主键PRIMARY KEY
能通过它唯一区分记录的字段称为主键。也就是说,数据库中主键不能相同,一个主键只能有一条记录。比如下表如果设置name为主键,那么数据库中就不能存同名的其他人。
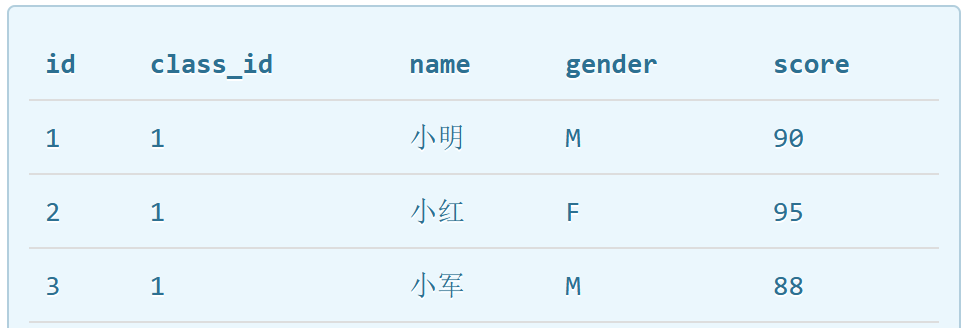
对主键的要求,最关键的一点是:记录一旦插入到表中,主键最好不要再修改,因为主键是用来唯一定位记录的,修改了主键,会造成一系列的影响。
因此主键最好选择与业务无关的字段,最好是无实际意义的字段,一般可以新增一个字段作为主键。例如上表中,选择name作为主键,那么表中就不允许同名的人,因此新增了id列,无实际业务意义,作为主键。主键不允许NULL类型,因此设置主键的列需要指定为NOT NULL。
主键有四种类型:
- 自增型:int类型,插入数据时系统自动分配一个自增数,简单方便最常用。
- GUID全局唯一标识符:是一种由算法生成的二进制长度为128位的数字标识符。
- 自定义唯一:自己定义的字符或数字,必须是唯一的。
- 联合主键:通过多个字段唯一标识记录,即两个或更多的字段都设置为主键,这种主键被称为联合主键。不常用。
最常用的是自增型和GUID。自增型主键效率高,占用空间小。GUID可扩展性强,理想情况下,地球上不会生成两个相同的GUID,但效率和空间比自增型差。因此小项目,简单事务都用自增型,如果需要经常迁移,建议使用GUID。
主键一般是在建表时创建的,当然之后也可以修改。语法如下:
CREATE TABLE <tablename> (list1name type primary key auto_increment, list1name type…);
auto_increment指定其是自增型主键。
外键FOREIGN KEY
通过外键字段,可以将该条记录和另外一个数据表关联。
比如我们还有一个class表,前面学生表中的class_id就可以设为外键,我们在class表中存储这个班级的其他信息,比如班干部班主任之类,这样使得数据分离的比较好,查询学生信息时不需要将冗余的班级信息也显示出来。
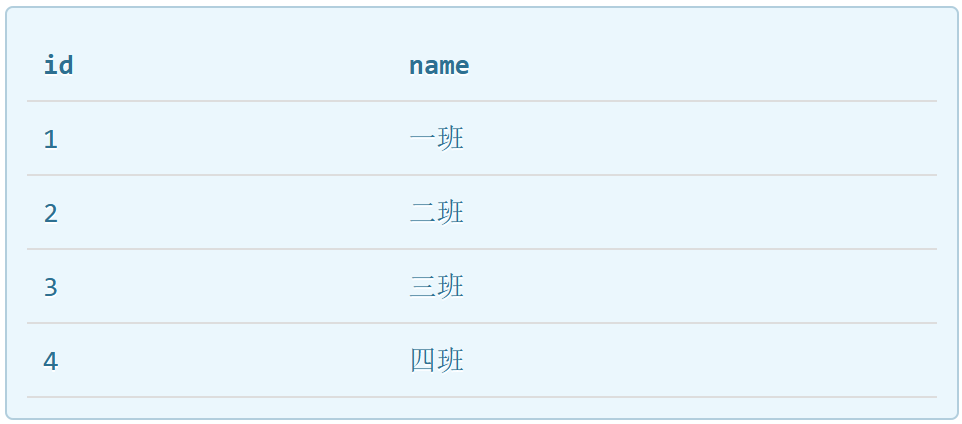
