一、容器之Map集合
集合体系的源码中,Map中的HashMap的设计堪称最经典,涉及数据结构、编程思想、哈希计算等等,在日常开发中对于一些源码的思想进行参考借鉴还是很有必要的。
- 基础:元素增查删、容器信息;
- 进阶:存储结构、容量、哈希;
API体系
在整个Map和Set的API体系中,最重要的就是HashMap的实现原理:
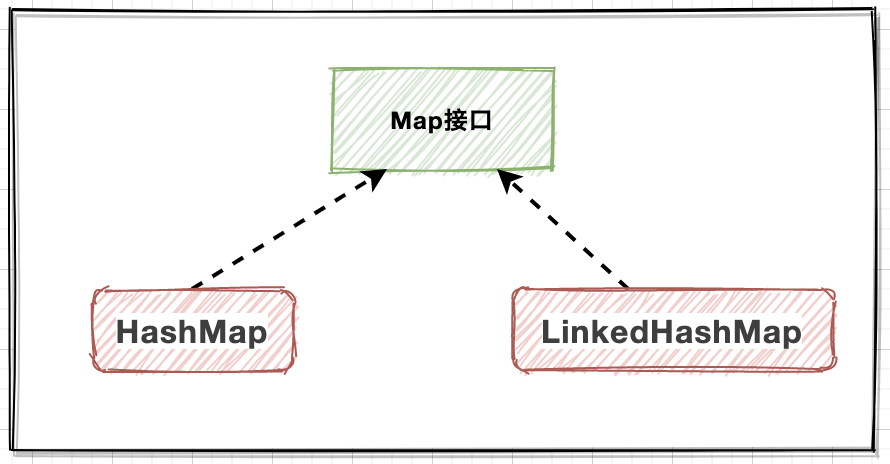
- HashMap:基于哈希表管理元素;
- LinkedHashMap:基于HashMap和双向链表;
- HashSet:底层维护HashMap结构;
- LinkedHashSet:继承HashSet,双向链表;
所以Map和Set的系列中,除特殊API之外,基本原理都依赖HashMap,只是在各自具体实现时,适用于不同特点的元素管理。
二、数据结构
在看HashMap之前,先理解一种数据结构:数组+链表的结构。

基于数组管理元素的位置,元素的存储形成链表结构,既然是链表那么就可以是单双向的结构,这需要针对具体的API去分析,通过这个结构可以得到几个关键信息:
