可以用字符串命令实现key-value的设置与获取,实现计数器功能,甚至实现位操作。
11.1 相关命令介绍
结构
字符串以key-value形式存储在redisDb的dict中的。字符串的key经过Hash之后作为dict的键,只能是string类型,字符串的value是dict的值,用结构体robj来表示。字符串值robj的type值为OBJ_STRING。
当字符串值是string类型时,encoding的值根据字符串的长短分别为OBJ_ENCODING_RAW或OBJ_ENCODING_EMBSTR;当字符串值是long类型时,encoding的值为OBJ_ENCODING_INT。
超时时间
字符串可以设置超时秒数或毫秒数。Redis会将秒数统一转换为毫秒数来设置。Redis将现在的毫秒时间戳+设置的毫秒数=过期时间戳。所有键的过期时间戳存储在redisDb的expire字典中,字典的key是字符串key经过Hash之后的值,value是字符串的到期毫秒时间戳。
计数器
当key不存在(值默认为0),或key的robj的encoding为OBJ_ENCODING_INT类型时,Redis直接对字符串值加减一个整型值,并将运算后的新值设置到redisDb中并返回,以此来实现计数器功能。如果值可以转换成float类型,也可以加减一个float值实现浮点数的计数器功能。
位操作
Redis提供了简单的位操作。Redis可以对字符串获取、设置任一字符的任一比特位,也可以对多个key进行位运算。在复杂的情况下,可以对多个连续的比特位进行获取和设置,而不论这几个bit位是否属于同一字节。
11.2 设置字符串
通过set相关命令将字符串设置到数据库,参数指定字符串的超时时间、设置条件等,同时也可以批量设置字符串。
11.2.1 set命令
如果key已经设置,会用新值覆盖旧值,不管原value是何种类型,如果在设置时不指定EX或PX参数,set命令会清除原有超时时间。
格式: SET key value [NX] [XX] [EX <seconds>] [PX <milliseconds>]
参数:
·NX: 当数据库中key不存在时,可以将key-value添加到数据库。
·XX: 当数据库中key存在时,可以将key-value设置到数据库,与NX参数互斥。
·EX: key的超时秒数。
·PX: key的超时毫秒数,与EX参数互斥。
将key-value添加到Redis数据库需要经过以下4个操作。
1.命令行解析额外参数
set命令共支持NX、XX、EX、PX这4个额外参数,在执行set命令时,需要首先对这4个参数进行解析,此时需要3个局部变量来辅助实现:
robj *expire = NULL; //超时时间,robj类型。Redis在解析命令行参数时,会将各个参数解析成robj类型,当expire值不为NULL则表示需要设置key的超时时间。
int unit = UNIT_SECONDS; //超时的单位,此值只有两个取值,分别为秒, 毫秒
int flags = OBJ_SET_NO_FLAGS; //int类型 一个二进制串,根据此值来确定key是否应该被设置到数据库。
#define OBJ_SET_NO_FLAGS 0
#define OBJ_SET_NX (1<<0) /* 标识key没有被设置过 */
#define OBJ_SET_XX (1<<1) /* 标识key已经存在 */
#define OBJ_SET_EX (1<<2) /* 标识key的超时时间被设置为单位秒 */
#define OBJ_SET_PX (1<<3) /* 标识key的超时时间被设置为单位毫秒 */
解析参数的具体过程:
(set、key、value 三个参数后) 从第4个参数开始依次向后通过for循环解析:
for (j = 3; j < c->argc; j++) {
char *a = c->argv[j]->ptr; //遍历的参数字符串
robj *next = (j == c->argc-1) ? NULL : c->argv[j+1]; //遍历的下个参数,最后一个为null
1)如果遇到参数NX(不区分大小写),并且没有设置过OBJ_SET_XX,表示key在没有被设置过的情况下才可以被设置,flags赋值如下。
flags |= OBJ_SET_NX;
2)如果遇到参数XX(不区分大小写),并且没有设置这OBJ_SET_NX时,表示key在已经被设置的情况下才可以被设置,flags赋值如下。
flags |= OBJ_SET_XX;
3)如果遇到参数EX(不区分大小写),并且没有设置过OBJ_SET_PX,且下个参数存在,表示key的过期时间单位为秒,秒数由下个参数指定。
flags |= OBJ_SET_EX;
unit = UNIT_SECONDS;
expire = next;
j++; //EX的下个参数肯定为秒数值,直接跳过下个参数的循环,j++
4)如果遇到参数PX(不区分大小写),并且没有设置过OBJ_SET_EX,且下个参数存在。表示key的过期时间单位为毫秒,毫秒数由下个参数指定。
flags |= OBJ_SET_PX;
unit = UNIT_MILLISECONDS;
expire = next;
j++;
2.value编码(优化)
c->argv[2] = tryObjectEncoding(c->argv[2]);
为了节省空间,在将key-value设置到数据库之前,根据value的不同长度和类型对value进行编码。编码的函数为
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
/* 1)判断o的类型是否为string类型。如果不为string类型则不能对robj类型进行操作:. */
serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
/* 判断o的encoding是否为sds类型,只有sds类型的数据才可以进一步优化: */
if (!sdsEncodedObject(o)) return o;
/*3)判断引用计数refcount,如果对象的引用计数大于1,表示此对象在多处被引用。在tryObjectEncoding函数结束时可能会修改o的值,所以贸然继续进行可能会造成其他影响,所以在refcount大于1的情况下,结束函数的运行,将o直接返回: */
if (o->refcount > 1) return o;
/*4)求value的字符串长度,当长度小于等于20时,试图将value转化为long类型,如果转换成功,则分为两种情况处理:*/
len = sdslen(s);
if (len <= 20 && string2l(s,len,&value)) {
