一、模块(module)的概念
1、模块定义和分类
在python中,一个.py文件就称之为一个模块(Module)。
模块的使用方式都是一样的,细分模块可以分为三类:
1 自定义模块:使用python编写的单个.py文件,或者把一系列的.py文件组织在一起的文件夹。(注:文件夹下有个__init__.py文件,该文件夹称之为包) 2 第三方模块:已被编译为共享库或DLL的C或C++扩展 3 python标准库:使用C编写并链接到python解释器的内置模块
2、模块优点
1) 从文件级别组织程序,更方便管理
2) 拿来主义,提升开发效率
我们不仅仅可以单独执行脚本文件,还可以导入到其他的模块中或者下载他人模块导入自己项目中使用,实现了功能的重复利用并且极大地提升我们的开发效率。
* 3) 模块可以避免函数名和变量名冲突
使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
3、模块的导入
1) 模块导入的搜索路径
模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块


1、在第一次导入某个模块时(比如spam),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用 ps:python解释器在启动时会自动加载一些模块到内存中,可以使用sys.modules查看 2、如果没有,解释器则会查找同名的内建模块 3、如果还没有找到就从sys.path给出的目录列表中依次寻找spam.py文件。
import sys print(sys.path)
注意事项:按照sys.path的路径顺序优先查找,所以若在当前目录下存在与要引入模块同名的文件,就会把要导入的模块屏蔽掉。 当前目录是优先于标准库目录的,需要强调的是:我们自定义的模块名不要跟python标准库的模块名重复
sys.path从以下位置初始化: 1 执行文件所在的当前目录 2 PTYHONPATH(包含一系列目录名,与shell变量PATH语法一样) 3 依赖安装时默认指定的
在初始化后,python程序可以修改sys.path。
import sys
sys.path.append('/a/b/c/d')
sys.path.insert(0,'/x/y/z')
路径排在前的目录,优先被搜索:搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找,sys.path中还可能包含.zip归档文件和.egg文件,python会把.zip归档文件当成一个目录去处理。
#首先制作归档文件:zip module.zip foo.py bar.py import sys sys.path.append('module.zip') import foo,bar #也可以使用zip中目录结构的具体位置 sys.path.append('module.zip/lib/python') #windows下的路径不加r开头,会语法错误 sys.path.insert(0,r'C:UsersAdministratorPycharmProjectsa') #至于.egg文件是由setuptools创建的包,这是按照第三方python库和扩展时使用的一种常见格式,.egg文件实际上只是添加了额外元数据(如版本号,依赖项等)的.zip文件。 #需要强调的一点是:只能从.zip文件中导入.py,.pyc等文件。使用C编写的共享库和扩展块无法直接从.zip文件中加载(此时setuptools等打包系统有时能提供一种规避方法),且从.zip中加载文件不会创建.pyc或者.pyo文件,因此一定要事先创建他们,来避免加载模块是性能下降。
2) 模块导入的过程
第一次导入模块会有三步流程,重复导入python会直接引用内存中已经加载好的结果,即后续的import语句仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句。
import sys
#test.py
#1.为源文件(导入的模块sys)创建新的名称空间,在模块中定义的函数和方法若是使用到了global时访问的就是这个名称空间。
#2.在新创建的命名空间中执行模块中包含的代码
事实上,函数定义也是“被执行”的语句,模块级别函数定义的执行将函数名放
入模块全局名称空间表,用globals()可以查看
#3.创建名字sys来引用该命名空间
这个名字和变量名没什么区别,都是‘第一类的’,且使用sys.名字(sys.MName)的方式
可以访问sys.py文件中定义的名字,sys.MName与test.py中的名字来自
两个完全不同的地方。
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突
print('from the spam.py') money=1000 def read1(): print('spam模块:',money) def read2(): print('spam模块') read1() def change(): global money money=0
import spam #只在第一次导入时才执行spam.py内代码 import spam import spam #执行结果:from the spam.py
import spam money=10 print(spam.money) ''' 执行结果: from the spam.py 1000 '''
import spam def read1(): print('========') spam.read1() ''' 执行结果: from the spam.py spam模块: 1000 '''
import spam money=1 spam.change() print(money) ''' 执行结果: from the spam.py 1 '''
3)为导入模块名起别名
为已经导入的模块起别名的方式对编写可扩展的代码很有用
import sys as sss print(sss.path) from sys import path as spp print(spp)
4)模块导入方法
A、导入一个或多个模块
import module1[, module2[,... moduleN]
B、导入模块里的单个或全部对象,这个导入方法将模块中的名字直接导入到当前的名称空间中,所以在当前名称空间中,调用直接使用名字就可以了、无需加前缀,但容易与当前执行文件中的名字冲突:
