参考博客地址
http://www.cnblogs.com/alex3714/articles/5230609.html
1、python GIL全局解释器锁
python调用的操作系统的原生线程,当python调用操作系统的原生线程工作之后,python就没有办法控制线程进行工作了,所以当多个线程同时修改同一份数据的时候,就有可能造成数据修改的不一致性,那么针对这种情况,python GIL全局解释器锁会允许在同一时间只有一个线程在修改数据;
需要注意,python GIL和python程序中的LOCK没有关系,是两个不同的概念;
Queue(队列)
Queue本身是线程安全的,特别是在多线程的程序中非常有用,数据在多个线程之间安全的进行交换,因为线程本身是不安全的,如果不加线程锁,数据就有可能会改乱了;但是多个线程同时访问一个Queue,就不需要加锁,因为queue本身线程安全的,queue中的数据同时只能被一个线程获取;
多线程queue分类:(import queue)
queue.Queue(maxsize=0) 先入先出
queue = Queue.Queue() queue.qsize() #返回近似的队列大小 queue.empty() #当队列为空值返回True queue.put(item,block,timeout) #如果block为False,当队列为full时,会抛出full异常; queue.put_nowait(item) #和put的block为False时一样; queue.get() #送队列中删除元素,并返回元素的值 queue.get_nowait() queue.task_done() #发送信号表示入列任务已经完成,经常在消费者线程中使用到; queue.join() #阻塞,直到队列中的所有元素处理完毕 需要注意的是Queue模块中的队列和collections中的deque不一样,前者用于不同线程之间的通信,后者主要是数据结构上的概念,支持in方法;
下面的例子同时开启5个线程进行下载:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
__author__ = 'Charles Chang'
import os
import Queue
import threading
import urllib2
class DownloadThread(threading.Thread):
def __init__(self,queue):
threading.Thread.__init__(self)
self.queue = queue
def run(self): #父类中会自动执行run方法
while True:
url = self.queue.get() #从队列中获取一个url元素
print self.name + "begin download"+url+"..."
self.download_file(url) #进行文件下载
self.queue.task_done() #下载文毕发送信号
print self.name + "download completed!!!"
def download_file(self,url):
urlhander=urllib2.urlopen(url)
fname= os.path.basename(url) + ".html" #文件名称
with open(fname,'wb') as f: #打开文件
while True:
chunk = urlhander.read(1024)
if not chunk:break
f.write(chunk)
if __name__ == '__main__':
urls= [
"http://wiki.python.org/moin/WebProgramming",
'https://www.createspace.com/3611970',
'http://wiki.python.org/moin/Documentation'
]
queue = Queue.Queue()
for i in range(5):
t = DownloadThread(queue)
t.setDaemon(True)
t.start()
for url in urls:
queue.put(url)
queue.join()
import Queue class Foo(object): def __init__(self,n): self.n = n q=Queue.Queue(maxsize=3) #队列的大小 q.put(Foo(1)) q.put(1) q.put(3,timeout=3) #默认put当队列满的时候回阻塞,设置超时时间,超时抛出异常 data = q.get_nowait() #获取不到数据不阻塞,直接抛出异常 q.empty() #队列是否为空 q.full() #队列是否已经满了
queue.LifoQueue(maxsize=0) last in first out
q=Queue.LifoQueue(maxsize=3) q.put(Foo(1)) q.put(1) q.put(3,timeout=3) print q.get() print q.get() print q.get() 和FIFO类似,只不过获取数据的时候,后put进去的数据先get得到;
queue.PriorityQueue(maxsize=0) 存储数据时可设置优先级的队列
q=Queue.PriorityQueue(maxsize=3) q.put((3,[1,2,3])) q.put((2,1)) q.put((10,1)) print q.get() print q.get() print q.get() put数据的格式为元祖的形式,第一个元素为优先级的值,越小优先级越高;第二个值为数据;get获取数据的时候,先获取到优先级高的数据;
生产者消费者
多进程的queue(from multiprocessing import Queue)
线程池:
http://www.cnblogs.com/wupeiqi/articles/4839959.html
python threading的两种调用方式:
直接调用import threadingimport time
def sayhi(num): #定义每个线程要运行的函数
print("running on number:%s" %num)
time.sleep(3)
if __name__ == '__main__':
t1 = threading.Thread(target=sayhi,args=(1,)) #生成一个线程实例
t2 = threading.Thread(target=sayhi,args=(2,)) #生成另一个线程实例
t1.start() #启动线程
t2.start() #启动另一个线程
