groupby():
groupby函数可以将一个df根据某一列或者某几列分组又或者是函数分组,经过groupby后会生成一个groupby对象,该对象本身不会返回任何内容,只有当相应的方法被调用时才会起作用
1.根据某一列分组
2.根据某几列分组,和根据某列分组用法基本一致
3.查看组容量和组数(size)
4.组的遍历,得到的组内数据分别是一个个df
5.head()和first()
6.[col].数学统计变量,即是计算每个分组该列的数学统计值
7.聚合函数(mean/sum/size/count/std/var/sem/describe/first/last/nth/min/max)和agg
我们使用iris数据做例子
from sklearn.datasets import load_iris import pandas as pd import numpy as np iris=load_iris() df=pd.DataFrame(iris.data,columns=iris.feature_names) df['sample']=iris.target
1.根据某一列分组
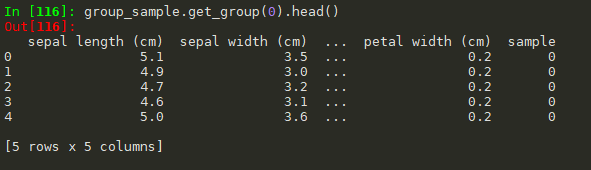
#根据sample分组 group_sample=df.groupby('sample') #get_group()是查看某一分组,比如说上面的sample有三种类别,我们可以使用get_group()查看某一类别 group_sample.get_group(0).head()
2.根据某几列分组,和根据某列分组用法基本一致
#列名需要以list形式传入 group_n=df.groupby(['petal width (cm)', 'sample']) group_n.get_group((0.1,0))
3.查看组容量和组数(size)
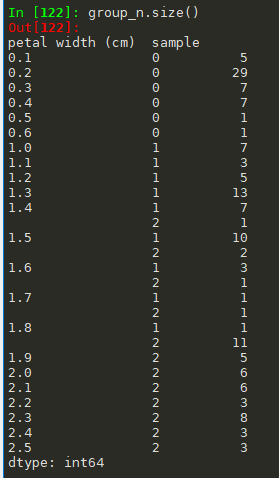
#调用get_group时可以先查看一个有几种分组,组内的容量是怎么样的 group_n.size()
4.组的遍历,得到的组内数据分别是一个个df
#name,group 分别是组名和组内数据 for name,group in group_n: print(name) print(group.head())
5.head()和first()
#head()返回的是每个组的前某几行,而不是数据集的前几行 group_n.head(2) #first()返回的每个分组的第一行信息,组成了一个df group_n.first()
6.[col].数学统计变量,即是计算每个分组该列的数学统计值
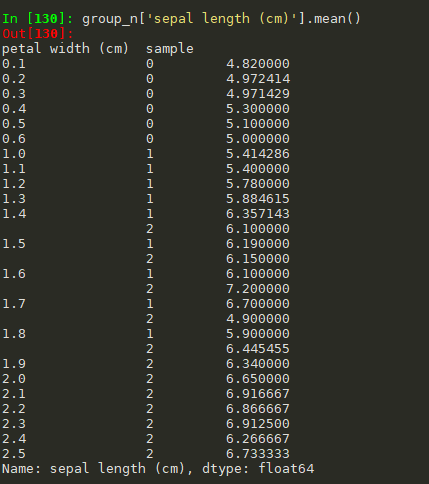
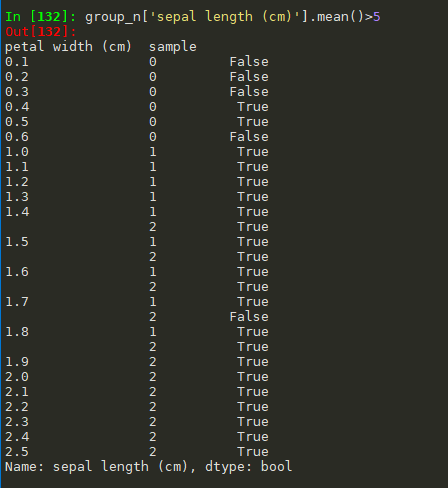
#计算每个分组的某列的平均值 group_n['sepal length (cm)'].mean() #返回的布尔型的值 group_n['sepal length (cm)'].mean()>5
7.聚合函数(mean/sum/size/count/std/var/sem/describe/first/last/nth/min/max),用法上面例子有,就不赘述了,
下面主要说一下agg()同时使用多个聚合函数
#计算每组每个特征的平均值 group_n.mean() #同时使用多个聚合函数 group_n.agg(('sum','mean')) group_n.agg(['sum','mean']) #和上面一样,只不过是重新命名了 group_n.agg([('rename_sum','sum'),('rename_mean','mean')]) #指定某一列使用某些函数,以字典形式传入 group_n.agg({'sepal length (cm)':['mean','max'],'sepal width (cm)':'var'}) #使用匿名函数或者自定义函数 group_n.agg(lambda x:x.max()-x.min())