一、背景简介
分布式系统中存在很多拆分的服务,在不断迭代升级的过程中,会出现如下常见的棘手情况:
某个技术组件版本升级,依赖包升级导致部分语法或者API过期,或者组件修复紧急的漏洞,从而会导致分布式系统下各个服务被动的升级迭代,很容易引发意外的问题;不同的服务中对组件的依赖和版本各不相同,从而导致不兼容问题的出现,很难对版本做统一的管理和维护,一旦出现问题很容易手忙脚乱,引发蝴蝶效应;
所以在复杂的系统中,对于依赖的框架和组件进行统一管理和二次浅封装,可以较大程度降低上述问题的处理成本与风险,同时可以更好的管理和控制技术栈。
二、框架浅封装
1、浅封装作用
为什么浅封装,核心目的在于统一管理和协调组件的依赖与升级,并对常用方法做一层包装,实际上很多组件使用到的功能点并不多,只是在业务中的使用点很多,这样给组件本身的迭代升级带来了一定的难度:
例如某个组件常用的API中存在巨大风险漏洞,或者替换掉过期的用法,需要对整个系统中涉及的地方做升级,这种操作的成本是非常高的;
如果是对这种常用的组件方法进行二次包装,作为处理业务的工具方法,那么解决上面的问题就相对轻松许多,只要对封装的工具方法升级,服务的依赖升级即可,降低时间成本和风险。
通过浅封装的手段,可以实现两个方面的解耦:
业务与技术
技术栈中常用的方法进行二次浅封装,这样可以较大程度的降低业务与技术的耦合,如此可以独立的升级技术栈,扩展功能而不影响业务服务的迭代。
框架与组件
不同的框架与组件都需要一定程度的自定义配置,同时分模块管理,在不同的服务中引入特定的依赖,也可以在基础包中做统一依赖,以此实现技术栈的快速组合搭配。
这里说的浅封装,是指包装常规常用的语法,组件本身就是技术层面的深度封装,所以也不可能完全隔开技术栈原生用法。
2、统一版本控制
例如微服务架构下,不同的研发组负责不同的业务模块,然而受到开发人员的经验和能力影响,很容易出现不同的服务组件选型不一致,或者相同的组件依赖版本不同,这样很难对系统架构做标准的统一管理。
对于二次封装的方式,可以严格的控制技术栈的迭代扩展,以及版本冲突的问题,通过对二次封装层的统一升级,可以快速实现业务服务的升级,解决不同服务的依赖差异问题。
三、实践案例
1、案例简介
Java分布式系统中,微服务基础组件(Nacos、Feign、Gateway、Seata)等,系统中间件(Quartz、Redis、Kafka、ElasticSearch,Logstash)等,对常用功能、配置、API等,进行二次浅封装并统一集成管理,以满足日常开发中基础环境搭建与临时工具的快速实现。
- butte-flyer 组件封装的应用案例;
- butte-frame 常用技术组件二次封装;
2、分层架构
整体划分五层:网关层、应用层、业务层、中间件层、基础层,组合成一套分布式系统。

服务总览
| 服务名 | 分层 | 端口 | 缓存库 | 数据库 | 描述 |
|---|---|---|---|---|---|
| flyer-gateway | 网关层 | 8010 | db1 | nacos | 路由控制 |
| flyer-facade | 应用层 | 8082 | db2 | facade | 门面服务 |
| flyer-admin | 应用层 | 8083 | db3 | admin | 后端管理 |
| flyer-account | 业务层 | 8084 | db4 | account | 账户管理 |
| flyer-quartz | 业务层 | 8085 | db5 | quartz | 定时任务 |
| kafka | 中间件 | 9092 | --- | ------ | 消息队列 |
| elasticsearch | 中间件 | 9200 | --- | ------ | 搜索引擎 |
| redis | 中间件 | 6379 | --- | ------ | 缓存中心 |
| logstash | 中间件 | 5044 | --- | es6.8.6 | 日志采集 |
| nacos | 基础层 | 8848 | --- | nacos | 注册配置 |
| seata | 基础层 | 8091 | --- | seata | 分布事务 |
| mysql | 基础层 | 3306 | --- | ------ | 数据存储 |
3、目录结构
在butte-frame中对各个技术栈进行二次封装管理,在butte-flyer中进行依赖引用。
butte-frame
├── frame-base 基础代码块
