上节作业回顾(讲解+温习90分钟)
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
# 仅用列表+循环实现“简单的购物车程序”
import os,time
goods = [("苹果",300),("白菜",400),("鸭梨",1000),("柿子",3000),("芒果",5000),("桂圆",8000)]
Tag = True
buy_List = []
while Tag :
os.system("clear")
salary = input("请输入你的工资(输入q退出程序):")
if salary == "q" or salary == "Q" :
print ("您并未购买商品,程序退出!")
exit()
elif salary.isdigit() :
salary = int(salary)
break
else :
print ("请以数字的形式输入您的工资!")
time.sleep(1.5)
while Tag :
os.system("clear")
title = "《商品清单》 您的余额为:{}元".format(salary)
print (title)
for item in goods :
print (goods.index(item)+1,item[0],item[1])
while Tag :
num = input("请输入想要购买的商品的编号(输入q退出程序并结帐):")
if num == "q" or num == "Q" :
if len(buy_List) == 0 :
print ("您没有买任何东西,程序退出!")
exit()
else :
for index in buy_List :
print ("您购买了一件{}商品,价格为:{}".format(goods[index-1][0],goods[index-1][1]))
else :
print ("您的最后余额为{}元,程序退出!".format(salary))
exit()
elif num.isdigit() and int(num) <= len(goods) and int(num) != 0 :
num = int(num)
break
else :
print ("请输入正确的数字编号,只能单选!")
while Tag :
if salary < goods[num-1][1] :
print ("您的余额已不足,请重新选择商品!")
time.sleep(1.5)
break
else :
salary = salary - goods[num-1][1]
buy_List.append(num)
print ("{}商品购买成功!您的余额为{}元".format(goods[num-1][0],salary))
time.sleep(1.5)
break
一,Python3 入门知识补充
1.1 bytes类型
- Python 3 最重要的新特性大概要算对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然)。这是件好事。
- 不管怎样,字符串和字节包之间的界线是必然的,下面的图解非常重要,务请牢记于心:
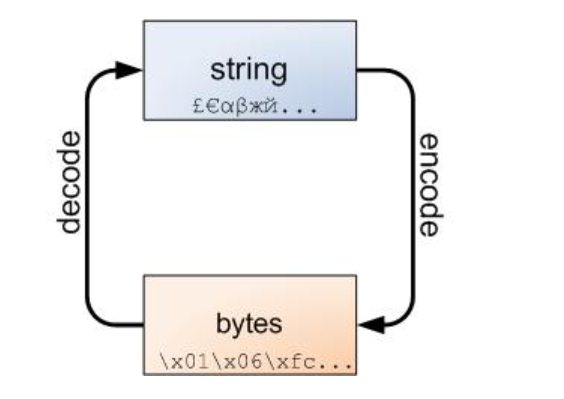
#在Python3中,字符串和二进制可以相互转换
>>> "你好吗?".encode() #将字符串转换成二进制
b'xe4xbdxa0xe5xa5xbdxe5x90x97xefxbcx9f'
>>> "你好吗?".encode().decode() #将二进制转换成字符串
'你好吗?'
特别提示:
在Python3中,如果要进行数据传输(Python的网络编程),必须先将字符串转换成二进制的格式才能进行传输。对方接收后,再转换回字符串进行识别。
在Python2.7中则没有以上要求。
1.2 三元运算
#正常写法
>>> a,b,c
(1, 3, 5)
>>> if a > b : c = a
... else : c = b
...
>>> c
3
#三元运算写法
>>> a,b,c = 1,3,5
>>> d = a if a > b else c #如果a大于b,那么d = a 否则的话,d = c
>>> d
5
如果我们用正常逻辑来写这段代码,需要写多行,很麻烦。如果我们用三元运算来写,一行即可。
1.3 进制
- 二进制:01
- 八进制:01234567
- 十进制:0123456789
- 十六进制:0123456789ABCDEF
二进制与十六进制之间的进制转换
http://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
计算机内存地址和为什么用16进制?
为什么用16进制?
- 计算机硬件是0101二进制的,16进制刚好是2的倍数,更容易表达一个命令或者数据。十六进制更简短,因为换算的时候一位16进制数可以顶4位2进制数,也就是一个字节(8位进制可以用两个16进制表示)
- 最早规定ASCII字符集采用的就是8bit(后期扩展了,但是基础单位还是8bit),8bit用2个16进制直接就能表达出来,不管阅读还是存储都比其他进制要方便
- 计算机中CPU运算也是遵照ASCII字符集,以16、32、64的这样的方式在发展,因此数据交换的时候16进制也显得更好
- 为了统一规范,CPU、内存、硬盘我们看到都是采用的16进制计算
16进制用在哪里?