第一种情况: 如果Redis的配置不要求运行LRU或LFU替换算法,并且转换后的value值小于OBJ_SHARED_INTEGERS,那么会返回共享数字对象。之所以这里的判断跟替换算法有关,是因为替换算法要求每个robj有不同的lru字段值,所以用了替换算法就不能共享robj了。通过上一章知道shared.integers是一个长度为10000的数组,里面预存了10000个数字对象,从0到9999。这些对象都是encoding=OBJ_ENCODING_INT的robj对象。
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
decrRefCount(o);
incrRefCount(shared.integers[value]);
return shared.integers[value];
} else {
第二种情况: 如果不能返回共享对象,那么将原来的robj的encoding改为OBJ_ENCODING_INT,这时robj的ptr字段直接存储为这个long型的值。robj的ptr字段本来是一个void*指针,所以在64位机器占8字节的长度,而一个long也是8字节,所以不论ptr存一个指针地址还是一个long型的值,都不会有额外的内存开销。
if (o->encoding == OBJ_ENCODING_RAW) {
sdsfree(o->ptr);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*) value;
return o;
} else if (o->encoding == OBJ_ENCODING_EMBSTR) {
decrRefCount(o);
return createStringObjectFromLongLongForValue(value);
}
}
}
/* 对于那些不能转成64位long的字符串最后再做两步处理*/
/* 1)如果字符串长度小于等于OBJ_ENCODING_EMBSTR_SIZE_LIMIT,定义为44,那么调用createEmbeddedStringObject将encoding改为OBJ_ENCODING_EMBSTR;
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
if (o->encoding == OBJ_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
decrRefCount(o);
return emb;
}
/*2)如果前面所有的编码尝试都没有成功,此时仍然是OBJ_ENCODING_RAW类型,且sds里空余字节过多 (SDS字符串末尾的可用空间超过10%),那么就会调用sds的sdsRemoveFreeSpace接口来释放空余字节。 */
trimStringObjectIfNeeded(o);
/* Return the original object. */
return o;
}
3.数据库添加key-value
当将value值优化好之后,调用setGenericCommand函数将key-value设置到数据库。
setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL);
if ((flags & OBJ_SET_NX && lookupKeyWrite(c->db,key) != NULL) ||
(flags & OBJ_SET_XX && lookupKeyWrite(c->db,key) == NULL))
{
addReply(c, abort_reply ? abort_reply : shared.null[c->resp]);
return;
}
当有OBJ_SET_NX标识时,需要保证当前数据库中没有key值。
当有OBJ_SET_XX时,需要保证当前数据库中已经有key值。否则直接报错退出。
当判断当前key-value可以写入数据库之后,调用setKey方法(redis 6中genericSetKey)将key-value写入数据库
void genericSetKey(client *c, redisDb *db, robj *key, robj *val, int keepttl, int signal) {
if (lookupKeyWrite(db,key) == NULL) {
dbAdd(db,key,val);
} else {
dbOverwrite(db,key,val);
}
incrRefCount(val);
if (!keepttl) removeExpire(db,key); //超时时间移除
if (signal) signalModifiedKey(c,db,key);
}
4.设置超时时间
Redis key的超时时间实际存储的是当前key的到期毫秒时间戳,指定超时时间单位为秒时,需要转化为毫秒数。Redis将所有含有超时时间的key存储到redisDb的expire字典内,第10章介绍的ttl命令可以快速确定key的超时秒数,就是通过查找这个字典实现的。
通过以上4个步骤已经成功地将一个key-value设置到Redis的数据库中。
setnx、setex、psetex命令的原理 :
这3个命令也是先调用了tryObjectEncoding将值优化,再调用setGenericCommand将key-value设置到数据库,只不过这3个命令不需要解析额外参数。
(1)setnx命令
格式:setnx key value
说明: 将key-value设置到数据库,当且仅当key不存在时。
源码分析: 在调用setGenericCommand时,将flags赋值为OBJ_SET_NX,表示只有key不存在时才可以执行函数。
(2)setex命令
格式:setex key seconds value
说明: 将key-value设置到数据库,并且指定key的超时秒数。
源码分析: 在调用setGenericCommand时,将flags赋值为OBJ_SET_NO_FLAGS,expire赋值为UNIT_SECONDS,表示不需要考虑数据库中是否存在key,且时间单位为秒。
(3)psetex命令
格式:psetex key milliseconds value
说明: 将key-value设置到数据库,并且指定key的超时毫秒数。
11.2.2 mset命令
通过set、setex等命令只能设置单个字符串到数据库,批量设置字符串时,可以使用mset或msetnx命令来解决。
格式:
mset key value [key value ...]
