Hive和HBase的区别
转载自https://blog.csdn.net/vipyeshuai/article/details/50847281
————————————————
region 变大后,可以进行划分
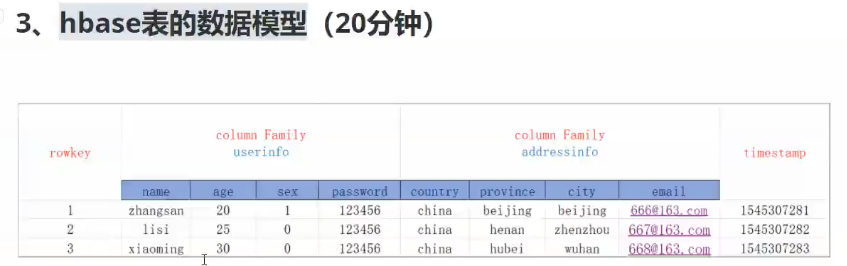
 version是版本号即时间戳 拥有所有版本
version是版本号即时间戳 拥有所有版本

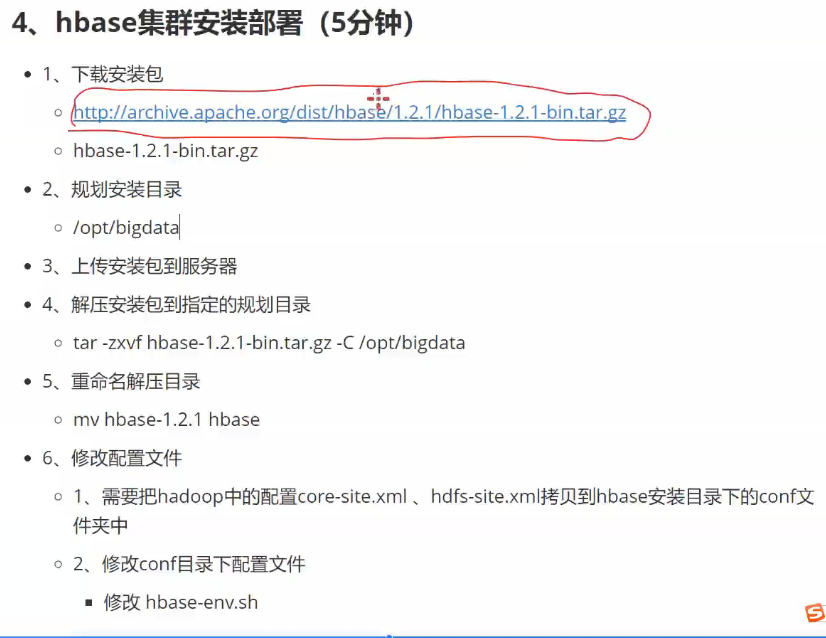
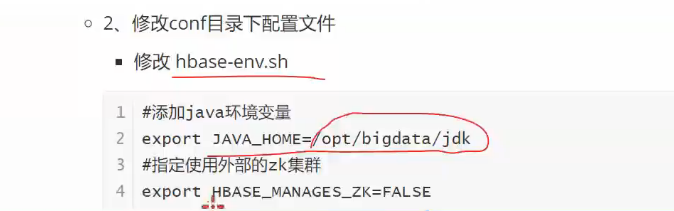


zookeeper环境


hbase启动

bin目录中

hmaster已启动
进入hbase客户端
help帮助,命令
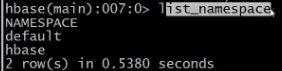
namespace即数据库