from modname import name1[, name2[, ... nameN]] #可以直接调用name1[, name2[, ... nameN]] from modname import * #比较不推荐,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
可以使用__all__来控制*(用来发布新版本),在spam.py中新增一行
__all__=['money','read1'] #这样在另外一个文件中用from spam import *就这能导入列表中规定的两个名字
验证一:当前位置直接使用read1和read2就好了,执行时,仍然以spam.py文件全局名称空间
#测试一:导入的函数read1,执行时仍然回到spam.py中寻找全局变量money #test.py from spam import read1 money=100 read1() ''' 执行结果: from the spam.py spam模块: 1000 #spam->read1->money 1000 ''' #测试二:导入的函数read2,执行时需要调用read1(),仍然回到spam.py中找read1() #test.py from spam import read2 def read1(): print('==========') read2() ''' 执行结果: from the spam.py spam模块 #spam->read2 calling read spam模块: 1000 #spam->read1->money 1000 '''
验证二:如果当前有重名read1或者read2,那么会有覆盖效果。
#测试三:导入的函数read1,被当前位置定义的read1覆盖掉了 #test.py from spam import read1 def read1(): print('==========') read1() ''' 执行结果: from the spam.py ========== '''
验证三:导入的方法在执行时,始终是以源文件为准的
from spam import money,read1 money=100 #将当前位置的名字money绑定到了100 print(money) #打印当前的名字 read1() #读取spam.py中的名字money,仍然为1000 ''' from the spam.py spam->read1->money 1000 '''
5)模块循环导入问题
模块循环/嵌套导入抛出异常的根本原因是由于在python中模块被导入一次之后,就不会重新导入,只会在第一次导入时执行模块内代码
在我们的项目中应该尽量避免出现循环/嵌套导入,如果出现多个模块都需要共享的数据,可以将共享的数据集中存放到某一个地方
在程序出现了循环/嵌套导入后的异常分析、解决方法如下
#示范文件内容如下 #m1.py print('正在导入m1') from m2 import y x='m1' #m2.py print('正在导入m2') from m1 import x y='m2' #run.py import m1 #测试一 执行run.py会抛出异常 正在导入m1 正在导入m2 Traceback (most recent call last): File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/aa.py", line 1, in <module> import m1 File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module> from m2 import y File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m2.py", line 2, in <module> from m1 import x ImportError: cannot import name 'x' #测试一结果分析 先执行run.py--->执行import m1,开始导入m1并运行其内部代码--->打印内容"正在导入m1" --->执行from m2 import y 开始导入m2并运行其内部代码--->打印内容“正在导入m2”--->执行from m1 import x,由于m1已经被导入过了,所以不会重新导入,所以直接去m1中拿x,然而x此时并没有存在于m1中,所以报错 #测试二:执行文件不等于导入文件,比如执行m1.py不等于导入了m1 直接执行m1.py抛出异常 正在导入m1 正在导入m2 正在导入m1 Traceback (most recent call last): File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module> from m2 import y File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m2.py", line 2, in <module> from m1 import x File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module> from m2 import y ImportError: cannot import name 'y' #测试二分析 执行m1.py,打印“正在导入m1”,执行from m2 import y ,导入m2进而执行m2.py内部代码--->打印"正在导入m2",执行from m1 import x,此时m1是第一次被导入,执行m1.py并不等于导入了m1,于是开始导入m1并执行其内部代码--->打印"正在导入m1",执行from m1 import y,由于m1已经被导入过了,所以无需继续导入而直接问m2要y,然而y此时并没有存在于m2中所以报错 # 解决方法: 方法一:导入语句放到最后 #m1.py print('正在导入m1') x='m1' from m2 import y #m2.py print('正在导入m2') y='m2' from m1 import x 方法二:导入语句放到函数中 #m1.py print('正在导入m1') def f1(): from m2 import y print(x,y) x = 'm1' # f1() #m2.py print('正在导入m2') def f2(): from m1 import x print(x,y) y = 'm2' #run.py import m1 m1.f1() 示例文件