msetnx key value [key value ...]
mset和msetnx底层都是调用的msetGenericCommand函数,不过第2个参数mset的传参为0,msetnx传参为1,msetGenericCommand的函数定义如下:
void msetGenericCommand(client *c, int nx) {
int j;
//校验参数必须为偶数
if ((c->argc % 2) == 0) {
addReplyError(c,"wrong number of arguments for MSET");
return;
}
/* 当nx参数为1时,需要遍历每个key在数据库中是否存在. */
if (nx) {
for (j = 1; j < c->argc; j += 2) {
if (lookupKeyWrite(c->db,c->argv[j]) != NULL) {
addReply(c, shared.czero);
return;
}
}
}
//节省内存考虑,需要调用tryObjectEncoding函数将每个value编码,
//注意mset和msetex不能设置超时时间,所以不需要考虑expire。
for (j = 1; j < c->argc; j += 2) {
c->argv[j+1] = tryObjectEncoding(c->argv[j+1]);
setKey(c,c->db,c->argv[j],c->argv[j+1]);
notifyKeyspaceEvent(NOTIFY_STRING,"set",c->argv[j],c->db->id);
}
server.dirty += (c->argc-1)/2;
addReply(c, nx ? shared.cone : shared.ok);
}
11.3 修改字符串
命令实现不覆盖原值修改字符串。
11.3.1 append命令
value值需要追加字符串; 格式:append key value
说明: 如果key不存在,此命令等同于set key value命令。
当key存在时,首先判断下value的类型是否为string类型。如果不为string类型时会报错。
if (checkType(c,o,OBJ_STRING))
return;
判断追加后的字符串长度必须小于512MB,否则会报错。
append = c->argv[2];
totlen = stringObjectLen(o)+sdslen(append->ptr);
if (checkStringLength(c,totlen) != C_OK)
return;
set命令时为什么没有限制最大长度呢?
因为在服务端接收到命令的时候,就已经判断了命令的最大长度不能大于512 MB,所以set命令不需要再次判断了。
/* 值对象创建好之后,将新字符串追加到原字符串末尾 */
o = dbUnshareStringValue(c->db,c->argv[1],o);
o->ptr = sdscatlen(o->ptr,append->ptr,sdslen(append->ptr));
totlen = sdslen(o->ptr);
11.3.2 setrange命令
主要用于设置value的部分子串,从偏移量offset开始覆盖成value值。如果偏移值大于原值的长度,则偏移量之前的字符串由"x00"填充。
格式:setrange key offset value
首先判断offset参数必须为long类型且必须大于等于0,否则设置失败。
原key不存在时,会创建一个robj对象,并将robj先设置到数据库;
key存在时,会要求原值必须为string类型,并且value的长度加offset值必须小于512 MB。
如果原值是共享类型的,则需解除共享,新创建一个新robj对象,对新对象进行操作。
当value的长度加offset会大于原值长度时,需要额外分配空间用于存储新值并返回。此时调用了sdsgrowzero函数。只有当offset+sdslen(value)大于原值长度时才会扩充空间,否则直接返回原字符串。
o->ptr = sdsgrowzero(o->ptr,offset+sdslen(value));
memcpy((char*)o->ptr+offset,value,sdslen(value));
当有了robj的地址之后,从offset位置开始将value覆盖掉原值,通过memcpy函数来实现。
通过以上步骤,实现了字符串的setrange操作。
11.3.3 计数器命令
包括 incr / decr、incrby / decrby 和 incrbyfloat这5个相关命令,都是原子性的操作,不会并发导致统计出错。
格式:
incr key
decr key
说明: 将key存储的值加1或减1。
incrby key increment
decrby key decrement
说明: 将key存储的值加或减指定值(increment/decrement)。
底层都调用了incrDecrCommand函数,incrby和decrby命令会首先判断增量是否为整数,若不是则设置失败。incrDecrCommand的定义如下:
void incrDecrCommand(client *c, long long incr)
函数第2个参数为要增加的值,可以是正整数,也可以是负整数。
void incrDecrCommand(client *c, long long incr) {
long long value, oldvalue;
robj *o, *new;
//先从数据库中获取key。如果key不存在则设为默认值0;如果key存在则判断原value值是否为long类型,如果不是,报错退出
o = lookupKeyWrite(c->db,c->argv[1]);
if (o != NULL && checkType(c,o,OBJ_STRING)) return;
if (getLongLongFromObjectOrReply(c,o,&value,NULL) != C_OK) return;
//将原值赋值为oldvalue(如果原值不存在,此值默认为0),凡涉及的数字的增加或减少,都需要判断增加后的值是否越界,如果越界则是不合法的:
oldvalue = value;
if ((incr < 0 && oldvalue < 0 && incr < (LLONG_MIN-oldvalue)) ||
(incr > 0 && oldvalue > 0 && incr > (LLONG_MAX-oldvalue))) {
