js代码的执行,主要分为两个个阶段:编译阶段、执行阶段!本文所有内容基于V8引擎。
1前言
v8引擎
v8引擎工作原理:
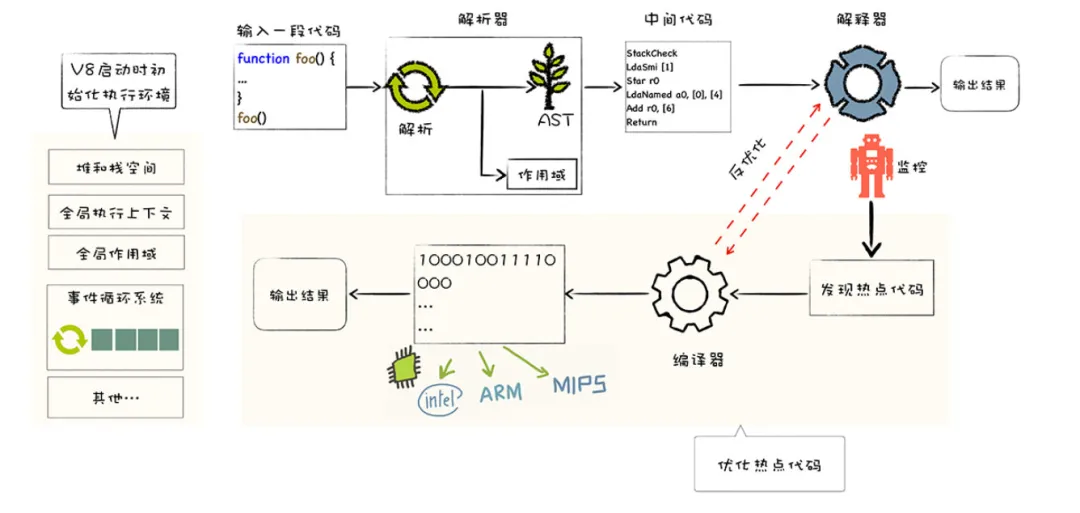
V8由许多子模块构成,其中这4个模块是最重要的:
- Parser:负责将JavaScript源码转换为Abstract Syntax Tree (AST);
- 如果函数没有被调用,那么是不会被转换成AST的
- Ignition:interpreter,即解释器,负责将AST转换为Bytecode,解释执行Bytecode;同时收集TurboFan优化编译所需的信息,比如函数参数的类型,有了类型才能进行真实的运算;
- 如果函数只调用一次,Ignition会执行解释执行ByteCode
- 解释器也有解释执行bytecode的能力
通常有两种类型的解释器,基于栈 (Stack-based)和基于寄存器 (Register-based),基于栈的解释器使用栈来保存函数参数、中间运算结果、变量等;基于寄存器的虚拟机则支持寄存器的指令操作,使用寄存器来保存参数、中间计算结果。通常,基于栈的虚拟机也定义了少量的寄存器,基于寄存器的虚拟机也有堆栈,其区别体现在它们提供的指令集体系。大多数解释器都是基于栈的,比如
Java 虚拟机,.Net 虚拟机,还有早期的 V8 虚拟机。基于堆栈的虚拟机在处理函数调用、解决递归问题和切换上下文时简单明快。而现在的 V8 虚拟机则采用了基于寄存器的设计,它将一些中间数据保存到寄存器中。基于寄存器的解释器架构:

- TurboFan:compiler,即编译器,利用Ignitio所收集的类型信息,将Bytecode转换为优化的汇编代码;
-
如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化的机器码,提高代码的执行性能;
-
但是,机器码实际上也会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如sum函数原来执行的是number类型,后来执行变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码;
- Orinoco:garbage collector,垃圾回收模块,负责将程序不再需要的内存空间回收;
提一嘴
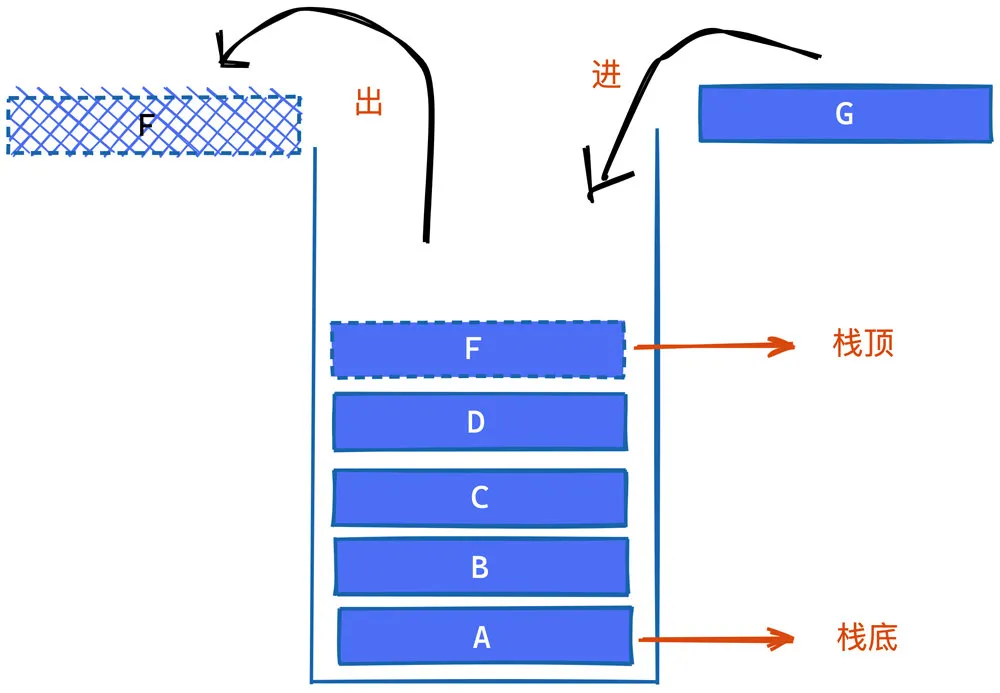
栈 stack
栈的特点是"LIFO,即后进先出(Last in, first out)"。数据存储时只能从顶部逐个存入,取出时也需从顶部逐个取出。
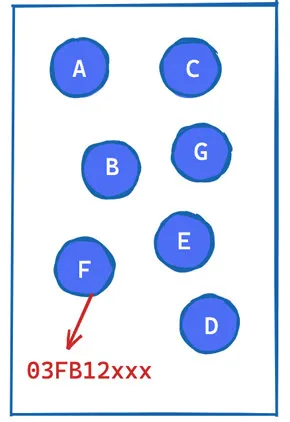
堆 heap
堆的特点是"无序"的key-value"键值对"存储方式。堆的存取方式跟顺序没有关系,不局限出入口。
队列 queue
队列的特点是是"FIFO,即先进先出(First in, first out)" 。数据存取时"从队尾插入,从队头取出"。
"与栈的区别:栈的存入取出都在顶部一个出入口,而队列分两个,一个出口,一个入口"。

2编译阶段
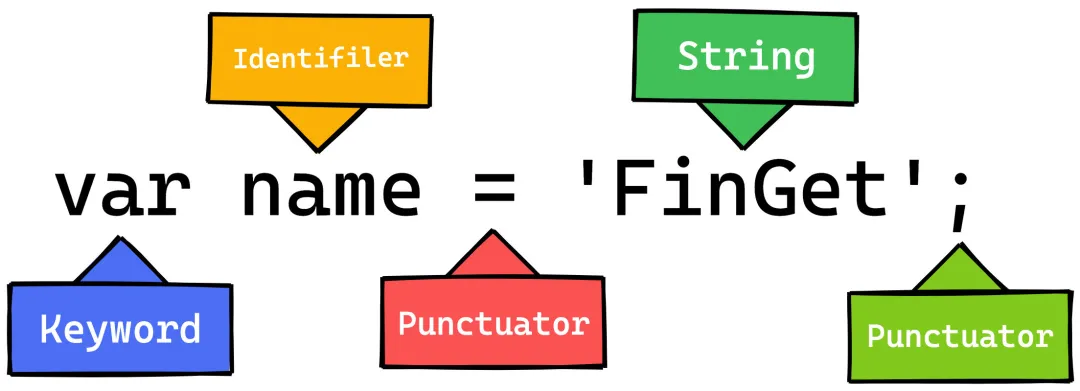
词法分析 Scanner
将由字符组成的字符串分解成(对编程语言来说)有意义的代码块,这些代码块被称为词法单元(token)。
