1 前言
每次上网想抄点作业,好不容易找到合适的作业想复制但偏偏人家不让你复制,这就很不舒服了啊。
2 开发思路
使用截图工具将要复制的文字截图保存下来,再利用python使用百度文字识别功能将图片中的文字提取出来并保存为文本。
3 注册百度云账号
百度云注册账号 https://cloud.baidu.com/?from=console
管理应用 https://console.bce.baidu.com/ai/#/ai/ocr/overview/index 创建一个
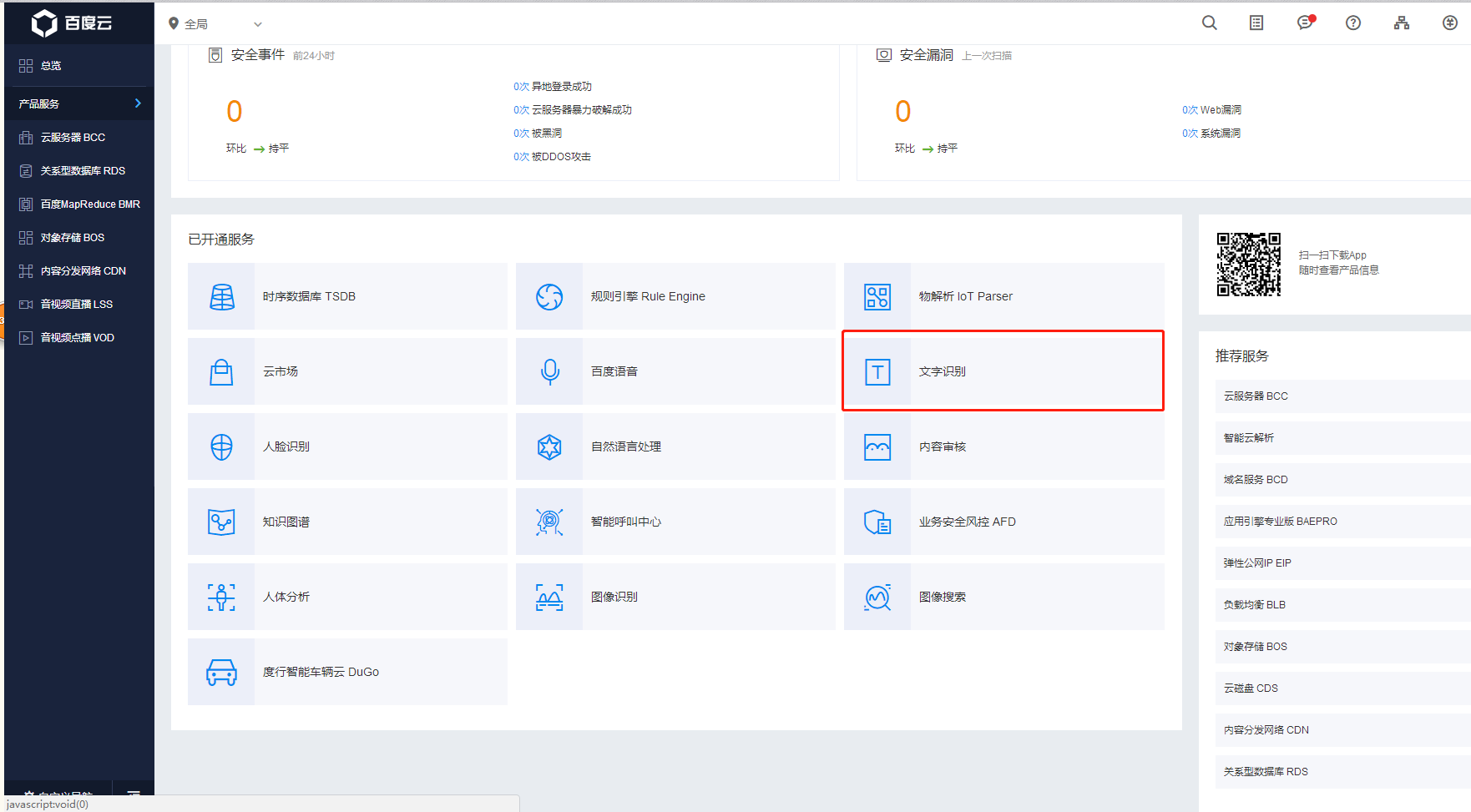
进入链接之后创建应用,由于是从文字识别点进去的,所以默认选中的就是ocr相关内容,填好表格确认。