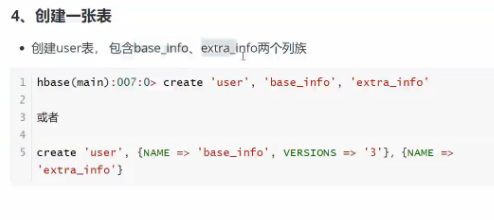
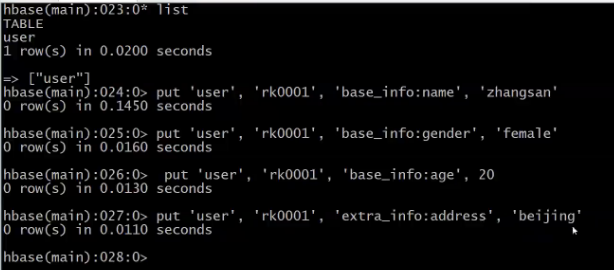
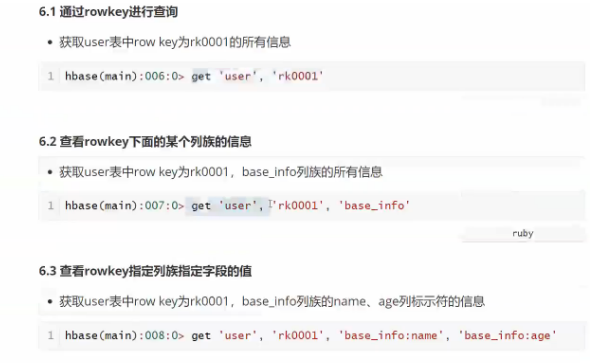
输入数据及列族

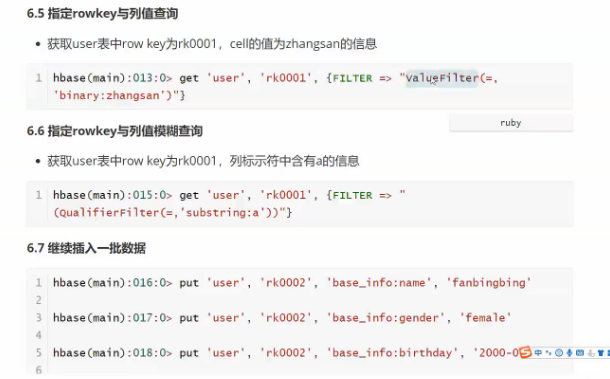
