引言
YOLOv2的论文全名为YOLO9000: Better, Faster, Stronger,它斩获了CVPR 2017 Best Paper Honorable Mention。在这篇文章中,作者首先在YOLOv1的基础上提出了改进的YOLOv2,然后提出了一种检测与分类联合训练方法,使用这种联合训练方法在COCO检测数据集和ImageNet分类数据集上训练出了YOLO9000模型,其可以检测超过9000多类物体。所以,这篇文章其实包含两个模型:YOLOv2和YOLO9000,不过后者是在前者基础上提出的,两者模型主体结构是一致的。YOLOv2相比YOLOv1做了很多方面的改进,这也使得YOLOv2的mAP有显著的提升,并且YOLOv2的速度依然很快,保持着自己作为one-stage方法的优势,YOLOv2和Faster R-CNN, SSD等模型的对比如图1所示。这里将首先介绍YOLOv2的改进策略,并给出YOLOv2的TensorFlow实现过程,然后介绍YOLO9000的训练方法。
YOLOv2的改进策略
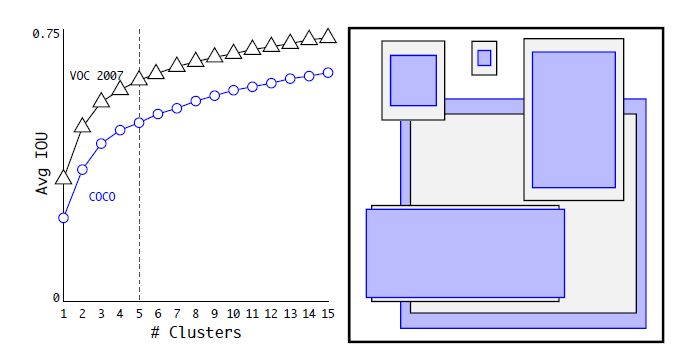
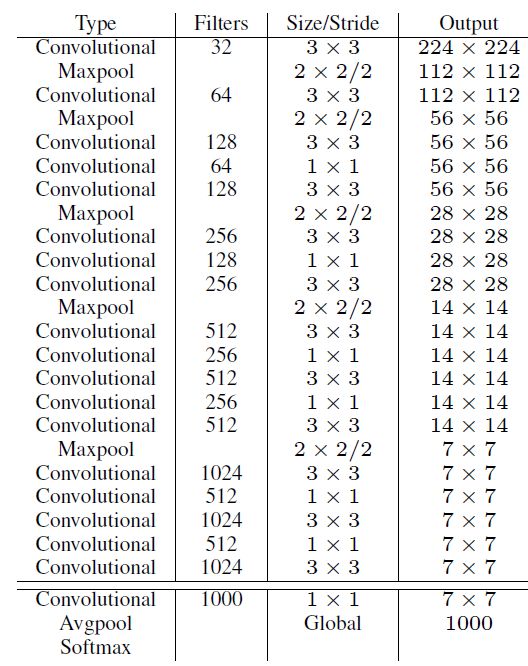
YOLOv1虽然检测速度很快,但是在检测精度上却不如R-CNN系检测方法,YOLOv1在物体定位方面(localization)不够准确,并且召回率(recall)较低。YOLOv2共提出了几种改进策略来提升YOLO模型的定位准确度和召回率,从而提高mAP,YOLOv2在改进中遵循一个原则:保持检测速度,这也是YOLO模型的一大优势。YOLOv2的改进策略如图2所示,可以看出,大部分的改进方法都可以比较显著提升模型的mAP。各个改进策略如下:
具体详细的可以参考:
个人觉得在看一些好的论文,可以在一些大佬的基础上进行学习,并思考这些观点是否是正确的,这样有利于更快地更容易地学习经典论文里面的思想。