 Iteration: 60, Tolerance: 1.0764e+00 Iteration: 70, Tolerance: 3.8360e-02 Iteration: 80, Tolerance: 1.3515e-03 Iteration: 90, Tolerance: 4.6209e-05 Iterarion: 100, error: 1.993399e-06, time: 3249.523926 ms
● 对应的 fortran 代码优化前后的结果
// Ubuntu 优化前: cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/08-multicore$ pgf90 -c matrix.F90 vector.F90 matrix.F90: vector.F90: cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/08-multicore$ pgf90 main.F90 matrix.o vector.o -fast -mp -Minfo -o no_acc.exe main.F90: main: 54, Loop not vectorized/parallelized: potential early exits cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/08-multicore$ ./no_acc.exe Rows: 8120601 nnz: 218535025 Iteration: 0 Tolerance: 4.006700E+08 Iteration: 10 Tolerance: 1.877230E+07 ^C cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/08-multicore$ cd .. cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90$ pgf90 -c matrix.F90 vector.F90 -fast -Minfo matrix.F90: allocate_3d_poisson_matrix: 54, Loop not fused: different loop trip count 55, Loop not vectorized/parallelized: loop count too small 56, Loop unrolled 3 times (completely unrolled) 71, Loop not vectorized: data dependency matvec: 118, Loop unrolled 2 times FMA (fused multiply-add) instruction(s) generated vector.F90: initialize_vector: 25, Memory set idiom, loop replaced by call to __c_mset8 dot: 46, Generated an alternate version of the loop Generated vector simd code for the loop containing reductions Generated 2 prefetch instructions for the loop Generated vector simd code for the loop containing reductions Generated 2 prefetch instructions for the loop FMA (fused multiply-add) instruction(s) generated waxpby: 59, Generated 2 alternate versions of the loop Generated vector simd code for the loop Generated 2 prefetch instructions for the loop Generated vector simd code for the loop Generated 2 prefetch instructions for the loop Generated vector simd code for the loop Generated 2 prefetch instructions for the loop FMA (fused multiply-add) instruction(s) generated cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90$ pgf90 main.F90 matrix.o vector.o -fast -Minfo -mp -o no_acc.exe main.F90: main: 54, Loop not vectorized/parallelized: potential early exits cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90$ ./no_acc.exe Rows: 8120601 nnz: 218535025 Iteration: 0 Tolerance: 4.006700E+08 Iteration: 10 Tolerance: 1.877230E+07 Iteration: 20 Tolerance: 6.435887E+05 Iteration: 30 Tolerance: 2.320219E+04 Iteration: 40 Tolerance: 8.356487E+02 Iteration: 50 Tolerance: 3.003893E+01 Iteration: 60 Tolerance: 1.076441E+00 Iteration: 70 Tolerance: 3.836034E-02 Iteration: 80 Tolerance: 1.351503E-03 Iteration: 90 Tolerance: 4.620883E-05 Total Iterations: 100 Time (s): 23.30484 s // Ubuntu 优化后: cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/08-multicore$ pgf90 -c matrix.F90 vector.F90 -acc -fast -Minfo matrix.F90: allocate_3d_poisson_matrix: 54, Loop not fused: different loop trip count 55, Loop not vectorized/parallelized: loop count too small 56, Loop unrolled 3 times (completely unrolled) 69, Loop not fused: function call before adjacent loop 71, Loop not vectorized: data