CopyOnWriteArrayList这是一个ArrayList的线程安全的变体。
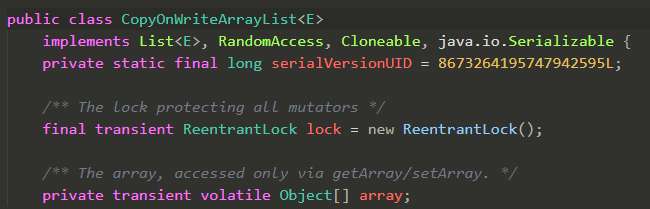
原理大概可以通俗的理解为:
初始化的时候只有一个容器,长时间内容器数据、数量等没有发生变化的时候,多个线程都是读取(假设这段时间里只发生读取的操作)同一个容器中的数据,所以这样大家读到的数据都是唯一、一致、安全的。
往里面增加数据:CopyOnWriteArrayList 底层实现添加的原理是先copy出一个容器(可以简称副本),再往新的容器里添加这个新的数据,最后把新的容器的引用地址赋值给了之前那个旧的的容器地址,但是在添加这个数据的期间,其他线程如果要去读取数据,仍然是读取到旧的容器里的数据。
设计思想:
CopyOnWriteArrayList 就是通过 Copy-On-Write(COW),即写时复制的思想来通过延时更新的策略来实现数据的最终一致性,并且能够保证读线程间不阻塞。
CopyOnWriteArrayList,就是用空间换时间,更新的时候基于副本更新,避免锁,然后最后用volatile变量来赋值保证可见性,更新的时候对读线程没有任何的影响!
缺点:
1、内存占用问题;
2、数据不能实时一致性:基于add时先行拷贝副本再修改引用的实现,所以CopyOnWrite 容器只能保证数据的最终一致性,不能保证数据的实时一致性。
应用场景:
随着元素数量和线程数量增加,CopyOnWriteArrayList在增加元素和删除元素时的性能下降非常明显,并且性能会比ArrayList低。
但在查找元素这点上随着线程数的增长,性能较ArrayList会好很多。例如在元素数量为1000、线程数量为100时,CopyOnWriteArrayList查找元素的性能大概为ArrayList的4倍。
根据这样的运行结果,在读多写少的并发场景中,CopyOnWriteArrayList较之ArrayList是更好的选择
关键代码:
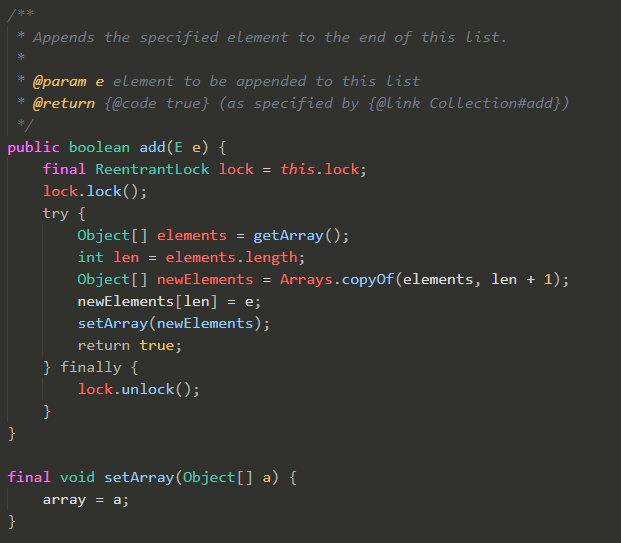
get:get(int index) 没有加任何锁和同步机制

add:新增元素场景,会进行新数据的创建和拷贝;数组元素越大,耗时约久,性能越差
数组引用是 volatile 修饰的,因此将旧的数组引用指向新的数组,根据 volatile 的 happens-before 规则,写线程对数组引用的修改对读线程是可见的。
CopyOnWrite 思想在Kafka源码中的运用:
在Kafka的内核源码中,有这么一个场景,客户端在向Kafka写数据的时候,会把消息先写入客户端本地的内存缓冲,然后在内存缓冲里形成一个Batch之后再一次性发送到Kafka服务器上去,这样有助于提升吞吐量。
话不多说,大家看下图:

这个时候Kafka的内存缓冲用的是什么数据结构呢?大家看源码:
这个数据结构就是核心的用来存放写入内存缓冲中的消息的数据结构,要看懂这个数据结构需要对很多Kafka内核源码里的概念进行解释,这里先不展开。
但是大家关注一点,他是自己实现了一个CopyOnWriteMap,这个CopyOnWriteMap采用的就是CopyOnWrite思想。
我们来看一下这个CopyOnWriteMap的源码实现:
所以Kafka这个核心数据结构在这里之所以采用CopyOnWriteMap思想来实现,就是因为这个Map的key-value对,其实没那么频繁更新。
也就是TopicPartition-Deque 这个key-value对,更新频率很低。
但是他的get操作却是高频的读取请求,因为会高频的读取出来一个TopicPartition对应的Deque数据结构,来对这个队列进行入队出队等操作,所以对于这个map而言,高频的是其get操作。
这个时候,Kafka就采用了CopyOnWrite思想来实现这个Map,避免更新key-value的时候阻塞住高频的读操作,实现无锁的效果,优化线程并发的性能。