addReplyError(c,"increment or decrement would overflow");
return;
}
value += incr; //此时的value值为原值加上增量后的值
//robj的ptr直接存储一个long值,只要robj没有被引用且不是共享对象,ptr直接赋值value值。
if (o && o->refcount == 1 && o->encoding == OBJ_ENCODING_INT &&
(value < 0 || value >= OBJ_SHARED_INTEGERS) &&
value >= LONG_MIN && value <= LONG_MAX)
{
new = o;
o->ptr = (void*)((long)value);
} else {
//不满足条件,则创建robj类型的new变量,将new设置或覆盖掉数据库原key-value即完成了计数器操作。
new = createStringObjectFromLongLongForValue(value);
if (o) {
dbOverwrite(c->db,c->argv[1],new);
} else {
dbAdd(c->db,c->argv[1],new);
}
}
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"incrby",c->argv[1],c->db->id);
server.dirty++;
addReply(c,shared.colon);
addReply(c,new);
addReply(c,shared.crlf);
}
小结:
通过以上对计算器的操作可知,先获取到原值,再在原值的基础上加减一个整型增量,就完成了计数器的功能。如果当增量是浮点数类型时,也可以实现浮点数的计数器操作。
相关命令如下:
incrbyfloat key increment
incrbyfloat实现与incrby原理类似;
11.4 字符串获取
主要包括get、getset、getrange、strlen、mget等相关命令;
11.4.1 get
当key不存在时,返回NIL。
格式:get key
通过set命令可知,字符串的key设置在redisDb的dict字典中,值是robj对象。在get命令执行时,将key经过散列计算之后再在字典中找到相应的值,完成字符串的获取操作。
11.4.2 getset命令
getset将给定key的值设为value,并返回key的旧值。atomically原子性;
格式:getset key value
getset命令是get和set命令的结合体,只要知道了get和set命令的基本实现,此命令也会掌握。
11.4.3 getrange命令
获取字符串的部分子串。getrange返回key的value值从start截取到end的子字符串
格式:getrange key start end
void getrangeCommand(client *c) {
robj *o;
long long start, end;
char *str, llbuf[32];
size_t strlen;
//1)判断start和end的类型,这两个值都必须是整数类型。
if (getLongLongFromObjectOrReply(c,c->argv[2],&start,NULL) != C_OK)
return;
if (getLongLongFromObjectOrReply(c,c->argv[3],&end,NULL) != C_OK)
return;
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.emptybulk)) == NULL ||
checkType(c,o,OBJ_STRING)) return;
// 2)因为是对字符串获取子字符串,所以如果值的encoding为OBJ_ENCODING_INT类型时,需要将值转换为string类型。
if (o->encoding == OBJ_ENCODING_INT) {
str = llbuf;
strlen = ll2string(llbuf,sizeof(llbuf),(long)o->ptr);
} else {
str = o->ptr;
strlen = sdslen(str);
}
/* start和end不合法*/
if (start < 0 && end < 0 && start > end) {
addReply(c,shared.emptybulk);
return;
}
//5)格式化start和end值。
if (start < 0) start = strlen+start;
if (end < 0) end = strlen+end;
if (start < 0) start = 0;
if (end < 0) end = 0;
if ((unsigned long long)end >= strlen) end = strlen-1;
/* 格式化之后,start赋值为strlen与start的和,如果和为负数,则将其改为0;end赋值为strlen与end的和,如果和为负数则赋值为0,如果大于strlen,则赋值为strlen-1。*/
if (start > end || strlen == 0) {
addReply(c,shared.emptybulk);
} else {
//6)当start和end计算好之后,通过指针的偏移获取str相应的值并返回。
addReplyBulkCBuffer(c,(char*)str+start,end-start+1);
}
}
11.4.4 strlen命令
返回value字符串的长度。
格式:strlen key
获取到值robj的ptr之后,如果值类型是string类型,通过sdslen函数便可以获取到value的长度。如果值类型不是string类型,通过递归可以求出整型值的字符串长度:
size_t stringObjectLen(robj *o) {
serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
if (sdsEncodedObject(o)) {
return sdslen(o->ptr);
} else {
return sdigits10((long)o->ptr);
}
}
uint32_t digits10(uint64_t v) {
if (v < 10) return 1;
if (v < 100) return 2;
if (v < 1000) return 3;
if (v < 1000000000000UL) {