├── frame-jdbc 数据库组件
├── frame-core 服务基础依赖
├── frame-gateway 路由网关
├── frame-nacos 注册与配置中心
├── frame-seata 分布式事务
├── frame-feign 服务间调用
├── frame-security 安全管理
├── frame-search 搜索引擎
├── frame-redis 缓存管理
├── frame-kafka 消息中间件
├── frame-quartz 定时任务
├── frame-swagger 接口文档
└── frame-sleuth 链路日志
butte-flyer
├── flyer-gateway 网关服务:路由控制
├── flyer-facade 门面服务:功能协作接口
├── flyer-account 账户服务:用户账户
├── flyer-quartz 任务服务:定时任务
└── flyer-admin 管理服务:后端管理
4、技术栈组件
系统常用的技术栈:基础框架、微服务组件、缓存、安全管理、数据库、定时任务、工具依赖等。
| 名称 | 版本 | 说明 |
|---|---|---|
| spring-cloud | 2.2.5.RELEASE | 微服务框架基础 |
| spring-boot | 2.2.5.RELEASE | 服务基础依赖 |
| gateway | 2.2.5.RELEASE | 路由网关 |
| nacos | 2.2.5.RELEASE | 注册中心与配置管理 |
| seata | 2.2.5.RELEASE | 分布式事务管理 |
| feign | 2.2.5.RELEASE | 微服务间请求调用 |
| security | 2.2.5.RELEASE | 安全管理 |
| sleuth | 2.2.5.RELEASE | 请求轨迹链路 |
| security-jwt | 1.0.10.RELEASE | JWT加密组件 |
| hikari | 3.4.2 | 数据库连接池,默认 |
| mybatis-plus | 3.4.2 | ORM持久层框架 |
| kafka | 2.0.1 | MQ消息队列 |
| elasticsearch | 6.8.6 | 搜索引擎 |
| logstash | 5.2 | 日志采集 |
| redis | 2.2.5.RELEASE | 缓存管理与加锁控制 |
| quartz | 2.3.2 | 定时任务管理 |
| swagger | 2.6.1 | 接口文档 |
| apache-common | 2.7.0 | 基础依赖包 |
| hutool | 5.3.1 | 基础工具包 |
四、微服务组件
1、Nacos
Nacos在整个组件体系中,提供两个核心能力,注册发现:适配微服务注册与发现标准,快速实现动态服务注册发现、元数据管理等,提供微服务组件中最基础的能力;配置中心:统一管理各个服务配置,集中在Nacos中存储管理,隔离多环境的不同配置,并且可以规避线上配置放开的风险;
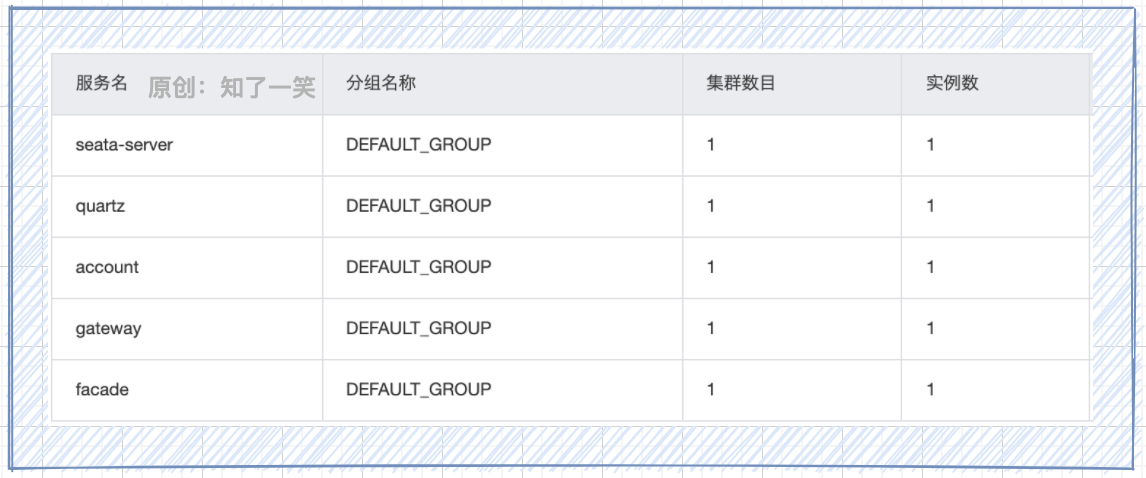
连接管理
spring:
cloud:
nacos:
# 配置读取
config:
prefix: application
server-addr: 127.0.0.1:8848
file-extension: yml
refresh-enabled: true
# 注册中心
discovery:
server-addr: 127.0.0.1:8848
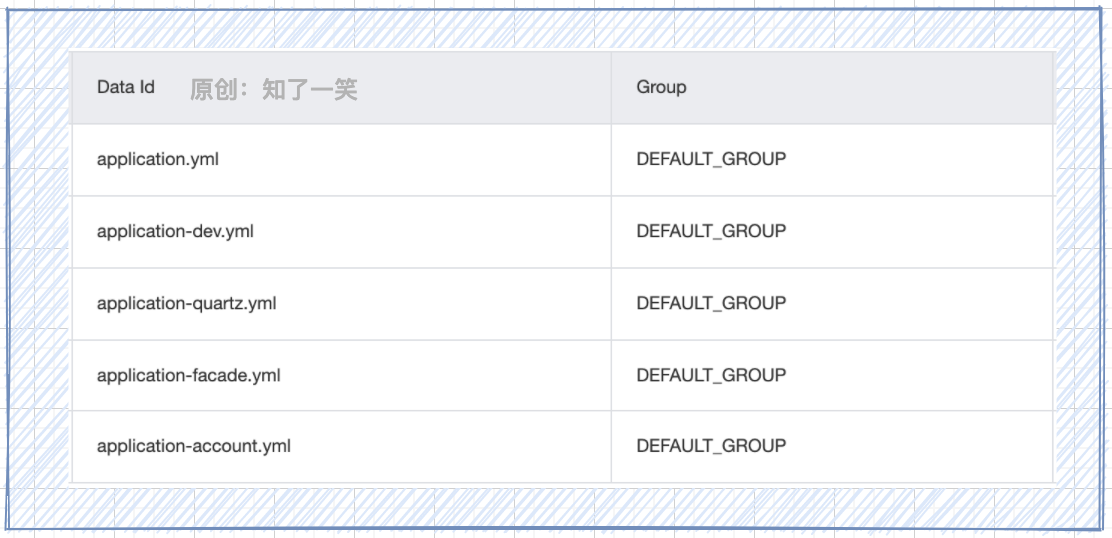
配置管理
- bootstrap.yml :服务中文件,连接和读取Nacos中配置信息;
- application.yml :公共基础配置,这里配置mybatis组件;
- application-dev.yml :中间件连接配置,用作环境标识隔离;
- application-def.yml :各个服务的自定义配置,参数加载;
2、Gateway
Gateway网关核心能力,提供统一的API路由管理,作为微服务架构体系下请求唯一入口,还可以在网关层处理所有的非业务功能,例如:安全控制,流量监控限流,等等。
路由控制:各个服务的发现和路由;
@Component
public class RouteFactory implements RouteDefinitionRepository {