print(t1.getName()) #获取线程名
print(t2.getName())
t1.join()
print('__main__')
继承调用
import threading
import time
class MyThread(threading.Thread):
def __init__(self,num):
threading.Thread.__init__(self)
self.num = num
def run(self):#定义每个线程要运行的函数
print("running on number:%s" %self.num)
time.sleep(3)
if __name__ == '__main__':
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
print(t1.getName()) #获取线程名
print(t2.getName())
主线程为'__main__'下面执行的部分,所以上述代码有三个线程,主线程在执行的时候,无需等待子线程执行完毕,就继续往下面执行,如果需要主线程等待子线程(阻塞),
那么就需要.join语法实现了,下面的代码是实现所有子线程并发执行完毕,然后主线程等待所有子线程执行完毕之后,继续往下执行;
import threading
import time
def sayhi(num): #定义每个线程要运行的函数
print("running on number:%s" %num)
time.sleep(3)
if __name__ == '__main__':
t_list=[] #存放线程实例
for i in range(10):
t = threading.Thread(target=sayhi,args=[i,])
t.start()
t_list.append(t)
for t in t_list:
t.join()
print('--main--')
守护线程daemin和join
Gevent协程
实现单线程时候的并发的效果,在IO阻塞的时候,无需切换线程的开销,操作系统不知道协程的存在,由程序员自己控制;
一、概念介绍
一个应用只有一个进程(进程是一个资源池)和一个主线程,随着硬件的升级,产生出了多核的CPU,为了能让进程同时使用各个CPU,产生了线程;
进程和线程的区别: a、多个线程之间内存是共享的 b、各个进程之间内存是不共享的
进程和线程的使用场景: a、当使用CPU多时,使用进程(利用多核CPU) b、I/O操作使用线程
1、多线程


创建多线程用threading.Tread类 t=threading.Thread(target=show,args(i,)) #创建一个多线程,创建多线程是将threading模块中的Thread类实例化,target指定的对象表示该线程执行的方法,args指定的内容表示show方法传入的参数; def __init__(self, group=None, target=None, name=None, args=(), kwargs=None, verbose=None): _Verbose.__init__(self, verbose) if kwargs is None: kwargs = {} self.__target = target #为私有普通字段 self.__name = str(name or _newname()) self.__args = args #为私有普通字段 self.__kwargs = kwargs self.__daemonic = self._set_daemon() self.__ident = None self.__started = Event() self.__stopped = False self.__block = Condition(Lock()) self.__initialized = True # sys.stderr is not stored in the class like # sys.exc_info since it can be changed between instances self.__stderr = _sys.stderr t.start() #启用该线程; t.setName() #为线程设置名称或者标识; t.setDeadmon() #将线程设置为后台线程;在多线程的代码执行过程中,主线程从上往下执行,子线程执行各个函数,如果将线程设置为后台线程,无论该子线程执行完毕。当主线程执行完毕,子线程也强制关闭; t.join(10) #阻塞10s,然后主线程才会往下执行;这样的话,会将程序的执行变成是串行的; t.run() #对于线程threading.Thread(target=show,args=(i,)),其中的show函数是由Thread类中的run方法执行的
2、线程锁和事件
在python2.7中默认执行100条CPU指令,执行完了就切换到另外一个线程
在多线程执行的时候,各个线程之间的执行时随机调度的,一个线程有可能在执行了几个CPU指令之后,就去执行其他的线程,在下面的例子中,各个线程为了抢占屏幕打印,导致输出可能出现混乱:
import threading
import time
gl_num = 0
def show(arg):
global gl_num
time.sleep(1)
gl_num +=1
print gl_num
for i in range(10):
t = threading.Thread(target=show, args=(i,))
t.start()
print 'main thread stop'
执行结果出现如下情况:
main thread stop
1
2
3
45
67
89
10
为了解决上述问题,设计GIL线程锁:
import threading import time gl_num = 0 lock = threading.RLock() #定义锁 def Func(): lock.acquire() global gl_num gl_num +=1 time.sleep(1) print gl_num lock.release() for i in range(10): t = threading.Thread(target=Func) t.start()
事件:event(threading中的类)