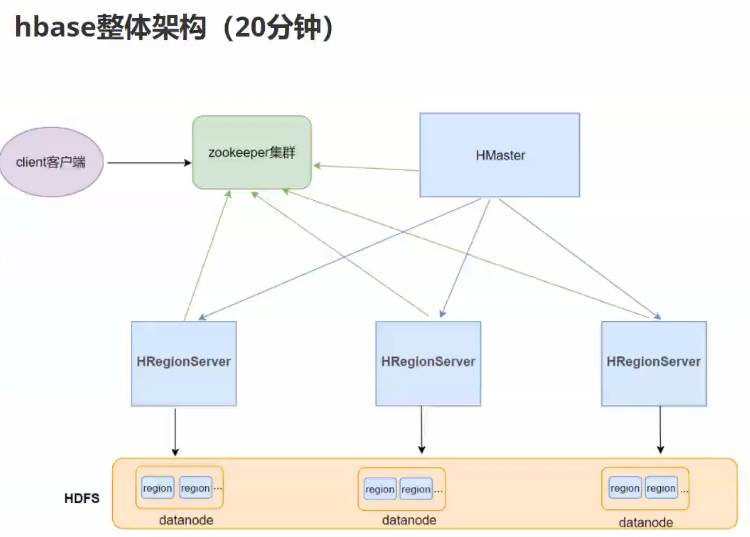
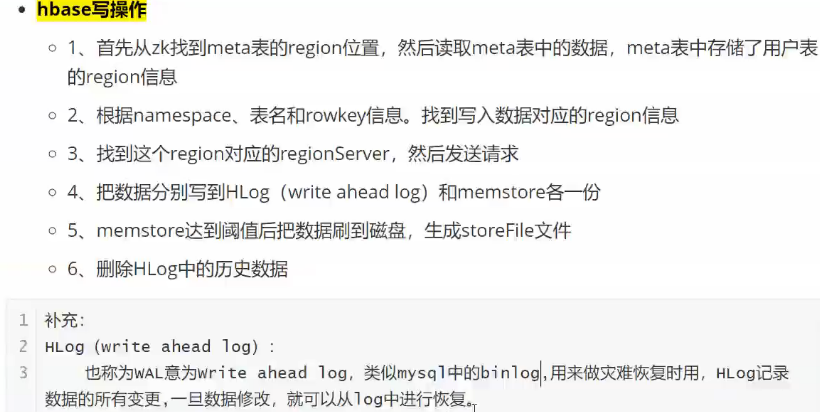
二:hbase存储原理
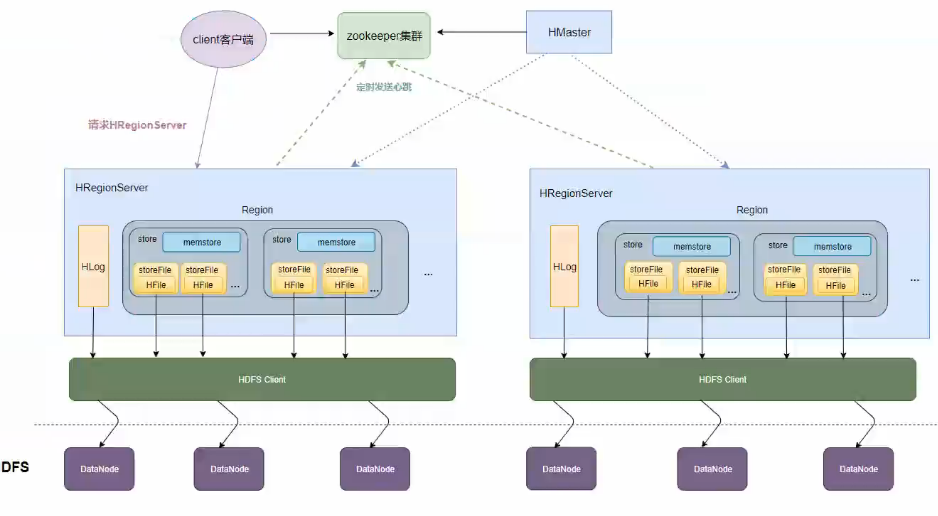
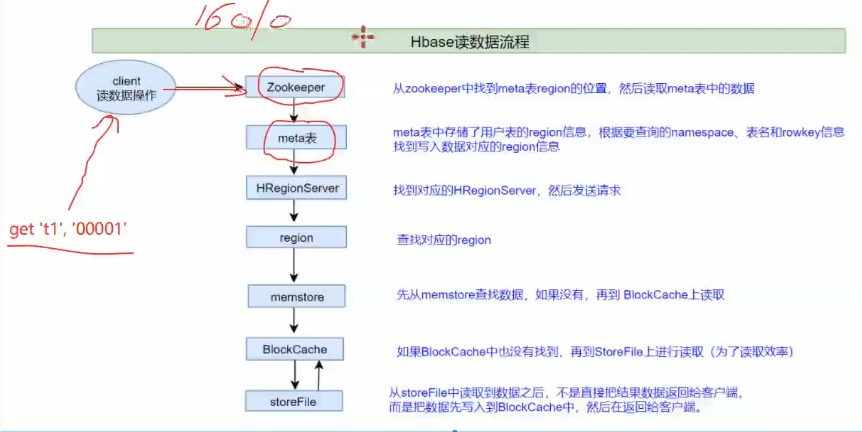
问题:blockcache是在客户机吗
读写流程不需要Hmaster参与