@Resource
private RouteService routeService ;
/**
* 加载全部路由
* @since 2021-11-14 18:08
*/
@Override
public Flux<RouteDefinition> getRouteDefinitions() {
return Flux.fromIterable(routeService.getRouteDefinitions());
}
/**
* 添加路由
* @since 2021-11-14 18:08
*/
@Override
public Mono<Void> save(Mono<RouteDefinition> routeMono) {
return routeMono.flatMap(routeDefinition -> {
routeService.saveRouter(routeDefinition);
return Mono.empty();
});
}
}
全局过滤:作为网关的基础能力;
@Component
public class GatewayFilter implements GlobalFilter {
private static final Logger logger = LoggerFactory.getLogger(GatewayFilter.class);
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
String uri = request.getURI().getPath() ;
String host = String.valueOf(request.getHeaders().getHost()) ;
logger.info("request host : {} , uri : {}",host,uri);
return chain.filter(exchange);
}
}
3、Feign
Feign组件是声明式的WebService客户端,使微服务之间的调用变得更简单,Feign通过注解手段,将请求进行模板化和接口化管理,可以更加标准的管理各个服务间的通信交互。
响应解码:定义Feign接口响应时解码逻辑,校验和控制统一的接口风格;
public class FeignDecode extends ResponseEntityDecoder {
public FeignDecode(Decoder decoder) {
super(decoder);
}
@Override
public Object decode(Response response, Type type) {
if (!type.getTypeName().startsWith(Rep.class.getName())) {
throw new RuntimeException("响应格式异常");
}
try {
return super.decode(response, type);
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e.getMessage());
}
}
}
4、Seata
Seata组件是开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务,实现AT、TCC、SAGA、XA事务模式,支持一站式的分布式解决方案。
事务配置:基于nacos管理Seata组件的参数定义;
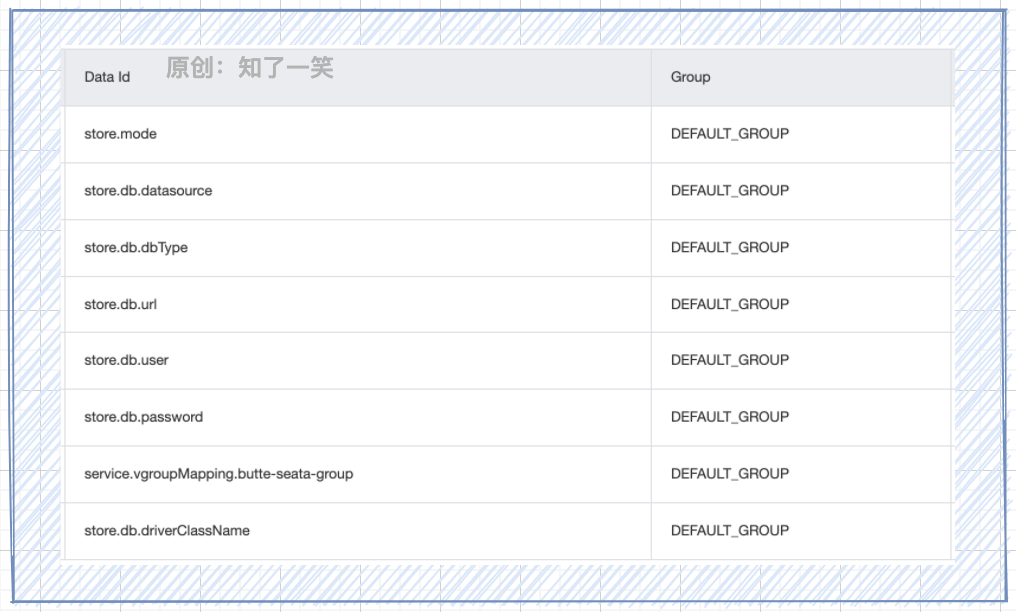
服务注册:在需要管理分布式事务的服务中连接和使用Seata服务;
seata:
enabled: true
application-id: ${spring.application.name}
tx-service-group: butte-seata-group
config:
type: nacos
nacos:
server-addr: ${spring.cloud.nacos.config.server-addr}
group: DEFAULT_GROUP
registry:
type: nacos
nacos:
server-addr: ${spring.cloud.nacos.config.server-addr}
application: seata-server
group: DEFAULT_GROUP