[ { "type": "Keyword", "value": "var" }, { "type": "Identifier", "value": "name" }, { "type": "Punctuator", "value": "=" }, { "type": "String", "value": "'finget'" }, { "type": "Punctuator", "value": ";" } ]
语法分析 Parser
这个过程是将词法单元流(数组)转换成一个由元素逐级嵌套所组成的代表了程序语法结构的树。这个树被称为“抽象语法树”(Abstract Syntax Tree,AST)。
{ "type": "Program", "body": [ { "type": "VariableDeclaration", "declarations": [ { "type": "VariableDeclarator", "id": { "type": "Identifier", "name": "name" }, "init": { "type": "Literal", "value": "finget", "raw": "'finget'" } } ], "kind": "var" } ], "sourceType": "script" }
在此过程中,如果源代码不符合语法规则,则会终止,并抛出“语法错误”。

这里有个工具,可以实时生成语法树,可以试试esprima。
字节码生成
可以用node --print-bytecode查看字节码:
// test.js function getMyname() { var myname = 'finget'; console.log(myname); } getMyname(); node --print-bytecode test.js ... [generated bytecode for function: getMyname (0x10ca700104e9 <SharedFunctionInfo getMyname>)] Parameter count 1 Register count 3 Frame size 24 18 E> 0x10ca70010e86 @ 0 : a7 StackCheck 37 S> 0x10ca70010e87 @ 1 : 12 00 LdaConstant [0] 0x10ca70010e89 @ 3 : 26 fb Star r0 48 S> 0x10ca70010e8b @ 5 : 13 01 00 LdaGlobal [1], [0] 0x10ca70010e8e @ 8 : 26 f9 Star r2 56 E> 0x10ca70010e90 @ 10 : 28 f9 02 02 LdaNamedProperty r2, [2], [2] 0x10ca70010e94 @ 14 : 26 fa Star r1 56 E> 0x10ca70010e96 @ 16 : 59 fa f9 fb 04 CallProperty1 r1, r2, r0, [4] 0x10ca70010e9b @ 21 : 0d LdaUndefined 69 S> 0x10ca70010e9c @ 22 : ab Return Constant pool (size = 3) Handler Table (size = 0) ...