if (v < 100000000UL) {
if (v < 1000000) {
if (v < 10000) return 4;
return 5 + (v >= 100000);
}
return 7 + (v >= 10000000UL);
}
if (v < 10000000000UL) {
return 9 + (v >= 1000000000UL);
}
return 11 + (v >= 100000000000UL);
}
return 12 + digits10(v / 1000000000000UL);
}
11.4.5 mget命令
获取多个key的值,。
格式: mget key [key …]
Redis所有的key-value存储在redisDb的dict中,for循环依次从数据库中获取到key-value。
void mgetCommand(client *c) {
int j;
addReplyArrayLen(c,c->argc-1);
for (j = 1; j < c->argc; j++) {
robj *o = lookupKeyRead(c->db,c->argv[j]);
if (o == NULL) {
addReplyNull(c);
} else {
if (o->type != OBJ_STRING) {
addReplyNull(c);
} else {
addReplyBulk(c,o);
}
}
}
}
11.5 字符串位操作
位设置、操作、统计等命令主要包括setbit、getbit、bitpos、bitcount、bittop和 bitfield;
11.5.1 setbit命令
对key所存储的字符串值,设置指定偏移量上的比特位。
格式:setbit key offset value
返回值: 返回指定偏移量原来存储的位。

图11-1 字符串abc的二进制表示
如图11-1所示,二进制串"abc"在内存中表示的,现在字符串第9比特位的值为1,如果想设置此值为0,需要经过以下步骤。
1)判断offset是否合法,一个字节占8位,一个字符串最大长度为512 MB,所以当offset/8大于512 MB时表示offset不合法。
2)校验bit位只可能是0或1,其他字符不合法,on表示输入的value值。
if (on & ~1) {
addReplyError(c,err);
return;
}
3)取出比特位上字符和字节; 修改第offset个比特位,需要先取出第offset/8个字节,赋值为byteval,offset/8赋值为byte。例如,要修改第9个比特位,需要先取出第2个字节。
byte = bitoffset >> 3;//一个字节是8位,现在需要除以8,以定位到第byte个字节上
byteval = ((uint8_t*)o->ptr)[byte];//取出第byte个字节
4)获取当前位字节作为返回值bitval, 当取出byteval之后,需要判断原字符串第offset位上的值,供命令的返回值使用。将offset对8取模赋值为bit,bit表示byteval的从低位数第bit位。byteval与bit相与的结果如果大于0表示原比特为1,等于0表示原比特为0。
bit = 7 - (bitoffset & 0x7); //offset对8取模
bitval = byteval & (1 << bit);//1<<bit位表示将1从低位向左移bit位,获取到第bit位的位置
…
addReply(c, bitval ? shared.cone : shared.czero);
5)修改比特位的值。将byteval的从低位数第bit位强制赋值为1。on&0x1的值结果只能为0x1或0x0,将其左移bit位与byteval相或可以得出新的字节的值,o的第byte位赋值为新值便完成了字符串的设置比特位操作。
byteval &= ~(1 << bit);//1左移bit位,取反与原值相与,即将原值的低bit位赋值为0
byteval |= ((on & 0x1) << bit);//on&0x1的值为要修改后的值,左移bit位,与原值相或,即求出新值
((uint8_t*)o->ptr)[byte] = byteval;
11.5.2 getbit命令
对key所存储的字符串,获取指定偏移量上的比特位。返回 字符串指定偏移量上的位值。
格式:getbit key offset
首先判断offset值是否合法。并设置要定位到的第byte个字节,以及字节的从低位数第bit位。当byte值小于原字符串长度时,第offset位的值一定是0,所以只有在byte小于原字符串长度的情况下获取第offset位的值才有意义。
如果原值是字符串类型,直接获取比特位的值即可。
如果是数值类型,需要将值转换为字符串类型再获取比特位的值。
获取方法同setbit的获取方法相同。
byte = bitoffset >> 3; //一个字符是8位,现在需要除以8,以定位到第byte个字节上
bit = 7 - (bitoffset & 0x7); //取模
if (sdsEncodedObject(o)) {
if (byte < sdslen(o->ptr))
bitval = ((uint8_t*)o->ptr)[byte] & (1 << bit);
} else {
if (byte < (size_t)ll2string(llbuf,sizeof(llbuf),(long)o->ptr))
bitval = llbuf[byte] & (1 << bit) //低位开始,第bit个字符与1相与,求其值
}
11.5.3 bitpos命令
将key所存储的字符串当作一个字节数组,从第start个字节开始(注意已经经过了8*start个索引),返回第一个被设置为bit值的索引值。
格式:bitpos key bit [start [end]]
同getrange一样,命令执行开始需要格式化start和end的值,这里的start和end是原字符串第start和end个字节,并不是字节数组的第start到end个索引。
当start和end赋值好之后,将bytes赋值为需要查找的字节的个数,调用redisBitpos函数来查找值,其中p为字节数组:
bytes = end – start + 1;
long pos = redisBitpos(p+start,bytes,bit);
redisBitpos的函数定义如下:
long redisBitpos(void *s, unsigned long count, int bit)