五、中间件集成
1、Kafka
Kafka是由Apache开源,具有分布式、分区的、多副本的、多订阅者,基于Zookeeper协调的分布式消息处理平台,由Scala和Java语言编写。还常用于搜集用户在应用服务中产生的日志数据。
消息发送:封装消息发送的基础能力;
@Component
public class KafkaSendOperate {
@Resource
private KafkaTemplate<String, String> kafkaTemplate ;
public void send (SendMsgVO entry) {
kafkaTemplate.send(entry.getTopic(),entry.getKey(),entry.getMsgBody()) ;
}
}
消息消费:消费监听时有两种策略;
- 消息生产方自己消费,通过Feign接口去执行具体消费服务的逻辑,这样有利于流程跟踪排查;
- 消息消费方直接监听,减少消息处理的流程节点,当然也可以打造统一的MQ总线服务(文尾);
public class KafkaListen {
private static final Logger logger = LoggerFactory.getLogger(KafkaListen.class);
/**
* Kafka消息监听
* @since 2021-11-06 16:47
*/
@KafkaListener(topics = KafkaTopic.USER_TOPIC)
public void listenUser (ConsumerRecord<?,String> record, Acknowledgment acknowledgment) {
try {
String key = String.valueOf(record.key());
String body = record.value();
switch (key){ }
} catch (Exception e){
e.printStackTrace();
} finally {
acknowledgment.acknowledge();
}
}
}
2、Redis
Redis是一款开源组件,基于内存的高性能的key-value数据结构存储系统,它可以用作数据库、缓存和消息中间件,支持多种类型的数据结构,如字符串、集合等。在实际应用中,通常用来做变动频率低的热点数据缓存和加锁机制。
KV数据缓存:作为Redis最常用的功能,即缓存一个指定有效期的键和值,在使用时直接获取;
@Component
public class RedisKvOperate {
@Resource
private StringRedisTemplate stringRedisTemplate ;
/**
* 创建缓存,必须带缓存时长
* @param key 缓存Key
* @param value 缓存Value
* @param expire 单位秒
* @return boolean
* @since 2021-08-07 21:12
*/
public boolean set (String key, String value, long expire) {
try {
stringRedisTemplate.opsForValue().set(key,value,expire, TimeUnit.SECONDS);
} catch (Exception e){
e.printStackTrace();
return Boolean.FALSE ;
}
return Boolean.TRUE ;
}
}
Lock加锁机制:基于spring-integration-redis中RedisLockRegistry,实现分布式锁;
@Component
public class RedisLockOperate {
@Resource
protected RedisLockRegistry redisLockRegistry;
/**
* 尝试一次加锁,采用默认时间
* @param lockKey 加锁Key
* @return java.lang.Boolean
* @since 2021-09-12 13:14
*/
@SneakyThrows
public <T> Boolean tryLock(T lockKey) {