- 网络编程,数据交换的时候需要对字节进行解析都是一个byte一个byte的处理,1个byte可以用0xFF两个16进制来表达。通过网络抓包,可以看到数据是通过16进制传输的。
- 数据存储,存储到硬件中是0101的方式,存储到系统中的表达方式都是byte方式
- 一些常用值的定义,比如:我们经常用到的html中color表达,就是用的16进制方式,4个16进制位可以表达好几百万的颜色信息。
二,字典
字典是一种key-value的数据类型,使用就像我们上学用的字典,通过笔画,字母来查对应页的详细内容
语法:
info = {
'stu1101':"TengLan Wu",
'stu1102':"LongZe Luola",
'stu11103':"XiaoZe Maliya",
}
字典的特性:
- dict是无序的
- key必须是唯一的(不能重复)
2.1 增加
#代码演示
>>> Dict = {'stu1101':"yunjisuan","stu1102":"benet","stu1103":"Tom","stu1104":"Amy"}
>>> Dict["stu1105"] = "苍井空"
>>> Dict
{'stu1102': 'benet', 'stu1104': 'Amy', 'stu1105': '苍井空', 'stu1101': 'yunjisuan', 'stu1103': 'Tom'}
如果想要赋值的字典的key值,在原字典里没有,那么就会被判断为是要新增字典元素
因为字典是无序的,所以增加的key:value后,在字典中的位置不固定。
2.2 修改
#代码演示
>>> Dict = {'stu1101':"yunjisuan","stu1102":"benet","stu1103":"Tom","stu1104":"Amy"}
>>> Dict["stu1102"] = "武藤兰"
>>> Dict
{'stu1102': '武藤兰', 'stu1104': 'Amy', 'stu1101': 'yunjisuan', 'stu1103': 'Tom'}
如果想要赋值的字典的key值,在原字典里已经存在,那么就会被判定为是要修改字典中已经有的key值所对应的value值;
2.3 删除
(1)指定key值进行删除
#代码演示:
>>> Dict = {"stu1101":"Tom","stu1102":"Amy","stu1103":"feixue","stu1104":"zhangsan","stu1105":"lisi"}
>>> Dict
{'stu1101': 'Tom', 'stu1103': 'feixue', 'stu1104': 'zhangsan', 'stu1105': 'lisi', 'stu1102': 'Amy'}
>>> Dict.pop("stu1101") #删除指定key,key所对应的value作为返回值(标准用法)
'Tom'
>>> Dict
{'stu1103': 'feixue', 'stu1104': 'zhangsan', 'stu1105': 'lisi', 'stu1102': 'Amy'}
>>> del Dict["stu1104"] #删除指定key,无返回值
>>> Dict
{'stu1103': 'feixue', 'stu1105': 'lisi', 'stu1102': 'Amy'}
(2)删除整个字典
#代码演示:
>>> Dict = {"stu1101":"Tom","stu1102":"Amy","stu1103":"feixue","stu1104":"zhangsan","stu1105":"lisi"}
>>> Dict
{'stu1101': 'Tom', 'stu1103': 'feixue', 'stu1104': 'zhangsan', 'stu1105': 'lisi', 'stu1102': 'Amy'}
>>> del Dict
>>> Dict #字典全被删除,所以找不到了
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'Dict' is not defined
(3)随机删除字典的key:value,并将删除的key:value作为返回值
#代码演示:
>>> Dict = {"stu1101":"Tom","stu1102":"Amy","stu1103":"feixue","stu1104":"zhangsan","stu1105":"lisi"}
>>> Dict.popitem()
('stu1101', 'Tom')
>>> Dict.popitem()
('stu1103', 'feixue')
>>> Dict.popitem()
('stu1104', 'zhangsan')
>>> Dict
{'stu1105': 'lisi', 'stu1102': 'Amy'}
2.4 查找
#代码演示:
>>> Dict = {"stu1101":"Tom","stu1102":"Amy","stu1103":"feixue","stu1104":"zhangsan","stu1105":"lisi"}
>>> "stu1102" in Dict #标准用法
True
>>> Dict.get("stu1102") #获取value
'Amy'
>>> Dict["stu1102"] #也是获取value,但是看下面
'Amy'
>>> Dict["stu1108"] #当字典中没有该key,会报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'stu1108'
>>> Dict.get("stu1108") #get()找不到key不会报错。
2.5 提取字典里所有的keys
#代码演示:
>>> Dict = {"stu1101":"Tom","stu1102":"Amy","stu1103":"feixue","stu1104":"zhangsan","stu1105":"lisi"}
>>> "stu1101" in Dict #可以直接判断字符串是否在一个字典的keys中
True
>>> Dict.keys() #提取字典所有的keys,返回一个字典类型的keys列表
dict_keys(['stu1102', 'stu1104', 'stu1101', 'stu1103', 'stu1105'])
>>> "stu1101" in Dict.keys() #也可以判断字符串是否存在于字典所有keys所组成的列表中
True
特别提示:
在此处的应用上Python2.7和Python3是有比较大的差别的。
#在Python2.7中
>>> a = {"a":"1","b":"2"}
>>> a.keys() #返回一个list类型
['a', 'b']
>>> list(a) #也返回一个list类型
['a', 'b']
>>> a.keys().index("b") #list类型才有index索引
1
>>> list(a).index("b") #list类型才有index索引
1
#在Python3中
>>> a = {"a":"1","b":"2"}
>>> list(a) #返回一个列表类型
['b', 'a']
>>> list(a).index("b") #列表类型才有索引
0
>>> a.keys() #返回的还是一个字典类型的keys
