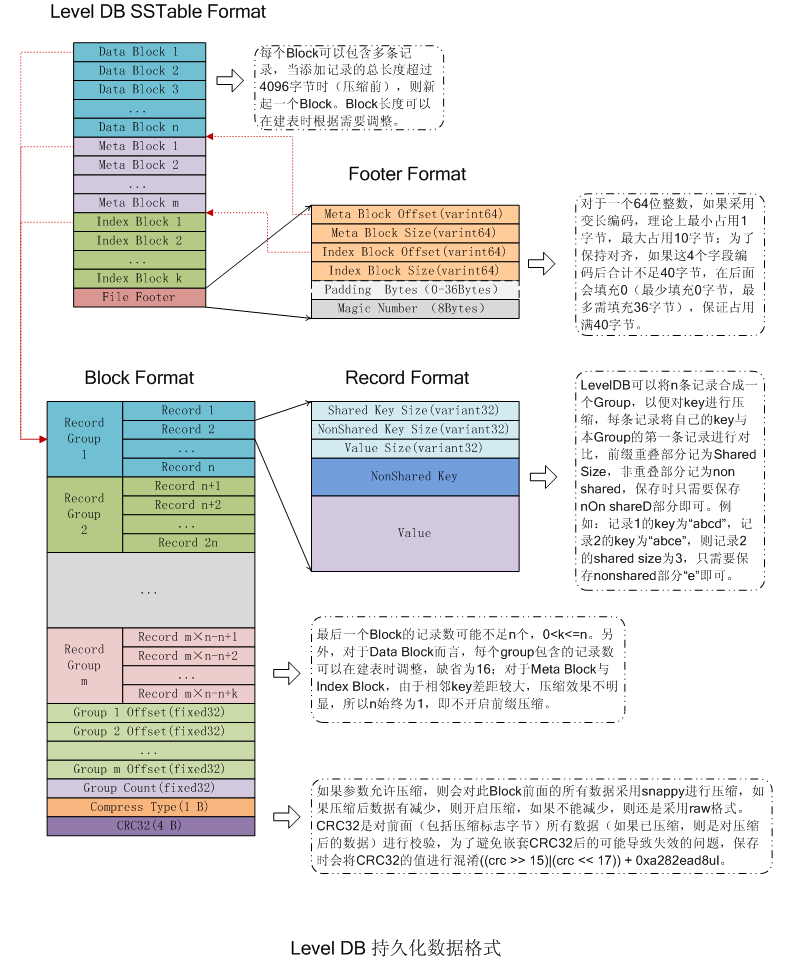
整体上,sstable文件分为数据区与索引区,尾部的footer指出了meta index block与data index block的偏移与大小,data index block指出了各data block的偏移与大小,meta index block指出了各meta block的偏移与大小。
1)DataBlock:存储Key-Value记录,分为Data、type、CRC三部分
2)MetaBlock:暂时没有使用
3)MetaBlock_index:记录filter的相关信息(本文暂时没有考虑filter)
4)IndexBlock:描述一个DataBlock,存储着对应DataBlock的最大Key值,DataBlock在.sst文件中的偏移量和大小
5)Footer :索引的索引,记录IndexBlock和MetaIndexBlock在SSTable中的偏移量了和大小
footer
先看footer结构。如下图。footer位于sstable文件尾部,占用空间固定为48个字节。其末尾8个字节是一个magic_number。metaindex_handle与index_handle物理上占用了40个字节,但实际上存储可能连32字节都不到。每一个handle的结构BlockHandle如右图,逻辑上分别表示offset+size,在内存中占用16个字节,但存储时由于采用可变长度编码,每个handle的物理存储通常不到8+8字节。因此这里两个handle总共占用不到32个字节,剩余填充0。

leveldb footer + block handle
BlockHandle指出了block的偏移与大小。在sstable文件中,一般有多个data block,多个meta block(当前版本只有一个filter block,可扩充),1个meta index block,1个data index block。其中filter block的内部结构稍微不同于其他Block,但都是用BlockHandle来指向的。
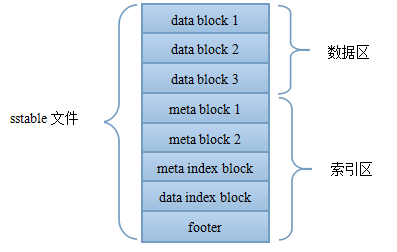
block