return redisLockRegistry.obtain(lockKey).tryLock(time, TimeUnit.MILLISECONDS);
}
/**
* 释放锁
* @param lockKey 解锁Key
* @since 2021-09-12 13:32
*/
public <T> void unlock(T lockKey) {
redisLockRegistry.obtain(lockKey).unlock();
}
}
3、ElasticSearch
ElasticSearch是一个基于Lucene的搜索服务器,它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,Elasticsearch是用Java开发的,是当前流行的企业级搜索引擎。
索引管理:索引的创建和删除,结构添加和查询;
基于ElasticsearchRestTemplate的模板方法操作;
@Component
public class TemplateOperate {
@Resource
private ElasticsearchRestTemplate template ;
/**
* 创建索引和结构
* @param clazz 基于注解类实体
* @return java.lang.Boolean
* @since 2021-08-15 19:25
*/
public <T> Boolean createPut (Class<T> clazz){
boolean createIf = template.createIndex(clazz) ;
if (createIf){
return template.putMapping(clazz) ;
}
return Boolean.FALSE ;
}
}
基于RestHighLevelClient原生API操作;
@Component
public class IndexOperate {
@Resource
private RestHighLevelClient client ;
/**
* 判断索引是否存在
* @return boolean
* @since 2021-08-07 18:57
*/
public boolean exists (IndexVO entry) {
GetIndexRequest getReq = new GetIndexRequest (entry.getIndexName()) ;
try {
return client.indices().exists(getReq, entry.getOptions());
} catch (Exception e) {
e.printStackTrace();
}
return Boolean.FALSE ;
}
}
数据管理:数据新增、主键查询、修改、批量操作,业务性质的搜索封装复杂度很高;
数据的增删改方法;
@Component
public class DataOperate {
@Resource
private RestHighLevelClient client ;
/**
* 批量更新数据
* @param entry 对象主体
* @since 2021-08-07 18:16
*/
public void bulkUpdate (DataVO entry){
if (CollUtil.isEmpty(entry.getDataList())){
return ;
}
// 请求条件
BulkRequest bulkUpdate = new BulkRequest(entry.getIndexName(),entry.getType()) ;
bulkUpdate.setRefreshPolicy(entry.getRefresh()) ;
entry.getDataList().forEach(dataMap -> {
UpdateRequest updateReq = new UpdateRequest() ;
updateReq.id(String.valueOf(dataMap.get("id"))) ;
updateReq.doc(dataMap) ;
bulkUpdate.add(updateReq) ;
});
try {
// 执行请求
client.bulk(bulkUpdate, entry.getOptions());
} catch (IOException e) {
e.printStackTrace();
}
}
}
索引主键查询,分组查询方法;