CPU可以一次性从内存读取8字节的数据,有的CPU甚至只能从地址的8字节整数倍开始获取数据。如果字符串如果比较长,那么字符串的首地址可能不在8字节的整数倍上,所以需要先处理这部分数据。如果这部分数据不是0或UCHAR_MAX,则表示要查询的值在这个字节上,标识found=1。
/*逐字节跳过未与sizeof(unsigned long)对齐的初始位 */
skipval = bit ? 0 : UCHAR_MAX; //0或255
c = (unsigned char*) s;
found = 0;
//sizeof(*l)=8, 8字节对齐。
while((unsigned long)c & (sizeof(*l)-1) && count) {
//如果bit=1, 则找出第一个不是全0的字节,如果bit=0则找出第一个不是全1的
if (*c != skipval) {
found = 1;
break;
}
c++;
count--;
pos += 8;
}
如果此时已经定位到了要查询的字节上,或指针已经移出字符串(count等于0),或者剩余的字节数量已经不足8个,需要对这剩下的这些字节进行特殊处理以便找到相应的值:
c = (unsigned char*)l;
for (j = 0; j < sizeof(*l); j++) { //处理8个字节
word <<= 8;
if (count) {
word |= *c;
c++;
count--;
}
}
此时如果要查找的比特为1,而word值为0,证明查找不到,直接报错退出。
if (bit == 1 && word == 0) return -1;
对赋值好的word进行处理。此时的one为除最高位为1之外,剩下全为0的二进制值,当((one&word)!=0)==bit时表示找到了相应的位置,返回pos即可,否则找不到查找的位置。
one = ULONG_MAX; /* All bits set to 1.*/
one >>= 1; /* All bits set to 1 but the MSB. */
one = ~one; /* All bits set to 0 but the MSB. */
while(one) {
if (((one & word) != 0) == bit) return pos;
pos++;
one >>= 1;
}
11.5.4 bitcount命令
获取字符串从start字节到end字节比特位值为1的数量。
格式:bitcount key [start] [end]
计算二进制串中1的数量比较常见的算法有3种,以字符串abc的二进制串0110000101100010011100011为例,此二进制串中共有10个1。
(1)遍历法
每次将二进制串与0x1相与,然后右移,直到原字符串为0时截止:
while(n>0)
{
if (n&0x1 == 1)
{
i++;
}
n = n>>1;
}
这种算法while循环的次数为n的长度。
(2)快速法
每次将二进制串的最低位1变为0,直到n变为0为止。
while(n>0)
{
n = n&(n-1);
i++;
}
算法相对于第一种算法来说效率有所提升,由于每次都是n&(n-1),初始时n有几个1就循环几次即可。
3)variable-precision swar算法
观察表11-1中的几个数,然后以这几个数作为掩码参与计算
表11-1 swar算法掩码

利用这4个数作为掩码参与运算:
int swar(uint32_t i)
{
//计算每2位二进制数中1的个数
i = ( i & 0x55555555) + ((i >> 1) & 0x55555555);
//计算每4位二进制数中1的个数
i = (i & 0x33333333) + ((i >> 2) & 0x33333333);
//计算每8位二进制数中1的个数
i = (i & 0x0F0F0F0F) + ((i >> 4) & 0x0F0F0F0F);
//将每8位当作一个int8的整数,然后相加求和
i = (i * 0x01010101) >> 24);
return i;
}
以字符串"abc"为例逐步说明。
①计算每两位二进制数中1的个数之后的值,如表11-2所示。
表11-2 swar算法第1步

②计算每四位二进制数中1的个数之后的值,如表11-3所示。
表11-3 swar算法第2步

③计算每八位二进制数中1的个数之后的值,如表11-4所示。
表11-4 swar算法第3步

④将每8位当作一个int8的整数,然后相加可以得出1的数量为10。其中i*0x01010101可以看成是:
i*0x01010101
= i*0x00000001 + i*0x00000100 + i*0x00010000 + i*0x01000000
//i*1(左移0位)+i*28(左移8位)+i*216(左移16位)+i*264(左移24位)
可用图11-2表示,如下所示。
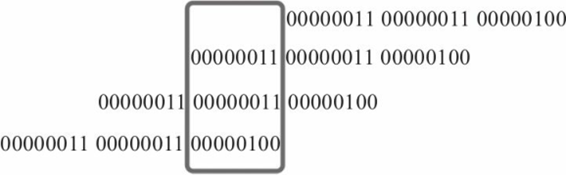
图11-2 swar算法结果获取
(4)统计二进制中1的数量
Redis中统计二进制中1的数量采用查表法和swar算法相结合方式计算。所谓查表法是定义一个数组,数组的各项为十进制0~255中所含1的数量,定义如下:
static const unsigned char bitsinbyte[256] = {0,1,1,2,1,2,2,3,1,..};
CPU一次性可以读取8个字节的内存值,Redis采用swar算法,且一次性处理4字节的内容,所以要先将非4字节整数倍地址的字节特殊处理,处理方法为:
/* 计算未对齐32位的初始字节 */
while((unsigned long)p & 3 && count) {
bits += bitsinbyte[*p++];
count--;
}
当处理完前面最多3个可能的字节之后,便采用swar算法来获取1的数量:
p4 = (uint32_t*)p; //4字节
while(count>=28) {
uint32_t aux1, aux2, aux3, aux4, aux5, aux6, aux7;
aux1 = *p4++; //一次读取4字节
aux2 = *p4++; //一次读取4字节
...
aux7 = *p4++;
count -= 28; //当前共处理了4×7=28字节,所以总长度需要减28字节
aux1 = aux1 - ((aux1 >> 1) & 0x55555555); //每两位, 高位移到低位, 原来的低位清0, 相减之
aux1 = (aux1 & 0x33333333) + ((aux1 >> 2) & 0x33333333);
...
bits += ((((aux1 + (aux1 >> 4)) & 0x0F0F0F0F) +
...