#m1.py f1() print('正在导入m1') import m2 x='m1' print(m2.y) #m2.py print('正在导入m2') import m1 y='m2' #run.py import m1 思考
* 6) 模块的重载
考虑到性能的原因,每个模块只被导入一次,放入字典sys.module中,如果你改变了模块的内容,你必须重启程序,python不支持重新加载或卸载之前导入的模块,
有的同学可能会想到直接从sys.module中删除一个模块不就可以卸载了吗,注意了,你删了sys.module中的模块对象仍然可能被其他程序的组件所引用,因而不会被清楚。
特别的对于我们引用了这个模块中的一个类,用这个类产生了很多对象,因而这些对象都有关于这个模块的引用。
如果只是你想交互测试的一个模块,使用 importlib.reload(), e.g. import importlib; importlib.reload(modulename),这只能用于测试环境。
def func1(): print('func1')
import time,importlib import aa time.sleep(20) # importlib.reload(aa) aa.func1()
在20秒的等待时间里,修改aa.py中func1的内容,等待test.py的结果。
打开importlib注释,重新测试
二、python文件
python文件区分两种用途:模块与脚本
1) 脚本,一个文件就是整个程序,用来被执行
2) 模块,文件中存放着一堆功能,用来被导入使用
python文件的编译:
为了提高加载模块的速度,强调强调强调:提高的是加载速度而绝非运行速度。python解释器会在__pycache__目录中下缓存每个模块编译后的版本,格式为:module.version.pyc。通常会包含python的版本号。例如,在CPython3.3版本下,spam.py模块会被缓存成__pycache__/spam.cpython-33.pyc。这种命名规范保证了编译后的结果多版本共存。
Python检查源文件的修改时间与编译的版本进行对比,如果过期就需要重新编译。这是完全自动的过程。并且编译的模块是平台独立的,所以相同的库可以在不同的架构的系统之间共享,即pyc使一种跨平台的字节码,类似于JAVA火.NET,是由python虚拟机来执行的,但是pyc的内容跟python的版本相关,不同的版本编译后的pyc文件不同,2.5编译的pyc文件不能到3.5上执行,并且pyc文件是可以反编译的,因而它的出现仅仅是用来提升模块的加载速度的,不是用来加密的。
#python解释器在以下两种情况下不检测缓存 #1 如果是在命令行中被直接导入模块,则按照这种方式,每次导入都会重新编译,并且不会存储编译后的结果(python3.3以前的版本应该是这样) python -m spam.py #2 如果源文件不存在,那么缓存的结果也不会被使用,如果想在没有源文件的情况下来使用编译后的结果,则编译后的结果必须在源目录下 sh-3.2# ls __pycache__ spam.py sh-3.2# rm -rf spam.py sh-3.2# mv __pycache__/spam.cpython-36.pyc ./spam.pyc sh-3.2# python3 spam.pyc spam #提示: 1.模块名区分大小写,foo.py与FOO.py代表的是两个模块 2.你可以使用-O或者-OO转换python命令来减少编译模块的大小 -O转换会帮你去掉assert语句 -OO转换会帮你去掉assert语句和__doc__文档字符串 由于一些程序可能依赖于assert语句或文档字符串,你应该在在确认需要 的情况下使用这些选项。 3.在速度上从.pyc文件中读指令来执行不会比从.py文件中读指令执行更快,只有在模块被加载时,.pyc文件才是更快的 4.只有使用import语句是才将文件自动编译为.pyc文件,在命令行或标准输入中指定运行脚本则不会生成这类文件,因而我们可以使用compieall模块为一个目录中的所有模块创建.pyc文件 模块可以作为一个脚本(使用python -m compileall)编译Python源 python -m compileall /module_directory 递归着编译 如果使用python -O -m compileall /module_directory -l则只一层 命令行里使用compile()函数时,自动使用python -O -m compileall 详见:https://docs.python.org/3/library/compileall.html#module-compileall
三、python内置全局变量__name__
当文件被当做脚本执行时:__name__ 等于'__main__'
当文件被当做模块导入时:__name__等于模块名
if __name__ == '__main__':
作用:用来控制.py文件在不同的应用场景下执行不同的逻辑,
1)避免代码被import,也就是被调用时,屏蔽代码段
2)调试运行代码
#fib.py def fib(n): # write Fibonacci series up to n a, b = 0, 1 while b < n: print(b, end=' ') a, b = b, a+b print() def fib2(n): # return Fibonacci series up to n result = [] a, b = 0, 1 while b < n: result.append(b) a, b = b, a+b return result if __name__ == "__main__": import sys fib(int(sys.argv[1])) #执行:python fib.py <arguments> python fib.py 50 #在命令行
四、python包
1、python包的定义
包就是一个包含有__init__.py文件的文件夹,所以其实我们创建包的目的就是为了用文件夹将文件/模块组织起来
Packages are a way of structuring Python’s module namespace by using “dotted module names” # 包是一种通过使用‘.模块名’来组织python模块名称空间的方式。
