1.配置环境变量JDK配置
1.JDK安装
个人喜欢在
vi ~/.bash profile 下配置
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91
export PATH=$JAVA_HOME/bin:$PATH
当然要让环境变量生效source ~/.bash_profile
echo $JAVA_HOME
在输入 java -verision,生效就装好了jdk

2.安装ssh
生成秘钥
ssh-keygen -t rsa
在将公钥复制到authorized_keys中

hadoop 安装中需要安装hadoop.env.sh

通过echo $JAVA_HOME 的到环境变量并且配置hadoop.env.sh中

core-site.xml要修改的文件在hadoop中
hadoop 在1.0是端口默认是9000现在2.0默认是8020
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:8020</value> </property> </configuration>
//制定一个存放临时文件的文件夹
<configuration>
<property>
<name>dfs.replication</name>
<value>/home/hadoop/app/tmp</value>
</property>
</configuration>
然后可以再core-site.xml中的指定的文件夹中
你有多少个datenode就写在slave中
5.启动hdfs
格式化文件系统(仅第一次执行即可,不要重复执行):hdfs/hadoop namenode -format

2.快速启动namenode和datanode

伪分布式启动成功

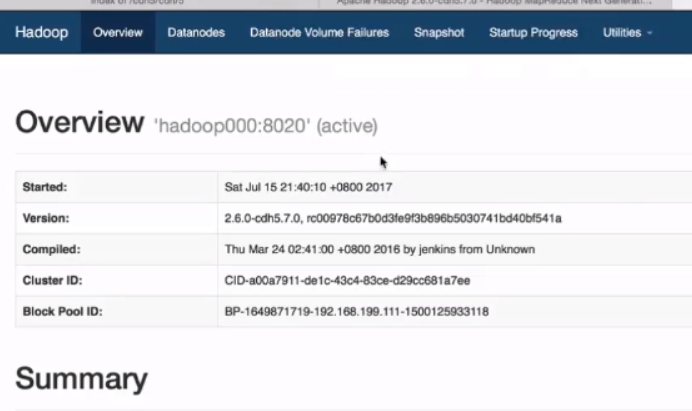
在网页上输入http://hadoop000:50070可以进行观看hadoop给前端的展示
停止伪分布式
./stop.dfs.sh