这里涉及到一个很重要的概念:JIT(Just-in-time)一边解释,一边执行。
它是如何工作的呢(结合第一张流程图来看):
1.在 JavaScript 引擎中增加一个监视器(也叫分析器)。监视器监控着代码的运行情况,记录代码一共运行了多少次、如何运行的等信息,如果同一行代码运行了几次,这个代码段就被标记成了 “warm”,如果运行了很多次,则被标记成 “hot”;
2.(基线编译器)如果一段代码变成了 “warm”,那么 JIT 就把它送到基线编译器去编译,并且把编译结果存储起来。比如,监视器监视到了,某行、某个变量执行同样的代码、使用了同样的变量类型,那么就会把编译后的版本,替换这一行代码的执行,并且存储;
3.(优化编译器)如果一个代码段变得 “hot”,监视器会把它发送到优化编译器中。生成一个更快速和高效的代码版本出来,并且存储。例如:循环加一个对象属性时,假设它是 INT 类型,优先做 INT 类型的判断;
4.(反优化 Deoptimization)可是对于 JavaScript 从来就没有确定这么一说,前 99 个对象属性保持着 INT 类型,可能第 100 个就没有这个属性了,那么这时候 JIT 会认为做了一个错误的假设,并且把优化代码丢掉,执行过程将会回到解释器或者基线编译器,这一过程叫做反优化。
作用域
作用域是一套规则,用来管理引擎如何查找变量。在es5之前,js只有全局作用域及函数作用域。es6引入了块级作用域。但是这个块级别作用域需要注意的是不是{}的作用域,而是let,const关键字的块级作用域。
var name = 'FinGet'; function fn() { var age = 18; console.log(name); }
在解析时就会确定作用域:
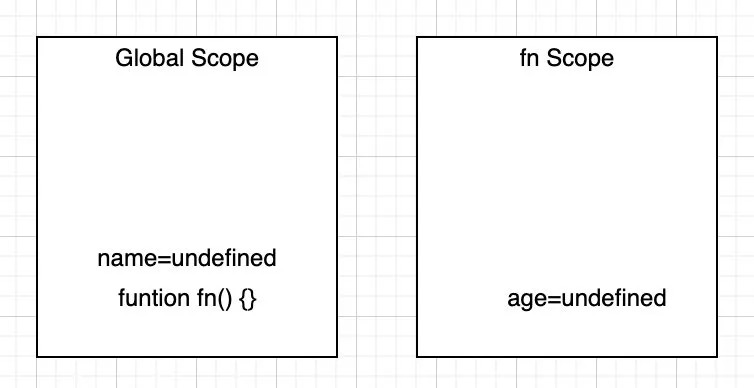
简单的来说,作用域就是个盒子,规定了变量和函数的可访问范围以及他们的生命周期。
词法作用域
词法作用域就是指作用域是由代码中函数声明的位置来决定的,所以词法作用域是静态的作用域,通过它就能够预测代码在执行过程中如何查找标识符。
function fn() { console.log(myName) } function fn1() { var myName = " FinGet " fn() } var myName = " global_finget " fn1()
上面代码打印的结果是:global_finget,这就是因为在编译阶段就已经确定了作用域,fn是定义在全局作用域中的,它在自己内部找不到myName就会去全局作用域中找,不会在fn1中查找。
3执行阶段
执行上下文
遇到函数执行的时候,就会创建一个执行上下文。执行上下文是当前 JavaScript 代码被解析和执行时所在环境的抽象概念。
JavaScript 中有三种执行上下文类型:
- 全局执行上下文 (只有一个)
- 函数执行上下文
- eval
执行上下文的创建分为两个阶段创建:1.创建阶段 2.执行阶段
创建阶段
在任意的 JavaScript 代码被执行时,执行上下文处于创建阶段。在创建阶段中总共发生了三件事情:
- 确定 this 的值,也被称为 This Binding
- LexicalEnvironment(词法环境) 组件被创建。
- VariableEnvironment(变量环境) 组件被创建。
ExecutionContext = { ThisBinding = <this value>, // 确定this LexicalEnvironment = { ... }, // 词法环境 VariableEnvironment = { ... }, // 变量环境 }
This Binding
在全局执行上下文中,this 的值指向全局对象,在浏览器中,this 的值指向 window 对象。在函数执行上下文中,this 的值取决于函数的调用方式。如果它被一个对象引用调用,那么 this 的值被设置为该对象,否则 this 的值被设置为全局对象或 undefined(严格模式下)。