有了这三个东西,AppID 、API Key、Secret Key,我们就可以在代码里调用接口了。
调用API官方指南:https://ai.baidu.com/docs#/OCR-Python-SDK/top
3 包依赖
本程序引用的包有:glob、os.path、aip.AipOcr、PIL.Image.
glob: 文件名模式匹配,不用遍历整个目录判断每个文件是不是符合。
os.path: 获取文件的属性信息。
aip.AipOcr: 调用百度ocr的API。
PIL.Image: 使用图像处理库中Image模块处理截图后的图片大小。
4 代码实现


import glob from os import path import os from aip import AipOcr from PIL import Image def convertimg(picfile, outdir): '''调整图片大小,对于过大的图片进行压缩 picfile: 图片路径 outdir: 图片输出路径 ''' img = Image.open(picfile) width, height = img.size while(width*height > 4000000): # 该数值压缩后的图片大约 两百多k width = width // 2 height = height // 2 new_img=img.resize((width,height),Image.BILINEAR) #合并目录path.join(...)。你给几个目录它就合并几个,形参多个目录间以逗号隔开 new_img.save(path.join(outdir,os.path.basename(picfile))) print("我是convertimg函数下的:"+os.path.basename(picfile)) def baiduOCR(picfile, outfile): """利用百度api识别文本,并保存提取的文字 picfile: 图片文件名 outfile: 输出文件 """ filename = path.basename(picfile) APP_ID = "" # 刚才获取的 ID,下同 API_KEY = "" SECRECT_KEY = "" client = AipOcr(APP_ID, API_KEY, SECRECT_KEY) i = open(picfile, 'rb') img = i.read() print("正在识别图片: " + filename) message = client.basicGeneral(img) # 通用文字识别,每天 50 000 次免费 #message = client.basicAccurate(img) # 通用文字高精度识别,每天 800 次免费 print("识别成功!") i.close(); with open(outfile, 'a+') as fo: fo.writelines("+" * 60 + ' ') fo.writelines("识别图片: " + filename + " " * 2) fo.writelines("文本内容: ") # 输出文本内容 for text in message.get('words_result'): fo.writelines(text.get('words') + ' ') fo.writelines(' '*2) print("文本导出成功!") print() if __name__ == "__main__": outfile = r'H:/picture/export.txt' outdir = r'H:/picture/tmp' if path.exists(outfile): os.remove(outfile) if not path.exists(outdir): print("创建临时输出目录: "+outdir) os.mkdir(outdir) print("压缩过大的图片...") #首先对过大的图片进行压缩,以提高识别速度,将压缩的图片保存于临时文件夹中 for picfile in glob.glob("H:/picture/*.jpg"): convertimg(picfile, outdir) print("图片识别...") for picfile in glob.glob("H:/picture/tmp/*"): baiduOCR(picfile, outfile) os.remove(picfile) print('图片文本提取结束!文本输出结果位于 %s 文件中。' % outfile) os.removedirs(outdir)
5 效果展示
百度文档截图

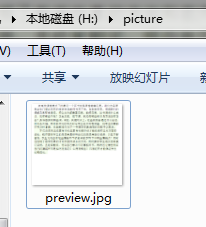
截图后文件保存在指定的文件夹里:
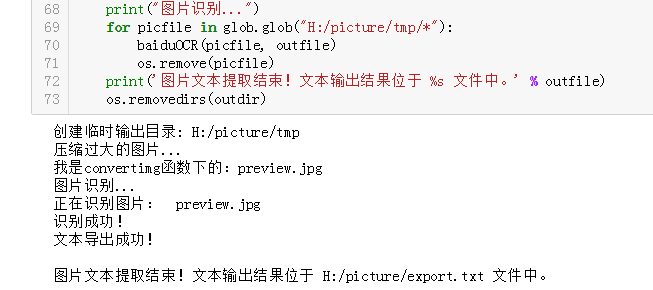
运行代码:
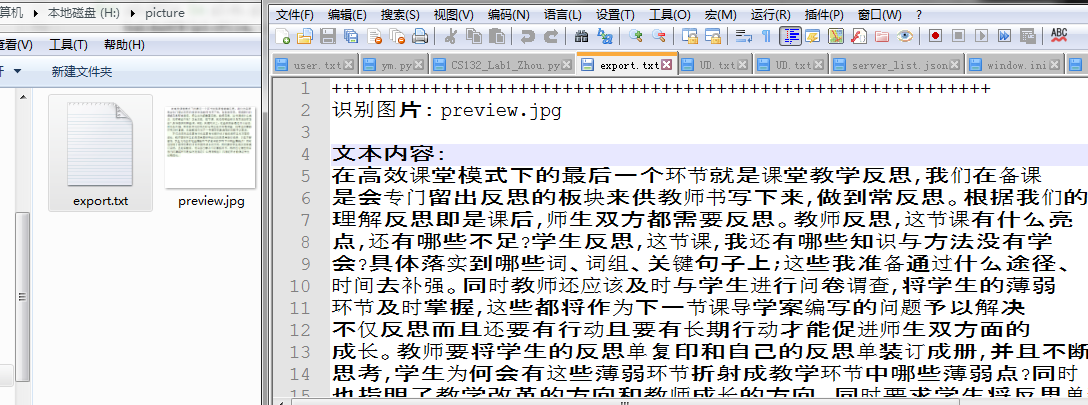
最终效果:
参考文献:
调用百度ocr的API,python简易版本(https://www.jianshu.com/p/e10dc43c38d0)