hlog预写日志,防止机子挂了
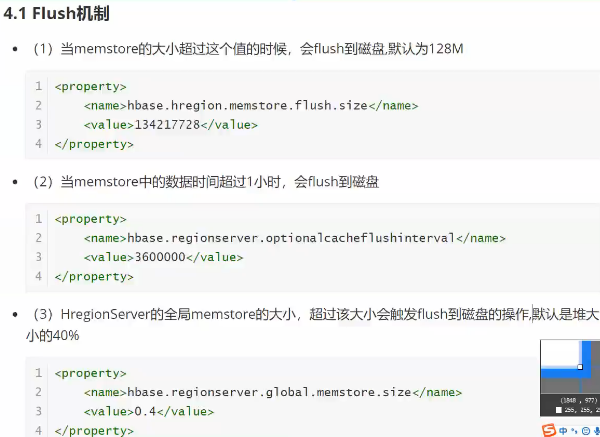
memstore满了就从内存刷到磁盘中
三个条件,满足任何一个(在下面)
flush 机制
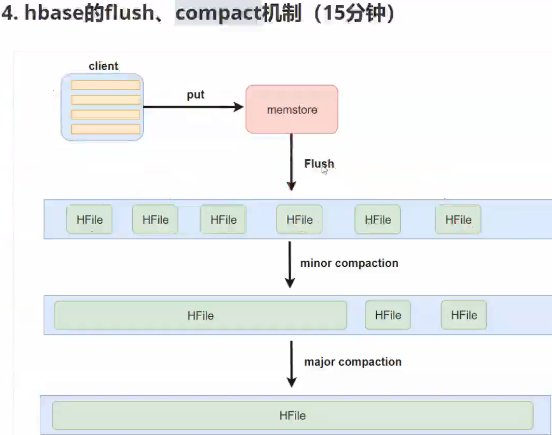
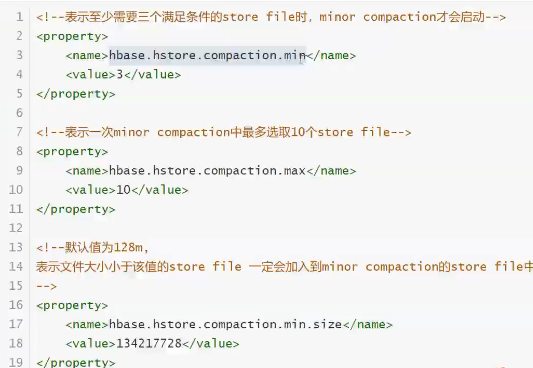
hfile 合并
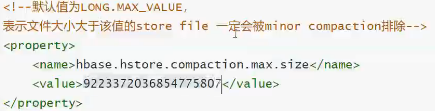
大合并
hbase官网
hbase.apache.org
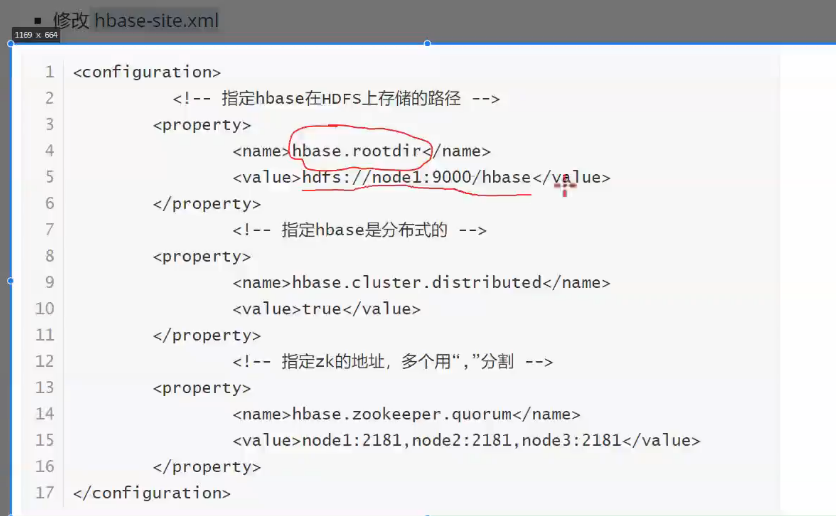
hbase-site.xml hbase参数设置
Region的拆分
如果100台机子(client)同时访问region,这个region所在的hregion server压力很大, 而其他空闲
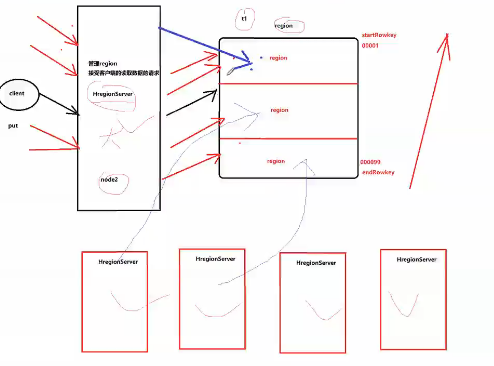
拆分后负载均衡,避免某一个region server压力过大
策略:达到10g (默认)
(默认)
缺陷:小表数据量很小,例9g,达不到拆分条件 但是访问还是很多