dict_keys(['b', 'a'])
>>> a.keys().index("b") #字典类型的keys没有索引
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'dict_keys' object has no attribute 'index'
2.6 提取字典里所有的values
#代码演示:
>>> Dict = {"stu1101":"Tom","stu1102":"Amy","stu1103":"feixue","stu1104":"zhangsan","stu1105":"lisi"}
>>> "Amy" in Dict #不能判断字符串是否存在于字典的values中
False
>>> Dict.values() #提取字典的所有values,返回一个字典类型的values列表
dict_values(['Amy', 'zhangsan', 'Tom', 'feixue', 'lisi'])
>>> "Amy" in Dict.values() #可以判断字符串是否存在于字典所有的values所组成的列表中
True
2.7 字典的合并
>>> Dict = {"stu1101":"Tom","stu1102":"Amy","stu1103":"feixue","stu1104":"zhangsan","stu1105":"lisi"}
>>> Dict2={"1":"2","3":"4","stu1102":"更新了"}
>>> Dict.update(Dict2)
>>> Dict
{'stu1105': 'lisi', 'stu1103': 'feixue', '3': '4', '1': '2', 'stu1104': 'zhangsan', 'stu1101': 'Tom', 'stu1102': '更新了'}
字典的合并是没有的key:values会新增到旧的字典中,如果key值出现重复就会进行value的更新操作。
2.8 多级字典嵌套及操作
#代码演示:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
av_catalog = {
"欧美":{
"www.youporn.com":["很多免费的,世界最大的","质量一般"],
"www.pornhub.com":["很多免费的,也很大","质量比yourporn高点"],
"x-art.com":["质量很高","全部收费,屌丝请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来"
print (av_catalog["大陆"]["1024"])
#输出
[root@localhost scripts]# python3 test.py
['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
2.9 循环dict
#代码演示:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
Dict = {
"stu1001":"Tom",
"stu1002":"Amy",
"stu1003":"benet",
"stu1004":"yunjisuan"
}
for key in Dict :
print (key,Dict[key])
#输出
[root@localhost scripts]# python3 test.py
stu1002 Amy
stu1001 Tom
stu1003 benet
stu1004 yunjisuan
2.10 循环dict时附带索引
#代码演示:
a = {
"yunjisuan":"33",
"benet":"44",
"Tom":"22",
"chensiqi":"88"
}
for index,keys in enumerate(a) :
print (index+1,keys,a[keys])
#输出结果
[root@localhost scripts]# python3 test2.py
1 chensiqi 88
2 Tom 22
3 yunjisuan 33
4 benet 44
2.11 如何让字典有序?
#代码演示:
a = {
"yunjisuan":"33",
"benet":"44",
"Tom":"22",
"chensiqi":"88"
}
b = []
for index,keys in enumerate(a) :
b.append((index+1,keys,a[keys]))
print (index+1,keys,a[keys])
print (b)
#输出结果
[root@localhost scripts]# python3 test2.py
1 Tom 22
2 yunjisuan 33
3 chensiqi 88
4 benet 44
[(1, 'Tom', '22'), (2, 'yunjisuan', '33'), (3, 'chensiqi', '88'), (4, 'benet', '44')]
三,利用字典优化"用户登陆接口程序"
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
#利用字典功能优化“用户登陆验证接口功能”
users = {"chensiqi1":"666666","chensiqi2":"666666"}
error = []
while True :
user_Name = input("请输入登录用户的用户名:")
if user_Name in error :
print ("用户已经被锁定,请尝试登陆其他用户!")
elif user_Name in users.keys() :
for i in range(3) :
user_Passwd = input("请输入登陆用户名的密码:")
if user_Passwd == users[user_Name] :
print ("{}用户登陆成功!".format(user_Name))
exit()
else :
print ("用户账户或密码输入错误!请重新输入,您还有{}次机会。".format(2-i))
else :
print ("您的密码已经输错3次了,账户已经锁定!请尝试登陆其他用户。")
error.append(user_Name)
else :
print ("没有这个账户名,请重新输入!")
四,逻辑引导与作业
逻辑引导:
- 我们学习了字典的各种存取方法,并且利用字典的key:values的便利的键值对应方式优化了“用户登陆接口”
- 但是,我们仍在存在着不少问题。比如我们输入输出数据时,有不少的数据都是字符串的格式。尤其在用户输入数据时,用户总是喜欢输入一些非常奇怪的数据。比如:“你好吗?”他非要输入成“(空格)你好吗(空格) ”。
- 对类似这些空格数据,我们很难做出判断。他到底输入的是不是一个正常数据。再比如用户在菜单选择里,我们同学们都已经知道了,通过字符串的.isdigit()来判断用户输入的是不是一个纯数字组成的数据。
- 是的,类似这些对字符串数据的判断,是我们在日常编程中经常要遭遇的问题。这就需要我们学习下一节的知识--->字符串的24种常用方法
作业:
程序:三级菜单
要求:
- [x] :打印省,市,县三级菜单
- [x] :只能用一个字典来存取地区名称
- [x] :可返回上一级
- [x] :可随时退出程序