要知道的是,外键不是通过名称相同就关联的,而是通过程序约束实现的,下面的语句演示添加classid为外键:
ALTER TABLE students ADD CONSTRAINT fk_class_id FOREIGN KEY (class_id) REFERENCES classes (id);
其中,外键约束的名称fk_class_id可以任意,FOREIGN KEY (class_id)指定了class_id作为外键,REFERENCES classes (id)指定了这个外键将关联到classes表的id列(即classes表的主键)。
通过定义外键约束,关系数据库可以保证无法插入无效的数据。即如果classes表不存在id=99的记录,students表就无法插入class_id=99的记录。
外键约束会影响性能,很多公司并不设置外键约束,仅靠程序保证逻辑正确。
删除外键:
ALTER TABLE students DROP FOREIGN KEY fk_class_id;
该操作只是删除了外键约束,实际外键那一列没有被删除。
利用外键可以形成一对多的关系,多对多关系是通过中间表实现的。
索引
索引是关系数据库中对某一列或多个列的值进行预排序的数据结构。
通过使用索引,可以让数据库系统不必扫描整个表,而是直接定位到符合条件的记录,这样就大大加快了查询速度。
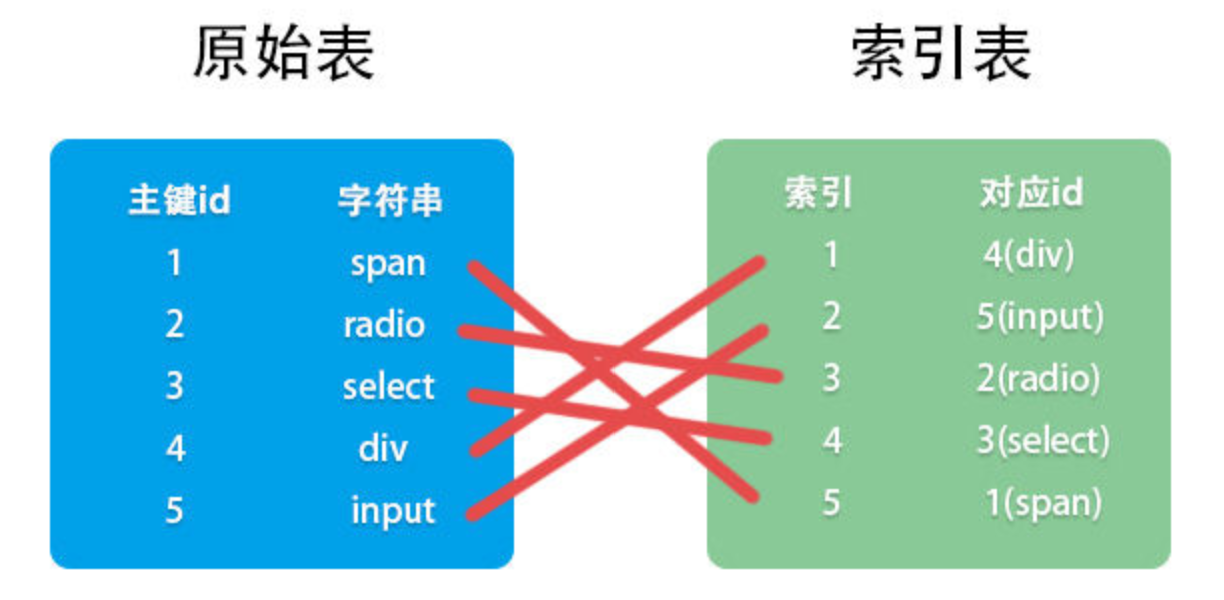
比如上表,当我们需要检索字符串input时,在原始表的input在表末,因此查找5次才能找到。而索引是对字符串进行排序得到一张索引表,查询时直接查找索引表,由于是有序的,就可以采用二分查找,提高效率。
索引的优点是提高了查询效率,缺点是在插入、更新和删除记录时,需要同时修改索引,因此,索引越多,插入、更新和删除记录的速度就越慢。因此要依据实际业务情况选择使用。
索引有四种:
· 主键索引:主键就是一种索引,对于主键,关系数据库会自动对其创建主键索引。使用主键索引的效率是最高的,因为主键会保证绝对唯一。关键字PRIMARY KEY.