class _Event(_Verbose): """A factory function that returns a new event object. An event manages a flag that can be set to true with the set() method and reset to false with the clear() method. The wait() method blocks until the flag is true. """ # After Tim Peters' event class (without is_posted()) def __init__(self, verbose=None): _Verbose.__init__(self, verbose) self.__cond = Condition(Lock()) self.__flag = False def _reset_internal_locks(self): # private! called by Thread._reset_internal_locks by _after_fork() self.__cond.__init__() def isSet(self): 'Return true if and only if the internal flag is true.' return self.__flag is_set = isSet def set(self): """Set the internal flag to true. All threads waiting for the flag to become true are awakened. Threads that call wait() once the flag is true will not block at all. """ self.__cond.acquire() try: self.__flag = True self.__cond.notify_all() finally: self.__cond.release() def clear(self): """Reset the internal flag to false. Subsequently, threads calling wait() will block until set() is called to set the internal flag to true again. """ self.__cond.acquire() try: self.__flag = False finally: self.__cond.release() def wait(self, timeout=None): """Block until the internal flag is true. If the internal flag is true on entry, return immediately. Otherwise, block until another thread calls set() to set the flag to true, or until the optional timeout occurs. When the timeout argument is present and not None, it should be a floating point number specifying a timeout for the operation in seconds (or fractions thereof). This method returns the internal flag on exit, so it will always return True except if a timeout is given and the operation times out. """ self.__cond.acquire() try: if not self.__flag: self.__cond.wait(timeout) return self.__flag finally: self.__cond.release()
上述使用的有三个方法和一个字段;
event的使用场景:让主线程控制子线程何时执行,让子线程停下来还是让子线程继续运行,实现该功能是靠标志位。类似于红灯停,绿灯行;
如下:
wait():判断Flag是否为True ,如果表示位Flag没有设定,那么就阻塞; set()表示Flag=True,clear()表示Flag=False;
#!/usr/bin/env python #_*_ coding:utf-8 _*_ import threading event_obj=threading.Event() #实例化Event类 def do(event): print 'start' event.wait() #如果Flag为False,那么就阻塞 print 'execute' for i in range(10): t=threading.Thread(target=do,args=(event_obj,)) t.start() event_obj.clear() inp = raw_input('input:') if inp == 'true': event_obj.set()
二、多进程的使用和介绍
1、windows上使用pycharm不支持多进程,需要在linux机器上实现,在启用多进程的时候,进程数最好与CPU的个数相同
#!/usr/bin/env python #_*_ coding:utf-8 _*_ from multiprocessing import Process #也可以使用multiprocessing.Process,但下面调用的时候需要注意;进程数做好与CPU的个数相同 import threading import time def foo(i): print 'say hi',i for i in range(10): p = Process(target=foo,args=(i,)) p.start()
2、进程变量和进程锁
为什么需要进程锁:在进程之间共享数据的时候使用,默认进程之间的数据是不共享的;
#!/usr/bin/env python #coding:utf-8 from multiprocessing import Process import time li = [] def foo(i): li.append(i) print 'say hi',li for i in range(10): p = Process(target=foo,args=(i,)) p.start() print 'ending',li 结果: say hi [0] say hi [1] say hi [4] say hi [3] say hi [5] say hi [8] ending [] say hi [2] say hi [7] say hi [9] say hi [6] root@QQ:/sc
数据共享方法a(推荐):
