报错:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Client requested master to start replication from position > file size; the first event 'mysql-bin.000009' at 36755547, the last event read from '/var/lib/mysql/mysql-bin.000009' at 4, the last byte read from '/var/lib/mysql/mysql-bin.000009' at 4.'
解决办法
1.登录master 将mysql-bin.000009日志导出
[root@mysql-master mysql]# mysqlbinlog /var/lib/mysql/mysql-bin.000009 >/root/mysql-bin.000009.log [root@mysql-master mysql]#
2.查看mysql-bin.000009.log 中的最后一个 end_log_pos
[root@mysql-master mysql]# tail -n 20 /root/mysql-bin.000009.log /*!*/; # at 36670286 #200608 22:27:45 server id 1 end_log_pos 36670342 CRC32 0x45a8818c Table_map: `zabbix`.`history` mapped to number 272 # at 36670342 #200608 22:27:45 server id 1 end_log_pos 36670477 CRC32 0x78f91cd3 Write_rows: table id 272 flags: STMT_END_F BINLOG ' ofPeXhMBAAAAOAAAAIaLLwIAABABAAAAAAEABnphYmJpeAAHaGlzdG9yeQAECAMFAwEIAIyBqEU= ofPeXh4BAAAAhwAAAA2MLwIAABABAAAAAAEAAgAE//DhWgAAAAAAAJH03l4AAAAAAAAAANaQyQ3w SVwAAAAAAACR9N5eG55eKcuQP0DFWcsN8H1zAAAAAAAAkfTeXgAAAAAAAFlA9SLeDfBBcwAAAAAA AJH03l6rz9VW7PtYQHSFBQ7THPl4 '/*!*/; # at 36670477 #200608 22:27:45 server id 1 end_log_pos 36670508 CRC32 0xd5b512b3 Xid = 12706433 COMMIT/*!*/; DELIMITER ; # End of log file ROLLBACK /* added by mysqlbinlog */; /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
结果是master的pos 36670508 < slave的pos 36755547
3.连接mysql-master 查看pos信息和日志内容
mysql> mysql> show binlog events in "mysql-bin.000009" from 36670508 limit 20; Empty set (0.00 sec)
4.重新同步 查看下一个日志文件的起始位置
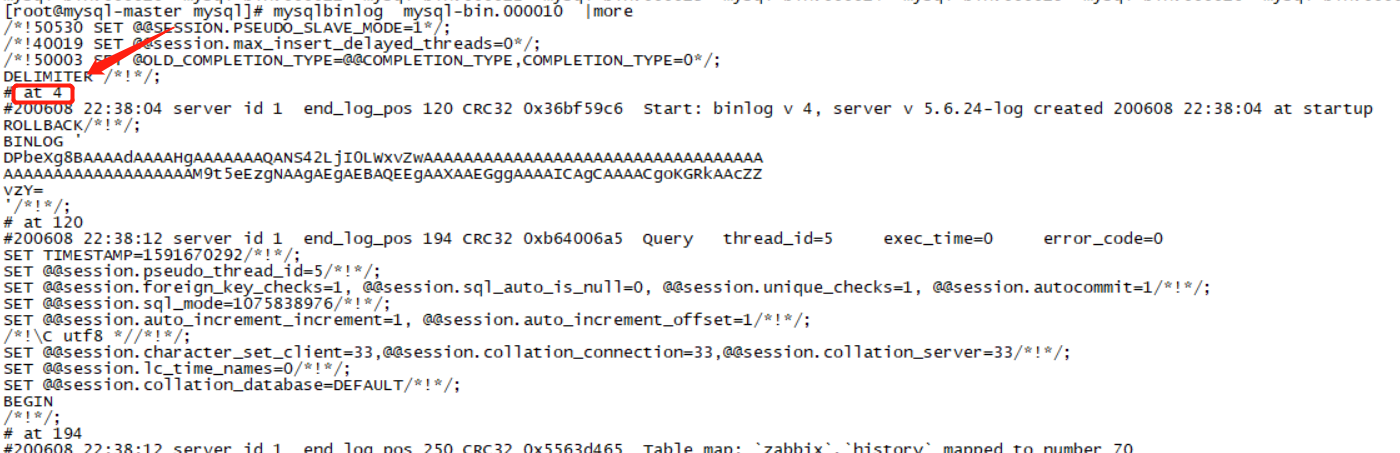
5. 开始同步
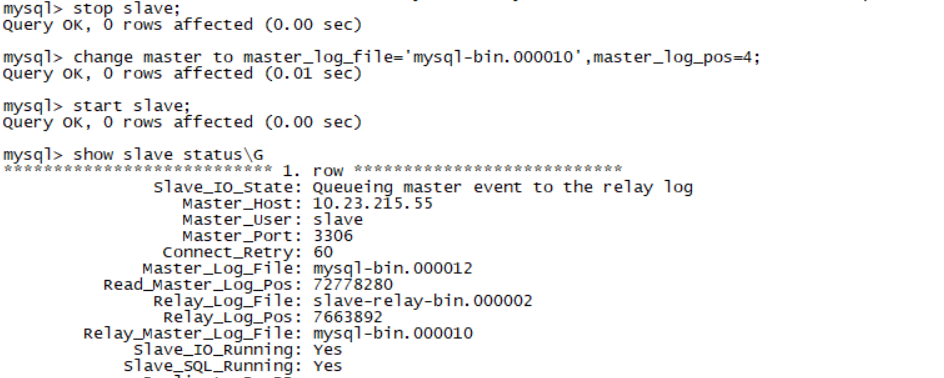