((aux7 + (aux7 >> 4)) & 0x0F0F0F0F))* 0x01010101) >> 24;
}
当count的数量小于28之后,便可以用查表法计算出剩余的二进制1的数量了。
p = (unsigned char*)p4;
while(count--) bits += bitsinbyte[*p++];
return bits;
11.5.5 bitop命令
对一个或多个key执行元操作,并将结果保存在一个新的key上,其中op_name可以是AND、OR、NOT、XOR这4种操作的任意一种。
格式:bitop op_name target_key key [key …]
命令执行时,key的数量设置为numkeys,用objects、src、len这3个指针数组分别存储key的robj、sds值和字符串长度并分别赋值。
src = zmalloc(sizeof(unsigned char*) * numkeys); //字符串数组,保存sds值
len = zmalloc(sizeof(long) * numkeys); //长度数组,存放sds的长度
objects = zmalloc(sizeof(robj*) * numkeys); //对象数组,保存字符串对象
for (j = 0; j < numkeys; j++) {
o = lookupKeyRead(c->db,c->argv[j+3]);
/* Handle non-existing keys as empty strings. */
....
/* Return an error if one of the keys is not a string. */
....
objects[j] = getDecodedObject(o);
src[j] = objects[j]->ptr;
len[j] = sdslen(objects[j]->ptr);
if (len[j] > maxlen) maxlen = len[j]; //求所有key中最长长度的key
if (j == 0 || len[j] < minlen) minlen = len[j]; //求所有key中最短长度的key
}
同bitcount思想一致,当minlen大于32时,bitop命令也会一次性处理32个字节来加快速度,下面我们以AND操作为例说明:
unsigned long *lp[16];//16个指针
unsigned long *lres = (unsigned long*) res;
…
if (op == BITOP_AND) {
while(minlen >= sizeof(unsigned long)*4) {
for (i = 1; i < numkeys; i++) { //lres指向res的地址, 所以lres初始时是第一个key的值
lres[0] &= lp[i][0]; //lp为long类型, lp[i][0]会一次性取8个字节的数据,所以lp[i][0]到lp[i][1]会跳8个字节
lres[1] &= lp[i][1];
lres[2] &= lp[i][2];
lres[3] &= lp[i][3];
lp[i]+=4; //lp[i]+4会跳32个字节
}
lres+=4; //lres向后偏移32个字节
j += sizeof(unsigned long)*4; //j+32
minlen -= sizeof(unsigned long)*4;
}
}
从以上代码看出,当minlen大于32时便可以进入for循环,一次for循环可以处理4个unsigned long型的数据,即32个字节,所以当此while循环结束的时候,只剩下不到32字节的数据了,对剩下的数据按字节处理就可以得到最终的结果。
/* j is set to the next byte to process by the previous loop. */
for (; j < maxlen; j++) { //len[i]是每个key的长度
output = (len[0] <= j) ? 0 : src[0][j]; //如果j小于长度则肯定为0, 否则取src[0][j]的值
if (op == BITOP_NOT) output = ~output;
for (i = 1; i < numkeys; i++) { //遍历所有输入键,对所有输入的scr[i][j]字节进行运算
byte = (len[i] <= j) ? 0 : src[i][j]; //如果数组的长度不足,表示key的长度已经小于j,那么相应的字节被假设为0
switch(op) {
case BITOP_AND: output &= byte; break;
case BITOP_OR: output |= byte; break;
case BITOP_XOR: output ^= byte; break;
}
}
res[j] = output;
}
res为最终返回的结果,将结果保存在dest_key即完成了字符串的bitop操作。
11.5.6 bitfield命令
将字符串当成一个二进制数组,并对这个字节数组第offset位开始进行获取、设置、增加值等。
格式:bitfield key [get type offset] [set type offset value] [incrby type offset increment] [overflow WRAP|SAT|FAIL]
参数:
1)type: 有符号或无符号的宽度,例如i8表示有符号的8位,u10表示无符号的10位。
2)offset: 开始操作的二进制数组的索引。
3)value: set操作要设置成的值。
4)increment: 自增操作要增加的值。
5)overflow: 有3个参数WRAP、SAT、FAIL,意义分别如下。
·WRAP:使用回绕方式处理有符号或无符号整数的溢出情况。对于无符号整数来说,回绕就像数值本身能够被存储的最大无符号数值进行取模。对于有符号的整数来说,数值本身为正数,则将数值与最大有符号数值进行取模,数值本身为负数,则将所有高位置1,低位保持原样。
·SAT:使用饱和方式处理溢出。上溢的结果为最大整数,下溢的结果为最小整数。
·FAIL:当结果出现上溢或下溢时,返回空值,拒绝执行。返回值: 返回一个数组,数组的各项是此命令各个子命令的执行结果。
当使用get命令对超出字符串当前范围内的二进制进行访问时,超出部分的二进制的值当作是0。使用set或incr命令对超出字符串当前范围的二进制位进行访问将导致字符串被扩大,被扩大的部分会使用值为0的二进制位进行填充。该命令最大支持64位长的有符号整数以及63位长的无符号整数。
为了实现bitfield命令,Redis用了一个结构体辅助实现:
struct bitfieldOp {
uint64_t offset; /* 偏移量. */
int64_t i64; /* incr或set的值*/
int opcode; /* 操作码. */
int owtype; /* 溢出控制 */
int bits; /* type值的宽度. */
int sign; /*type值的有符号或无符号标识 */
};
bitfield命令被执行时,需要逐个解析参数,并将各个子命令格式化到bitfieldOp结构体数组里:
struct bitfieldOp *ops = NULL; /* Array of ops to execute at end. */
for (j = 2; j < c->argc; j++) {
...
