注:本文是人工智能研究网的学习笔记
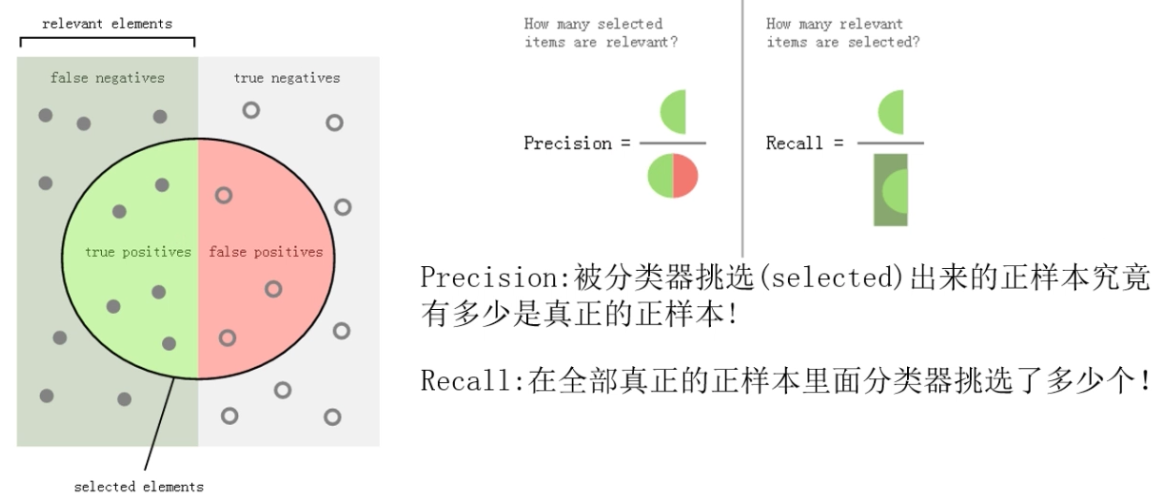
Precision和Recall都能够从下面的TP,TN,FP,FN里面计算出来。
几个缩写的含义:
| 缩写 | 含义 |
|---|---|
| P | condition positive |
| N | condition negative |
| TP | true positive (with hit) |
| TN | true negative (with correct rejection) |
| FP | false positive (with false alarm, Type I error) |
| FN | false negative (with miss, Type II error) |
TP: 我认为是真的,结果确实是真的
TN: 我认为是假的,结果确实是假的
FP: 我认为是真的,结果是假的
FN: 我认为是假的,结果是真的
T / F: 表名我预测的结果的真假
P / N: 表名我所认为的真还是假

precision和recall的进一步解释
precision和accuracy的区别
简单的来说,给定一组测量点的集合:
精确(precision): 所有的测量点到测量点集合的均值非常接近,与测量点的方差有关。就是说各个点紧密的聚合在一起。
准确(accuracy): 所有的测量点到真实值非常接近。与测量点的偏差有关。
以上两个概念是相互独立的,因此数据点集合可以使accurate的,也可以使precise的,还可以都不是或者都是。

二元分类问题

from sklearn import metrics
y_pred = [0, 1, 0, 0]
y_true = [0, 1, 0, 1]
print(metrics.precision_score(y_true, y_pred)) # 1.0
print(metrics.recall_score(y_true, y_pred)) # 0.5
# beta值越小,表示越看中precision
# beta值越大,表示越看中recall
print(metrics.f1_score(y_true, y_pred)) # 0.666666666667
print(metrics.fbeta_score(y_true, y_pred, beta=0.5)) # 0.833333333333
print(metrics.fbeta_score(y_true, y_pred, beta=1)) # 0.666666666667
print(metrics.fbeta_score(y_true, y_pred, beta=2)) # 0.555555555556
将二元分类指标拓展到多类和或多标签问题中

from sklearn import metrics
y_pred = [0, 1, 2, 0, 1, 2]
y_true = [0, 2, 1, 0, 0, 1]
print(metrics.precision_score(y_true, y_pred, average='macro'))
print(metrics.recall_score(y_true, y_pred, average='micro'))
print(metrics.f1_score(y_true, y_pred, average='weighted'))
print(metrics.fbeta_score(y_true, y_pred, beta=0.5, average='macro'))
print(metrics.precision_recall_fscore_support(y_true, y_pred, beta=0.5, average=None))
