JDK ByteBuffer
当我们进行数据传输的时候,往往需要使用缓冲区,常用的缓存区就是JDK NIO类库提供的java.nio.Buffer;
实际上,7种基础类型(Boolean除外)都有自己的缓冲区实现,对于NIO编程而言,我们主要使用的是ByteBuffer;从功能角度而言,ByteBuffer完全可以满足NIO编程的需要,但是对于NIO编程的复杂性,ByteBuffer也具有局限性,它的缺点如下:
-
ByteBuffer长度固定,一旦分配完成,它的容量不能动态扩展和收缩,当需要编码的POJO对象大于ByteBuffer的容量时,会发生索引越界; -
ByteBuffer只有一个标识位置的指针position,读写的时候需要手工调用flip()和rewind()等; -
ByteBuffer的API功能有限,一些高级和实用的特性它不支持,需要使用者自己实现;
JDK ByteBuffer由于只有一个位置指针用于处理读写操作,因此每次读写的时候都需要额外调用flip()和clear()等方法,否则功能将会出错;
capacity:缓冲区中的最大数据容量,它代表这个缓冲区的容量,一旦设定就不可以更改;比如 capacity 为 1024 的 IntBuffer,代表其一次可以存放 1024 个 int 类型的值
position: 被写入或者读取的元素索引,值由get()/put()自动更新,被初始为0;
limit:指定还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)
mark: 标记着当前position可读或可写的索引值
从写操作模式到读操作模式切换的时候(flip),position 都会归零,这样就可以从头开始读写了;
写操作模式下,limit 代表的是最大能写入的数据,这个时候 limit 等于 capacity;
写结束后,切换到读模式,此时的 limit 等于 Buffer 中实际的数据大小,因为 Buffer 不一定被写满了;
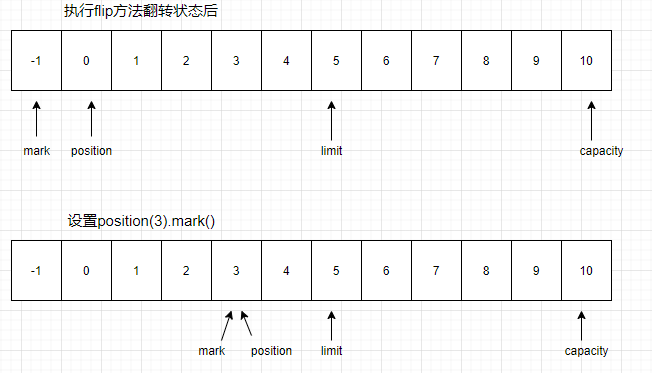
java.nio.Buffer#flip 用于状态翻转
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
java.nio.Buffer#mark
public final Buffer mark() {
mark = position;
return this;
}
关系:mark <= position <= limit <= capacity
测试demo如下:
public class ByteBufferTest {
public static void main(String[] args) {
CharBuffer buffer = CharBuffer.allocate(10);
System.out.println("---读取数据前——-");
printBuffer(buffer);
for(int i= 0 ; i < 5 ; i++) {
buffer.put(String.valueOf(i).charAt(0));
}
System.out.println("---读取数据后——-");
printBuffer(buffer);
System.out.println("当前buffer值:" + buffer);
buffer.flip();
System.out.println("---调用flip方法后——-");
printBuffer(buffer);
System.out.println("当前buffer值:" + buffer);
System.out.println("---设置position(3).mark()——-");
buffer.position(3).mark();
printBuffer(buffer);
System.out.println("---设置position(3).limit(6).mark().position(5)——-");
buffer.position(3).limit(6).mark().position(5);
printBuffer(buffer);
System.out.println("---调用clear方法后——-");
buffer.clear();
printBuffer(buffer);
System.out.println("---调用duplicate方法后——-");
CharBuffer dupeBuffer = buffer.duplicate();
printBuffer(dupeBuffer);
System.out.println("---dupeBuffer调用clear方法后——-");
dupeBuffer.clear();
printBuffer(dupeBuffer);
}
private static void printBuffer(Buffer buffer) {
System.out.println("[limit=" + buffer.limit()
+", position = " + buffer.position()
+", capacity = " + buffer.capacity() + "]");
}
}
执行结果如下:
---读取数据前——- [limit=10, position = 0, capacity = 10] ---读取数据后——- [limit=10, position = 5, capacity = 10] 当前buffer值: ---调用flip方法后——- [limit=5, position = 0, capacity = 10] 当前buffer值:01234 ---设置position(3).mark()——- [limit=5, position = 3, capacity = 10] ---设置position(3).limit(6).mark().position(5)——- [limit=6, position = 5, capacity = 10] ---调用clear方法后——- [limit=10, position = 0, capacity = 10] ---调用duplicate方法后——- [limit=10, position = 0, capacity = 10] ---dupeBuffer调用clear方法后——- [limit=10, position = 0, capacity = 10]
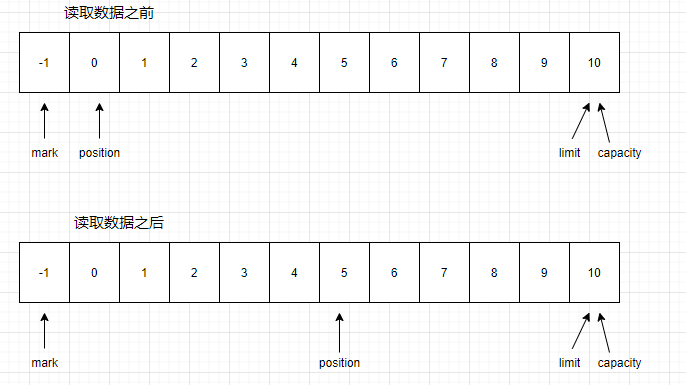
当执行flip()操作后,它的limit被设置为position,position设置为0,capacity不变,读取的内容是从position到limit之间;
上图如果不执行flip操作,buffer读取到是position到limit之间的内容,因此测试代码中第一次打印buffer为空,第二次即执行flip操作后,buffer打印为01234;

ByteBuffer有其局限性,缺点如下:
-
ByteBuffer长度固定,一旦分配完成,它的容量不能动态扩展和收缩,当需要编码的POJO对象大于ByteBuffer的容量时,会发生索引越界异常;
-
ByteBuffer 只有一个标识位置的指针position,读写的时候需要手工调用flip()和rewind()等,使用者必须小心谨慎地处理这些API;
-
ByteBuffer的API功能有限,需要使用者自己实现;
Netty ByteBuf
从结构上来说,ByteBuf 由Byte数组构成的缓冲区;数组中每个字节用来存放信息;
ByteBuf 通过两个位置指针来协助缓冲区的读写操作,一个用于读取数据,一个用于写入数据;这两个索引通过在字节数组中移动,来定位需要读或者写信息的位置;读操作使用readerIndex,写操作使用writerIndex;
测试demo如下:
public class NettyByteBuf {
public static void main(String[] args) {
// 创建byteBuf对象,该对象内部包含一个字节数组byte[10]
// 通过readerindex和writerIndex和capacity,将buffer分成三个区域
// 已经读取的区域:[0,readerindex)
// 可读取的区域:[readerindex,writerIndex)
// 可写的区域: [writerIndex,capacity)
ByteBuf byteBuf = Unpooled.buffer(10);
System.out.println("写入前 byteBuf -> " + byteBuf);
for (int i = 0; i < 8; i++) {
byteBuf.writeByte(i);
}
System.out.println("写入后 byteBuf ->" + byteBuf);
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("执行getByte方法:");
for (int i = 0; i < 5; i++) {
stringBuilder.append(byteBuf.getByte(i)).append(" ");
}
System.out.println(stringBuilder.toString());
System.out.println("调用getByte方法后 byteBuf ->" + byteBuf);
stringBuilder.setLength(0);
stringBuilder.append("执行readByte方法:");
for (int i = 0; i < 5; i++) {
stringBuilder.append(byteBuf.readByte()).append(" ");
}
System.out.println(stringBuilder.toString());
System.out.println("调用readByte方法后 byteBuf ->" + byteBuf);
}
}
执行结果如下:
写入前 byteBuf -> UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeHeapByteBuf(ridx: 0, widx: 0, cap: 10) 写入后 byteBuf ->UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeHeapByteBuf(ridx: 0, widx: 8, cap: 10) 执行getByte方法:0 1 2 3 4 调用getByte方法后 byteBuf ->UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeHeapByteBuf(ridx: 0, widx: 8, cap: 10) 执行readByte方法:0 1 2 3 4 调用readByte方法后 byteBuf ->UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeHeapByteBuf(ridx: 5, widx: 8, cap: 10)
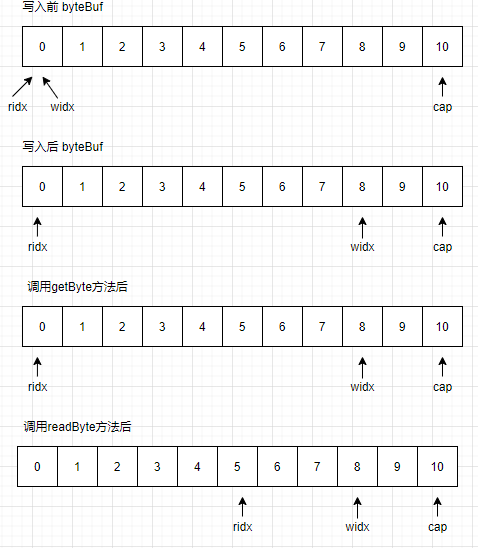
rederIndex和writerIndex的取值一开始都是0,随着数据的写入writerIndex会增加,读取数据会使rederIndex增加,但它不会超过writerIndex;
在读取之后,[0,readerindex)之间的数据被视为discard,调用discardReadBytes方法,可以释放这部分空间,它的作用类似ByteBuffer的compact方法;
[readerindex,writerIndex)之间的数据是可读取的,等价于ByteBuffer position到limit之间的数据;
[writerIndex,capacity)之间的空间是可写的,等价于ByteBuffer limit到capacity之间的可用空间;
由于写操作不修改rederIndex指针,读操作不修改writerIndex指针,因此读写间不再需要调整位置指针,简化了缓存区的读写操作,避免了由于遗漏flip()操作导致功能的异常;
关于JVM内存与对外内存如下:
java.nio.ByteBuffer#allocate: 分配空间位于JVM中(也称JVM堆内存),分配空间需要从外界Java程序接收到外部传来的数据时,首先被系统内存获取,然后再由系统内存复制拷贝到JVM内存中供Java程序使用;
java.nio.ByteBuffer#allocateDirect: 分配的内存是系统内存(也称直接内存),无需复制;
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,某些情况下这部分内存也会被频繁地使用,而且也可能导致OutOfMemoryError异常出现;Java里用DirectByteBuffer可以分配一块直接内存(堆外内存),元空间对应的内存也叫作直接内存,它们对应的都是机器的物理内存;
参考:[《深入理解 Java 虚拟机 第三版》2.2.7 小节]

Netty的接收和发送ByteBuffer堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝;
如果使用传统的JVM堆内存进行Socket读写,JVM会将堆内存Buffer拷贝一份到直接内存中,然后才能写入Socket中。JVM堆内存的数据是不能直接写入Socket中的。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝 ;
测试代码如下:
public static void heapAccess() {
long startTime = System.currentTimeMillis();
//分配堆内存
ByteBuffer buffer = ByteBuffer.allocate(1000);
for (int i = 0; i < 100000; i++) {
for (int j = 0; j < 200; j++) {
buffer.putInt(j);
}
buffer.flip();
for (int j = 0; j < 200; j++) {
buffer.getInt();
}
buffer.clear();
}
long endTime = System.currentTimeMillis();
System.out.println("堆内存访问:" + (endTime - startTime));
}
public static void directAccess() {
long startTime = System.currentTimeMillis();
//分配直接内存
ByteBuffer buffer = ByteBuffer.allocateDirect(1000);
for (int i = 0; i < 100000; i++) {
for (int j = 0; j < 200; j++) {
buffer.putInt(j);
}
buffer.flip();
for (int j = 0; j < 200; j++) {
buffer.getInt();
}
buffer.clear();
}
long endTime = System.currentTimeMillis();
System.out.println("直接内存访问:" + (endTime - startTime));
}
从程序运行结果看出直接内存申请较慢,但访问效率高,JVM堆内存则相反;
在JVM实现上,本地IO会直接操作直接内存(直接内存=>系统调用=>硬盘/网卡),而非直接内存则需要二次拷贝(堆内存=>直接内存=>系统调用=>硬盘/网卡);