词法环境(Lexical Environment)
词法环境是一个包含标识符变量映射的结构。(这里的标识符表示变量/函数的名称,变量是对实际对象【包括函数类型对象】或原始值的引用)。在词法环境中,有两个组成部分:(1)环境记录(environment record) (2)对外部环境的引用
- 环境记录是
存储变量和函数声明的实际位置。 - 对外部环境的引用意味着它
可以访问其外部词法环境。(实现作用域链的重要部分)
词法环境有两种类型:
-
全局环境(在全局执行上下文中)是一个没有外部环境的词法环境。全局环境的外部环境引用为 null。它拥有一个全局对象(window 对象)及其关联的方法和属性(例如数组方法)以及任何用户自定义的全局变量,this 的值指向这个全局对象。
-
函数环境,用户在函数中定义的变量被存储在环境记录中。对外部环境的引用可以是全局环境,也可以是包含内部函数的外部函数环境。
注意:对于函数环境而言,环境记录 还包含了一个
arguments对象,该对象包含了索引和传递给函数的参数之间的映射以及传递给函数的参数的长度(数量)。
变量环境 Variable Environment
它也是一个词法环境,其 EnvironmentRecord 包含了由 VariableStatements 在此执行上下文创建的绑定。
如上所述,变量环境也是一个词法环境,因此它具有上面定义的词法环境的所有属性。
示例代码:
let a = 20; const b = 30; var c; function multiply(e, f) { var g = 20; return e * f * g; } c = multiply(20, 30);
执行上下文:
GlobalExectionContext = { ThisBinding: <Global Object>, LexicalEnvironment: { EnvironmentRecord: { Type: "Object", // 标识符绑定在这里 a: < uninitialized >, b: < uninitialized >, multiply: < func > } outer: <null> }, VariableEnvironment: { EnvironmentRecord: { Type: "Object", // 标识符绑定在这里 c: undefined, } outer: <null> } } FunctionExectionContext = { ThisBinding: <Global Object>, LexicalEnvironment: { EnvironmentRecord: { Type: "Declarative", // 标识符绑定在这里 Arguments: {0: 20, 1: 30, length: 2}, }, outer: <GlobalLexicalEnvironment> // 指定全局环境 }, VariableEnvironment: { EnvironmentRecord: { Type: "Declarative", // 标识符绑定在这里 g: undefined }, outer: <GlobalLexicalEnvironment> } }
仔细看上面的:
a: < uninitialized >,c: undefined。所以你在let a定义前console.log(a)的时候会得到Uncaught ReferenceError: Cannot access 'a' before initialization。
为什么要有两个词法环境