#!/usr/bin/env python #_*_ coding:utf-8 _*_ from multiprocessing import Process,Array temp =Array('i',[11,22,33,44]) #创建一个只包含数字类型的数组,只要使用此类,后面就是共享的数据 #数组的个数是不可变的,如果是可变的话,类似于字符串使用'+'号拼接,在增加新的元素的时候,需要开辟新的内存空间;python中可变的数组通过类似于列表的方式实现; def Foo(i): temp[i]=100+i #改变数组的元素 for item in temp: print i,'----->',item for i in range(2): p=Process(target=Foo,args=(i,)) #启用进程 p.start() 在linux上运行的结果如下: 0 -----> 100 0 -----> 22 0 -----> 33 0 -----> 44 1 -----> 100 1 -----> 101 1 -----> 33 1 -----> 44
from multiprocessing import Process,Manager manage = Manager() dic = manage.dict() def Foo(i): dic[i] = 100+i print dic.values() for i in range(2): p = Process(target=Foo,args=(i,)) p.start() p.join() 结果为: [100] [100, 101]
那么既然进程间的数据可以共享,那么就有可能类似于多进程那样产生脏数据,解决方法是通过进程锁实现的;
#!/usr/bin/env python # -*- coding:utf-8 -*- from multiprocessing import Process, Array, RLock def Foo(lock,temp,i): lock.acquire() temp[0] = 100+i for item in temp: print i,'----->',item lock.release() lock = RLock() temp = Array('i', [11, 22, 33, 44]) for i in range(20): p = Process(target=Foo,args=(lock,temp,i,)) p.start()
3、进程池
#!/usr/bin/env python # -*- coding:utf-8 -*- from multiprocessing import Process,Pool import time def Foo(i): time.sleep(2) return i+100 def Bar(arg): print arg pool = Pool(5) #print pool.apply(Foo,(1,)) #直接关闭 #print pool.apply_async(func =Foo, args=(1,)).get() for i in range(10): pool.apply_async(func=Foo, args=(i,),callback=Bar) #进程池中进程执行完毕再关闭 print 'end' pool.close() pool.join()
三、协程的原理和使用
不像进程和线程是由操作系统提供的,协程是由程序员自己控制的;在使用多线程执行程序的时候,CPU在线程之间来回切换,而线程的切换是耗时的,协程只需要启用一个线程,由操作员自己控制执行哪块代码段;
对于IO操作,一个线程利用协程切换,在多个协程之间操作;一般而言,线程的切换要比协程的切换耗时,在IO多的时候用协程,计算多的时候,用线程;
#!/usr/bin/env python # -*- coding:utf-8 -*- from greenlet import greenlet def test1(): print 12 gr2.switch() print 34 gr2.switch() def test2(): print 56 gr1.switch() print 78 gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch() 结果为: 12 56 34 78
#!/usr/bin/env python #_*_ coding:utf-8 _*_ import urllib t=urllib.urlopen('http://cnblogs.com') print t.read()
from gevent import monkey; monkey.patch_all() import gevent import urllib2 def f(url): print('GET: %s' % url) resp = urllib2.urlopen(url) #阻塞,看谁返回 data = resp.read() print('%d bytes received from %s.' % (len(data), url)) gevent.joinall([ gevent.spawn(f, 'https://www.python.org/'), gevent.spawn(f, 'https://www.yahoo.com/'), gevent.spawn(f, 'https://github.com/'), ]) #在每一个协程执行完毕时候,执行f方法
协程是线程的分片;由于在python中存在GIL,所以相比与其他语言,协程在python中显得更为重要;
python协程提供了两个模块,分别是greenlet和gevent,其中greenlet的切换是写程序的人自己实现的;
from greenlet import greenlet
def test1():
print(12)
gr2.switch()
print(34)
gr2.switch()
def test2():
print(56)
gr2.switch()
print(78)
gr1.switch()
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch()
输出结果:
12
56
78
34
而gevent是遇到io/阻塞就会立即切换,无需程序员控制
import gevent
def foo():
print(11)
gevent.sleep(0)
print(22)
def bar():
print(33)
gevent.sleep(0)
print(44)
gevent.joinall([
gevent.spawn(foo),
gevent.spawn(bar),
])
结果为:
11
33
22
44
四、设计线程池
进程、线程和CPU的关系如下:
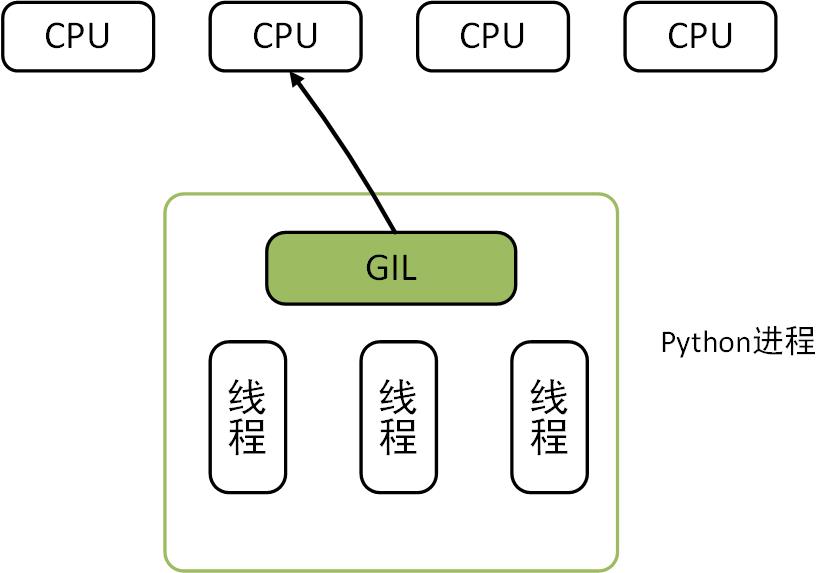
设计说明:
a、为了避免线程池中线程数量的浪费,取min(进程数,最大线程数);