@Component
public class QueryOperate {
@Resource
private RestHighLevelClient client ;
/**
* 指定字段分组查询
* @since 2021-10-07 19:00
*/
public Map<String,Object> groupByField (QueryVO entry){
Map<String,Object> groupMap = new HashMap<>() ;
// 分组API
String groupName = entry.getGroupField()+"_group" ;
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(0) ;
TermsAggregationBuilder termAgg = AggregationBuilders.terms(groupName)
.field(entry.getGroupField()) ;
sourceBuilder.aggregation(termAgg);
// 查询API
SearchRequest searchRequest = new SearchRequest(entry.getIndexName());
searchRequest.source(sourceBuilder) ;
try {
// 执行API
SearchResponse response = client.search(searchRequest, entry.getOptions());
// 响应结果
Terms groupTerm = response.getAggregations().get(groupName) ;
if (CollUtil.isNotEmpty(groupTerm.getBuckets())){
for (Terms.Bucket bucket:groupTerm.getBuckets()){
groupMap.put(bucket.getKeyAsString(),bucket.getDocCount()) ;
}
}
} catch (IOException e) {
e.printStackTrace();
}
return groupMap ;
}
}
4、Logstash
Logstash是一款开源的数据采集组件,具有实时管道功能。Logstash能够动态的从多个来源采集数据,进行标准化转换数据,并将数据传输到所选择的存储容器。
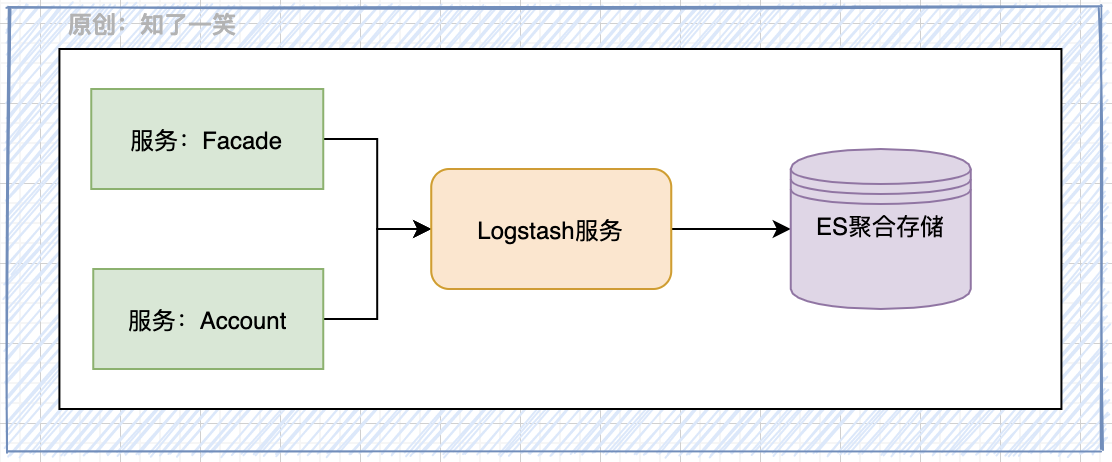
- Sleuth:管理服务链路,提供核心TraceId和SpanId生成;
- ElasticSearch:基于ES引擎做日志聚合存储和查询;
- Logstash:提供日志采集服务,和数据发送ES的能力;
logback.xml:服务连接Logstash地址,并加载核心配置;
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml" />
<springProperty scope="context" name="APP_NAME" source="spring.application.name" defaultValue="butte_app" />
<springProperty scope="context" name="DES_URI" source="logstash.destination.uri" />
<springProperty scope="context" name="DES_PORT" source="logstash.destination.port" />
<!-- 输出到LogStash配置,需要启动LogStash服务 -->
<appender name="LogStash"
class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>${DES_URI:- }:${DES_PORT:- }</destination>
<encoder
class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${APP_NAME:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