- 扩容:基于数组则面对扩容问题;
- 链表:形成链表结构的机制;
- 哈希:哈希值计算与冲突处理;
三、HashMap详解
1、结构封装
既然上面简单描述了数组+链表的结构,那么从源码角度看看是如何封装的:
transient Node<K,V>[] table;
在HashMap中数组结构的变量命名为table(表),并且是基于Node<K,V>的节点:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
实现Map.Entry接口,并定义节点的结构变量,和节点自身的相关方法。
2、构造方法
在知道HashMap中的基础结构后,可以看其相关的构造方法,初始化哪些变量:
无参构造
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
- float DEFAULT_LOAD_FACTOR = 0.75f;
- this.loadFactor = DEFAULT_LOAD_FACTOR;
实际上还要关注一个核心参数:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 16
即数组默认的初始化容量DEFAULT_INITIAL_CAPACITY为16,扩容的阈值loadFactor为0.75,即表示当数组中元素达到12个便会进行扩容操作。
有参构造
当然也可以通过有参构造方法去设置两个参数:即容量和扩容的阈值:
public HashMap(int initialCapacity, float loadFactor) ;
通过两个构造方法的源码可知:当直接创建新的HashMap的时候,不会立即对哈希数组进行初始化,但是可以对关键变量做自定义设置。
3、装载元素
顺着HashMap的使用方法,看元素添加:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
在put的时候并没有做过多直接操作,而是调用两个关键方法:
- hash():计算key的hash值;
- putVal():元素添加过程;
这里必须看一个关键方法,哈希值的计算:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