变量环境组件(VariableEnvironment) 是用来登记var function变量声明,词法环境组件(LexicalEnvironment)是用来登记let const class等变量声明。
在ES6之前都没有块级作用域,ES6之后我们可以用let const来声明块级作用域,有这两个词法环境是为了实现块级作用域的同时不影响var变量声明和函数声明,具体如下:
- 首先在一个正在运行的执行上下文内,词法环境由
LexicalEnvironment和VariableEnvironment构成,用来登记所有的变量声明。 - 当执行到块级代码时候,会先
LexicalEnvironment记录下来,记录为oldEnv。 - 创建一个新的
LexicalEnvironment(outer指向oldEnv),记录为newEnv,并将newEnv设置为正在执行上下文的LexicalEnvironment。 - 块级代码内的
letconst会登记在newEnv里面,但是var声明和函数声明还是登记在原来的VariableEnvironment里。 - 块级代码执行结束后,将
oldEnv还原为正在执行上下文的LexicalEnvironment。
function foo(){ var a = 1 let b = 2 { let b = 3 var c = 4 let d = 5 console.log(a) console.log(b) } console.log(b) console.log(c) console.log(d) } foo()
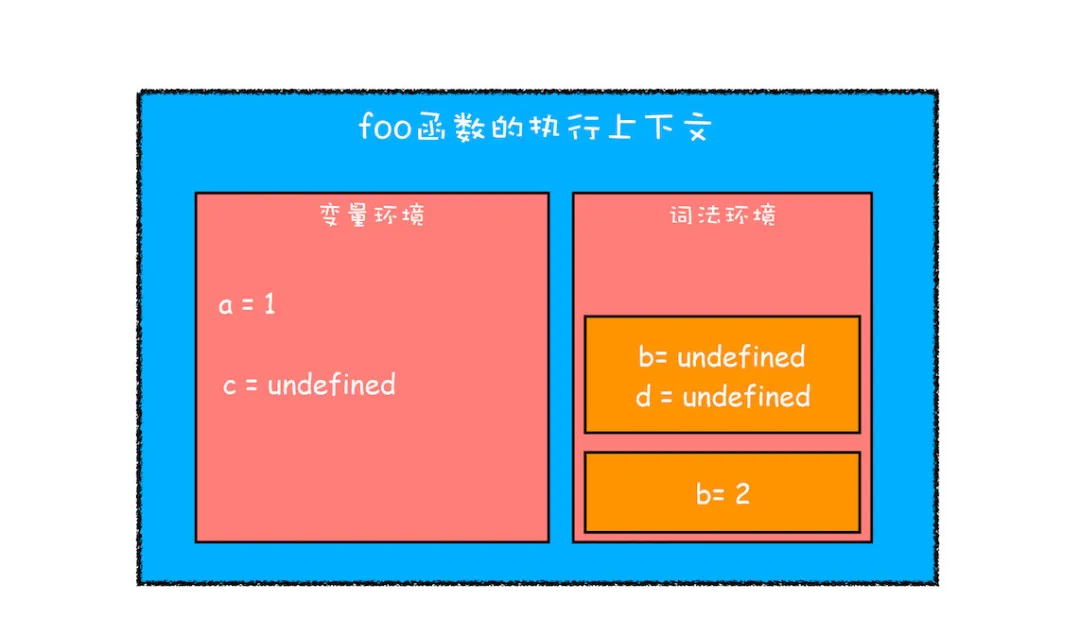
从图中可以看出,当进入函数的作用域块时,作用域块中通过let声明的变量,会被存放在词法环境的一个单独的区域中,这个区域中的变量并不影响作用域块外面的变量,比如在作用域外面声明了变量b,在该作用域块内部也声明了变量b,当执行到作用域内部时,它们都是独立的存在。
其实,在词法环境内部,维护了一个小型栈结构,栈底是函数最外层的变量,进入一个作用域块后,就会把该作用域块内部的变量压到栈顶;当作用域执行完成之后,该作用域的信息就会从栈顶弹出,这就是词法环境的结构。需要注意下,我这里所讲的变量是指通过let或者const声明的变量。
再接下来,当执行到作用域块中的console.log(a)这行代码时,就需要在词法环境和变量环境中查找变量a的值了,具体查找方式是:沿着词法环境的栈顶向下查询,如果在词法环境中的某个块中查找到了,就直接返回给JavaScript引擎,如果没有查找到,那么继续在变量环境中查找。
执行栈 Execution Context Stack
每个函数都会有自己的执行上下文,多个执行上下文就会以栈(调用栈)的方式来管理。
function a () { console.log('In fn a') function b () { console.log('In fn b') function c () { console.log('In fn c') } c() } b() } a()

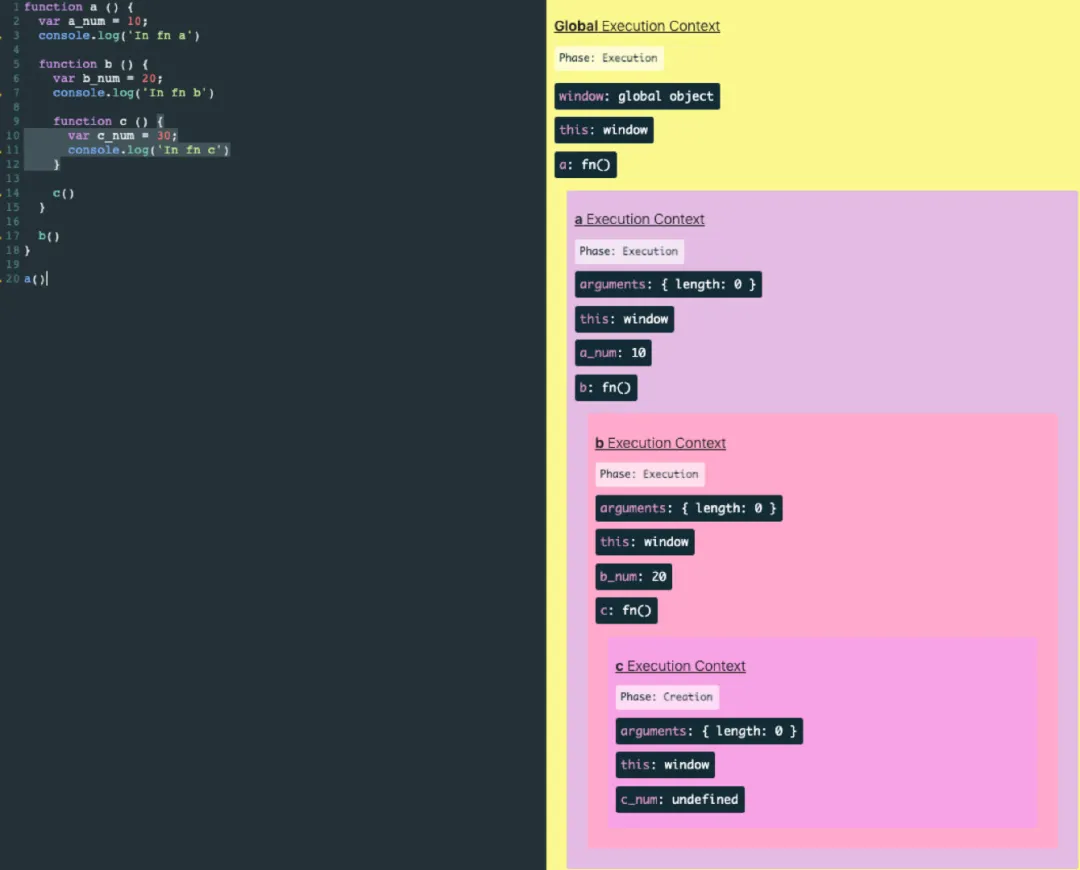
可以用这个工具试一下,更直观的观察进栈和出栈javascript visualizer 工具。
看这个图就可以看出作用域链了吧,很直观。作用域链就是在执行上下文创建阶段确定的。有了执行的环境,才能确定它应该和谁构成作用域链。
4V8垃圾回收
内存分配
栈
栈是临时存储空间,主要存储局部变量和函数调用,内小且存储连续,操作起来简单方便,一般由系统自动分配,自动回收,所以文章内所说的垃圾回收,都是基于堆内存。
基本类型数据(Number, Boolean, String, Null, Undefined, Symbol, BigInt)保存在在栈内存中。引用类型数据保存在堆内存中,引用数据类型的变量是一个指向堆内存中实际对象的引用,存在栈中。
为什么基本数据类型存储在栈中,引用数据类型存储在堆中?