预分区

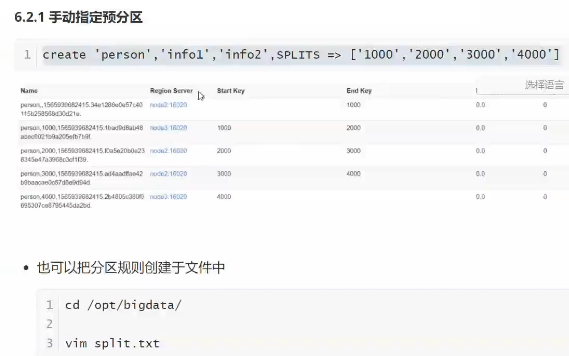
5个region 1-1000 ,1000-2000,2000-3000,3000-4000,4000+ rowkey
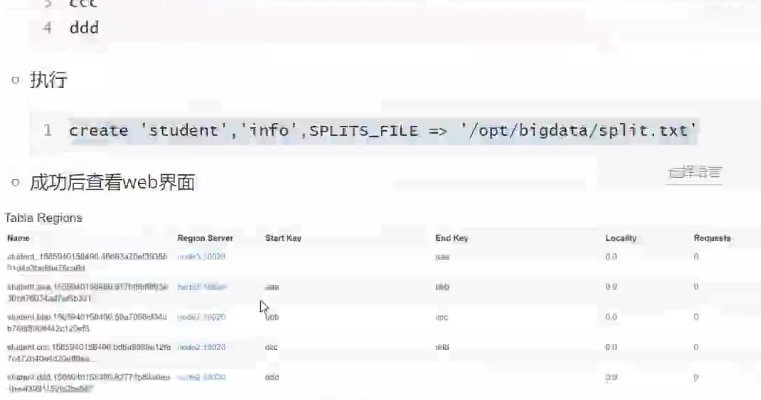
通过字母顺序作为rowkey
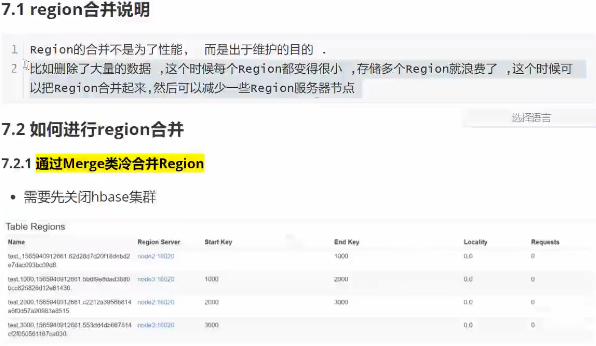
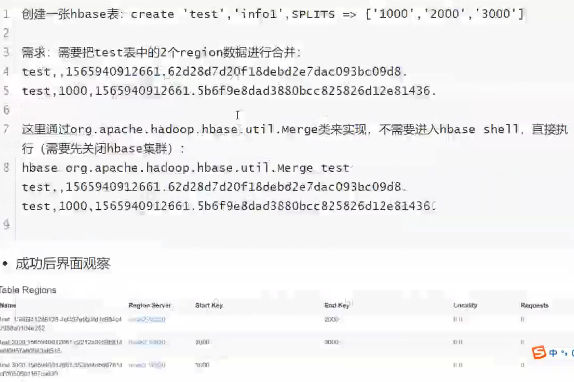
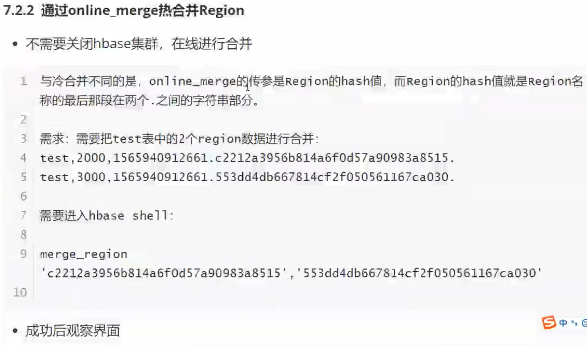
Region合并
若数据大量被删除,则空出很多region
我们需要将一些region合并