并不是直接获取Object中hashCode的返回值,计算key对应的hashCode值,和hashCode值右移16位的值,并对两个结果进行异或运算,以此拉低哈希冲突发生的概率。
再看putVal()方法,这里的操作就相当精彩:
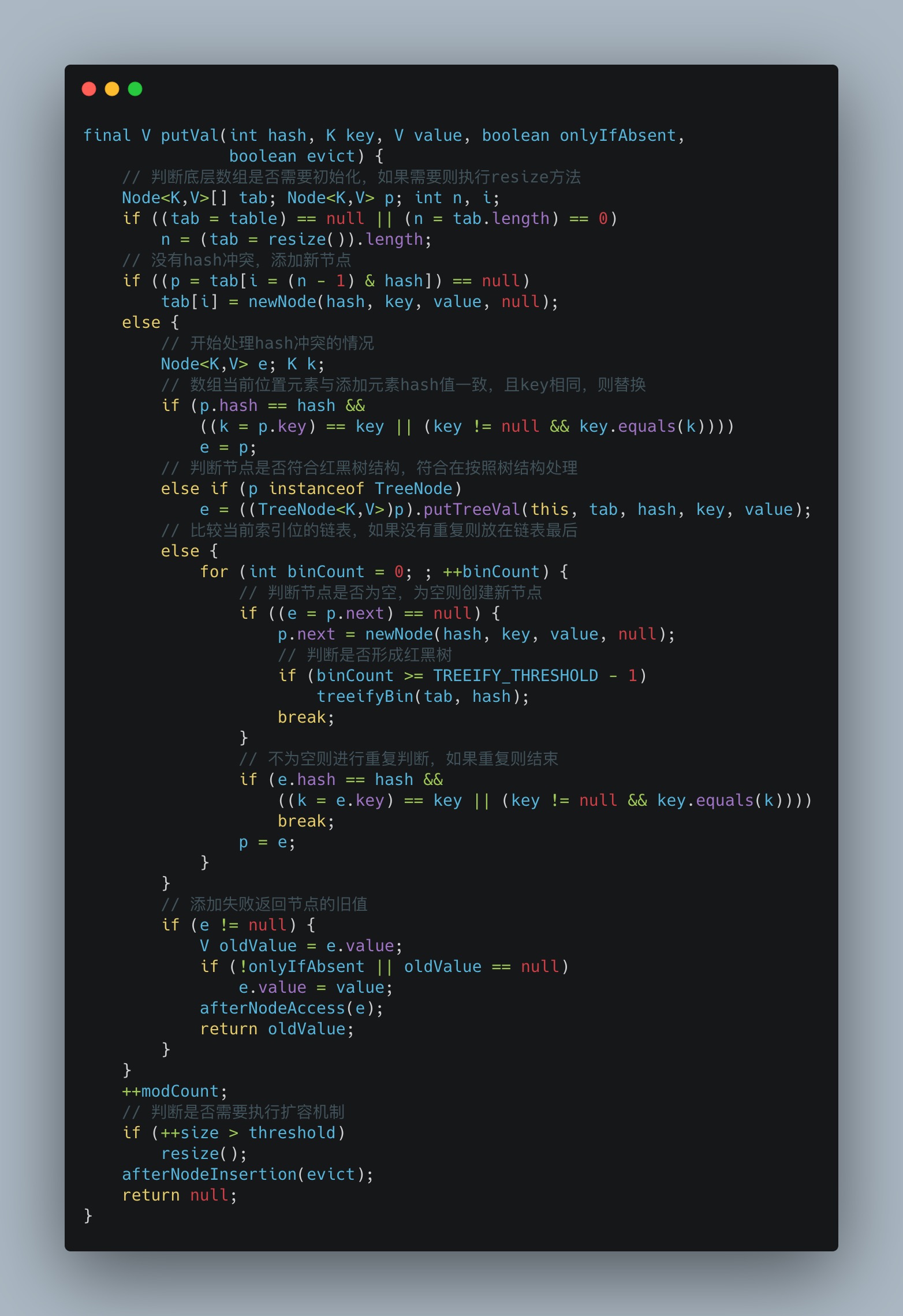
核心步骤总结:
- 首次执行判断并初始化底层数组;
- 基于哈希值计算结果添加元素;
- 根据添加元素后的容量来判断是否扩容;
这里还需要说明一个问题:
HashMap基于红黑树来处理哈希冲突问题,如果hash冲突过多,对O(n)的查询性能的影响非常大,当冲突节点链表的冲突元素数量到达8时,并且数组的长度到达64时,会使用红黑树结构代替链表来处理哈希冲突的查询性能问题,关于树结构可以移步之前的相关文章。
4、自动化扩容
容器在一定边界内可以不断添加元素,其核心的机制就是扩容,HashMap的扩容遵循最小可用原则,当然容量到达阈值,便会触发自动扩容机制。