mysql> stop slave; Query OK, 0 rows affected (0.00 sec) mysql> change master to master_log_file='mysql-bin.000010',master_log_pos=4; Query OK, 0 rows affected (0.01 sec) mysql> start slave; Query OK, 0 rows affected (0.00 sec) mysql> show slave statusG
6.查看slave状态,问题解决。
问题分析:
master的pos 36670508 < slave的pos 36755547 也就是说从库里同步了的记录比主库里的binlog日志里记录的多,为啥会出现这个情况呢。个人猜测可能是用sync_binlog参数导致 ,日志还没有刷到磁盘中,在内存里的binlog日志已经发送给slave了,这个时候master服务器重启了导致,日志并没有刷到master的磁盘里。slave已经执行了binlog日志,这样就出现了slave记录比master多。主从里的binlog日志就对不上,所以出错了。
mysql> show global variables like '%sync_binlog%'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | sync_binlog | 0 | +---------------+-------+ 1 row in set (0.00 sec)
默认,sync_binlog=0,表示MySQL不控制binlog的刷新,由文件系统自己控制它的缓存的刷新。这时候的性能是最好的,但是风险也是最大的。因为一旦系统Crash,在binlog_cache中的所有binlog信息都会被丢失。
如果sync_binlog>0,表示每sync_binlog次事务提交,MySQL调用文件系统的刷新操作将缓存刷下去。最安全的就是sync_binlog=1了,表示每次事务提交,MySQL都会把binlog刷下去,是最安全但是性能损耗最大的设置。这样的话,在数据库所在的主机操作系统损坏或者突然掉电的情况下,系统才有可能丢失1个事务的数据。但是binlog虽然是顺序IO,但是设置sync_binlog=1,多个事务同时提交,同样很大的影响MySQL和IO性能。对于高并发事务的系统来说,“sync_binlog”设置为0和设置为1的系统写入性能差距可能高达5倍甚至更多。
所以很多dba设置的sync_binlog并不是最安全的1,而是100或者是0。这样牺牲一定的一致性,可以获得更高的并发和性能。
那么问题来了
怎么知道在断电那会master的内存binlog数据就完全发送给slave了 如果没发送完整咋办,上面的方法虽然暂时解决同步问题,可能会出现其他问题 例如说 master在断电前将某个表中的一个字段值改1 既还没来得及写入到binlog 也还没发送给slave 。
所以还需要做一致性校验和修复。或者在业务低峰的时候重做一次完整的同步解决。我比较懒,而且公司的mysql服务器数据也就10来个G 我做了一次完整同步,避免后续出现问题。
1.导出
mysqldump -h xx.xx.xx.xx -uroot -pxxxxx --all-databases --flush-logs --master-data=2 >./backup.sql
2.导入
mysql -uroot -pxxxx <./backup.sql
3.more backup.sql 查看 MASTER_LOG_FILE MASTER_LOG_POS值进行同步
4.再进行同步。操作和上面的同步操作一样。