· 普通索引:优化查询速度,可以重复。关键字INDEX或者KEY。
· 唯一索引:避免同一个表中某数据列中的值重复,比如身份证号我们可以设置唯一索引。UNIQUE KEY.
· 全文索引:用于特定情况,只能用于MyISAM类型的数据表、只能用于CHAR ,VARCHAR,TEXT数据列类型。FULLTEXT.
索引可以在表创建时添加,也可以在创建后修改。
例如学生表中可以对score创建索引:
ALTER TABLE students ADD INDEX idx_score (score); idx_score是索引名称,是任意的。
索引的效率取决于索引列的值是否散列,即该列的值如果越互不相同,那么索引效率越高。如果存在大量相同的值,则索引将失去意义。例如对性别创建索引就十分没必要。
像一些字段需要具有唯一性,比如身份证号,我们可以添加唯一索引:
ALTER TABLE students ADD UNIQUE INDEX uni_name (name);
无论是否创建索引,对于用户和应用程序来说,使用关系数据库不会有任何区别。当我们在数据库中查询时,如果有相应的索引可用,数据库系统就会自动使用索引来提高查询效率,如果没有索引,查询只是速度会变慢。因此,索引可以在使用数据库的过程中逐步优化。
别名
有时候表名列名很长,我们希望简短一些可以给他们起别名;
SELECT s.id,s.name, c.id
FROM students as s, classes as c;
s是students的别名,c是classes的别名,s.id为完全限定名,因为classes中也有id列,
不这样id有二义性,会报错。
给列名起别名格式:<表名>.<列名> as <别名> 给表名起别名格式:<表名> as <别名>。as 可以省略。
NULL值
NULL代表着空。
字段可以设置是否允许为NULL,默认允许为NULL,指定NOT NULL不允许为NULL,即插入记录时,该字段为NULL将会出错。
如果某条记录的某列为NULL,想匹配含NULL的记录,很自然会想到 where listname = NULL;但这个语法是错误的,NULL很特殊,因此mysql也提供了特殊的运算符针对NULL。
· IS NULL:筛选该列为NULL的记录,如 where list1 is null;
· IS NOT NULL:筛选不是NULL的记录。
NULL和空值:NULL表示不存在,空值即' ',空值为有效的值,两者不一样。空值可以用运算符<>=比较,而NULL用上述运算符比较。
变量
MySQL中的变量有4种,局部变量、用户变量、会话变量和全局变量。
· 局部变量:
仅用于BEGIN和END语句块之间,如用在存储过程中,作用域仅限该语句块。定义方式如下:
#定义变量 DECLARE varname INT DEFAULT 0; #给其赋值 方法1:SET varname=10; 方法2:使用INTO,见MySQL 其他常用语法中的存储过程
· 用户变量:
用户自定义的变量,作用域为当前连接。无需提前定义,使用@即表示这是一个变量。赋值方法:
方法1:用set赋值 SET @var:=10; 方法2:用select SELECT @var:=10; 方法3:用INTO,详见存储过程
SQL中给变量赋值用 :=,虽然set中使用=也可以赋值,但select中用=是不允许的,因此建议养成用 :=的习惯。
· 会话变量和全局变量:这是服务器端维护的变量,在此不表。