1) 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2)创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包的本质就是一种模块。
2、python包的优点
包的本质就是一个文件夹,那么文件夹唯一的功能就是将文件组织起来。
随着功能越写越多,我们无法将所以功能都放到一个文件中,于是我们使用模块去组织功能。
而随着模块越来越多,我们就需要用文件夹将模块文件组织起来,以此来提高程序的结构性和可维护性。
3、包的使用之import 和注意事项
1) 在import/from...import时,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。
但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
而from...import后面的导入模块,必须是不能带点,否则会有语法错误。
2) import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
3) 包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
### 使用import导入包:单独导入包名称时不会导入包中所有包含的所有子模块
import glance glance.cmd.manage.main() #AttributeError: module 'glance' has no attribute 'cmd',单独导入包名,子模块无法调用 #解决方法 from . import cmd #glance/__init__.py,导入包本质就是在导入__init__.py文件 from . import manage #glance/cmd/__init__.py #or import glance.cmd.manage glance.cmd.manage.main()
### 使用from ... import ...导入包的模块
from glance.db import models models.register_models('mysql') from glance.db.models import register_models register_models('mysql')
### 从一个包导入所有*: 想从包api中导入所有,实际上该语句只会导入包api下__init__.py文件中定义的名字,我们可以在这个文件中定义__all___:
#glance同级目录test.py文件 from glance.api import * #api/__init__.py文件 x=10 def func(): print('from api.__init.py') __all__=['x','func','policy']
#glance同级目录test.py文件中 from glance import * get() create_resource('a.conf') main() register_models('mysql') #在glance.__init__.py中 from .api.policy import get from .api.versions import create_resource from .cmd.manage import main from .db.models import register_models __all__=['get','create_resource','main','register_models']
### 绝对导入和相对导入
最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以执行文件的sys.path为起始点开始导入,称之为绝对导入(以glance作为起始)
# 优点: 执行文件与被导入的模块中都可以使用 # 缺点: 所有导入都是以sys.path为起始点,导入麻烦
相对导入:参照当前所在文件的文件夹为起始开始查找,称之为相对导入。
# 符号: "."代表当前所在文件的文件夹,".."代表上一级文件夹,"..."代表上一级的上一级文件夹 # 优点: 导入更加简单 # 缺点: 只能在导入包中的模块时才能使用(只能在一个包中使用,不能用于不同目录内)
比如:
# glance/api/version.py中想要导入glance/cmd/manage.py
# 在glance/api/version.py,单独运行报错原因:只能在同一个包内进行导入,不同目录之间无法进行相对或绝对导入 # 绝对导入,单独run version.py会报错 “ModuleNotFoundError: No module named 'glance'”
from glance.cmd import manage
manage.main()
# 相对导入,单独run version.py会报错 “ValueError: attempted relative import beyond top-level package”
from ..cmd import manage
manage.main()
# 测试代码:glance的同级目录test.py,
from glance.api import versions
注意:
* 相对导入只能用于包内部模块之间的相互导入,导入者与被导入者都必须存在于一个包内
* 试图在顶级包之外使用相对导入是错误的,言外之意,必须在顶级包内使用相对导入,每增加一个“.”代表跳到上一级文件夹,而上一级不应该超出顶级包。
---- 报错“attempted relative import beyond top-level package”
* 导入路径必须注意,包以及包的模块都是用来被导入的,而不是被直接执行的。而环境变量都是以执行文件为准的。
#api/version.py中,单独执行没有问题。 import policy policy.get() #glance同级下的一个test.py,这样就报错了 from glance.api import versions #ImportError: No module named 'policy' ''' 分析: 此时我们导入versions在versions.py中执行,import policy需要找从sys.path也就是从当前目录找policy.py,这必然是找不到的 '''