逻辑上主要分为数据与重启点。重启点也是一个指针,指出了一些特殊的位置。data block中的key是有序存储的,相邻的key之间可能有重复,因此存储时采用前缀压缩,后一个key只存储与前一个key不同的部分。那些重启点指出的位置就表示该key不按前缀压缩,而是完整存储该key。除了减少压缩空间之外,重启点的第二个作用就是加速读取。如果说data index block可以通过二分来定位具体的block,那么重启点则可以通过二分的方法来定位具体的重启点位置,进一步减少了需要读取的数据。对于leveldb来讲,可以通过options.block_size与options.block_restart_interval来设置block的大小与重启点的间隔。默认data block的大小为4K。而重启点则每隔16个key。具体的单条record的存储格式如下图所示。
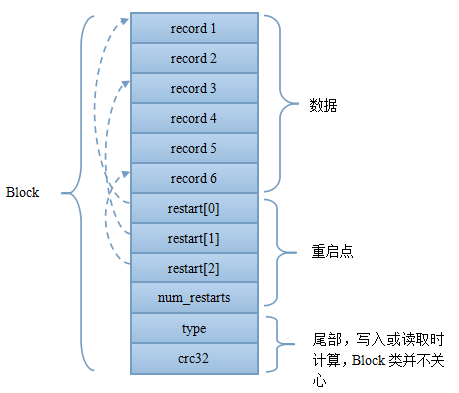
Block格式

Record 格式
data index block
Index Block的结构与Data Block一样,只不过每个group只包含一条记录,即Data Block的最大Key与偏移。其实这里说最大Key并不是很准确,理论上,只要保存最大Key就可以实现二分查找,但是Level DB在这里做了个优化,它并保存最大key,而是保存一个能分隔两个Data Block的最短Key,如:假定Data Block1的最后一个Key为“abcdefg”,Data Block2的第一个Key为“abzxcv”,则index可以记录Data Block1的索引key为“abd”;这样的分割串可以有很多,只要保证Data Block1中的所有Key都小于等于此索引,Data Block2中的所有Key都大于此索引即可。这种优化缩减了索引长度,查询时可以有效减小比较次数。
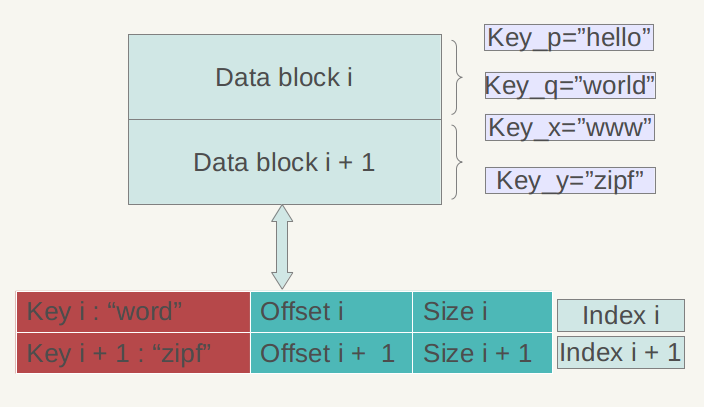
data block与meta index block、data index block都是采用block来存储的(filter block稍微不同)。而对于block来讲,其都是按(key,value)格式存储一条条的record的。对于这些不同类型的block,其(key,value)都是什么了?总结如下图。现在只有一个meta block用于filter,因此meta index block中也只有一条记录,其key是filter. + filter_policy的name。
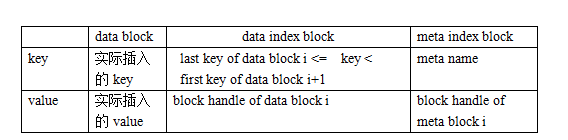
不同block的key, value
sstable格式