b、如果长时间内线程数小于池子的大小,,那么就应该释放部分线程,需要判断当前线程池的状态,使用上下文管理实现;
上下文管理实现方式类似于之前文件操作:with open ('flag') as f: f.write()
c、关闭线程
线程池简单版本说明:
1、创建10个线程对象
2、queue中拿线程,有用的拿,没有用的等待
3、线程执行完毕,归还线程池
import Queue class Threadpool(object): def __init__(self,max_num=20): self.queue=Queue.Queue(max_num) #队列的大小 for i in xrange(max_num): self.queue.put(threading.Thread) #将20条数据放入到队列中,threading.Thread表示类,类在内存中只会保留一份,只需要一块空间,而如果是threading.Thread()则表示对象,实例化的对象则需要单独开辟一块空间; def get_thread(self): return self.queue.get() #如果queue中没有数据,那么在get的时候就会阻塞,直到有数据为止 def add_thread(self): self.queue.put(threading.Thread) pool = Threadpool(10) def func(arg,p): print arg import time time.sleep(2) p.add_thread() #函数执行完毕之后再向pool中加一条线程 for i in xrange(30): ret = pool.get_thread() #拿到线程,如果没有,就会阻塞等待 t= ret(target=func,args=(i,pool)) t.start()
#前面一种方法是在内存中创建类的方式实现的,下面的方式是创建对象的方式实现: import Queue class Threadpool(object): def __init__(self,max_num=20): self.queue=Queue.Queue(max_num) for i in xrange(max_num): self.queue.put(threading.Thread()) #创建线程对象 def get_thread(self): return self.queue.get() def add_thread(self): self.queue.put(threading.Thread()) pool = Threadpool(10) def func(arg,p): print arg import time time.sleep(2) p.add_thread() for i in xrange(300): ret=pool.get_thread() #此处不能使用ret=threading.Thread(target=func,args=(i,pool)),如果这样就和之前创建的线程对象无关了. ret._Thread__target=func #target是私有字段,私有字段的赋值采用这种方式 ret._Thread__args=(i,pool) ret.start() #上述可以实现,但是不好,因为每次创建对象都会在内存中开辟新的内存空间。私有字段的使用也不建议使用这种方式。
预备知识-----线程池设计之上下文管理
上下文管理:自定义with语句可以实现上下文管理来记录线程数目,对函数增加@contextlib.contextmanager装饰器,就可以通过with语句实现上下文管理了;通过with语句执行函数时顺序是这样的:内存加载show函数--->遇到with执行show函数中的内容--->遇到show函数中的yield就执行with部分的函数--->执行yield下面的内容
import contextlib
doing= []
@contextlib.contextmanager
def show(l1,item):
print('before') (1)
yield
print('after') (3)
with show(doing,1):
print("with in") (2)
利用上下文管理记录内存中的线程数目
import contextlib
import time
import random
import threading
doing = []
def num(l2):
while True:
print(len(l2),'aaaaa') #记录内存中线程的个数
time.sleep(1)
t = threading.Thread(target=num,args=(doing,))
t.start()
@contextlib.contextmanager
def show(l1,item):
doing.append(item) #将当前线程添加到doing中,等sleep若干秒之后再移除
yield
doing.remove(item)
def task(i):
flag = threading.current_thread()
with show(doing,flag):
print('with in')
time.sleep(random.randint(1,4))
for i in range(20):
temp = threading.Thread(target=task,args=(i,)) #运行线程
temp.start()
设计思路:
1、主线程从上往下执行,主线程创建子线程,记录正在执行的线程个数;
2、将函数show和task加载到内存中;
3、20次循环,每一个循环创建一个线程,线程内部执行操作,执行的时间不同,所以线程的个数是动态的,线程的任务是在记录执行的线程执行之前,将线程的ID加入到列表中;