JavaScript引擎需要用栈来维护程序执行期间的上下文的状态,如果栈空间大了的话,所有数据都存放在栈空间里面,会影响到上下文切换的效率,进而影响整个程序的执行效率。
堆
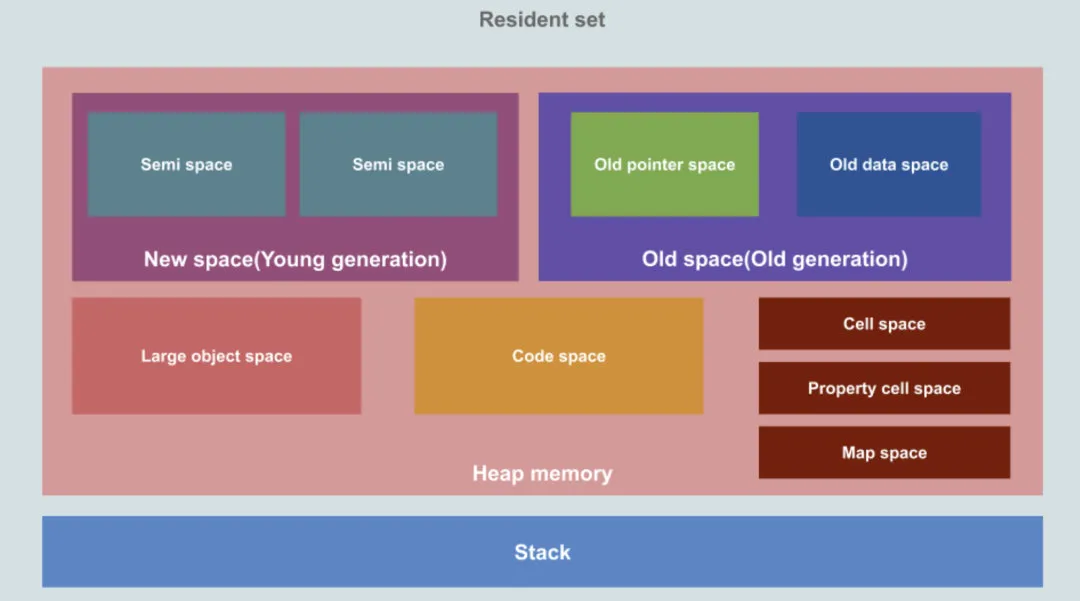
这里用来存储对象和动态数据,这是内存中最大的区域,并且是GC(Garbage collection 垃圾回收)工作的地方。不过,并不是所有的堆内存都可以进行GC,只有新生代和老生代被GC管理。堆可以进一步细分为下面这样:
- 新生代空间:是最新产生的数据存活的地方,这些数据往往都是短暂的。这个空间被一分为二,然后被Scavenger(Minor GC)所管理。稍后会介绍。可以通过V8标志如 --max_semi_space_size 或 --min_semi_space_size 来控制新生代空间大小
- 老生代空间:是从新生代空间经过至少两轮Minor GC仍然存活下来的数据,该空间被Major GC(Mark-Sweep & Mark-Compact)管理,稍后会介绍。可以通过 --initial_old_space_size 或 --max_old_space_size控制空间大小。
Old pointer space:存活下来的包含指向其他对象指针的对象
Old data space:存活下来的只包含数据的对象。
- 大对象空间:这是比空间大小还要大的对象,大对象不会被gc处理。
- 代码空间:这里是JIT所编译的代码。这是除了在大对象空间中分配代码并执行之外的唯一可执行的空间。
- map空间:存放 Cell 和 Map,每个区域都是存放相同大小的元素,结构简单。
代际假说
代际假说有以下两个特点:
- 第一个是大部分对象在内存中存在的时间很短,简单来说,就是很多对象一经分配内存,很快就变得不可访问;
- 第二个是不死的对象,会活得更久。
在 V8 中会把堆分为新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象。
新生区通常只支持 1~8M 的容量,而老生区支持的容量就大很多了。对于这两块区域,V8 分别使用两个不同的垃圾回收器,以便更高效地实施垃圾回收。
