上一篇文章:Raft算法之日志复制
Raft算法之成员关系变化
有时候可能会遇到需要对集群中的成员数量进行更新的操作,比较简单的做法将更新操作分为两个阶段进行,在第一个阶段将全部的使用旧的配置文件的集群C_old成员全部关闭,所以将不能对客户端的请求进行处理。然后在第二个阶段使用新的配置文件启动集群成员。一个很明显的劣势在于更新成员数量的时候有一段时间是无法对客户端请求进行处理的。
Raft使用了一种新的方案对成员进行更新。在两阶段更新之间加入了一个配置转换阶段,称为联合共识。引入联合共识阶段,集群在进行成员关系变化的同时,不需要关闭集群成员,从而可以在更新成员数量的过程中也可以对客户端的请求进行处理。
在联合共识阶段具有以下几点属性:
- 日志条目均复制到使用两种配置的所有服务器。
- 来自任一配置的任何服务器都可以充当领导者.
- 选举和日志的提交需要分别来自新旧配置的大多数人接受。
联合共识允许集群中的单个服务器在不同的时间从旧的配置转换为新的配置,从而不会影响安全性。并且在整个配置更新期间可以继续为客户端提供服务。
1 配置更新过程
1.1 理想情况
以向集群中添加新的成员为例,正常情况下假设该过程不涉及客户端发送的其他的新的请求:
假设旧的配置文件称为C_o,新的配置文件称为C_n,旧的集群称为C_old,新添加的成员称为C_new.
- 当集群C_old在正常运行过程中(当前使用旧的配置文件C_o),接收到来自客户端关于添加新成员的请求。
Leader接收到则直接处理,Follower接收到则会重定向到Leader.
Leader创建一个用于更新配置的新的日志文件C_o_n(该日志配置文件表示C_old与C_new成员共存),该配置文件按照正常流程复制到集群中大多数服务器(包括C_old,C_new)- 包括新成员C_new,服务器始终使用其日志中的最新配置,而不管该条目是否被提交,
Leader将使用C_o_n规则来确定何时提交C_o_n的日志条目。 - 也就是说本地只持有C_o配置日志文件的成员仍然使用旧的配置文件。当接收到C_o_n配置文件之后不论是否已经应用到复制状态机,都会使用C_o_n配置文件作为服务器的配置文件。
- 包括新成员C_new,服务器始终使用其日志中的最新配置,而不管该条目是否被提交,
- 当新的日志文件C_o_n成功在集群中提交之后,进入了联合共识阶段。
- 进入联合共识阶段之后,
Leader创建一个新的用于配置更新的新的配置文件C_n,并将该日志发送到大部分C_new服务器(文献中是这么说的,至此还没搞明白为什么不是所有的服务器)。
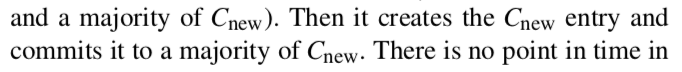
- 当配置日志文件C_n成功提交之后,则表明成员更新过程结束,集群使用新的配置文件C_n按照正常的流程继续运行。
如果不考虑客户端发送的新的请求以及服务器崩溃的情况下,可以把配置更新看做一个普通的日志文件,按照正常流程发送,提交,应用后便成功完成配置的更新。唯一不同的是普通的日志文件需要提交过后才会应用到复制状态机,而配置文件日志则是当服务器接收到之后,不论是否已经提交,接收到的配置信息都会生效。
1.2 联合共识阶段
联合共识阶段:指的是C_o_n配置日志文件成功提交到集群中的大多数服务器,且C_n配置日志文件还没有提交到集群中的大多数服务器之间的时间段。
在该阶段,任何操作(选举或者是其他的日志请求)对于C_old和C_new的成员来说都不能单独做出决策。即需要C_old与C_new中的大部分服务器同时做出决策。(因为日志的提交条件是成功复制到大多数的服务器,所以当C_o_n日志文件被提交之后,有可能还存在部分的服务器没有接收到C_o_n日志文件,仍然处于C_old阶段,C_new的成员也是如此)
2 Leader崩溃情况
分别从以下几个时间点说一下Leader在各个阶段发生崩溃的措施:
- C_o_n配置日志文件未提交之前.
- C_o_n配置日志文件提交之后,且C_n配置日志文件未提交前之间(联合共识阶段)的时间段
- C_n配置日志文件提交之后.
2.1 C_o_n配置日志文件未提交之前
从集群初始正常运行状态一直到C_o_n配置日志文件被提交这段时间,如果Leader奔溃,那么当选Leader的成员可能是使用C_o的成员,也可能是接收到C_o_n配置日志文件的成员。因为C_o_n配置日志文件还未被提交,所以C_old的成员可以单独做出决策。而C_new的成员还不能单独做出决策。
2.2 联合共识阶段
C_o_n配置日志文件提交之后,且C_n配置日志文件未提交前之间的时间段,由于C_o_n配置日志文件只有当复制到C_old和C_new两者中大多数成员之后才被提交,所以当提交C_o_n配置日志文件之后,使用C_o_n配置日志文件的成员占全部服务器成员的大多数,因此,如果Leader崩溃,那么只能从使用C_o_n配置日志文件的成员中选取Leader。此时对于C_old和C_new的成员来说都不能单独做出决策,因此也不能在使用C_o以及C_n的成员中选取Leader.
2.3 C_n配置日志文件提交之后
当该日志提交之后,实际上已经完成了网络中成员关系的更新。所以Leader的选举即可和正常运行阶段相同。
3 存在的问题
在成员关系更新阶段,主要存在三个问题:
- 新添加的成员可能不会存储任何之前的日志条目,如果将它们加入集群,在日志条目与
Leader完成同步之前,是无法提交新的日志条目的。 Leader可能不属于新配置集群中的一部分。- 假设更新成员关系是对集群中的成员进行删除,那么被删除的节点可能会扰乱集群。
3.1 问题一
针对该问题,Raft的做法是引入一个新的状态,即允许新的成员以一种不具备决策权(选举和参与日志提交)的身份加入集群,因此在选举Leader或者是统计日志是否已经分发到大部分成员时,将不会考虑该成员。一直到该成员的日志存储状态追赶上集群中的其他成员,再赋予该成员决策权。
3.2 问题二
原因: 该问题产生的原因是可能新添加到集群中的新成员的数量要远远多于旧集群的数量(个人理解,如果有错误欢迎指出)。由于之前说到的C_n配置日志文件需要发送到C_new中的大多数成员,而Leader并不属于C_new中的一员。所以在发送C_n配置日志文件的时段,Leader将会对C_new的成员进行管理。
解决方案: 当C_n日志成功完成提交时,该Leader自动转换身份为Follower,然后从C_new的成员中选举出一个新的Leader.
3.3 问题三
原因: 被删除的服务器如果没有关闭,那么他们将不会接收到心跳信息和日志信息,从而不断发生超时,最后导致任期不断增加(高于集群中所有成员的任期),然后不断向集群中发送请求投票消息。集群中的Leader将变为Follower,集群中将不断开始新的选举。从而扰乱集群的正常运行。
解决方案: Raft引入了一个最小选举超时时间,意思是如果集群中存在Leader时,并且接收到心跳信息之后在最小选举超时时间内接受到请求投票消息,那么将会忽略掉该投票消息。
下一篇文章:Raft算法之日志压缩