dependency 83, Generating enter data copyin(a) 84, Generating enter data copyin(a%coefs(:),a%row_offsets(:),a%cols(:)) free_matrix: 98, Generating exit data delete(a%coefs(:),a%cols(:),a%row_offsets(:)) 99, Generating exit data delete(a) matvec: 118, Generating implicit copyin(arow_offsets(1:a%num_rows+1),acols(:),acoefs(:)) Generating implicit copyout(y(:a%num_rows)) Generating implicit copyin(x(:)) 120, Loop is parallelizable Accelerator kernel generated Generating Tesla code 120, !$acc loop gang, worker(8) ! blockidx%x threadidx%y 125, !$acc loop vector(32) ! threadidx%x 129, Generating implicit reduction(+:tmpsum) 120, Loop not fused: no successor loop 125, Loop is parallelizable Loop unrolled 2 times FMA (fused multiply-add) instruction(s) generated vector.F90: initialize_vector: 25, Generating present(vector(:)) 26, Loop is parallelizable Accelerator kernel generated Generating Tesla code 26, !$acc loop gang, vector(128) ! blockidx%x threadidx%x 26, Memory set idiom, loop replaced by call to __c_mset8 allocate_vector: 34, Generating enter data create(vector(:)) free_vector: 39, Generating exit data delete(vector(:)) dot: 50, Generating implicit copyin(y(:length),x(:length)) 51, Loop is parallelizable Accelerator kernel generated Generating Tesla code 51, !$acc loop gang, vector(128) ! blockidx%x threadidx%x 52, Generating implicit reduction(+:tmpsum) 51, Loop not fused: no successor loop Generated an alternate version of the loop Generated vector simd code for the loop containing reductions Generated 2 prefetch instructions for the loop Generated vector simd code for the loop containing reductions Generated 2 prefetch instructions for the loop FMA (fused multiply-add) instruction(s) generated waxpby: 65, Generating implicit copyin(x(:length),y(:length)) Generating implicit copyout(w(:length)) 66, Loop is parallelizable Accelerator kernel generated Generating Tesla code 66, !$acc loop gang, vector(128) ! blockidx%x threadidx%x 66, Loop not fused: no successor loop Generated 2 alternate versions of the loop Generated vector simd code for the loop Generated 2 prefetch instructions for the loop Generated vector simd code for the loop Generated 2 prefetch instructions for the loop Generated vector simd code for the loop Generated 2 prefetch instructions for the loop FMA (fused multiply-add) instruction(s) generated cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/08-multicore$ pgf90 main.F90 matrix.o vector.o -acc -fast -Minfo -mp -o acc.exe main.F90: main: 54, Loop not vectorized/parallelized: potential early exits cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter02/f90/08-multicore$ ./acc.exe Rows: 8120601 nnz: 218535025 Iteration: 0 Tolerance: 4.006700E+08 Iteration: 10 Tolerance: 1.877230E+07 Iteration: 20 Tolerance: 6.435887E+05 Iteration: 30 Tolerance: 2.320219E+04 Iteration: 40 Tolerance: 8.356487E+02 Iteration: 50 Tolerance: 3.003893E+01 Iteration: 60 Tolerance: 1.076441E+00 Iteration: 70 Tolerance: 3.836034E-02 Iteration: 80 Tolerance: 1.351503E-03 Iteration: 90 Tolerance: 4.620883E-05 Total Iterations: 100 Time (s): 3.533652 s
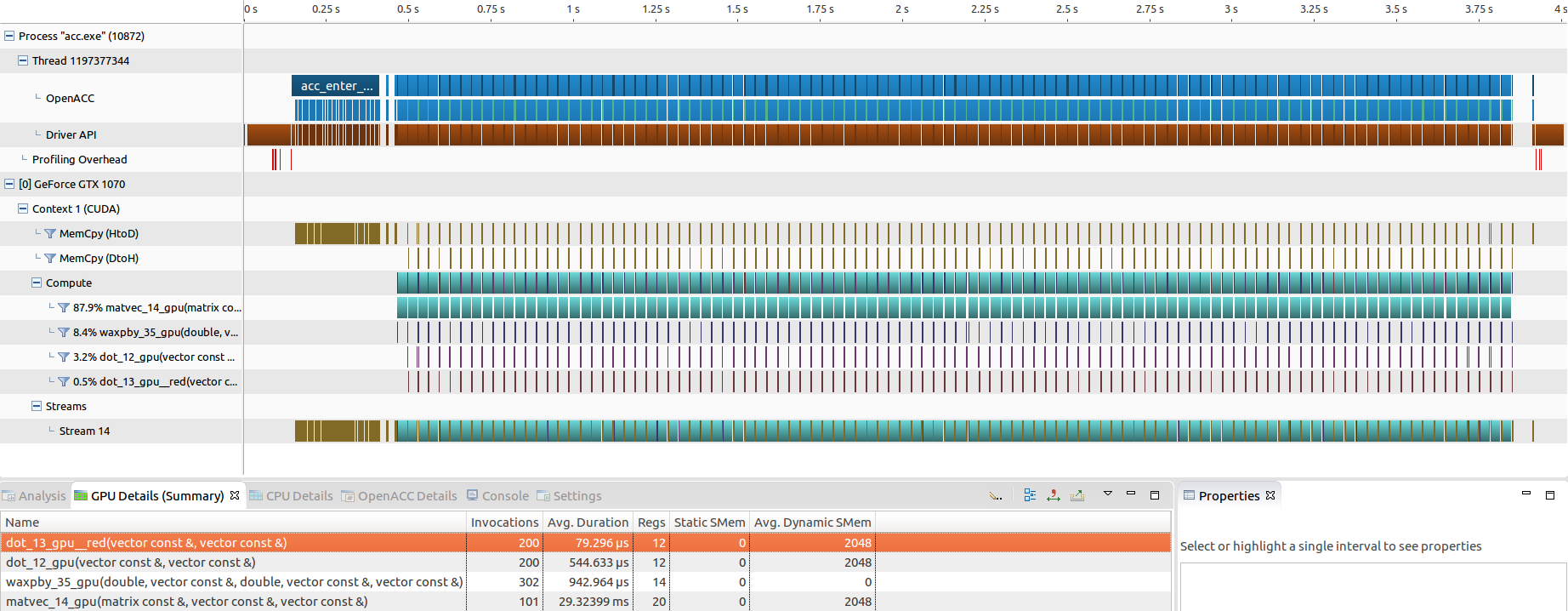
● C++ 优化结果在 nvprof 中的表现