- 副垃圾回收器,主要负责新生代的垃圾回收。
- 主垃圾回收器,主要负责老生代的垃圾回收。
新生代中用Scavenge算法来处理。所谓 Scavenge 算法,是把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域。

新生代回收
新加入的对象都会存放到对象区域,当对象区域快被写满时,就需要执行一次垃圾清理操作。
- 先标记需要回收的对象,然后把对象区激活对象复制到空闲区,并排序;
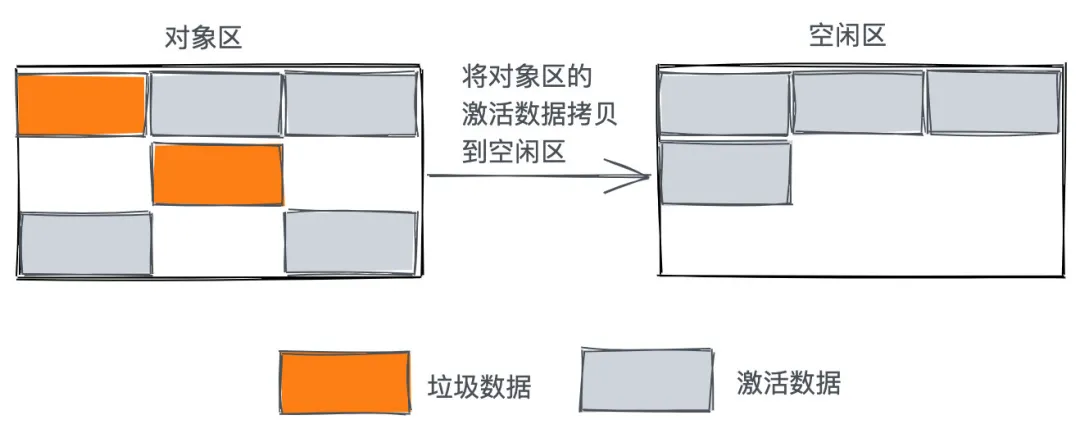
2. 完成复制后,对象区域与空闲区域进行角色翻转,也就是原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域。

由于新生代中采用的 Scavenge 算法,所以每次执行清理操作时,都需要将存活的对象从对象区域复制到空闲区域。但复制操作需要时间成本,如果新生区空间设置得太大了,那么每次清理的时间就会过久,所以为了执行效率,一般新生区的空间会被设置得比较小。
也正是因为新生区的空间不大,所以很容易被存活的对象装满整个区域。为了解决这个问题,JavaScript 引擎采用了对象晋升策略,也就是经过两次垃圾回收依然还存活的对象,会被移动到老生区中。
老生代回收
Mark-Sweep
Mark-Sweep处理时分为两阶段,标记阶段和清理阶段,看起来与Scavenge类似,不同的是,Scavenge算法是复制活动对象,而由于在老生代中活动对象占大多数,所以Mark-Sweep在标记了活动对象和非活动对象之后,直接把非活动对象清除。
- 标记阶段:对老生代进行第一次扫描,标记活动对象
- 清理阶段:对老生代进行第二次扫描,清除未被标记的对象,即清理非活动对象
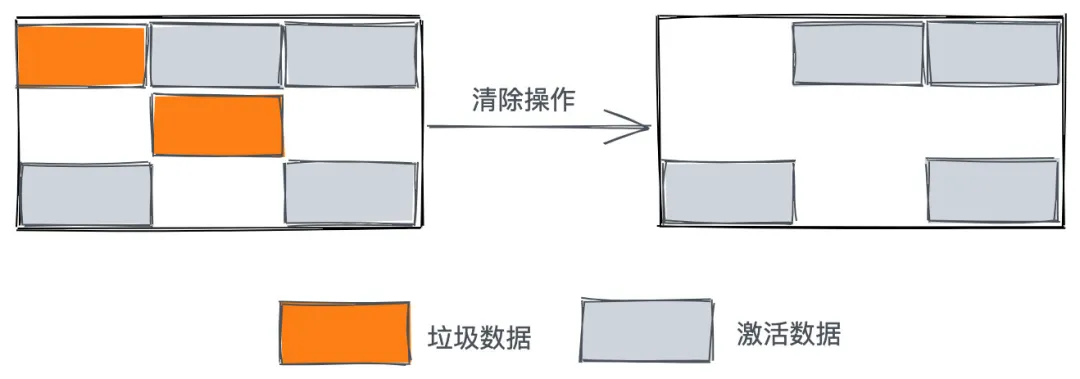
Mark-Compact
由于Mark-Sweep完成之后,老生代的内存中产生了很多内存碎片,若不清理这些内存碎片,如果出现需要分配一个大对象的时候,这时所有的碎片空间都完全无法完成分配,就会提前触发垃圾回收,而这次回收其实不是必要的。