import Queue import threading import contextlib StopEvent = object() class ThreadPool(object): def __init__(self, max_num): self.q = Queue.Queue(max_num) self.max_num = max_num self.cancel = False self.generate_list = [] self.free_list = [] def run(self, func, args, callback=None): """ 线程池执行一个任务 :param func: 任务函数 :param args: 任务函数所需参数 :param callback: 任务执行失败或成功后执行的回调函数,回调函数有两个参数1、任务函数执行状态;2、任务函数返回值(默认为None,即:不执行回调函数) :return: 如果线程池已经终止,则返回True否则None """ if self.cancel: return True if len(self.free_list) == 0 and len(self.generate_list) < self.max_num: self.generate_thread() w = (func, args, callback,) self.q.put(w) def generate_thread(self): """ 创建一个线程 """ t = threading.Thread(target=self.call) t.start() def call(self): """ 循环去获取任务函数并执行任务函数 """ current_thread = threading.currentThread self.generate_list.append(current_thread) event = self.q.get() while event != StopEvent: func, arguments, callback = event try: result = func(*arguments) success = True except Exception, e: success = False result = None if callback is not None: try: callback(success, result) except Exception, e: pass with self.worker_state(self.free_list, current_thread): event = self.q.get() else: self.generate_list.remove(current_thread) def terminal(self): """ 终止线程池中的所有线程 """ self.cancel = True full_size = len(self.generate_list) while full_size: self.q.put(StopEvent) full_size -= 1 @contextlib.contextmanager def worker_state(self, state_list, worker_thread): """ 用于记录线程中正在等待的线程数 """ state_list.append(worker_thread) try: yield finally: state_list.remove(worker_thread)
协程
又称为微线程:是一种用户态的轻量级线程;用户自己控制的;是在单线程中实现的;
协程拥有自己的寄存器上下文和栈;
1、无需线程上下文切换的开销;
2、无需原子操作锁定以及同步的开销;
3、方便切换数据流;
4、适用于高并发;
但是:
1、无法利用多核资源,需要和进程配合才可以;
2、进行阻塞Blocking操作(IO时)会阻塞掉整个程序;
#!/usr/bin/env python # _*_ coding:utf-8 _*_ __author__ = 'Charles' import gevent def foo(): print('�33[32;1mRunning in foo�33[0m') gevent.sleep(0) print('�33[32;1mExplicit context switch to foo again�33[0m') def bar(): print('�33[33;1mExplicit context to bar�33[0m') gevent.sleep(0) print('�33[33;1mImplicit context switch back to bar�33[0m') def ex(): print('�33[31;1mExplicit context to bar�33[0m') gevent.sleep(1) print('�33[31;1mImplicit context switch back to bar�33[0m') gevent.joinall([ gevent.spawn(foo), #启动三个协程 gevent.spawn(bar), gevent.spawn(ex), ]) #使用gevent,当遇到IO操作的时候(使用sleep模拟),协程就会切换;
使用gevent实现单线程下的多socket并发
Server side:
#!/usr/bin/env python # _*_ coding:utf-8 _*_ __author__ = 'Charles' import sys import socket import time import gevent from gevent import socket,monkey monkey.patch_all() #会将所有的操作变成非阻塞的 def server(port): s = socket.socket() s.bind(('0.0.0.0', port)) s.listen(500) while True: cli, addr = s.accept() gevent.spawn(handle_request, cli) def handle_request(conn): try: while True: data = conn.recv(1024) print("recv:", data) conn.send(data) if not data: conn.shutdown(socket.SHUT_WR) #没有数据就关闭连接 except Exception as ex: print(ex) finally: conn.close() if __name__ == '__main__': server(8001)
client
#!/usr/bin/env python # _*_ coding:utf-8 _*_ __author__ = 'Charles' import socket HOST = 'localhost' # The remote host PORT = 8001 # The same port as used by the server s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((HOST, PORT)) while True: msg = bytes(input(">>:"),encoding="utf8") s.sendall(msg) data = s.recv(1024) #print(data) print('Received', repr(data)) s.close()
事件驱动和异步IO
是一种编程范式;
1、单线程(同步);
2、多线程;
3、事件驱动编程模式;
nginx是多进程,单线程,异步IO的;