/* Populate the array of operations we'll process. */
ops = zrealloc(ops,sizeof(*ops)*(numops+1));
ops[numops].offset = bitoffset; //偏移量
ops[numops].i64 = i64; //设置值
ops[numops].opcode = opcode; //操作
ops[numops].owtype = owtype; //溢出控制
ops[numops].bits = bits; //宽度
ops[numops].sign = sign; //符号位, 有符号值为1, 无符号值为0
numops++;
}
假设type值为'i8',则将被解析成有符号的8位宽度的值,sign值为1,bits值为8。
先来看一下get操作的执行过程。根据bitoffset和bits已经知道了要获取的偏移量和获取的宽度。现在只需要考虑获取有符号数据和无符号数据即可。
获取无符号数据: 比较简单,只需要获取bits个字节即可:
uint64_t getUnsignedBitfield(unsigned char *p, uint64_t offset, uint64_t bits) {
uint64_t byte, bit, byteval, bitval, j, value = 0;
for (j = 0; j < bits; j++) { //获取从第offset位开始的bits个二进制位
byte = offset >> 3; //求出在第几个字节上
bit = 7 - (offset & 0x7);
byteval = p[byte];
bitval = (byteval >> bit) & 1;
value = (value<<1) | bitval;
offset++;
}
return value;
}
value就是获取到的宽度为bits的无符号二进制数据。
有符号数据的获取,(uint64_t)1<<(bits-1))可以获取到符号位上的值,如果符号位上的值为1,表示此值为负数。宽度比较低的负数在转换成宽度较长的负数时,除了将符号位置为1外,高低应该全补1。-1在计算机里的二进制表示为全1,-1左移bits位表示低(bits-1)位置0,高位全置1,与原值相与得到了高位全为1,低位为正常值的一个负数。
if (bits < 64 && (value & ((uint64_t)1 << (bits-1)))) //符号位为1,表示负数
value |= ((uint64_t)-1) << bits; //所有的高位补1
return value;
对于set和incrby操作,顾名思义,set就是将value设置到指定偏移量,incrby就是将原值加上value。这些比较简单,最后来看一下set或incrby之后可能出现的溢出的操作。
溢出
我们假设有符号或无符号的最大值为max,最小值为min,value表示原始的二进制串的int64值,incr表示值的增量,另外两个maxincr和minincr定义如下:
maxincr = max-value;
minincr = min-value;
①当value大于max,或者incr>maxincr时;
②当value小于min,或者incr<minincr时。
通过上文可知,溢出时有3种处理情况,分别为WRAP、SAT、FAIL。下面来看一下有符号和无符号的溢出处理。当溢出控制参数为SAT时,向上溢出直接返回最大值max,向下溢出直接返回0。
当溢出控制参数为WARP时分两种情况。
(1)无符号的溢出处理
将value与max取模得出最终值(即溢出后又从0开始累加得出最终值):
uint64_t mask = ((uint64_t)-1) << bits;
uint64_t res = value+incr;
res &= ~mask;
(2)有符号的溢出处理
符号位为1代表负数,此时将溢出的高位全置1,低位保留原值。
符号位为0代表正数,仍然同无符号处理一致取模得出最终值:
uint64_t msb = (uint64_t)1 << (bits-1);
uint64_t a = value, b = incr, c;
c = a+b; /* Perform addition as unsigned so that's defined. */
if (bits < 64) {
uint64_t mask = ((uint64_t)-1) << bits;
if (c & msb) {
c |= mask;
} else {
c &= ~mask;
}
}
从这里可以看出,无论是有符号还是无符号的溢出,都是将原值取模得出低bits位,然后正数高位补0,负数高位补1得出最终值。当我们得出最终的二进制串值之后,将原字符串从offset位开始,取value的低bits的位设置成新值。这样就完成了bitfiled操作。
11.6 本章小结
本章介绍了Redis的字符串命令。set和get命令在Redis中是最常用的命令。字符串命令底层借助于sds来实现,通过robj结构体来实现数据的设置和获取。字符串key-value和超时时间存储在redisDb的字典里。