阈值:threshold=capacity*loadFactor,默认即 16*0.75=12。
核心方法:resize;
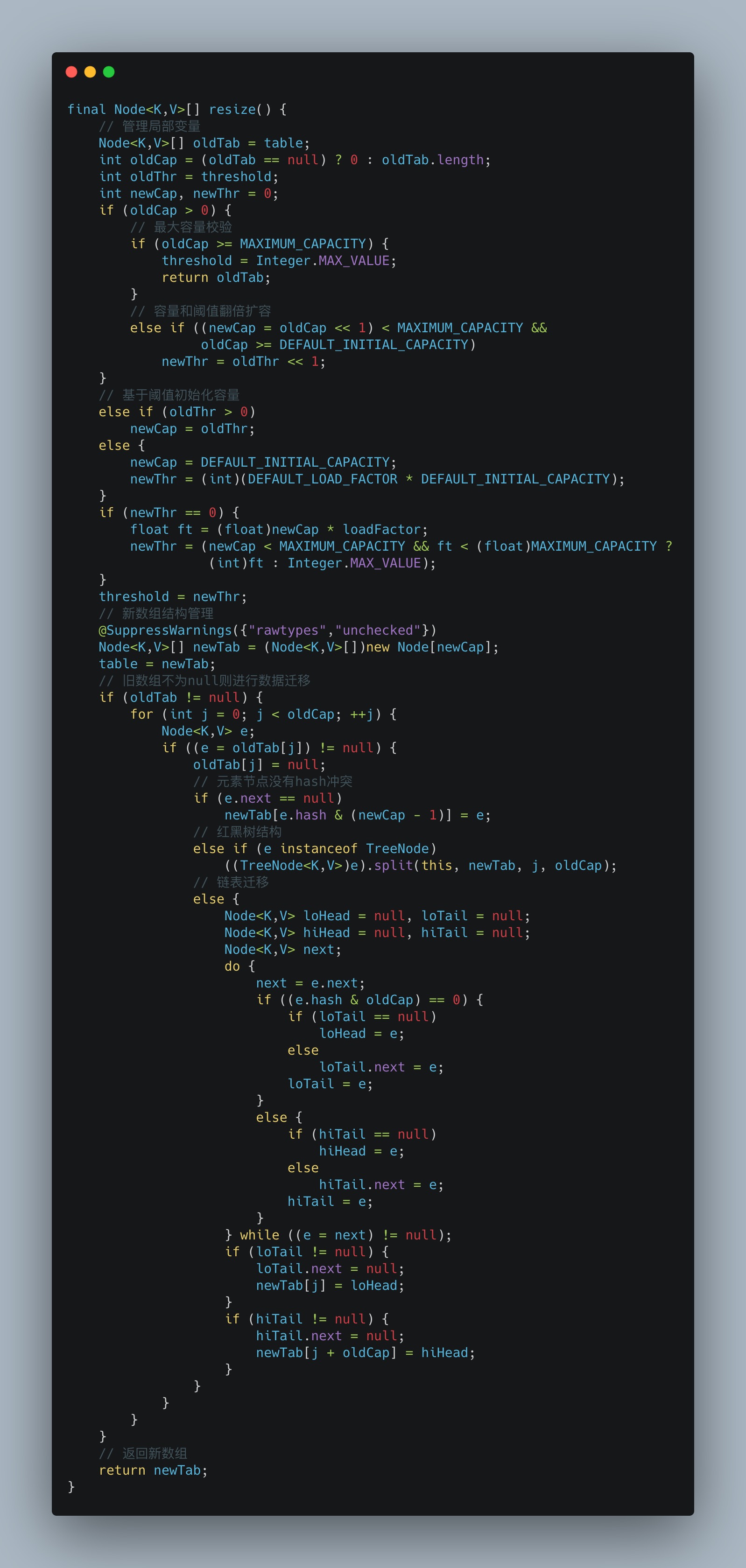
核心步骤总结:
- 判断扩容的边界参数:threshold;
- 核心参数计算:容量和阈值;
- 基于新参数创建一个新的空数组;
- 原数组为null则过程可以理解为初始化;
- 原数组不为null则扩容并迁移数据;
很显然如果涉及数组扩容则会很影响效率,所以在日常开发中,可以在使用HashMap的时候预先估计好HashMap的大小,保证阈值大于存储的元素数量,尽可能避免进行多次扩容操作。
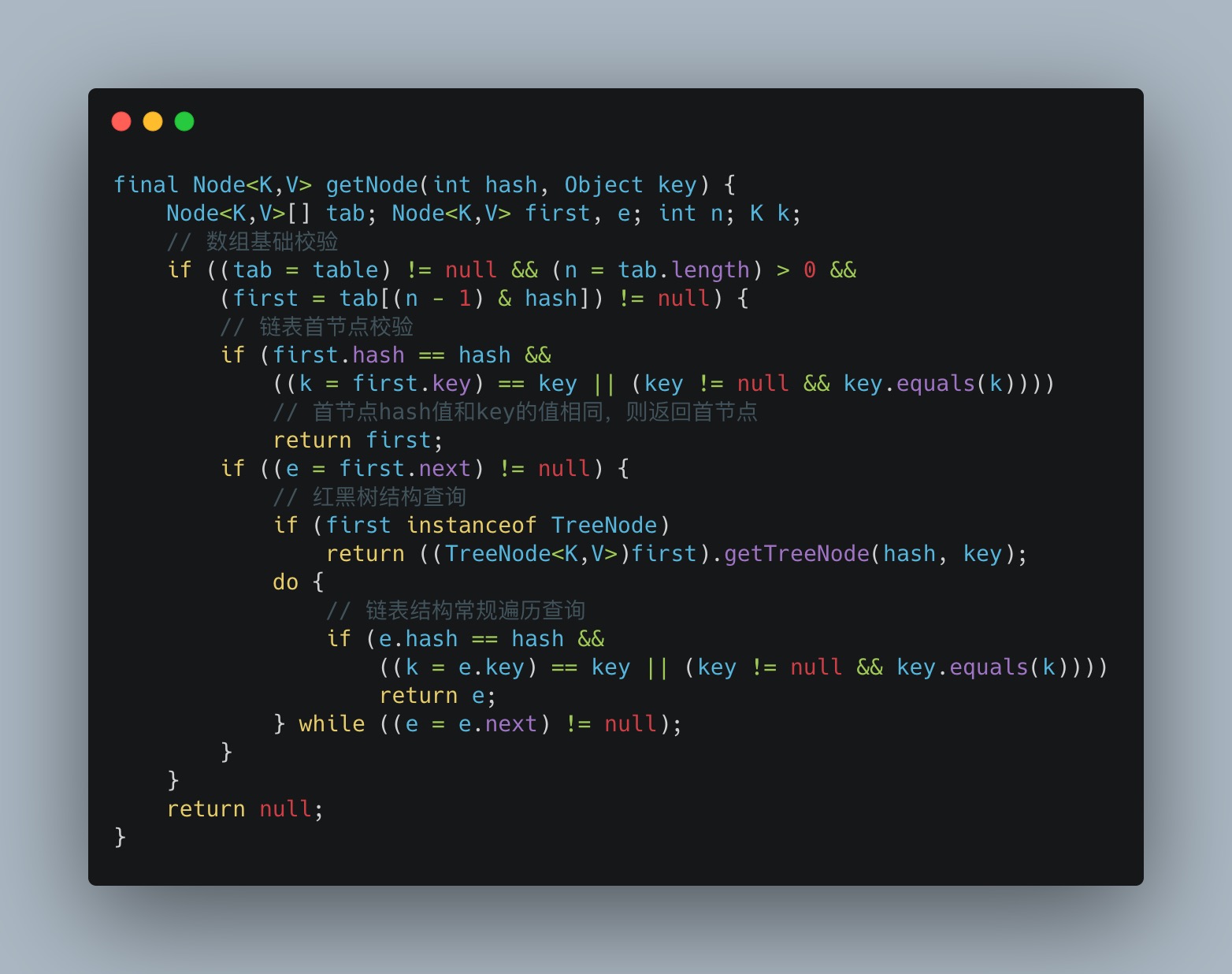
5、查询元素
getNode查找方法,通过hash值的计算,然后依次经过数组、红黑树、链表进行遍历查询:
6、删除元素
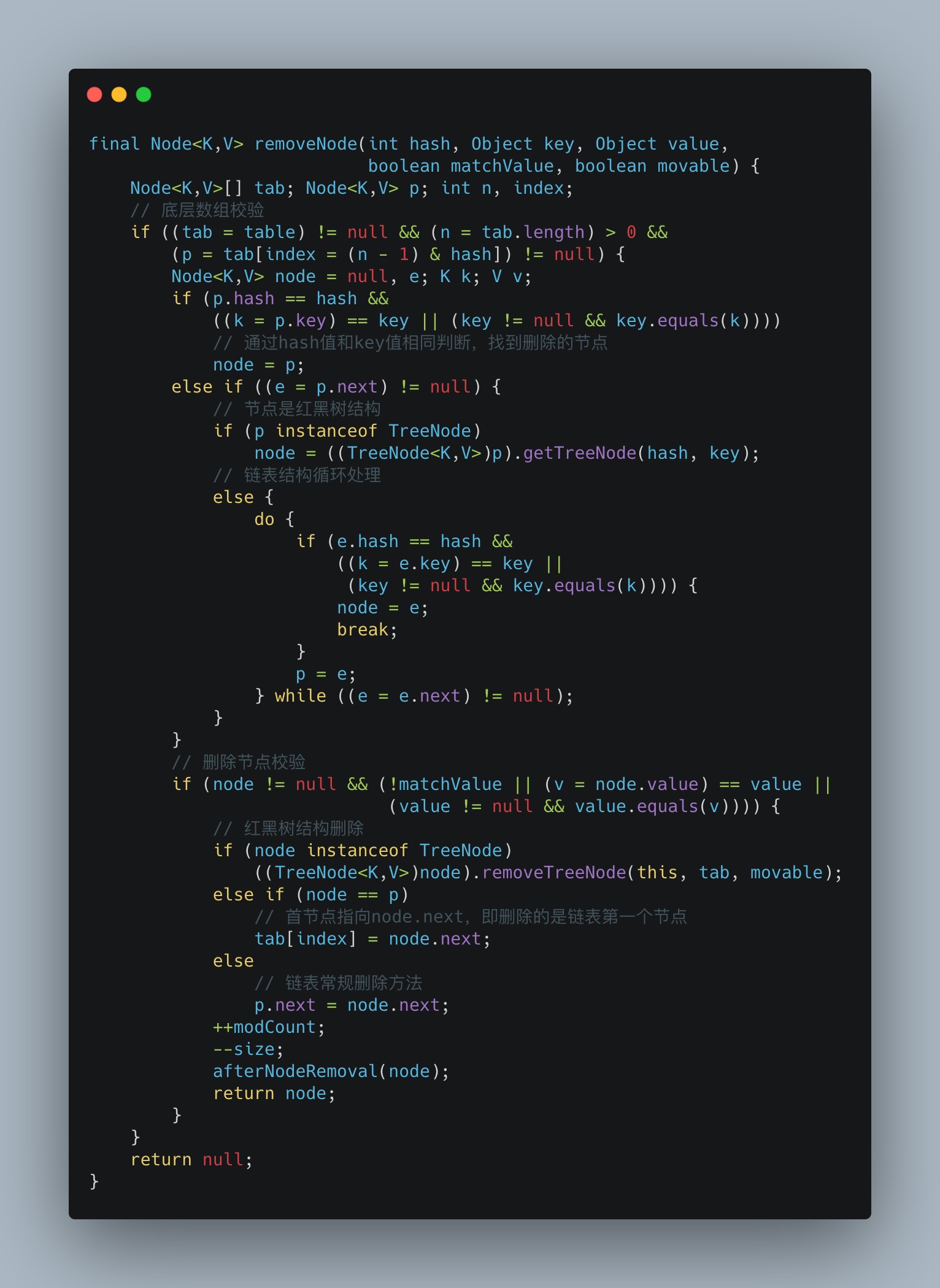
removeNode删除方法,首先通过hash值的计算,找到要删除的节点,然后判断索引位置是红黑树还是链表结构,分别执行各自的删除流程:
7、补充说明
这里对两个方法做个简单的说明:hashCode()与equals(),通常来说重写equals方法的时候需要重写hashCode方法。
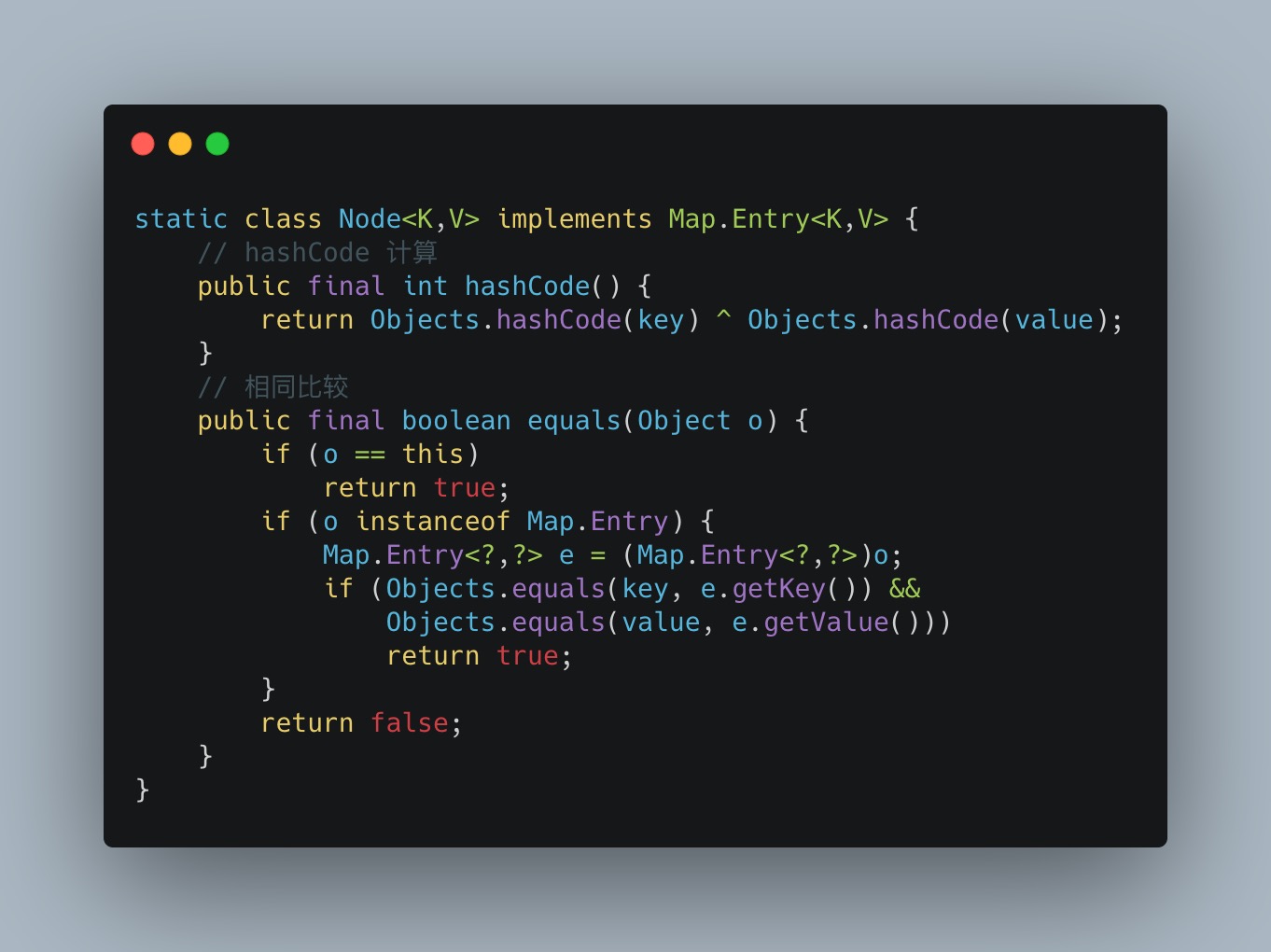
这两个方法都可以用来比较两个对象是否相等,但是hash值有存在冲突的情况,可能存在两个对象的hash值冲突,这时候可以通过equals判断对象值是否相同,==判断值对象,地址判断引用对象。
在HashMap的结构中,链表上的hash值相同情况还要通过equals方法来判断具体值是否相同,才能找到相应的对象。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/java-base-parent
GitEE·地址
https://gitee.com/cicadasmile/java-base-parent

阅读标签
【Java基础】【设计模式】【结构与算法】【Linux系统】【数据库】
【分布式架构】【微服务】【大数据组件】【SpringBoot进阶】【Spring&Boot基础】