为了解决内存碎片问题,Mark-Compact被提出,它是在是在 Mark-Sweep的基础上演进而来的,相比Mark-Sweep,Mark-Compact添加了活动对象整理阶段,将所有的活动对象往一端移动,移动完成后,直接清理掉边界外的内存。
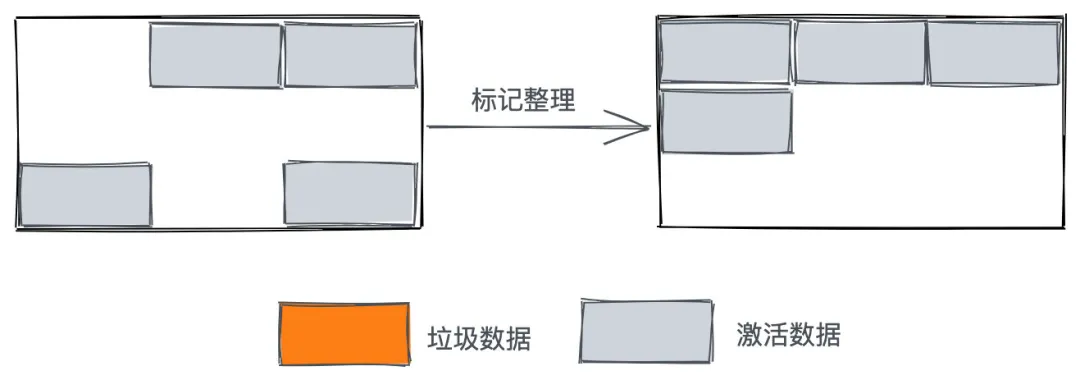
全停顿 Stop-The-World
垃圾回收如果耗费时间,那么主线程的JS操作就要停下来等待垃圾回收完成继续执行,我们把这种行为叫做全停顿(Stop-The-World)。
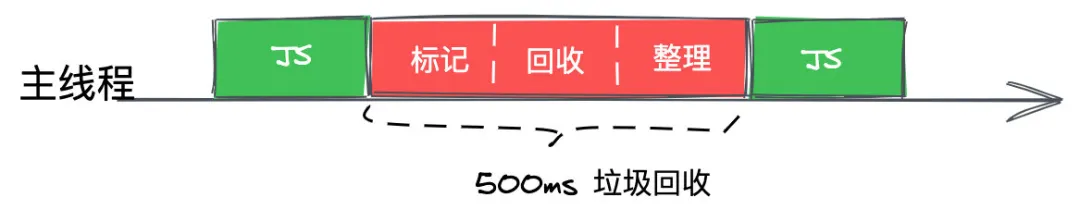
增量标记
为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们把这个算法称为增量标记(Incremental Marking)算法。如下图所示:

惰性清理
增量标记只是对活动对象和非活动对象进行标记,惰性清理用来真正的清理释放内存。当增量标记完成后,假如当前的可用内存足以让我们快速的执行代码,其实我们是没必要立即清理内存的,可以将清理的过程延迟一下,让JavaScript逻辑代码先执行,也无需一次性清理完所有非活动对象内存,垃圾回收器会按需逐一进行清理,直到所有的页都清理完毕。
并发回收
并发式GC允许在在垃圾回收的同时不需要将主线程挂起,两者可以同时进行,只有在个别时候需要短暂停下来让垃圾回收器做一些特殊的操作。但是这种方式也要面对增量回收的问题,就是在垃圾回收过程中,由于JavaScript代码在执行,堆中的对象的引用关系随时可能会变化,所以也要进行写屏障操作。
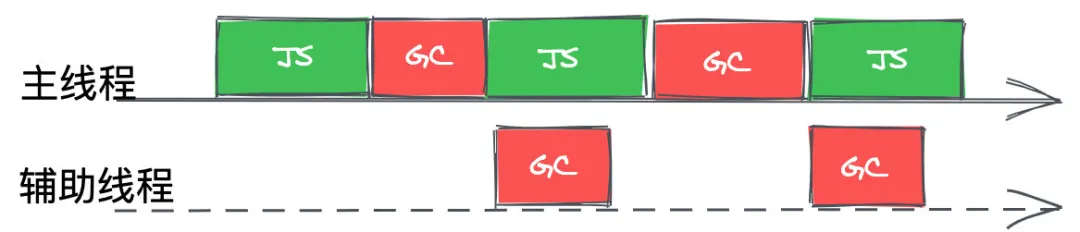
并行回收
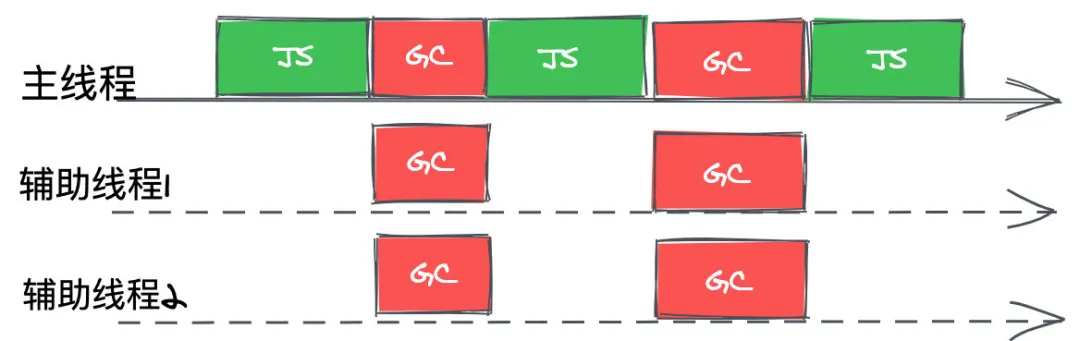
并行式GC允许主线程和辅助线程同时执行同样的GC工作,这样可以让辅助线程来分担主线程的GC工作,使得垃圾回收所耗费的时间等于总时间除以参与的线程数量(加上一些同步开销)。
原文出自https://mp.weixin.qq.com/s/EWAcPO5CbdoYAm0HQpRl_g