├── test.py └── glance #Top-level package │ ├── __init__.py #Initialize the glance package │ ├── api #Subpackage for api │ ├── __init__.py │ ├── policy.py │ └── versions.py │ ├── cmd #Subpackage for cmd │ ├── __init__.py │ └── manage.py │ └── db #Subpackage for db ├── __init__.py └── models.py
实验: https://pan.baidu.com/s/1C1Rzioen64WvvuOiQuamZQ
# import的使用 # import glance.api.policy # glance.api.policy.get() #from policy.py #一次性import整个包 # import glance # glance.cmd.manage.main() #AttributeError: module 'glance' has no attribute 'cmd' #import包里的某个模块 # import glance.cmd.manage # glance.cmd.manage.main() #from manage.py #使用from...import # # from glance.db import models # # # # glance.db.models.register_models('mysql') #NameError: name 'glance' is not defined # # # db.models.register_models('mysql') #NameError: name 'db' is not defined # # models.register_models('mysql') # from glance.db.models import register_models # register_models('mysql') #from models.py: mysql # #一次性从包导入所有* #1、from glance.api import * # # from glance.api import * # # func() # # policy.get() # # print(x) # # versions.create_resource("10.1.1") # #2、from glance import * # # from glance.api.policy import * # # get() # # from glance.api.versions import * # # create_resource('a.conf') # # from glance.cmd.manage import * # # main() # # from glance.db.models import * # # register_models('mysql') # from glance import * # get() # create_resource('a.conf') # main() # register_models('mysql') # #测试在glance/api/version.py中想要导入glance/cmd/manage.py # from glance.api import versions
#从一个模块内导入所有* #2-1、from glance import * # from .models import * # __all__=['register_models']
#从一个模块内导入所有* #1、from glance.api import * # from . import policy # from . import versions # # x=10 # # def func(): # print('from api.__init.py') # # # __all__=['x','func','policy'] # __all__=['x','func','policy',"versions"] #2-1、from glance import * #2-2、from glance import * # from .policy import get # from .versions import create_resource # from .policy import * # from .versions import * # # __all__ =['get','create_resource']
#从一个模块内导入所有* #2、from glance import * # from .api import * # # from .cmd.manage import * # # from .db.models import * from .api.policy import get from .api.versions import create_resource from .cmd.manage import main from .db.models import register_models __all__=['get','create_resource','main','register_models']
#从一个模块内导入所有* #2-1、from glance import * # from .manage import * # __all__=['ma']
def get(): print('from policy.py')
def create_resource(conf): print('from version.py: ',conf)
def main(): print('from manage.py')
def register_models(engine): print('from models.py: ',engine)
*4、包的分发
https://packaging.python.org/distributing/
五、软件开发规范
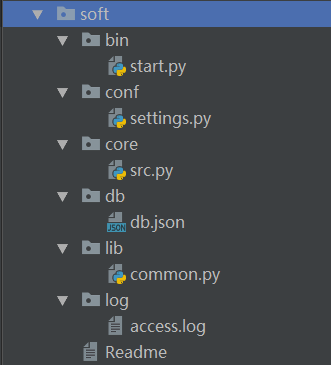
【参考链接】https://www.cnblogs.com/yuanchenqi/articles/5732581.html