</configuration>
5、Quartz
Quartz是一个完全由java编写的开源作业调度框架,用来执行各个服务中的定时调度任务,在微服务体系架构下,通常开发一个独立的Quartz服务,通过Feign接口去触发各个服务的任务执行。
配置参数:定时任务基础信息,数据库表,线程池;
spring:
quartz:
job-store-type: jdbc
properties:
org:
quartz:
scheduler:
instanceName: ButteScheduler
instanceId: AUTO
jobStore:
class: org.quartz.impl.jdbcjobstore.JobStoreTX
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
tablePrefix: qrtz_
isClustered: true
clusterCheckinInterval: 15000
useProperties: false
threadPool:
class: org.quartz.simpl.SimpleThreadPool
threadPriority: 5
threadCount: 10
threadsInheritContextClassLoaderOfInitializingThread: true
6、Swagger
Swagger是常用的接口文档管理组件,通过对API接口和对象的简单注释,快速生成接口描述信息,并且提供可视化界面可以快速对接口发送请求和调试,该组件在前后端联调中,极大的提高效率。
配置基本的包扫描能力即可;
@Configuration
public class SwaggerConfig {
@Bean
public Docket createRestApi() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.basePackage("com.butte"))
.paths(PathSelectors.any())
.build();
}
}
访问:服务:端口/swagger-ui.html即可打开接口文档;

六、数据库配置
1、MySQL
微服务架构下,不同的服务对应不同的MySQL库,基于业务模块做库的划分是当前常用的方式,可以对各自业务下的服务做迭代升级,同时可以避免单点故障导致雪崩效应。

2、HikariCP
HikariCP作为SpringBoot2版本推荐和默认采用的数据库连接池,具有速度极快、轻量简单的特点。
spring:
datasource:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/${data.name.mysql}?${spring.datasource.db-param}
username: root
password: 123456
db-param: useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
hikari:
minimumIdle: 5
maximumPoolSize: 10
idleTimeout: 300000
maxLifetime: 500000
connectionTimeout: 30000
连接池的配置根据业务的并发需求量,做适当的调优即可。
3、Mybatis
Mybatis持久层的框架组件,支持定制化SQL、存储过程以及高级映射,MyBatis-Plus是一个MyBatis的增强工具,在MyBatis的基础上只做增强不做改变,可以简化开发、提高效率。
mybatis-plus:
mapper-locations: classpath*:/mapper/**/*.xml
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
- 同系列-架构:┃ 分布式 ┃ 消息中间件 ┃ 事务管理 ┃ 高并发 ┃ 缓存管理 ┃
- 同系列-组件:┃ Kafka消息 ┃ ElasticSearch搜索 ┃ Redis缓存 ┃ Quartz任务 ┃ Swagger2接口 ┃
七、源代码地址
应用仓库:
https://gitee.com/cicadasmile/butte-flyer-parent
组件封装:
https://gitee.com/cicadasmile/butte-frame-parent
